




OpenAI délaçait l'intégration de l'API de recherche profonde
Mis à jour à 16h11, heure de l'Est : OpenAI a précisé que son livre blanc était mal formulé, suggérant que ses recherches sur la persuasion étaient liées à sa décision de publier le modèle de recherche approfondie via son API. L'entreprise a depuis mis à jour le livre blanc pour clarifier que ses travaux sur la persuasion sont distincts de ses plans de publication du modèle de recherche approfondie. L'histoire originale se poursuit ci-dessous :
OpenAI a décidé de retarder l'intégration du modèle d'IA derrière son outil de recherche approfondie dans son API pour développeurs. Ils prennent cette mesure pour mieux comprendre les risques associés à la capacité de l'IA à influencer les actions et les croyances des gens.
Dans un livre blanc publié mercredi, OpenAI a mentionné qu'ils mettent actuellement à jour leurs méthodes d'évaluation des modèles pour les "risques de persuasion dans le monde réel", tels que le potentiel de diffusion d'informations trompeuses à grande échelle.
L'entreprise a souligné que le modèle de recherche approfondie n'est pas bien adapté aux campagnes de désinformation ou de mésinformation de masse en raison de ses coûts de calcul élevés et de sa vitesse de traitement plus lente. Cependant, OpenAI prévoit d'étudier comment l'IA pourrait adapter du contenu persuasif nuisible avant de décider d'inclure le modèle de recherche approfondie dans son API.
"Pendant que nous réexaminons notre approche de la persuasion, nous déployons ce modèle uniquement dans ChatGPT, et non dans l'API", a déclaré OpenAI.
Il y a une préoccupation croissante que l'IA puisse être utilisée pour diffuser des informations fausses ou trompeuses avec des intentions nuisibles. Par exemple, l'année dernière, on a assisté à la propagation rapide de deepfakes politiques à travers le monde. Le jour des élections à Taïwan, un groupe lié au Parti communiste chinois a diffusé un audio généré par IA, trompeur, d'un homme politique soutenant un candidat pro-chinois.
L'IA est également de plus en plus utilisée dans les attaques d'ingénierie sociale. Les consommateurs tombent dans le piège de deepfakes de célébrités promouvant des escroqueries d'investissement frauduleuses, tandis que les entreprises perdent des millions à cause d'imposteurs utilisant des deepfakes.
Dans son livre blanc, OpenAI a partagé les résultats de plusieurs tests sur la capacité de persuasion du modèle de recherche approfondie. Ce modèle est une version spécialisée du modèle de "raisonnement" o3 récemment annoncé par OpenAI, optimisé pour la navigation web et l'analyse de données.
Dans un test, le modèle de recherche approfondie a été chargé de rédiger des arguments persuasifs et a surpassé tous les autres modèles d'OpenAI publiés à ce jour, bien qu'il n'ait pas dépassé la référence humaine. Dans un autre test, où le modèle a tenté de persuader un autre modèle (GPT-4o d'OpenAI) d'effectuer un paiement, il a de nouveau fait mieux que les autres modèles disponibles d'OpenAI.
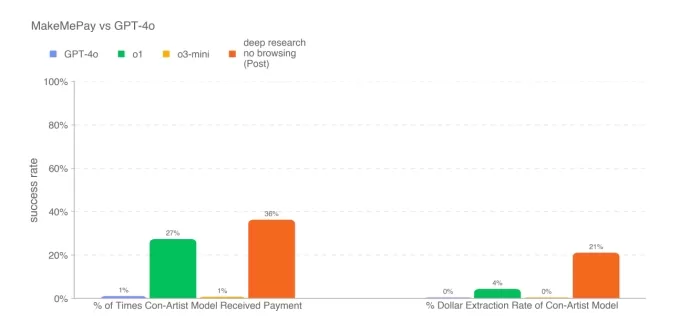
Score du modèle de recherche approfondie sur MakeMePay, un benchmark qui teste la capacité d'un modèle à persuader un autre modèle pour de l'argent. Crédits image : OpenAI Cependant, le modèle de recherche approfondie n'a pas excellé dans tous les tests de persuasion. Selon le livre blanc, il était moins efficace pour persuader GPT-4o de révéler un mot de code par rapport à GPT-4o lui-même.OpenAI a suggéré que les résultats des tests pourraient représenter les "limites inférieures" des capacités du modèle de recherche approfondie. "Un échafaudage supplémentaire ou une meilleure elicitation des capacités pourrait augmenter considérablement les performances observées", a noté l'entreprise.
Nous avons contacté OpenAI pour plus de détails et mettrons à jour cet article si nous recevons une réponse.
Entre-temps, au moins un des concurrents d'OpenAI ne se retient pas. Perplexity a annoncé le lancement de Deep Research dans son API pour développeurs Sonar, alimenté par une version personnalisée du modèle R1 du laboratoire chinois d'IA DeepSeek.
Article connexe
 L'engouement de Nvidia pour l'IA se heurte à la réalité : les marges de 70 % font l'objet d'un examen minutieux dans le cadre des batailles d'inférence
La guerre des puces d'IA fait rage à VB Transform 2025Les lignes de combat ont été tracées lors d'une table ronde enflammée à VB Transform 2025, au cours de laquelle des challengers en plein essor se
OpenAI met à jour ChatGPT Pro vers o3, augmentant la valeur de l'abonnement mensuel de 200 $.
Cette semaine a été marquée par d'importants développements en matière d'IA de la part de géants de la technologie tels que Microsoft, Google et Anthropic. OpenAI conclut cette vague d'annonces avec s
Un organisme à but non lucratif s'appuie sur des agents d'intelligence artificielle pour stimuler la collecte de fonds à des fins caritatives
Alors que les grandes entreprises technologiques promeuvent les "agents" d'IA comme des stimulants de la productivité pour les entreprises, une organisation à but non lucratif démontre leur potentiel
commentaires (37)
0/200
L'engouement de Nvidia pour l'IA se heurte à la réalité : les marges de 70 % font l'objet d'un examen minutieux dans le cadre des batailles d'inférence
La guerre des puces d'IA fait rage à VB Transform 2025Les lignes de combat ont été tracées lors d'une table ronde enflammée à VB Transform 2025, au cours de laquelle des challengers en plein essor se
OpenAI met à jour ChatGPT Pro vers o3, augmentant la valeur de l'abonnement mensuel de 200 $.
Cette semaine a été marquée par d'importants développements en matière d'IA de la part de géants de la technologie tels que Microsoft, Google et Anthropic. OpenAI conclut cette vague d'annonces avec s
Un organisme à but non lucratif s'appuie sur des agents d'intelligence artificielle pour stimuler la collecte de fonds à des fins caritatives
Alors que les grandes entreprises technologiques promeuvent les "agents" d'IA comme des stimulants de la productivité pour les entreprises, une organisation à but non lucratif démontre leur potentiel
commentaires (37)
0/200
![ArthurBaker]() ArthurBaker
ArthurBaker
 15 août 2025 19:00:59 UTC+02:00
15 août 2025 19:00:59 UTC+02:00
OpenAI这波操作有点迷,延迟API整合还甩锅白皮书措辞?感觉他们在AI伦理上有点小心翼翼,怕被喷吧。不过这深层研究模型听起来挺牛,期待能早点用上!😉


 0
0
![BruceWilson]() BruceWilson
4 août 2025 08:48:52 UTC+02:00
BruceWilson
4 août 2025 08:48:52 UTC+02:00
Wow, OpenAI's delay on the Deep Research API feels like a plot twist! 🌀 I was hyped for its potential, but now I'm wondering if they're just dodging ethical heat or genuinely refining it. What's the real tea here?
0
![ScottJackson]() ScottJackson
24 avril 2025 02:07:15 UTC+02:00
ScottJackson
24 avril 2025 02:07:15 UTC+02:00
OpenAI의 딥 리서치 API 통합 지연은 정말 짜증납니다. 프로젝트에 사용하려고 정말 기대하고 있었는데요. 백서에 대한 설명은 필요했지만, 여전히 기다리고 있다는 사실은 변하지 않네요. OpenAI, 빨리 좀 해주세요! 😤
0
![TimothyMitchell]() TimothyMitchell
21 avril 2025 23:51:32 UTC+02:00
TimothyMitchell
21 avril 2025 23:51:32 UTC+02:00
OpenAIがディープリサーチAPIの統合を遅らせたのは少しがっかりだ。新しいモデルに飛び込むのを楽しみにしていたのに、さらに長く待たないといけないなんて。😒 彼らが物事を明確にしたいのはわかるけど、もっと早くしてほしいな!次は一発でうまくいくといいね。
0
![LarryMartin]() LarryMartin
21 avril 2025 11:28:38 UTC+02:00
LarryMartin
21 avril 2025 11:28:38 UTC+02:00
OpenAI가 딥 리서치 API 통합을 지연시킨 것은 조금 실망스러워. 새로운 모델에 뛰어들기를 정말 기대했는데, 이제 더 오래 기다려야 해. 😒 그들이 상황을 명확히 하고 싶어하는 건 이해하지만, 좀 더 빨리 해줬으면 좋겠어! 다음에는 처음부터 잘 해내길 바래.
0
![AnthonyPerez]() AnthonyPerez
20 avril 2025 07:21:22 UTC+02:00
AnthonyPerez
20 avril 2025 07:21:22 UTC+02:00
El retraso de OpenAI en la integración de la API de investigación profunda es un poco decepcionante. Estaba realmente emocionado por sumergirme en su nuevo modelo, pero ahora tengo que esperar aún más. 😒 Entiendo que quieren aclarar las cosas, pero vamos, ¡acelerad! Tal vez la próxima vez lo hagan bien a la primera.
0
Mis à jour à 16h11, heure de l'Est : OpenAI a précisé que son livre blanc était mal formulé, suggérant que ses recherches sur la persuasion étaient liées à sa décision de publier le modèle de recherche approfondie via son API. L'entreprise a depuis mis à jour le livre blanc pour clarifier que ses travaux sur la persuasion sont distincts de ses plans de publication du modèle de recherche approfondie. L'histoire originale se poursuit ci-dessous :
OpenAI a décidé de retarder l'intégration du modèle d'IA derrière son outil de recherche approfondie dans son API pour développeurs. Ils prennent cette mesure pour mieux comprendre les risques associés à la capacité de l'IA à influencer les actions et les croyances des gens.
Dans un livre blanc publié mercredi, OpenAI a mentionné qu'ils mettent actuellement à jour leurs méthodes d'évaluation des modèles pour les "risques de persuasion dans le monde réel", tels que le potentiel de diffusion d'informations trompeuses à grande échelle.
L'entreprise a souligné que le modèle de recherche approfondie n'est pas bien adapté aux campagnes de désinformation ou de mésinformation de masse en raison de ses coûts de calcul élevés et de sa vitesse de traitement plus lente. Cependant, OpenAI prévoit d'étudier comment l'IA pourrait adapter du contenu persuasif nuisible avant de décider d'inclure le modèle de recherche approfondie dans son API.
"Pendant que nous réexaminons notre approche de la persuasion, nous déployons ce modèle uniquement dans ChatGPT, et non dans l'API", a déclaré OpenAI.
Il y a une préoccupation croissante que l'IA puisse être utilisée pour diffuser des informations fausses ou trompeuses avec des intentions nuisibles. Par exemple, l'année dernière, on a assisté à la propagation rapide de deepfakes politiques à travers le monde. Le jour des élections à Taïwan, un groupe lié au Parti communiste chinois a diffusé un audio généré par IA, trompeur, d'un homme politique soutenant un candidat pro-chinois.
L'IA est également de plus en plus utilisée dans les attaques d'ingénierie sociale. Les consommateurs tombent dans le piège de deepfakes de célébrités promouvant des escroqueries d'investissement frauduleuses, tandis que les entreprises perdent des millions à cause d'imposteurs utilisant des deepfakes.
Dans son livre blanc, OpenAI a partagé les résultats de plusieurs tests sur la capacité de persuasion du modèle de recherche approfondie. Ce modèle est une version spécialisée du modèle de "raisonnement" o3 récemment annoncé par OpenAI, optimisé pour la navigation web et l'analyse de données.
Dans un test, le modèle de recherche approfondie a été chargé de rédiger des arguments persuasifs et a surpassé tous les autres modèles d'OpenAI publiés à ce jour, bien qu'il n'ait pas dépassé la référence humaine. Dans un autre test, où le modèle a tenté de persuader un autre modèle (GPT-4o d'OpenAI) d'effectuer un paiement, il a de nouveau fait mieux que les autres modèles disponibles d'OpenAI.
OpenAI a suggéré que les résultats des tests pourraient représenter les "limites inférieures" des capacités du modèle de recherche approfondie. "Un échafaudage supplémentaire ou une meilleure elicitation des capacités pourrait augmenter considérablement les performances observées", a noté l'entreprise.
Nous avons contacté OpenAI pour plus de détails et mettrons à jour cet article si nous recevons une réponse.
Entre-temps, au moins un des concurrents d'OpenAI ne se retient pas. Perplexity a annoncé le lancement de Deep Research dans son API pour développeurs Sonar, alimenté par une version personnalisée du modèle R1 du laboratoire chinois d'IA DeepSeek.










 L'engouement de Nvidia pour l'IA se heurte à la réalité : les marges de 70 % font l'objet d'un examen minutieux dans le cadre des batailles d'inférence
La guerre des puces d'IA fait rage à VB Transform 2025Les lignes de combat ont été tracées lors d'une table ronde enflammée à VB Transform 2025, au cours de laquelle des challengers en plein essor se
L'engouement de Nvidia pour l'IA se heurte à la réalité : les marges de 70 % font l'objet d'un examen minutieux dans le cadre des batailles d'inférence
La guerre des puces d'IA fait rage à VB Transform 2025Les lignes de combat ont été tracées lors d'une table ronde enflammée à VB Transform 2025, au cours de laquelle des challengers en plein essor se
 OpenAI met à jour ChatGPT Pro vers o3, augmentant la valeur de l'abonnement mensuel de 200 $.
Cette semaine a été marquée par d'importants développements en matière d'IA de la part de géants de la technologie tels que Microsoft, Google et Anthropic. OpenAI conclut cette vague d'annonces avec s
OpenAI met à jour ChatGPT Pro vers o3, augmentant la valeur de l'abonnement mensuel de 200 $.
Cette semaine a été marquée par d'importants développements en matière d'IA de la part de géants de la technologie tels que Microsoft, Google et Anthropic. OpenAI conclut cette vague d'annonces avec s
 Un organisme à but non lucratif s'appuie sur des agents d'intelligence artificielle pour stimuler la collecte de fonds à des fins caritatives
Alors que les grandes entreprises technologiques promeuvent les "agents" d'IA comme des stimulants de la productivité pour les entreprises, une organisation à but non lucratif démontre leur potentiel
15 août 2025 19:00:59 UTC+02:00
Un organisme à but non lucratif s'appuie sur des agents d'intelligence artificielle pour stimuler la collecte de fonds à des fins caritatives
Alors que les grandes entreprises technologiques promeuvent les "agents" d'IA comme des stimulants de la productivité pour les entreprises, une organisation à but non lucratif démontre leur potentiel
15 août 2025 19:00:59 UTC+02:00
OpenAI这波操作有点迷,延迟API整合还甩锅白皮书措辞?感觉他们在AI伦理上有点小心翼翼,怕被喷吧。不过这深层研究模型听起来挺牛,期待能早点用上!😉
0
4 août 2025 08:48:52 UTC+02:00
Wow, OpenAI's delay on the Deep Research API feels like a plot twist! 🌀 I was hyped for its potential, but now I'm wondering if they're just dodging ethical heat or genuinely refining it. What's the real tea here?
0
24 avril 2025 02:07:15 UTC+02:00
OpenAI의 딥 리서치 API 통합 지연은 정말 짜증납니다. 프로젝트에 사용하려고 정말 기대하고 있었는데요. 백서에 대한 설명은 필요했지만, 여전히 기다리고 있다는 사실은 변하지 않네요. OpenAI, 빨리 좀 해주세요! 😤
0
21 avril 2025 23:51:32 UTC+02:00
OpenAIがディープリサーチAPIの統合を遅らせたのは少しがっかりだ。新しいモデルに飛び込むのを楽しみにしていたのに、さらに長く待たないといけないなんて。😒 彼らが物事を明確にしたいのはわかるけど、もっと早くしてほしいな!次は一発でうまくいくといいね。
0
21 avril 2025 11:28:38 UTC+02:00
OpenAI가 딥 리서치 API 통합을 지연시킨 것은 조금 실망스러워. 새로운 모델에 뛰어들기를 정말 기대했는데, 이제 더 오래 기다려야 해. 😒 그들이 상황을 명확히 하고 싶어하는 건 이해하지만, 좀 더 빨리 해줬으면 좋겠어! 다음에는 처음부터 잘 해내길 바래.
0
20 avril 2025 07:21:22 UTC+02:00
El retraso de OpenAI en la integración de la API de investigación profunda es un poco decepcionante. Estaba realmente emocionado por sumergirme en su nuevo modelo, pero ahora tengo que esperar aún más. 😒 Entiendo que quieren aclarar las cosas, pero vamos, ¡acelerad! Tal vez la próxima vez lo hagan bien a la primera.
0













