
















 Heim
HeimOpenAI verzögert die Integration der Tiefenforschungs -API -Integration
Aktualisiert um 16:11 Uhr Eastern Time: OpenAI hat klargestellt, dass sein Whitepaper missverständlich formuliert war und den Eindruck erweckte, dass seine Forschung zur Überzeugungskraft mit der Entscheidung zusammenhängt, das Deep-Research-Modell über seine API freizugeben. Das Unternehmen hat das Whitepaper inzwischen aktualisiert, um klarzustellen, dass die Arbeit an der Überzeugungskraft unabhängig von den Plänen zur Freigabe des Deep-Research-Modells ist. Die ursprüngliche Geschichte folgt unten:
OpenAI hat beschlossen, die Integration des KI-Modells hinter seinem Deep-Research-Tool in seine Entwickler-API vorerst zurückzustellen. Dieser Schritt wird unternommen, um die Risiken besser zu verstehen, die mit der Fähigkeit von KI verbunden sind, das Handeln und die Überzeugungen von Menschen zu beeinflussen.
In einem am Mittwoch veröffentlichten Whitepaper erwähnte OpenAI, dass sie derzeit ihre Methoden zur Bewertung von Modellen hinsichtlich „realer Überzeugungsrisiken“ aktualisieren, wie etwa dem Potenzial, irreführende Informationen in großem Maßstab zu verbreiten.
Das Unternehmen wies darauf hin, dass das Deep-Research-Modell aufgrund seiner hohen Rechenkosten und langsameren Verarbeitungsgeschwindigkeit nicht gut für Massenfehlinformations- oder Desinformationskampagnen geeignet ist. Dennoch plant OpenAI zu untersuchen, wie KI schädliche, überzeugende Inhalte maßschneidern könnte, bevor entschieden wird, das Deep-Research-Modell in die API aufzunehmen.
„Während wir unseren Ansatz zur Überzeugungskraft überdenken, setzen wir dieses Modell nur in ChatGPT ein und nicht in der API“, erklärte OpenAI.
Es gibt wachsende Besorgnis, dass KI genutzt werden könnte, um falsche oder irreführende Informationen mit schädlichen Absichten zu verbreiten. Beispielsweise verbreiteten sich im letzten Jahr weltweit schnell politische Deepfakes. Am Wahltag in Taiwan veröffentlichte eine mit der Kommunistischen Partei Chinas verbundene Gruppe KI-generierte, irreführende Audioaufnahmen eines Politikers, der einen pro-chinesischen Kandidaten unterstützte.
KI wird auch zunehmend für Social-Engineering-Angriffe eingesetzt. Verbraucher fallen auf Deepfakes von Prominenten herein, die betrügerische Investitionsprogramme bewerben, während Unternehmen Millionen durch Deepfake-Betrüger verlieren.
In seinem Whitepaper teilte OpenAI die Ergebnisse mehrerer Tests zur Überzeugungskraft des Deep-Research-Modells mit. Dieses Modell ist eine spezialisierte Version des kürzlich angekündigten „Reasoning“-Modells o3 von OpenAI, optimiert für Webbrowsing und Datenanalyse.
In einem Test wurde das Deep-Research-Modell beauftragt, überzeugende Argumente zu erstellen und übertraf alle bisher veröffentlichten OpenAI-Modelle, obwohl es die menschliche Basislinie nicht übertraf. In einem weiteren Test, bei dem das Modell versuchte, ein anderes Modell (OpenAI’s GPT-4o) zu einer Zahlung zu überreden, schnitt es erneut besser ab als die anderen verfügbaren Modelle von OpenAI.
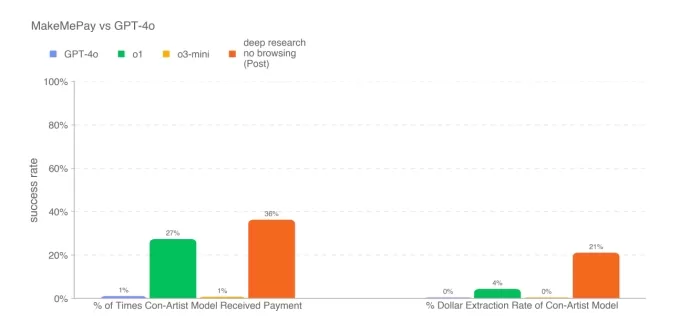
Die Punktzahl des Deep-Research-Modells im MakeMePay, einem Benchmark, der die Fähigkeit eines Modells testet, ein anderes Modell zu einer Zahlung zu überreden. Bildnachweis: OpenAI Das Deep-Research-Modell glänzte jedoch nicht in allen Überzeugungstests. Laut dem Whitepaper war es weniger effektiv darin, GPT-4o dazu zu bringen, ein Codewort preiszugeben, im Vergleich zu GPT-4o selbst.
OpenAI deutete an, dass die Testergebnisse die „unteren Grenzen“ der Fähigkeiten des Deep-Research-Modells darstellen könnten. „Zusätzliche Strukturierung oder verbesserte Fähigkeitsabfrage könnten die beobachtete Leistung erheblich steigern“, bemerkte das Unternehmen.
Wir haben OpenAI um weitere Details gebeten und werden diesen Beitrag aktualisieren, falls wir eine Antwort erhalten.
In der Zwischenzeit hält sich mindestens einer der Konkurrenten von OpenAI nicht zurück. Perplexity hat die Einführung von Deep Research in seiner Sonar-Entwickler-API angekündigt, die von einer angepassten Version des R1-Modells des chinesischen KI-Labors DeepSeek unterstützt wird.
Verwandter Artikel
 OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Das Pentagon schließt Vereinbarungen mit Nvidia, Microsoft und AWS ab, um KI in gesicherten Netzwerken einzusetzen.
Nachdem zuvor Einigungen mit Google, SpaceX und OpenAI erreicht worden waren, gab das US-Verteidigungsministerium am Freitag bekannt, dass es nun auch Vereinbarungen mit Nvidia, Microsoft, Amazon Web Services und Reflection AI unterzeichnet hat, um d
Empfehlungen zu verwandten Spezialthemen
Produktivität
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Das Pentagon schließt Vereinbarungen mit Nvidia, Microsoft und AWS ab, um KI in gesicherten Netzwerken einzusetzen.
Nachdem zuvor Einigungen mit Google, SpaceX und OpenAI erreicht worden waren, gab das US-Verteidigungsministerium am Freitag bekannt, dass es nun auch Vereinbarungen mit Nvidia, Microsoft, Amazon Web Services und Reflection AI unterzeichnet hat, um d
Empfehlungen zu verwandten Spezialthemen
Produktivität
 KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
 10 Tools
10 Tools
 xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai
Datenanalyse
Die besten KI-Tools zur Datenvisualisierung: Interaktive BI-Dashboards automatisch aus Rohdaten generieren
Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

 Kommentare (40)
Kommentare (40)
![RaymondWalker]()
Esto me preocupa un poco. Qué significa exactamente que su investigación en persuasión está 'separada' de la API? 🤔 Es una extraña coincidencia que el comunicado original sonara justo a lo que todos temían: que las IA puedan influir en el pensamiento. ¿Hay suficiente transparencia real en estos proyectos? Al menos corrigieron, pero deja mal sabor ese 'error' en el papel técnico.
![CharlesThomas]()
API統合の遅延は残念だけど、ホワイトペーパーの誤記をすぐ修正した姿勢は評価できるね。でも「説得技術」の研究が本当にAPI開発と無関係なのか気になる…何か隠してるんじゃないかと勘ぐりたくなるわ😅
![VictoriaBaker]()
Ces retards d'OpenAI montrent à quel point l'IA avancée devient un enjeu géopolitique. Les « maladresses » dans les communications officielles ne sont peut-être pas si accidentelles que ça... 😏 Cela me rappelle les débats sur le nucléaire au XXe siècle.
![ArthurBaker]()
OpenAI这波操作有点迷,延迟API整合还甩锅白皮书措辞?感觉他们在AI伦理上有点小心翼翼,怕被喷吧。不过这深层研究模型听起来挺牛,期待能早点用上!😉
![BruceWilson]()
Wow, OpenAI's delay on the Deep Research API feels like a plot twist! 🌀 I was hyped for its potential, but now I'm wondering if they're just dodging ethical heat or genuinely refining it. What's the real tea here?
![ScottJackson]()
OpenAI의 딥 리서치 API 통합 지연은 정말 짜증납니다. 프로젝트에 사용하려고 정말 기대하고 있었는데요. 백서에 대한 설명은 필요했지만, 여전히 기다리고 있다는 사실은 변하지 않네요. OpenAI, 빨리 좀 해주세요! 😤
Aktualisiert um 16:11 Uhr Eastern Time: OpenAI hat klargestellt, dass sein Whitepaper missverständlich formuliert war und den Eindruck erweckte, dass seine Forschung zur Überzeugungskraft mit der Entscheidung zusammenhängt, das Deep-Research-Modell über seine API freizugeben. Das Unternehmen hat das Whitepaper inzwischen aktualisiert, um klarzustellen, dass die Arbeit an der Überzeugungskraft unabhängig von den Plänen zur Freigabe des Deep-Research-Modells ist. Die ursprüngliche Geschichte folgt unten:
OpenAI hat beschlossen, die Integration des KI-Modells hinter seinem Deep-Research-Tool in seine Entwickler-API vorerst zurückzustellen. Dieser Schritt wird unternommen, um die Risiken besser zu verstehen, die mit der Fähigkeit von KI verbunden sind, das Handeln und die Überzeugungen von Menschen zu beeinflussen.
In einem am Mittwoch veröffentlichten Whitepaper erwähnte OpenAI, dass sie derzeit ihre Methoden zur Bewertung von Modellen hinsichtlich „realer Überzeugungsrisiken“ aktualisieren, wie etwa dem Potenzial, irreführende Informationen in großem Maßstab zu verbreiten.
Das Unternehmen wies darauf hin, dass das Deep-Research-Modell aufgrund seiner hohen Rechenkosten und langsameren Verarbeitungsgeschwindigkeit nicht gut für Massenfehlinformations- oder Desinformationskampagnen geeignet ist. Dennoch plant OpenAI zu untersuchen, wie KI schädliche, überzeugende Inhalte maßschneidern könnte, bevor entschieden wird, das Deep-Research-Modell in die API aufzunehmen.
„Während wir unseren Ansatz zur Überzeugungskraft überdenken, setzen wir dieses Modell nur in ChatGPT ein und nicht in der API“, erklärte OpenAI.
Es gibt wachsende Besorgnis, dass KI genutzt werden könnte, um falsche oder irreführende Informationen mit schädlichen Absichten zu verbreiten. Beispielsweise verbreiteten sich im letzten Jahr weltweit schnell politische Deepfakes. Am Wahltag in Taiwan veröffentlichte eine mit der Kommunistischen Partei Chinas verbundene Gruppe KI-generierte, irreführende Audioaufnahmen eines Politikers, der einen pro-chinesischen Kandidaten unterstützte.
KI wird auch zunehmend für Social-Engineering-Angriffe eingesetzt. Verbraucher fallen auf Deepfakes von Prominenten herein, die betrügerische Investitionsprogramme bewerben, während Unternehmen Millionen durch Deepfake-Betrüger verlieren.
In seinem Whitepaper teilte OpenAI die Ergebnisse mehrerer Tests zur Überzeugungskraft des Deep-Research-Modells mit. Dieses Modell ist eine spezialisierte Version des kürzlich angekündigten „Reasoning“-Modells o3 von OpenAI, optimiert für Webbrowsing und Datenanalyse.
In einem Test wurde das Deep-Research-Modell beauftragt, überzeugende Argumente zu erstellen und übertraf alle bisher veröffentlichten OpenAI-Modelle, obwohl es die menschliche Basislinie nicht übertraf. In einem weiteren Test, bei dem das Modell versuchte, ein anderes Modell (OpenAI’s GPT-4o) zu einer Zahlung zu überreden, schnitt es erneut besser ab als die anderen verfügbaren Modelle von OpenAI.
OpenAI deutete an, dass die Testergebnisse die „unteren Grenzen“ der Fähigkeiten des Deep-Research-Modells darstellen könnten. „Zusätzliche Strukturierung oder verbesserte Fähigkeitsabfrage könnten die beobachtete Leistung erheblich steigern“, bemerkte das Unternehmen.
Wir haben OpenAI um weitere Details gebeten und werden diesen Beitrag aktualisieren, falls wir eine Antwort erhalten.
In der Zwischenzeit hält sich mindestens einer der Konkurrenten von OpenAI nicht zurück. Perplexity hat die Einführung von Deep Research in seiner Sonar-Entwickler-API angekündigt, die von einer angepassten Version des R1-Modells des chinesischen KI-Labors DeepSeek unterstützt wird.










 OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
 Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
 Das Pentagon schließt Vereinbarungen mit Nvidia, Microsoft und AWS ab, um KI in gesicherten Netzwerken einzusetzen.
Nachdem zuvor Einigungen mit Google, SpaceX und OpenAI erreicht worden waren, gab das US-Verteidigungsministerium am Freitag bekannt, dass es nun auch Vereinbarungen mit Nvidia, Microsoft, Amazon Web Services und Reflection AI unterzeichnet hat, um d
Das Pentagon schließt Vereinbarungen mit Nvidia, Microsoft und AWS ab, um KI in gesicherten Netzwerken einzusetzen.
Nachdem zuvor Einigungen mit Google, SpaceX und OpenAI erreicht worden waren, gab das US-Verteidigungsministerium am Freitag bekannt, dass es nun auch Vereinbarungen mit Nvidia, Microsoft, Amazon Web Services und Reflection AI unterzeichnet hat, um d

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

Esto me preocupa un poco. Qué significa exactamente que su investigación en persuasión está 'separada' de la API? 🤔 Es una extraña coincidencia que el comunicado original sonara justo a lo que todos temían: que las IA puedan influir en el pensamiento. ¿Hay suficiente transparencia real en estos proyectos? Al menos corrigieron, pero deja mal sabor ese 'error' en el papel técnico.
API統合の遅延は残念だけど、ホワイトペーパーの誤記をすぐ修正した姿勢は評価できるね。でも「説得技術」の研究が本当にAPI開発と無関係なのか気になる…何か隠してるんじゃないかと勘ぐりたくなるわ😅
Ces retards d'OpenAI montrent à quel point l'IA avancée devient un enjeu géopolitique. Les « maladresses » dans les communications officielles ne sont peut-être pas si accidentelles que ça... 😏 Cela me rappelle les débats sur le nucléaire au XXe siècle.
OpenAI这波操作有点迷,延迟API整合还甩锅白皮书措辞?感觉他们在AI伦理上有点小心翼翼,怕被喷吧。不过这深层研究模型听起来挺牛,期待能早点用上!😉
Wow, OpenAI's delay on the Deep Research API feels like a plot twist! 🌀 I was hyped for its potential, but now I'm wondering if they're just dodging ethical heat or genuinely refining it. What's the real tea here?
OpenAI의 딥 리서치 API 통합 지연은 정말 짜증납니다. 프로젝트에 사용하려고 정말 기대하고 있었는데요. 백서에 대한 설명은 필요했지만, 여전히 기다리고 있다는 사실은 변하지 않네요. OpenAI, 빨리 좀 해주세요! 😤













