
















 首頁
首頁Meta 發表 Llama 4:開創下一世代多模式人工智慧能力
Meta 的 Llama 4 代表著多模態人工智慧技術的一大躍進,引進了前所未有的功能,重塑了人工智慧的可能性。憑藉其三重專門模型、擴充的情境處理功能以及打破基準的效能,最新的迭代版本為人工智慧的開發與實作建立了新的標準。
重點
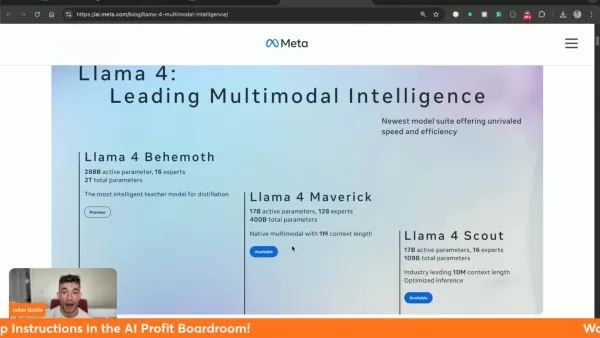
三種專門的 Llama 4 變體:Behemoth (訓練)、Maverick 及 Scout
Scout 機型具有革命性的 1,000 萬個代幣上下文視窗
Maverick 優於 Gemini 2.0 Flash 和 GPT-4o 等競爭對手。
可透過 llama.com 和 Hugging Face 平台購買
在視覺處理、編碼和複雜推理等關鍵基準上表現優異
整合至 WhatsApp、Messenger 和 Instagram 內的 MetaAI 服務
了解 Llama 4:Meta 最新的人工智能突破
什麼是 Llama 4?
Llama 4 是 Meta 迄今為止最先進的多模態 AI 系統,在統一的架構中結合了文字和視覺處理。這項新世代的技術可在各種應用程式中提供無與倫比的效率,並有三種不同的模型可提供專門的功能。
該系統突破性的上下文處理功能解決了以往的限制,能夠對複雜的輸入進行細微的詮釋。特別具有革命性的是 Scout 的 10M 記憶體容量,允許在保持連貫性的情況下全面分析大量資料集。
Meta 透過 llama.com 和 Hugging Face 促進了廣泛的可及性,鼓勵開發人員創新,同時將 Llama 4 整合到其旗艦社交平台中。
Llama 4 Scout 與其他機型的比較
Llama 4 Scout 與競爭對手的比較:基準分析
Llama 4 Scout 針對業界領導者建立新的效能標準:
基準 Llama 4 Scout Gemma 3 27B Mistral 3.1 24B Gemini 2.0 Flash-Lite 圖像推理 (MMMU) 69.4 64.9 62.8 68.0 MathVista 70.7 67.6 68.9 57.6 圖像理解 (ChartQA) 88.8 76.3 86.2 73.0 DocVQA (測試) 94.4 90.4 94.1 91.2 編碼 (LiveCodeBench) 32.8 29.7 - 28.9 推理與知識 (MMLU Pro) 74.3 67.5 66.8 71.6
本模型在文件分析 (94.4 分 DocVQA) 和視覺資料詮釋 (88.8 分 ChartQA) 方面尤其出色,同時在所有測試類別中均保持競爭力。
如何開始使用 Llama 4
在您的專案中存取並實作 Llama 4
透過以下步驟開始探索 Llama 4 的功能:
- 平台存取:訪問官方分銷渠道 llama.com 或 Hugging Face
- 模型選擇:根據專案需求選擇可用版本 (注意 Behemoth 仍在開發中)
- 系統整合:依照 Meta 的完整說明文件執行
- 效能測試:使用各種應用程式進行實驗,以優化結果
Llama 4 成本分析
瞭解 Llama 4 Maverick 的推論成本
Llama 4 Maverick 以每百萬個代幣 0.19 美元至 0.49 美元的價格運作,相較於其他替代方案,呈現顯著的價值:
- Gemini 2.0 Flash:~0.17 美元/百萬代用幣
- deepseek v3.1: ~$0.48/百萬代用幣
- GPT-4o:~$4.38/million 代幣
權衡 Llama 4 的利弊
優點
領先基準的效能指標
史無前例的 1000 萬代用幣容量
可透過主要的人工智能平台存取
真正的多模式架構
相較於其他優質產品更具成本效益
缺點
巨型模型仍在訓練階段
系統資源需求高
探索 Llama 4 的核心功能
Llama 4 機型的主要特色
Llama 4 引入了多項突破性創新:
- 原生多模態:統一處理文字和視覺輸入
- 龐大的上下文容量:在 Scout 模型中處理 10M 記憶體
- 性能領先:在多個領域超越 GPT-4o/Gemini 2.0
- 開放存取:透過 llama.com 和 Hugging Face 提供
- 架構效率:專家混合 (MoE) 設計可最佳化運算資源
Llama 4 的多樣化使用案例
Llama 4 在各行各業的潛在應用
Llama 4 的先進功能可實現轉型應用:
- 客戶體驗:使用延伸的情境記憶加強聊天機器人互動
- 內容製作:高品質的自動化內容製作
- 商業智慧:進階資料模式識別與分析
- 開發人員工具:AI 驅動的編碼協助與除錯
- 社交平台:整合至 Meta 的訊息服務,以改善 AI 互動
常見問題
在哪裡可以取得 Llama 4?
可透過 llama.com 和 Hugging Face 取得,並整合至 Meta 的社交平台。
Llama 4 Scout 的情境視窗大小為何?
Scout 具備領先業界的 1,000 萬個代幣容量,可提供全面的情境瞭解。
與其他機型相比,Llama 4 的表現如何?
在與領先競爭對手的多項基準比較中,表現出卓越的能力。
Meta AI 是什麼?
Meta 的 AI 實作目前由 Llama 4 在 WhatsApp、Messenger 和 Instagram 上支援。
相關問題
Llama 4 有哪些不同的模式?
三種專業模型:Behemoth (訓練/教師模型)、Maverick (1M context multimodal) 和 Scout (10M context specialist)。
專家混合 (MoE) 架構如何提升 Llama 4 的效能?
透過專門的子網路,在維持輸出品質的同時,優化計算效率。
在哪裡可以檢視每個 Llama 4 機型的指令調整基準?
可與 GPT-4o、Gemini 2.0 Flash 及其他領先機型進行全面比較。
相關文章
 百度健康內部測試 AI 醫生助理「DoctorClaw」,短期內將用於學術資料檢索與辦公室輔助
據報導,百度健康已開始對一款專為醫師設計的專業 AI 智慧助理進行內部測試。這款內部代號為「DoctorClaw」(龍蝦醫生版)的產品,標誌著百度在醫療領域部署大型語言模型方面邁出了重要一步。知情人士透露,該專案目前仍處於封閉開發階段,現已進入內部測試。雖然具體產品形式尚未完全公開,但已接近推出。 就功能而言,DoctorClaw 初期將聚焦於學術文獻檢索與常規診間輔助。然而,其長期戰略旨在深度融
《Cursor Composer 2》對決《Claude Opus 4.6》:效能測試引發新一輪 AI 程式設計辯論
3月19日,Cursor 正式發布其自主研發的編碼模型 Composer 2。 這項公告在開發者社群中立即引發熱議——根據 Cursor 的說法,Composer 2 在 Terminal-Bench 2.0 上的得分為 61.7%,在相同的測試條件下,顯著超越了 Claude Opus 4.6 的 58.0%。Anthropic 的旗艦模型,竟被自家 IDE 內建的模型超越?隨著消息傳開,相關辯
StrictlyVC 舊金山站將匯聚 TDK Ventures、Replit 等企業的領導者
今年首場 StrictlyVC 活動即將在舊金山登場,時間比你想像的還要快。 4月30日於菲律賓文化中心(Sentro Filipino Cultural Center)舉辦的聚會門票現仍開放購買,現場將有陣容強大的講者陣容。除了StrictlyVC一貫以人脈拓展與社群互動著稱外,這場舊金山活動對於尋求最新募資洞見的人工智慧創新者與創辦人而言,將具有特別的價值。誰將登上舞台門票現已開售,但若您尚未
相關專題推薦
寫作
百度健康內部測試 AI 醫生助理「DoctorClaw」,短期內將用於學術資料檢索與辦公室輔助
據報導,百度健康已開始對一款專為醫師設計的專業 AI 智慧助理進行內部測試。這款內部代號為「DoctorClaw」(龍蝦醫生版)的產品,標誌著百度在醫療領域部署大型語言模型方面邁出了重要一步。知情人士透露,該專案目前仍處於封閉開發階段,現已進入內部測試。雖然具體產品形式尚未完全公開,但已接近推出。 就功能而言,DoctorClaw 初期將聚焦於學術文獻檢索與常規診間輔助。然而,其長期戰略旨在深度融
《Cursor Composer 2》對決《Claude Opus 4.6》:效能測試引發新一輪 AI 程式設計辯論
3月19日,Cursor 正式發布其自主研發的編碼模型 Composer 2。 這項公告在開發者社群中立即引發熱議——根據 Cursor 的說法,Composer 2 在 Terminal-Bench 2.0 上的得分為 61.7%,在相同的測試條件下,顯著超越了 Claude Opus 4.6 的 58.0%。Anthropic 的旗艦模型,竟被自家 IDE 內建的模型超越?隨著消息傳開,相關辯
StrictlyVC 舊金山站將匯聚 TDK Ventures、Replit 等企業的領導者
今年首場 StrictlyVC 活動即將在舊金山登場,時間比你想像的還要快。 4月30日於菲律賓文化中心(Sentro Filipino Cultural Center)舉辦的聚會門票現仍開放購買,現場將有陣容強大的講者陣容。除了StrictlyVC一貫以人脈拓展與社群互動著稱外,這場舊金山活動對於尋求最新募資洞見的人工智慧創新者與創辦人而言,將具有特別的價值。誰將登上舞台門票現已開售,但若您尚未
相關專題推薦
寫作
 最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
 10 個工具
10 個工具
 xix.ai
商業
最佳 AI 合約審查軟體:即時發現法律漏洞與合規風險
xix.ai
商業
最佳 AI 合約審查軟體:即時發現法律漏洞與合規風險
立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai
動畫創作
專為東華設計的AI動漫生成器:可用於建立網路小說角色及漫畫頭像
探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai
漫畫創作
漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

 評論 (1)
0/500
評論 (1)
0/500
![CharlesYoung]()
C'est fou à quel point l'IA multimodale progresse vite ! 🤯 Mais je me demande si Meta va partager ces modèles en open-source comme avant, ou si la concurrence avec OpenAI les pousse à garder leurs cartes cachées...
Meta 的 Llama 4 代表著多模態人工智慧技術的一大躍進,引進了前所未有的功能,重塑了人工智慧的可能性。憑藉其三重專門模型、擴充的情境處理功能以及打破基準的效能,最新的迭代版本為人工智慧的開發與實作建立了新的標準。
重點
三種專門的 Llama 4 變體:Behemoth (訓練)、Maverick 及 Scout
Scout 機型具有革命性的 1,000 萬個代幣上下文視窗
Maverick 優於 Gemini 2.0 Flash 和 GPT-4o 等競爭對手。
可透過 llama.com 和 Hugging Face 平台購買
在視覺處理、編碼和複雜推理等關鍵基準上表現優異
整合至 WhatsApp、Messenger 和 Instagram 內的 MetaAI 服務
了解 Llama 4:Meta 最新的人工智能突破
什麼是 Llama 4?
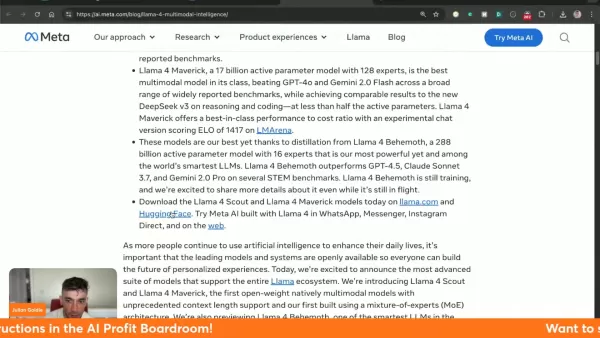
Llama 4 是 Meta 迄今為止最先進的多模態 AI 系統,在統一的架構中結合了文字和視覺處理。這項新世代的技術可在各種應用程式中提供無與倫比的效率,並有三種不同的模型可提供專門的功能。
該系統突破性的上下文處理功能解決了以往的限制,能夠對複雜的輸入進行細微的詮釋。特別具有革命性的是 Scout 的 10M 記憶體容量,允許在保持連貫性的情況下全面分析大量資料集。
Meta 透過 llama.com 和 Hugging Face 促進了廣泛的可及性,鼓勵開發人員創新,同時將 Llama 4 整合到其旗艦社交平台中。
Llama 4 Scout 與其他機型的比較
Llama 4 Scout 與競爭對手的比較:基準分析
Llama 4 Scout 針對業界領導者建立新的效能標準:
| 基準 | Llama 4 Scout | Gemma 3 27B | Mistral 3.1 24B | Gemini 2.0 Flash-Lite |
|---|---|---|---|---|
| 圖像推理 (MMMU) | 69.4 | 64.9 | 62.8 | 68.0 |
| MathVista | 70.7 | 67.6 | 68.9 | 57.6 |
| 圖像理解 (ChartQA) | 88.8 | 76.3 | 86.2 | 73.0 |
| DocVQA (測試) | 94.4 | 90.4 | 94.1 | 91.2 |
| 編碼 (LiveCodeBench) | 32.8 | 29.7 | - | 28.9 |
| 推理與知識 (MMLU Pro) | 74.3 | 67.5 | 66.8 | 71.6 |
本模型在文件分析 (94.4 分 DocVQA) 和視覺資料詮釋 (88.8 分 ChartQA) 方面尤其出色,同時在所有測試類別中均保持競爭力。
如何開始使用 Llama 4
在您的專案中存取並實作 Llama 4
透過以下步驟開始探索 Llama 4 的功能:
- 平台存取:訪問官方分銷渠道 llama.com 或 Hugging Face
- 模型選擇:根據專案需求選擇可用版本 (注意 Behemoth 仍在開發中)
- 系統整合:依照 Meta 的完整說明文件執行
- 效能測試:使用各種應用程式進行實驗,以優化結果
Llama 4 成本分析
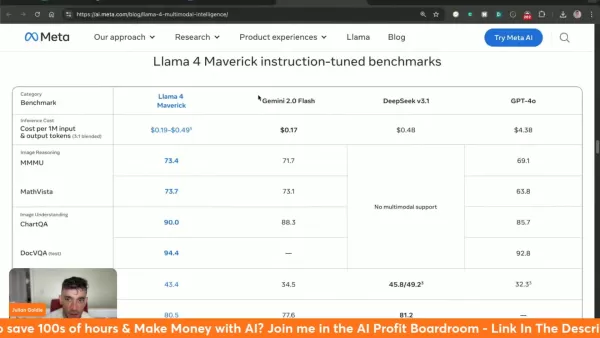
瞭解 Llama 4 Maverick 的推論成本
Llama 4 Maverick 以每百萬個代幣 0.19 美元至 0.49 美元的價格運作,相較於其他替代方案,呈現顯著的價值:
- Gemini 2.0 Flash:~0.17 美元/百萬代用幣
- deepseek v3.1: ~$0.48/百萬代用幣
- GPT-4o:~$4.38/million 代幣
權衡 Llama 4 的利弊
優點
領先基準的效能指標
史無前例的 1000 萬代用幣容量
可透過主要的人工智能平台存取
真正的多模式架構
相較於其他優質產品更具成本效益
缺點
巨型模型仍在訓練階段
系統資源需求高
探索 Llama 4 的核心功能
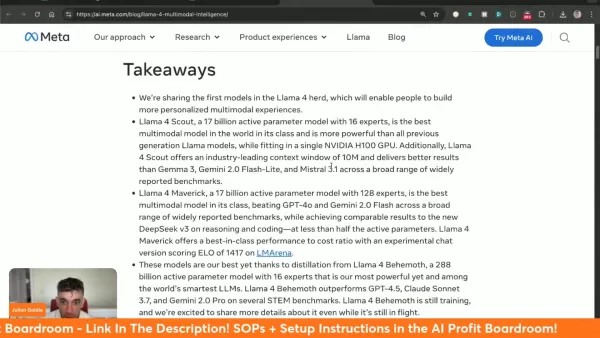
Llama 4 機型的主要特色
Llama 4 引入了多項突破性創新:
- 原生多模態:統一處理文字和視覺輸入
- 龐大的上下文容量:在 Scout 模型中處理 10M 記憶體
- 性能領先:在多個領域超越 GPT-4o/Gemini 2.0
- 開放存取:透過 llama.com 和 Hugging Face 提供
- 架構效率:專家混合 (MoE) 設計可最佳化運算資源
Llama 4 的多樣化使用案例
Llama 4 在各行各業的潛在應用
Llama 4 的先進功能可實現轉型應用:
- 客戶體驗:使用延伸的情境記憶加強聊天機器人互動
- 內容製作:高品質的自動化內容製作
- 商業智慧:進階資料模式識別與分析
- 開發人員工具:AI 驅動的編碼協助與除錯
- 社交平台:整合至 Meta 的訊息服務,以改善 AI 互動
常見問題
在哪裡可以取得 Llama 4?
可透過 llama.com 和 Hugging Face 取得,並整合至 Meta 的社交平台。
Llama 4 Scout 的情境視窗大小為何?
Scout 具備領先業界的 1,000 萬個代幣容量,可提供全面的情境瞭解。
與其他機型相比,Llama 4 的表現如何?
在與領先競爭對手的多項基準比較中,表現出卓越的能力。
Meta AI 是什麼?
Meta 的 AI 實作目前由 Llama 4 在 WhatsApp、Messenger 和 Instagram 上支援。
相關問題
Llama 4 有哪些不同的模式?
三種專業模型:Behemoth (訓練/教師模型)、Maverick (1M context multimodal) 和 Scout (10M context specialist)。
專家混合 (MoE) 架構如何提升 Llama 4 的效能?
透過專門的子網路,在維持輸出品質的同時,優化計算效率。
在哪裡可以檢視每個 Llama 4 機型的指令調整基準?
可與 GPT-4o、Gemini 2.0 Flash 及其他領先機型進行全面比較。










 百度健康內部測試 AI 醫生助理「DoctorClaw」,短期內將用於學術資料檢索與辦公室輔助
據報導,百度健康已開始對一款專為醫師設計的專業 AI 智慧助理進行內部測試。這款內部代號為「DoctorClaw」(龍蝦醫生版)的產品,標誌著百度在醫療領域部署大型語言模型方面邁出了重要一步。知情人士透露,該專案目前仍處於封閉開發階段,現已進入內部測試。雖然具體產品形式尚未完全公開,但已接近推出。 就功能而言,DoctorClaw 初期將聚焦於學術文獻檢索與常規診間輔助。然而,其長期戰略旨在深度融
百度健康內部測試 AI 醫生助理「DoctorClaw」,短期內將用於學術資料檢索與辦公室輔助
據報導,百度健康已開始對一款專為醫師設計的專業 AI 智慧助理進行內部測試。這款內部代號為「DoctorClaw」(龍蝦醫生版)的產品,標誌著百度在醫療領域部署大型語言模型方面邁出了重要一步。知情人士透露,該專案目前仍處於封閉開發階段,現已進入內部測試。雖然具體產品形式尚未完全公開,但已接近推出。 就功能而言,DoctorClaw 初期將聚焦於學術文獻檢索與常規診間輔助。然而,其長期戰略旨在深度融
 《Cursor Composer 2》對決《Claude Opus 4.6》:效能測試引發新一輪 AI 程式設計辯論
3月19日,Cursor 正式發布其自主研發的編碼模型 Composer 2。 這項公告在開發者社群中立即引發熱議——根據 Cursor 的說法,Composer 2 在 Terminal-Bench 2.0 上的得分為 61.7%,在相同的測試條件下,顯著超越了 Claude Opus 4.6 的 58.0%。Anthropic 的旗艦模型,竟被自家 IDE 內建的模型超越?隨著消息傳開,相關辯
《Cursor Composer 2》對決《Claude Opus 4.6》:效能測試引發新一輪 AI 程式設計辯論
3月19日,Cursor 正式發布其自主研發的編碼模型 Composer 2。 這項公告在開發者社群中立即引發熱議——根據 Cursor 的說法,Composer 2 在 Terminal-Bench 2.0 上的得分為 61.7%,在相同的測試條件下,顯著超越了 Claude Opus 4.6 的 58.0%。Anthropic 的旗艦模型,竟被自家 IDE 內建的模型超越?隨著消息傳開,相關辯
 StrictlyVC 舊金山站將匯聚 TDK Ventures、Replit 等企業的領導者
今年首場 StrictlyVC 活動即將在舊金山登場,時間比你想像的還要快。 4月30日於菲律賓文化中心(Sentro Filipino Cultural Center)舉辦的聚會門票現仍開放購買,現場將有陣容強大的講者陣容。除了StrictlyVC一貫以人脈拓展與社群互動著稱外,這場舊金山活動對於尋求最新募資洞見的人工智慧創新者與創辦人而言,將具有特別的價值。誰將登上舞台門票現已開售,但若您尚未
StrictlyVC 舊金山站將匯聚 TDK Ventures、Replit 等企業的領導者
今年首場 StrictlyVC 活動即將在舊金山登場,時間比你想像的還要快。 4月30日於菲律賓文化中心(Sentro Filipino Cultural Center)舉辦的聚會門票現仍開放購買,現場將有陣容強大的講者陣容。除了StrictlyVC一貫以人脈拓展與社群互動著稱外,這場舊金山活動對於尋求最新募資洞見的人工智慧創新者與創辦人而言,將具有特別的價值。誰將登上舞台門票現已開售,但若您尚未

在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai

探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

C'est fou à quel point l'IA multimodale progresse vite ! 🤯 Mais je me demande si Meta va partager ces modèles en open-source comme avant, ou si la concurrence avec OpenAI les pousse à garder leurs cartes cachées...













