
















 Maison
Maison
Meta dévoile le Llama 4, pionnier des capacités d'IA multimodale de nouvelle génération
Le Llama 4 de Meta représente un saut quantique dans la technologie de l'IA multimodale, introduisant des capacités sans précédent qui redéfinissent ce qui est possible en matière d'intelligence artificielle. Avec sa triade de modèles spécialisés, son traitement contextuel étendu et ses performances défiant toute concurrence, cette dernière itération établit de nouvelles normes pour le développement et la mise en œuvre de l'IA.
Points clés
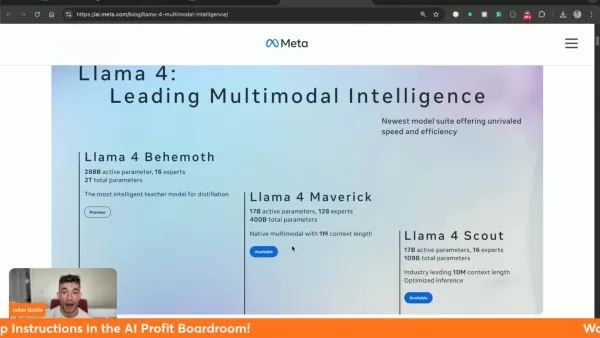
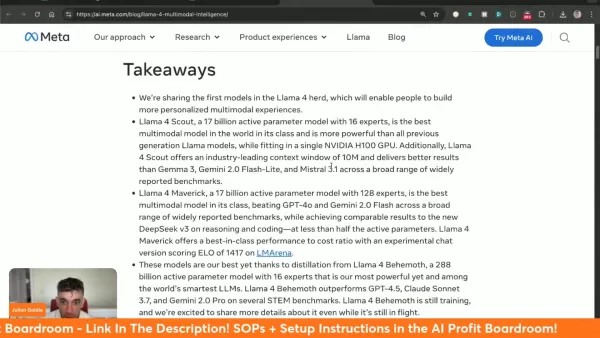
Trois variantes spécialisées du Llama 4 : Behemoth (formation), Maverick et Scout.
Le modèle Scout est doté d'une fenêtre contextuelle révolutionnaire de 10 millions de jetons.
Maverick surpasse ses concurrents, notamment Gemini 2.0 Flash et GPT-4o.
Disponible sur les plateformes llama.com et Hugging Face
Démontre des performances supérieures dans des domaines clés - traitement visuel, codage et raisonnement complexe
Intégré dans les services MetaAI au sein de WhatsApp, Messenger et Instagram
Comprendre le Llama 4 : la dernière avancée de Meta en matière d'IA
Qu'est-ce que Llama 4 ?
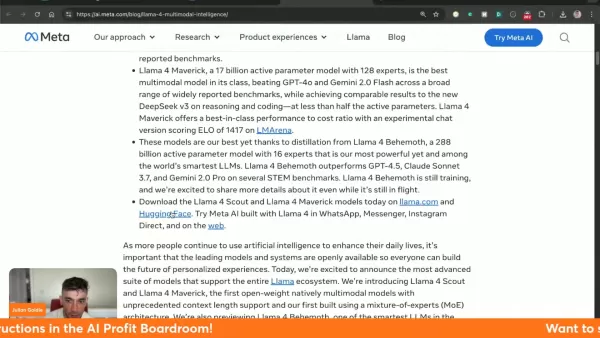
Llama 4 constitue le système d'IA multimodale de Meta le plus avancé à ce jour, combinant le traitement textuel et visuel dans une architecture unifiée. Cette technologie de nouvelle génération offre une efficacité inégalée dans diverses applications, avec trois modèles distincts offrant des capacités spécialisées.
Le traitement contextuel révolutionnaire du système permet de s'affranchir des limites précédentes et d'interpréter de manière nuancée des données complexes. La capacité de 10 millions de jetons de Scout est particulièrement révolutionnaire, car elle permet l'analyse complète de vastes ensembles de données tout en préservant la cohérence.
Meta facilite une large accessibilité via llama.com et Hugging Face, encourageant l'innovation des développeurs tout en intégrant le Llama 4 dans ses plateformes sociales phares.
Comparaison du Llama 4 Scout avec d'autres modèles
Le Llama 4 Scout comparé à ses concurrents : Une analyse comparative
Le Llama 4 Scout établit de nouvelles normes de performance par rapport aux leaders de l'industrie :
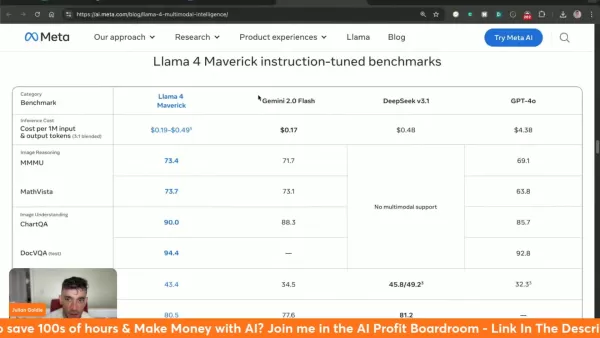
Analyse comparative Llama 4 Scout Gemma 3 27B Mistral 3.1 24B Gemini 2.0 Flash-Lite Raisonnement sur l'image (MMMU) 69.4 64.9 62.8 68.0 MathVista 70.7 67.6 68.9 57.6 Compréhension des images (ChartQA) 88.8 76.3 86.2 73.0 DocVQA (test) 94.4 90.4 94.1 91.2 Codage (LiveCodeBench) 32.8 29.7 - 28.9 Raisonnement et connaissances (MMLU Pro) 74.3 67.5 66.8 71.6
Le modèle excelle particulièrement dans l'analyse de documents (94,4 DocVQA) et l'interprétation de données visuelles (88,8 ChartQA), tout en maintenant des performances compétitives dans toutes les catégories testées.
Comment démarrer avec Llama 4
Accéder à Llama 4 et l'implémenter dans vos projets
Commencez à explorer les capacités de Llama 4 en suivant les étapes suivantes :
- Accès à la plate-forme : Visitez les canaux de distribution officiels sur llama.com ou Hugging Face.
- Sélection du modèle : Choisissez parmi les versions disponibles en fonction des exigences du projet (notez que Behemoth est toujours en développement).
- Intégration du système : Suivre la documentation complète de Meta pour l'implémentation
- Test de performance : Expérimenter avec diverses applications pour optimiser les résultats
Analyse des coûts du Llama 4
Comprendre le coût d'inférence de Llama 4 Maverick
Le Llama 4 Maverick fonctionne à un prix compris entre 0,19 et 0,49 dollar par million de jetons, ce qui représente une valeur significative par rapport aux autres solutions :
- Gemini 2.0 Flash : ~0,17 $/million de jetons
- deepseek v3.1 : ~0,48$/million de jetons
- GPT-4o : ~4,38 $/million de jetons
Peser le pour et le contre de Llama 4
Avantages
Des mesures de performance qui font référence
Capacité contextuelle sans précédent de 10 millions de jetons
Accessible via les principales plateformes d'IA
Véritable architecture multimodale
Rentable par rapport aux alternatives haut de gamme
Inconvénients
Modèle géant encore en phase d'apprentissage
Besoins élevés en ressources système
Exploration des principales caractéristiques du Llama 4
Principales caractéristiques des modèles de lama 4
Le Llama 4 présente plusieurs innovations révolutionnaires :
- Multimodalité native : Traitement unifié des entrées textuelles et visuelles
- Capacité de contexte massive : traitement de 10 millions de jetons dans le modèle Scout
- Leadership en matière de performance : Surpasse le GPT-4o/Gemini 2.0 dans de nombreuses catégories
- Accessibilité ouverte : Disponible via llama.com et Hugging Face
- Efficacité architecturale : La conception du mélange d'experts (MoE) optimise les ressources informatiques.
Divers cas d'utilisation du Llama 4
Applications potentielles du Llama 4 dans diverses industries
Les capacités avancées du Llama 4 permettent des applications transformatrices :
- Expérience client : Amélioration des interactions avec les chatbots grâce à une mémoire contextuelle étendue
- Génération de contenu : Production automatisée de contenu de haute qualité
- Intelligence économique : Reconnaissance et analyse avancées des données
- Outils pour les développeurs : Assistance au codage et débogage alimentés par l'IA
- Plateformes sociales : Intégration dans les services de messagerie de Meta pour améliorer les interactions avec l'IA
Questions fréquemment posées
Où puis-je accéder à Llama 4 ?
Disponible sur llama.com et Hugging Face, avec intégration dans les plateformes sociales de Meta.
Quelle est la taille de la fenêtre contextuelle de Llama 4 Scout ?
Scout dispose d'une capacité de 10 millions de jetons, la plus élevée de l'industrie, pour une compréhension complète du contexte.
Quelles sont les performances de Llama 4 par rapport aux autres modèles ?
Llama 4 Scout démontre des capacités supérieures à celles de ses concurrents dans de nombreux domaines d'évaluation.
Qu'est-ce que Meta AI ?
L'implémentation de l'IA de Meta est désormais alimentée par Llama 4 sur WhatsApp, Messenger et Instagram.
Questions connexes
Quels sont les différents modèles disponibles dans Llama 4 ?
Trois modèles spécialisés : Behemoth (modèle de formation/enseignement), Maverick (1M contexte multimodal), et Scout (10M contexte spécialiste).
Comment l'architecture Mixture of Experts (MoE) améliore-t-elle les performances de Llama 4 ?
Elle optimise l'efficacité des calculs tout en maintenant la qualité des résultats grâce à des sous-réseaux spécialisés.
Où puis-je consulter les points de référence adaptés aux instructions pour chaque modèle de Llama 4 ?
Des comparaisons complètes sont disponibles par rapport à GPT-4o, Gemini 2.0 Flash et d'autres modèles de premier plan.
Article connexe
 Zhiyuan WITA met fin à son projet d'interaction avec des robots « nus » en déposant sa première demande d'agrément
Le secteur de l'intelligence incarnée a franchi une étape importante. Selon la dernière annonce de l'Administration du cyberespace de Shanghai, le grand modèle WITA développé par Zhiyuan a mené à bien
Une étude anthropologique établit un lien entre les contenus générés par l'IA et une diminution de la réflexion humaine
Lorsque vous voyez l'IA produire instantanément un code ou un document bien structuré et d'une logique claire, êtes-vous tenté de lui faire confiance sans y réfléchir à deux fois ? Selon AIbase, Anthr
Les ministères britanniques s'affrontent au sujet des besoins énergétiques des centres de données dédiés à l'IA
Le gouvernement britannique est confronté à un défi de taille : promouvoir les énergies propres tout en visant à devenir un leader mondial dans le domaine de l'intelligence artificielle. Or, de sérieu
Recommandations de sujets spéciaux liés
Création de bande dessinée
Zhiyuan WITA met fin à son projet d'interaction avec des robots « nus » en déposant sa première demande d'agrément
Le secteur de l'intelligence incarnée a franchi une étape importante. Selon la dernière annonce de l'Administration du cyberespace de Shanghai, le grand modèle WITA développé par Zhiyuan a mené à bien
Une étude anthropologique établit un lien entre les contenus générés par l'IA et une diminution de la réflexion humaine
Lorsque vous voyez l'IA produire instantanément un code ou un document bien structuré et d'une logique claire, êtes-vous tenté de lui faire confiance sans y réfléchir à deux fois ? Selon AIbase, Anthr
Les ministères britanniques s'affrontent au sujet des besoins énergétiques des centres de données dédiés à l'IA
Le gouvernement britannique est confronté à un défi de taille : promouvoir les énergies propres tout en visant à devenir un leader mondial dans le domaine de l'intelligence artificielle. Or, de sérieu
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
 10 outils
10 outils
 xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

 commentaires (1)
commentaires (1)
![CharlesYoung]()
C'est fou à quel point l'IA multimodale progresse vite ! 🤯 Mais je me demande si Meta va partager ces modèles en open-source comme avant, ou si la concurrence avec OpenAI les pousse à garder leurs cartes cachées...
Le Llama 4 de Meta représente un saut quantique dans la technologie de l'IA multimodale, introduisant des capacités sans précédent qui redéfinissent ce qui est possible en matière d'intelligence artificielle. Avec sa triade de modèles spécialisés, son traitement contextuel étendu et ses performances défiant toute concurrence, cette dernière itération établit de nouvelles normes pour le développement et la mise en œuvre de l'IA.
Points clés
Trois variantes spécialisées du Llama 4 : Behemoth (formation), Maverick et Scout.
Le modèle Scout est doté d'une fenêtre contextuelle révolutionnaire de 10 millions de jetons.
Maverick surpasse ses concurrents, notamment Gemini 2.0 Flash et GPT-4o.
Disponible sur les plateformes llama.com et Hugging Face
Démontre des performances supérieures dans des domaines clés - traitement visuel, codage et raisonnement complexe
Intégré dans les services MetaAI au sein de WhatsApp, Messenger et Instagram
Comprendre le Llama 4 : la dernière avancée de Meta en matière d'IA
Qu'est-ce que Llama 4 ?
Llama 4 constitue le système d'IA multimodale de Meta le plus avancé à ce jour, combinant le traitement textuel et visuel dans une architecture unifiée. Cette technologie de nouvelle génération offre une efficacité inégalée dans diverses applications, avec trois modèles distincts offrant des capacités spécialisées.
Le traitement contextuel révolutionnaire du système permet de s'affranchir des limites précédentes et d'interpréter de manière nuancée des données complexes. La capacité de 10 millions de jetons de Scout est particulièrement révolutionnaire, car elle permet l'analyse complète de vastes ensembles de données tout en préservant la cohérence.
Meta facilite une large accessibilité via llama.com et Hugging Face, encourageant l'innovation des développeurs tout en intégrant le Llama 4 dans ses plateformes sociales phares.
Comparaison du Llama 4 Scout avec d'autres modèles
Le Llama 4 Scout comparé à ses concurrents : Une analyse comparative
Le Llama 4 Scout établit de nouvelles normes de performance par rapport aux leaders de l'industrie :
| Analyse comparative | Llama 4 Scout | Gemma 3 27B | Mistral 3.1 24B | Gemini 2.0 Flash-Lite |
|---|---|---|---|---|
| Raisonnement sur l'image (MMMU) | 69.4 | 64.9 | 62.8 | 68.0 |
| MathVista | 70.7 | 67.6 | 68.9 | 57.6 |
| Compréhension des images (ChartQA) | 88.8 | 76.3 | 86.2 | 73.0 |
| DocVQA (test) | 94.4 | 90.4 | 94.1 | 91.2 |
| Codage (LiveCodeBench) | 32.8 | 29.7 | - | 28.9 |
| Raisonnement et connaissances (MMLU Pro) | 74.3 | 67.5 | 66.8 | 71.6 |
Le modèle excelle particulièrement dans l'analyse de documents (94,4 DocVQA) et l'interprétation de données visuelles (88,8 ChartQA), tout en maintenant des performances compétitives dans toutes les catégories testées.
Comment démarrer avec Llama 4
Accéder à Llama 4 et l'implémenter dans vos projets
Commencez à explorer les capacités de Llama 4 en suivant les étapes suivantes :
- Accès à la plate-forme : Visitez les canaux de distribution officiels sur llama.com ou Hugging Face.
- Sélection du modèle : Choisissez parmi les versions disponibles en fonction des exigences du projet (notez que Behemoth est toujours en développement).
- Intégration du système : Suivre la documentation complète de Meta pour l'implémentation
- Test de performance : Expérimenter avec diverses applications pour optimiser les résultats
Analyse des coûts du Llama 4
Comprendre le coût d'inférence de Llama 4 Maverick
Le Llama 4 Maverick fonctionne à un prix compris entre 0,19 et 0,49 dollar par million de jetons, ce qui représente une valeur significative par rapport aux autres solutions :
- Gemini 2.0 Flash : ~0,17 $/million de jetons
- deepseek v3.1 : ~0,48$/million de jetons
- GPT-4o : ~4,38 $/million de jetons
Peser le pour et le contre de Llama 4
Avantages
Des mesures de performance qui font référence
Capacité contextuelle sans précédent de 10 millions de jetons
Accessible via les principales plateformes d'IA
Véritable architecture multimodale
Rentable par rapport aux alternatives haut de gamme
Inconvénients
Modèle géant encore en phase d'apprentissage
Besoins élevés en ressources système
Exploration des principales caractéristiques du Llama 4
Principales caractéristiques des modèles de lama 4
Le Llama 4 présente plusieurs innovations révolutionnaires :
- Multimodalité native : Traitement unifié des entrées textuelles et visuelles
- Capacité de contexte massive : traitement de 10 millions de jetons dans le modèle Scout
- Leadership en matière de performance : Surpasse le GPT-4o/Gemini 2.0 dans de nombreuses catégories
- Accessibilité ouverte : Disponible via llama.com et Hugging Face
- Efficacité architecturale : La conception du mélange d'experts (MoE) optimise les ressources informatiques.
Divers cas d'utilisation du Llama 4
Applications potentielles du Llama 4 dans diverses industries
Les capacités avancées du Llama 4 permettent des applications transformatrices :
- Expérience client : Amélioration des interactions avec les chatbots grâce à une mémoire contextuelle étendue
- Génération de contenu : Production automatisée de contenu de haute qualité
- Intelligence économique : Reconnaissance et analyse avancées des données
- Outils pour les développeurs : Assistance au codage et débogage alimentés par l'IA
- Plateformes sociales : Intégration dans les services de messagerie de Meta pour améliorer les interactions avec l'IA
Questions fréquemment posées
Où puis-je accéder à Llama 4 ?
Disponible sur llama.com et Hugging Face, avec intégration dans les plateformes sociales de Meta.
Quelle est la taille de la fenêtre contextuelle de Llama 4 Scout ?
Scout dispose d'une capacité de 10 millions de jetons, la plus élevée de l'industrie, pour une compréhension complète du contexte.
Quelles sont les performances de Llama 4 par rapport aux autres modèles ?
Llama 4 Scout démontre des capacités supérieures à celles de ses concurrents dans de nombreux domaines d'évaluation.
Qu'est-ce que Meta AI ?
L'implémentation de l'IA de Meta est désormais alimentée par Llama 4 sur WhatsApp, Messenger et Instagram.
Questions connexes
Quels sont les différents modèles disponibles dans Llama 4 ?
Trois modèles spécialisés : Behemoth (modèle de formation/enseignement), Maverick (1M contexte multimodal), et Scout (10M contexte spécialiste).
Comment l'architecture Mixture of Experts (MoE) améliore-t-elle les performances de Llama 4 ?
Elle optimise l'efficacité des calculs tout en maintenant la qualité des résultats grâce à des sous-réseaux spécialisés.
Où puis-je consulter les points de référence adaptés aux instructions pour chaque modèle de Llama 4 ?
Des comparaisons complètes sont disponibles par rapport à GPT-4o, Gemini 2.0 Flash et d'autres modèles de premier plan.










 Zhiyuan WITA met fin à son projet d'interaction avec des robots « nus » en déposant sa première demande d'agrément
Le secteur de l'intelligence incarnée a franchi une étape importante. Selon la dernière annonce de l'Administration du cyberespace de Shanghai, le grand modèle WITA développé par Zhiyuan a mené à bien
Zhiyuan WITA met fin à son projet d'interaction avec des robots « nus » en déposant sa première demande d'agrément
Le secteur de l'intelligence incarnée a franchi une étape importante. Selon la dernière annonce de l'Administration du cyberespace de Shanghai, le grand modèle WITA développé par Zhiyuan a mené à bien
 Une étude anthropologique établit un lien entre les contenus générés par l'IA et une diminution de la réflexion humaine
Lorsque vous voyez l'IA produire instantanément un code ou un document bien structuré et d'une logique claire, êtes-vous tenté de lui faire confiance sans y réfléchir à deux fois ? Selon AIbase, Anthr
Une étude anthropologique établit un lien entre les contenus générés par l'IA et une diminution de la réflexion humaine
Lorsque vous voyez l'IA produire instantanément un code ou un document bien structuré et d'une logique claire, êtes-vous tenté de lui faire confiance sans y réfléchir à deux fois ? Selon AIbase, Anthr
 Les ministères britanniques s'affrontent au sujet des besoins énergétiques des centres de données dédiés à l'IA
Le gouvernement britannique est confronté à un défi de taille : promouvoir les énergies propres tout en visant à devenir un leader mondial dans le domaine de l'intelligence artificielle. Or, de sérieu
Les ministères britanniques s'affrontent au sujet des besoins énergétiques des centres de données dédiés à l'IA
Le gouvernement britannique est confronté à un défi de taille : promouvoir les énergies propres tout en visant à devenir un leader mondial dans le domaine de l'intelligence artificielle. Or, de sérieu

Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

C'est fou à quel point l'IA multimodale progresse vite ! 🤯 Mais je me demande si Meta va partager ces modèles en open-source comme avant, ou si la concurrence avec OpenAI les pousse à garder leurs cartes cachées...













