
















 Hogar
HogarMeta presenta Llama 4: pionera en IA multimodal de nueva generación
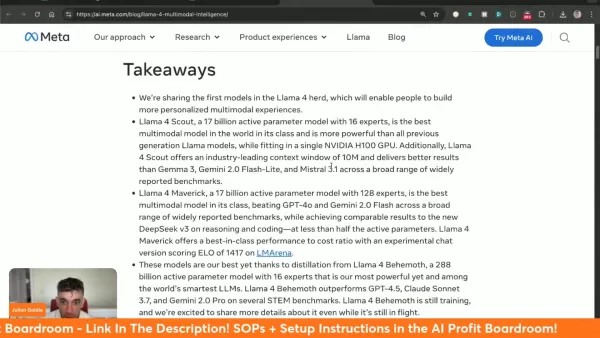
Llama 4 de Meta representa un salto cuántico en la tecnología de IA multimodal, introduciendo capacidades sin precedentes que remodelan lo que es posible en inteligencia artificial. Con su tríada de modelos especializados, su procesamiento contextual ampliado y su rendimiento que desafía los estándares de referencia, esta última iteración establece nuevos estándares para el desarrollo y la implementación de la IA.
Puntos clave
Tres variantes especializadas de Llama 4: Behemoth (entrenamiento), Maverick y Scout
El modelo Scout incorpora una revolucionaria ventana de contexto de 10 millones de tokens
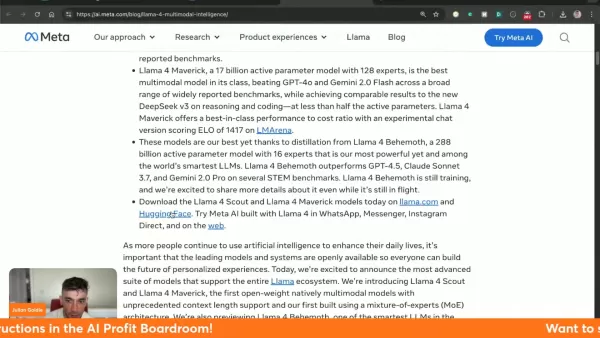
Maverick supera a competidores como Gemini 2.0 Flash y GPT-4o
Disponible a través de las plataformas llama.com y Hugging Face
Demuestra un rendimiento superior en las pruebas de referencia clave: procesamiento visual, codificación y razonamiento complejo
Integrado en los servicios MetaAI dentro de WhatsApp, Messenger e Instagram
Llama 4: el último avance de Meta en IA
¿Qué es Llama 4?
Llama 4 constituye el sistema de IA multimodal más avanzado de Meta hasta la fecha, combinando el procesamiento textual y visual en una arquitectura unificada. Esta tecnología de última generación ofrece una eficacia inigualable en diversas aplicaciones, con tres modelos distintos que ofrecen capacidades especializadas.
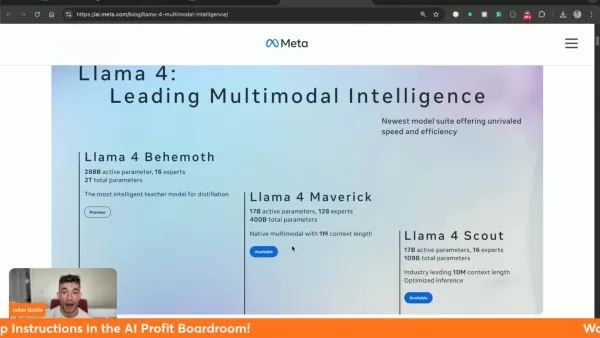
La innovadora gestión del contexto del sistema aborda las limitaciones anteriores, permitiendo una interpretación matizada de entradas complejas. Especialmente revolucionaria es la capacidad de 10 millones de tokens de Scout, que permite un análisis exhaustivo de grandes conjuntos de datos manteniendo la coherencia.
Meta facilita una amplia accesibilidad a través de llama.com y Hugging Face, fomentando la innovación de los desarrolladores al tiempo que integra Llama 4 en sus plataformas sociales insignia.
Comparación de Llama 4 Scout con otros modelos
Llama 4 Scout frente a la competencia: Un análisis comparativo
Llama 4 Scout establece nuevos estándares de rendimiento frente a los líderes del sector:
Benchmark Llama 4 Scout Gemma 3 27B Mistral 3.1 24B Gemini 2.0 Flash-Lite Razonamiento por imágenes (MMMU) 69.4 64.9 62.8 68.0 MathVista 70.7 67.6 68.9 57.6 Comprensión de imágenes (ChartQA) 88.8 76.3 86.2 73.0 DocVQA (prueba) 94.4 90.4 94.1 91.2 Codificación (LiveCodeBench) 32.8 29.7 - 28.9 Razonamiento y conocimiento (MMLU Pro) 74.3 67.5 66.8 71.6
El modelo destaca especialmente en el análisis de documentos (puntuación de 94,4 DocVQA) y en la interpretación de datos visuales (88,8 ChartQA), al tiempo que mantiene un rendimiento competitivo en todas las categorías evaluadas.
Cómo empezar con Llama 4
Acceso e implementación de Llama 4 en sus proyectos
Comience a explorar las capacidades de Llama 4 siguiendo estos pasos:
- Acceso a la plataforma: Visite los canales de distribución oficiales en llama.com o Hugging Face
- Selección del modelo: Elija entre las versiones disponibles en función de los requisitos del proyecto (tenga en cuenta que Behemoth sigue en desarrollo)
- Integración del sistema: Siga la documentación completa de Meta para la implementación
- Pruebas de rendimiento: Experimente con varias aplicaciones para optimizar los resultados
Análisis de costes de Llama 4
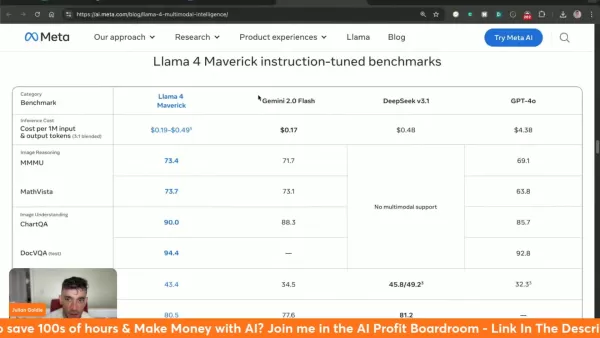
Comprender el coste de inferencia de Llama 4 Maverick
Llama 4 Maverick opera a entre 0,19 y 0,49 dólares por millón de tokens, lo que representa un valor significativo frente a otras alternativas:
- Gemini 2.0 Flash: ~0,17 $/millón de tokens
- deepseek v3.1: ~0,48 $/millón de tokens
- GPT-4o: ~4,38 $/millón de fichas
Sopesar los pros y los contras de Llama 4
Ventajas
Métricas de rendimiento líderes de referencia
Capacidad contextual sin precedentes de 10 millones de tokens
Accesible a través de las principales plataformas de IA
Verdadera arquitectura multimodal
Rentable en comparación con otras alternativas de gama alta
Contras
Modelo gigantesco aún en fase de formación
Elevados requisitos de recursos del sistema
Exploración de las características principales de Llama 4
Características principales de los modelos Llama 4
Llama 4 introduce varias innovaciones revolucionarias:
- Multimodalidad nativa: Procesamiento unificado de entradas de texto y visuales
- Capacidad contextual masiva: procesamiento de 10 millones de tokens en el modelo Scout.
- Liderazgo en rendimiento: Supera a GPT-4o/Gemini 2.0 en múltiples categorías
- Accesibilidad abierta: Disponible a través de llama.com y Hugging Face
- Eficiencia arquitectónica: El diseño de Mezcla de Expertos (MoE) optimiza los recursos informáticos
Diversos casos de uso de Llama 4
Aplicaciones potenciales de Llama 4 en diversas industrias
Las capacidades avanzadas de Llama 4 permiten aplicaciones transformadoras:
- Experiencia del cliente: Interacciones de chatbot mejoradas utilizando memoria de contexto ampliada
- Generación de contenidos: Producción automatizada de contenidos de alta calidad
- Inteligencia empresarial: Reconocimiento y análisis avanzados de patrones de datos
- Herramientas para desarrolladores: Asistencia y depuración de código mediante IA
- Plataformas sociales: Integración en los servicios de mensajería de Meta para mejorar las interacciones con la IA
Preguntas más frecuentes
¿Dónde puedo acceder a Llama 4?
Disponible a través de llama.com y Hugging Face, con integración en las plataformas sociales de Meta.
¿Cuál es el tamaño de la ventana contextual de Llama 4 Scout?
Scout cuenta con una capacidad líder en el sector de 10 millones de tokens para una comprensión exhaustiva del contexto.
¿Cuál es el rendimiento de Llama 4 en comparación con otros modelos?
Demuestra capacidades superiores a través de múltiples puntos de referencia frente a los principales competidores.
¿Qué es Meta AI?
La implementación de IA de Meta ahora impulsada por Llama 4 en WhatsApp, Messenger e Instagram.
Preguntas relacionadas
¿Cuáles son los diferentes modelos disponibles en Llama 4?
Tres modelos especializados: Behemoth (modelo de formación/enseñanza), Maverick (multimodal de 1M de contexto) y Scout (especialista de 10M de contexto).
¿Cómo mejora el rendimiento de Llama 4 la arquitectura de Mezcla de Expertos (MoE)?
Optimiza la eficiencia computacional al tiempo que mantiene la calidad de los resultados mediante subredes especializadas.
¿Dónde puedo consultar las pruebas comparativas ajustadas a las instrucciones para cada modelo de Llama 4?
Comparaciones exhaustivas disponibles con GPT-4o, Gemini 2.0 Flash y otros modelos líderes.
Artículo relacionado
 Un estudio antropológico relaciona el contenido generado por IA con una disminución del pensamiento humano
Cuando ves que la IA genera al instante un código o un documento bien estructurado y lógicamente claro, ¿te sientes tentado a confiar en él sin pensarlo dos veces? Según AIbase, la empresa líder en IA
Los ministerios del Gobierno británico discrepan sobre las necesidades energéticas de los centros de datos de IA
El Gobierno del Reino Unido se enfrenta a un gran reto: impulsar las energías limpias al tiempo que aspira a convertirse en líder mundial en inteligencia artificial. Sin embargo, se observan graves di
La Administración del Ciberespacio de China exige el etiquetado de los vídeos cortos generados por IA y de ficción
La Administración del Ciberespacio de China ha puesto en marcha un plan integral para normalizar el etiquetado de los contenidos de vídeos cortos, exigiendo a las plataformas que incluyan seis etiquet
Recomendaciones de temas especiales relacionados
Creación de cómics
Un estudio antropológico relaciona el contenido generado por IA con una disminución del pensamiento humano
Cuando ves que la IA genera al instante un código o un documento bien estructurado y lógicamente claro, ¿te sientes tentado a confiar en él sin pensarlo dos veces? Según AIbase, la empresa líder en IA
Los ministerios del Gobierno británico discrepan sobre las necesidades energéticas de los centros de datos de IA
El Gobierno del Reino Unido se enfrenta a un gran reto: impulsar las energías limpias al tiempo que aspira a convertirse en líder mundial en inteligencia artificial. Sin embargo, se observan graves di
La Administración del Ciberespacio de China exige el etiquetado de los vídeos cortos generados por IA y de ficción
La Administración del Ciberespacio de China ha puesto en marcha un plan integral para normalizar el etiquetado de los contenidos de vídeos cortos, exigiendo a las plataformas que incluyan seis etiquet
Recomendaciones de temas especiales relacionados
Creación de cómics
 Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
 10 herramientas
10 herramientas
 xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai
Negocio
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai
Texto a voz
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

 comentario (1)
0/500
comentario (1)
0/500
![CharlesYoung]()
C'est fou à quel point l'IA multimodale progresse vite ! 🤯 Mais je me demande si Meta va partager ces modèles en open-source comme avant, ou si la concurrence avec OpenAI les pousse à garder leurs cartes cachées...
Llama 4 de Meta representa un salto cuántico en la tecnología de IA multimodal, introduciendo capacidades sin precedentes que remodelan lo que es posible en inteligencia artificial. Con su tríada de modelos especializados, su procesamiento contextual ampliado y su rendimiento que desafía los estándares de referencia, esta última iteración establece nuevos estándares para el desarrollo y la implementación de la IA.
Puntos clave
Tres variantes especializadas de Llama 4: Behemoth (entrenamiento), Maverick y Scout
El modelo Scout incorpora una revolucionaria ventana de contexto de 10 millones de tokens
Maverick supera a competidores como Gemini 2.0 Flash y GPT-4o
Disponible a través de las plataformas llama.com y Hugging Face
Demuestra un rendimiento superior en las pruebas de referencia clave: procesamiento visual, codificación y razonamiento complejo
Integrado en los servicios MetaAI dentro de WhatsApp, Messenger e Instagram
Llama 4: el último avance de Meta en IA
¿Qué es Llama 4?
Llama 4 constituye el sistema de IA multimodal más avanzado de Meta hasta la fecha, combinando el procesamiento textual y visual en una arquitectura unificada. Esta tecnología de última generación ofrece una eficacia inigualable en diversas aplicaciones, con tres modelos distintos que ofrecen capacidades especializadas.
La innovadora gestión del contexto del sistema aborda las limitaciones anteriores, permitiendo una interpretación matizada de entradas complejas. Especialmente revolucionaria es la capacidad de 10 millones de tokens de Scout, que permite un análisis exhaustivo de grandes conjuntos de datos manteniendo la coherencia.
Meta facilita una amplia accesibilidad a través de llama.com y Hugging Face, fomentando la innovación de los desarrolladores al tiempo que integra Llama 4 en sus plataformas sociales insignia.
Comparación de Llama 4 Scout con otros modelos
Llama 4 Scout frente a la competencia: Un análisis comparativo
Llama 4 Scout establece nuevos estándares de rendimiento frente a los líderes del sector:
| Benchmark | Llama 4 Scout | Gemma 3 27B | Mistral 3.1 24B | Gemini 2.0 Flash-Lite |
|---|---|---|---|---|
| Razonamiento por imágenes (MMMU) | 69.4 | 64.9 | 62.8 | 68.0 |
| MathVista | 70.7 | 67.6 | 68.9 | 57.6 |
| Comprensión de imágenes (ChartQA) | 88.8 | 76.3 | 86.2 | 73.0 |
| DocVQA (prueba) | 94.4 | 90.4 | 94.1 | 91.2 |
| Codificación (LiveCodeBench) | 32.8 | 29.7 | - | 28.9 |
| Razonamiento y conocimiento (MMLU Pro) | 74.3 | 67.5 | 66.8 | 71.6 |
El modelo destaca especialmente en el análisis de documentos (puntuación de 94,4 DocVQA) y en la interpretación de datos visuales (88,8 ChartQA), al tiempo que mantiene un rendimiento competitivo en todas las categorías evaluadas.
Cómo empezar con Llama 4
Acceso e implementación de Llama 4 en sus proyectos
Comience a explorar las capacidades de Llama 4 siguiendo estos pasos:
- Acceso a la plataforma: Visite los canales de distribución oficiales en llama.com o Hugging Face
- Selección del modelo: Elija entre las versiones disponibles en función de los requisitos del proyecto (tenga en cuenta que Behemoth sigue en desarrollo)
- Integración del sistema: Siga la documentación completa de Meta para la implementación
- Pruebas de rendimiento: Experimente con varias aplicaciones para optimizar los resultados
Análisis de costes de Llama 4
Comprender el coste de inferencia de Llama 4 Maverick
Llama 4 Maverick opera a entre 0,19 y 0,49 dólares por millón de tokens, lo que representa un valor significativo frente a otras alternativas:
- Gemini 2.0 Flash: ~0,17 $/millón de tokens
- deepseek v3.1: ~0,48 $/millón de tokens
- GPT-4o: ~4,38 $/millón de fichas
Sopesar los pros y los contras de Llama 4
Ventajas
Métricas de rendimiento líderes de referencia
Capacidad contextual sin precedentes de 10 millones de tokens
Accesible a través de las principales plataformas de IA
Verdadera arquitectura multimodal
Rentable en comparación con otras alternativas de gama alta
Contras
Modelo gigantesco aún en fase de formación
Elevados requisitos de recursos del sistema
Exploración de las características principales de Llama 4
Características principales de los modelos Llama 4
Llama 4 introduce varias innovaciones revolucionarias:
- Multimodalidad nativa: Procesamiento unificado de entradas de texto y visuales
- Capacidad contextual masiva: procesamiento de 10 millones de tokens en el modelo Scout.
- Liderazgo en rendimiento: Supera a GPT-4o/Gemini 2.0 en múltiples categorías
- Accesibilidad abierta: Disponible a través de llama.com y Hugging Face
- Eficiencia arquitectónica: El diseño de Mezcla de Expertos (MoE) optimiza los recursos informáticos
Diversos casos de uso de Llama 4
Aplicaciones potenciales de Llama 4 en diversas industrias
Las capacidades avanzadas de Llama 4 permiten aplicaciones transformadoras:
- Experiencia del cliente: Interacciones de chatbot mejoradas utilizando memoria de contexto ampliada
- Generación de contenidos: Producción automatizada de contenidos de alta calidad
- Inteligencia empresarial: Reconocimiento y análisis avanzados de patrones de datos
- Herramientas para desarrolladores: Asistencia y depuración de código mediante IA
- Plataformas sociales: Integración en los servicios de mensajería de Meta para mejorar las interacciones con la IA
Preguntas más frecuentes
¿Dónde puedo acceder a Llama 4?
Disponible a través de llama.com y Hugging Face, con integración en las plataformas sociales de Meta.
¿Cuál es el tamaño de la ventana contextual de Llama 4 Scout?
Scout cuenta con una capacidad líder en el sector de 10 millones de tokens para una comprensión exhaustiva del contexto.
¿Cuál es el rendimiento de Llama 4 en comparación con otros modelos?
Demuestra capacidades superiores a través de múltiples puntos de referencia frente a los principales competidores.
¿Qué es Meta AI?
La implementación de IA de Meta ahora impulsada por Llama 4 en WhatsApp, Messenger e Instagram.
Preguntas relacionadas
¿Cuáles son los diferentes modelos disponibles en Llama 4?
Tres modelos especializados: Behemoth (modelo de formación/enseñanza), Maverick (multimodal de 1M de contexto) y Scout (especialista de 10M de contexto).
¿Cómo mejora el rendimiento de Llama 4 la arquitectura de Mezcla de Expertos (MoE)?
Optimiza la eficiencia computacional al tiempo que mantiene la calidad de los resultados mediante subredes especializadas.
¿Dónde puedo consultar las pruebas comparativas ajustadas a las instrucciones para cada modelo de Llama 4?
Comparaciones exhaustivas disponibles con GPT-4o, Gemini 2.0 Flash y otros modelos líderes.










 Un estudio antropológico relaciona el contenido generado por IA con una disminución del pensamiento humano
Cuando ves que la IA genera al instante un código o un documento bien estructurado y lógicamente claro, ¿te sientes tentado a confiar en él sin pensarlo dos veces? Según AIbase, la empresa líder en IA
Un estudio antropológico relaciona el contenido generado por IA con una disminución del pensamiento humano
Cuando ves que la IA genera al instante un código o un documento bien estructurado y lógicamente claro, ¿te sientes tentado a confiar en él sin pensarlo dos veces? Según AIbase, la empresa líder en IA
 Los ministerios del Gobierno británico discrepan sobre las necesidades energéticas de los centros de datos de IA
El Gobierno del Reino Unido se enfrenta a un gran reto: impulsar las energías limpias al tiempo que aspira a convertirse en líder mundial en inteligencia artificial. Sin embargo, se observan graves di
Los ministerios del Gobierno británico discrepan sobre las necesidades energéticas de los centros de datos de IA
El Gobierno del Reino Unido se enfrenta a un gran reto: impulsar las energías limpias al tiempo que aspira a convertirse en líder mundial en inteligencia artificial. Sin embargo, se observan graves di
 La Administración del Ciberespacio de China exige el etiquetado de los vídeos cortos generados por IA y de ficción
La Administración del Ciberespacio de China ha puesto en marcha un plan integral para normalizar el etiquetado de los contenidos de vídeos cortos, exigiendo a las plataformas que incluyan seis etiquet
La Administración del Ciberespacio de China exige el etiquetado de los vídeos cortos generados por IA y de ficción
La Administración del Ciberespacio de China ha puesto en marcha un plan integral para normalizar el etiquetado de los contenidos de vídeos cortos, exigiendo a las plataformas que incluyan seis etiquet

Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai

Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

C'est fou à quel point l'IA multimodale progresse vite ! 🤯 Mais je me demande si Meta va partager ces modèles en open-source comme avant, ou si la concurrence avec OpenAI les pousse à garder leurs cartes cachées...













