
















 Lar
LarMeta revela Llama 4: pioneirismo em recursos de IA multimodal de última geração
O Llama 4 da Meta representa um salto quântico na tecnologia de IA multimodal, introduzindo recursos sem precedentes que remodelam o que é possível na inteligência artificial. Com sua tríade de modelos especializados, processamento de contexto expandido e desempenho que desafia os padrões de referência, essa última iteração estabelece novos padrões para o desenvolvimento e a implementação de IA.
Pontos principais
Três variantes especializadas do Llama 4: Behemoth (treinamento), Maverick e Scout
O modelo Scout apresenta a revolucionária janela de contexto de 10 milhões de tokens
O Maverick supera o desempenho dos concorrentes, incluindo o Gemini 2.0 Flash e o GPT-4o
Disponível nas plataformas llama.com e Hugging Face
Demonstra desempenho superior nos principais benchmarks - processamento visual, codificação e raciocínio complexo
Integrado aos serviços da MetaAI no WhatsApp, Messenger e Instagram
Entendendo a Llama 4: a mais recente inovação em IA da Meta
O que é a Llama 4?
O Llama 4 constitui o sistema de IA multimodal mais avançado da Meta até o momento, combinando texto e processamento visual em uma arquitetura unificada. Essa tecnologia de última geração proporciona uma eficiência inigualável em diversos aplicativos, com três modelos distintos que oferecem recursos especializados.
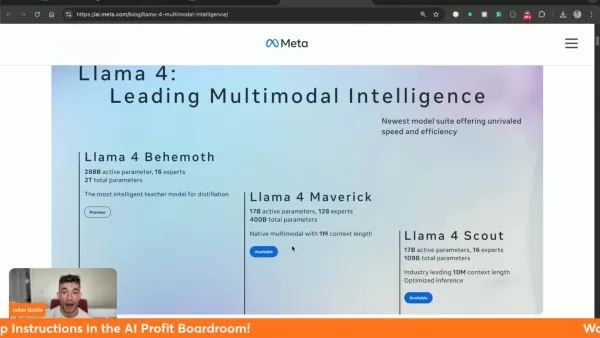
O inovador tratamento de contexto do sistema aborda as limitações anteriores, permitindo a interpretação diferenciada de entradas complexas. Particularmente revolucionária é a capacidade de 10 milhões de tokens do Scout, que permite a análise abrangente de conjuntos de dados extensos com coerência mantida.
O Meta facilita a ampla acessibilidade por meio do llama.com e do Hugging Face, incentivando a inovação do desenvolvedor e integrando a Llama 4 às suas principais plataformas sociais.
Comparação do Llama 4 Scout com outros modelos
Llama 4 Scout vs. Concorrentes: Uma análise de benchmark
A Llama 4 Scout estabelece novos padrões de desempenho em relação aos líderes do setor:
Benchmark Llama 4 Scout Gemma 3 27B Mistral 3.1 24B Gemini 2.0 Flash-Lite Raciocínio de imagem (MMMU) 69.4 64.9 62.8 68.0 MathVista 70.7 67.6 68.9 57.6 Compreensão de imagens (ChartQA) 88.8 76.3 86.2 73.0 DocVQA (teste) 94.4 90.4 94.1 91.2 Codificação (LiveCodeBench) 32.8 29.7 - 28.9 Raciocínio e conhecimento (MMLU Pro) 74.3 67.5 66.8 71.6
O modelo se destaca especialmente na análise de documentos (pontuação DocVQA de 94,4) e na interpretação de dados visuais (ChartQA de 88,8), mantendo um desempenho competitivo em todas as categorias testadas.
Como começar a usar a Llama 4
Acessando e implementando a Llama 4 em seus projetos
Comece a explorar os recursos da Llama 4 por meio destas etapas:
- Acesso à plataforma: Visite os canais de distribuição oficiais em llama.com ou Hugging Face
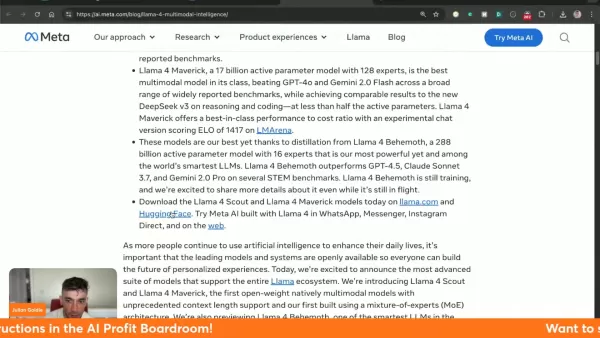
- Seleção do modelo: Escolha entre as versões disponíveis com base nos requisitos do projeto (observe que o Behemoth continua em desenvolvimento)
- Integração do sistema: Siga a documentação abrangente do Meta para implementação
- Teste de desempenho: Faça experiências com vários aplicativos para otimizar os resultados
Análise de custo da Llama 4
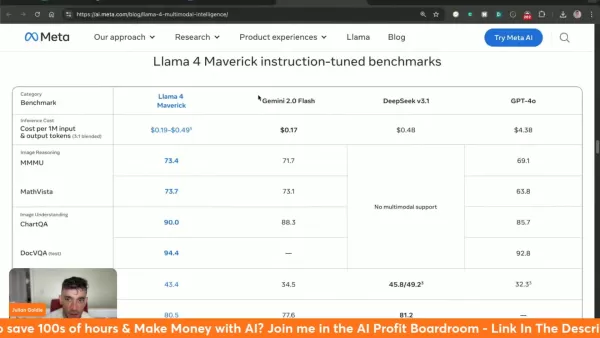
Entendendo o custo de inferência da Llama 4 Maverick
A Llama 4 Maverick opera a US$ 0,19 a US$ 0,49 por milhão de tokens, apresentando um valor significativo em relação às alternativas:
- Gemini 2.0 Flash: ~$ 0,17/milhão de tokens
- deepseek v3.1: ~$0,48/milhão de tokens
- GPT-4o: ~$4,38/milhão de tokens
Pesando os prós e contras da Llama 4
Prós
Métricas de desempenho líderes em benchmark
Capacidade sem precedentes de contexto de 10 milhões de tokens
Acessível por meio das principais plataformas de IA
Verdadeira arquitetura multimodal
Custo-benefício em comparação com alternativas premium
Contras
Modelo gigantesco ainda em fase de treinamento
Altos requisitos de recursos do sistema
Explorando os principais recursos da Llama 4
Principais recursos dos modelos da Llama 4
A Llama 4 apresenta várias inovações revolucionárias:
- Multimodalidade nativa: Processamento unificado de texto e entradas visuais
- Grande capacidade de contexto: processamento de 10 milhões de tokens no modelo Scout
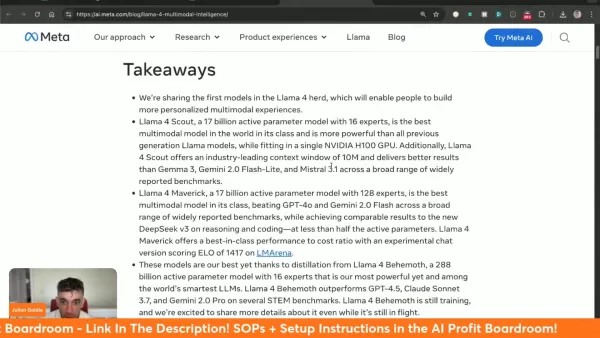
- Liderança em desempenho: Supera o GPT-4o/Gemini 2.0 em várias categorias
- Acessibilidade aberta: Disponível via llama.com e Hugging Face
- Eficiência arquitetônica: O projeto Mixture of Experts (MoE) otimiza os recursos de computação
Diversos casos de uso da Llama 4
Aplicações potenciais da Llama 4 em vários setores
Os recursos avançados da Llama 4 permitem aplicativos transformadores:
- Experiência do cliente: Interações aprimoradas do chatbot usando memória de contexto estendida
- Geração de conteúdo: Produção de conteúdo automatizado de alta qualidade
- Inteligência comercial: Reconhecimento e análise avançados de padrões de dados
- Ferramentas para desenvolvedores: Assistência e depuração de codificação com tecnologia de IA
- Plataformas sociais: Integrado aos serviços de mensagens do Meta para melhorar as interações com IA
Perguntas frequentes
Onde posso acessar a Llama 4?
Disponível em llama.com e Hugging Face, com integração às plataformas sociais da Meta.
Qual é o tamanho da janela de contexto do Llama 4 Scout?
O Scout apresenta uma capacidade de 10 milhões de tokens, líder do setor, para uma compreensão abrangente do contexto.
Qual é o desempenho da Llama 4 em comparação com outros modelos?
Demonstra recursos superiores em vários benchmarks em relação aos principais concorrentes.
O que é o Meta AI?
A implementação de IA da Meta agora é alimentada pela Llama 4 no WhatsApp, Messenger e Instagram.
Perguntas relacionadas
Quais são os diferentes modelos disponíveis na Llama 4?
Três modelos especializados: Behemoth (modelo de treinamento/professor), Maverick (contexto multimodal de 1 milhão) e Scout (especialista em contexto de 10 milhões).
Como a arquitetura Mixture of Experts (MoE) melhora o desempenho da Llama 4?
Otimiza a eficiência computacional e mantém a qualidade da saída por meio de sub-redes especializadas.
Onde posso ver os benchmarks ajustados por instrução para cada modelo da Llama 4?
Comparações abrangentes disponíveis em relação ao GPT-4o, Gemini 2.0 Flash e outros modelos líderes.
Artigo relacionado
 A Administração do Ciberespaço da China exige a identificação de vídeos curtos gerados por IA e de ficção
A Administração do Ciberespaço da China lançou um plano abrangente para padronizar a rotulagem de conteúdos de vídeos curtos, exigindo que as plataformas ofereçam seis rótulos obrigatórios — incluindo
O DeepL, conhecido pela tradução de textos, agora se volta para a tradução de voz
A DeepL, empresa de tradução mais conhecida por suas ferramentas baseadas em texto, lançou hoje um pacote de tradução de voz para voz voltado para cenários como reuniões, conversas em dispositivos móv
As anotações de reuniões da IA da Talat ficam armazenadas no seu dispositivo, e não na nuvem
O Granola, aplicativo de anotações com inteligência artificial avaliado em US$ 250 milhões, vem ganhando força entre fundadores de empresas de tecnologia e investidores de capital de risco. Mas um des
Recomendações de tópicos especiais relacionados
escrita
A Administração do Ciberespaço da China exige a identificação de vídeos curtos gerados por IA e de ficção
A Administração do Ciberespaço da China lançou um plano abrangente para padronizar a rotulagem de conteúdos de vídeos curtos, exigindo que as plataformas ofereçam seis rótulos obrigatórios — incluindo
O DeepL, conhecido pela tradução de textos, agora se volta para a tradução de voz
A DeepL, empresa de tradução mais conhecida por suas ferramentas baseadas em texto, lançou hoje um pacote de tradução de voz para voz voltado para cenários como reuniões, conversas em dispositivos móv
As anotações de reuniões da IA da Talat ficam armazenadas no seu dispositivo, e não na nuvem
O Granola, aplicativo de anotações com inteligência artificial avaliado em US$ 250 milhões, vem ganhando força entre fundadores de empresas de tecnologia e investidores de capital de risco. Mas um des
Recomendações de tópicos especiais relacionados
escrita
 Os melhores criadores de perfis de ficção com IA: gerar motivações consistentes para personagens e falhas fatais
Os melhores criadores de perfis de ficção com IA: gerar motivações consistentes para personagens e falhas fatais
Descubra os melhores criadores de perfis de ficção com IA de 2026 para criar personagens complexos. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias que geram motivações consistentes e falhas fatais. Compare as opções gratuitas com as pagas por meio de testes práticos. Liberte agora o seu potencial narrativo.
 10 ferramentas
10 ferramentas
 xix.ai
Negócios
Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
xix.ai
Negócios
Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai
código
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

 Comentários (1)
Comentários (1)
![CharlesYoung]()
C'est fou à quel point l'IA multimodale progresse vite ! 🤯 Mais je me demande si Meta va partager ces modèles en open-source comme avant, ou si la concurrence avec OpenAI les pousse à garder leurs cartes cachées...
O Llama 4 da Meta representa um salto quântico na tecnologia de IA multimodal, introduzindo recursos sem precedentes que remodelam o que é possível na inteligência artificial. Com sua tríade de modelos especializados, processamento de contexto expandido e desempenho que desafia os padrões de referência, essa última iteração estabelece novos padrões para o desenvolvimento e a implementação de IA.
Pontos principais
Três variantes especializadas do Llama 4: Behemoth (treinamento), Maverick e Scout
O modelo Scout apresenta a revolucionária janela de contexto de 10 milhões de tokens
O Maverick supera o desempenho dos concorrentes, incluindo o Gemini 2.0 Flash e o GPT-4o
Disponível nas plataformas llama.com e Hugging Face
Demonstra desempenho superior nos principais benchmarks - processamento visual, codificação e raciocínio complexo
Integrado aos serviços da MetaAI no WhatsApp, Messenger e Instagram
Entendendo a Llama 4: a mais recente inovação em IA da Meta
O que é a Llama 4?
O Llama 4 constitui o sistema de IA multimodal mais avançado da Meta até o momento, combinando texto e processamento visual em uma arquitetura unificada. Essa tecnologia de última geração proporciona uma eficiência inigualável em diversos aplicativos, com três modelos distintos que oferecem recursos especializados.
O inovador tratamento de contexto do sistema aborda as limitações anteriores, permitindo a interpretação diferenciada de entradas complexas. Particularmente revolucionária é a capacidade de 10 milhões de tokens do Scout, que permite a análise abrangente de conjuntos de dados extensos com coerência mantida.
O Meta facilita a ampla acessibilidade por meio do llama.com e do Hugging Face, incentivando a inovação do desenvolvedor e integrando a Llama 4 às suas principais plataformas sociais.
Comparação do Llama 4 Scout com outros modelos
Llama 4 Scout vs. Concorrentes: Uma análise de benchmark
A Llama 4 Scout estabelece novos padrões de desempenho em relação aos líderes do setor:
| Benchmark | Llama 4 Scout | Gemma 3 27B | Mistral 3.1 24B | Gemini 2.0 Flash-Lite |
|---|---|---|---|---|
| Raciocínio de imagem (MMMU) | 69.4 | 64.9 | 62.8 | 68.0 |
| MathVista | 70.7 | 67.6 | 68.9 | 57.6 |
| Compreensão de imagens (ChartQA) | 88.8 | 76.3 | 86.2 | 73.0 |
| DocVQA (teste) | 94.4 | 90.4 | 94.1 | 91.2 |
| Codificação (LiveCodeBench) | 32.8 | 29.7 | - | 28.9 |
| Raciocínio e conhecimento (MMLU Pro) | 74.3 | 67.5 | 66.8 | 71.6 |
O modelo se destaca especialmente na análise de documentos (pontuação DocVQA de 94,4) e na interpretação de dados visuais (ChartQA de 88,8), mantendo um desempenho competitivo em todas as categorias testadas.
Como começar a usar a Llama 4
Acessando e implementando a Llama 4 em seus projetos
Comece a explorar os recursos da Llama 4 por meio destas etapas:
- Acesso à plataforma: Visite os canais de distribuição oficiais em llama.com ou Hugging Face
- Seleção do modelo: Escolha entre as versões disponíveis com base nos requisitos do projeto (observe que o Behemoth continua em desenvolvimento)
- Integração do sistema: Siga a documentação abrangente do Meta para implementação
- Teste de desempenho: Faça experiências com vários aplicativos para otimizar os resultados
Análise de custo da Llama 4
Entendendo o custo de inferência da Llama 4 Maverick
A Llama 4 Maverick opera a US$ 0,19 a US$ 0,49 por milhão de tokens, apresentando um valor significativo em relação às alternativas:
- Gemini 2.0 Flash: ~$ 0,17/milhão de tokens
- deepseek v3.1: ~$0,48/milhão de tokens
- GPT-4o: ~$4,38/milhão de tokens
Pesando os prós e contras da Llama 4
Prós
Métricas de desempenho líderes em benchmark
Capacidade sem precedentes de contexto de 10 milhões de tokens
Acessível por meio das principais plataformas de IA
Verdadeira arquitetura multimodal
Custo-benefício em comparação com alternativas premium
Contras
Modelo gigantesco ainda em fase de treinamento
Altos requisitos de recursos do sistema
Explorando os principais recursos da Llama 4
Principais recursos dos modelos da Llama 4
A Llama 4 apresenta várias inovações revolucionárias:
- Multimodalidade nativa: Processamento unificado de texto e entradas visuais
- Grande capacidade de contexto: processamento de 10 milhões de tokens no modelo Scout
- Liderança em desempenho: Supera o GPT-4o/Gemini 2.0 em várias categorias
- Acessibilidade aberta: Disponível via llama.com e Hugging Face
- Eficiência arquitetônica: O projeto Mixture of Experts (MoE) otimiza os recursos de computação
Diversos casos de uso da Llama 4
Aplicações potenciais da Llama 4 em vários setores
Os recursos avançados da Llama 4 permitem aplicativos transformadores:
- Experiência do cliente: Interações aprimoradas do chatbot usando memória de contexto estendida
- Geração de conteúdo: Produção de conteúdo automatizado de alta qualidade
- Inteligência comercial: Reconhecimento e análise avançados de padrões de dados
- Ferramentas para desenvolvedores: Assistência e depuração de codificação com tecnologia de IA
- Plataformas sociais: Integrado aos serviços de mensagens do Meta para melhorar as interações com IA
Perguntas frequentes
Onde posso acessar a Llama 4?
Disponível em llama.com e Hugging Face, com integração às plataformas sociais da Meta.
Qual é o tamanho da janela de contexto do Llama 4 Scout?
O Scout apresenta uma capacidade de 10 milhões de tokens, líder do setor, para uma compreensão abrangente do contexto.
Qual é o desempenho da Llama 4 em comparação com outros modelos?
Demonstra recursos superiores em vários benchmarks em relação aos principais concorrentes.
O que é o Meta AI?
A implementação de IA da Meta agora é alimentada pela Llama 4 no WhatsApp, Messenger e Instagram.
Perguntas relacionadas
Quais são os diferentes modelos disponíveis na Llama 4?
Três modelos especializados: Behemoth (modelo de treinamento/professor), Maverick (contexto multimodal de 1 milhão) e Scout (especialista em contexto de 10 milhões).
Como a arquitetura Mixture of Experts (MoE) melhora o desempenho da Llama 4?
Otimiza a eficiência computacional e mantém a qualidade da saída por meio de sub-redes especializadas.
Onde posso ver os benchmarks ajustados por instrução para cada modelo da Llama 4?
Comparações abrangentes disponíveis em relação ao GPT-4o, Gemini 2.0 Flash e outros modelos líderes.










 A Administração do Ciberespaço da China exige a identificação de vídeos curtos gerados por IA e de ficção
A Administração do Ciberespaço da China lançou um plano abrangente para padronizar a rotulagem de conteúdos de vídeos curtos, exigindo que as plataformas ofereçam seis rótulos obrigatórios — incluindo
A Administração do Ciberespaço da China exige a identificação de vídeos curtos gerados por IA e de ficção
A Administração do Ciberespaço da China lançou um plano abrangente para padronizar a rotulagem de conteúdos de vídeos curtos, exigindo que as plataformas ofereçam seis rótulos obrigatórios — incluindo
 O DeepL, conhecido pela tradução de textos, agora se volta para a tradução de voz
A DeepL, empresa de tradução mais conhecida por suas ferramentas baseadas em texto, lançou hoje um pacote de tradução de voz para voz voltado para cenários como reuniões, conversas em dispositivos móv
O DeepL, conhecido pela tradução de textos, agora se volta para a tradução de voz
A DeepL, empresa de tradução mais conhecida por suas ferramentas baseadas em texto, lançou hoje um pacote de tradução de voz para voz voltado para cenários como reuniões, conversas em dispositivos móv
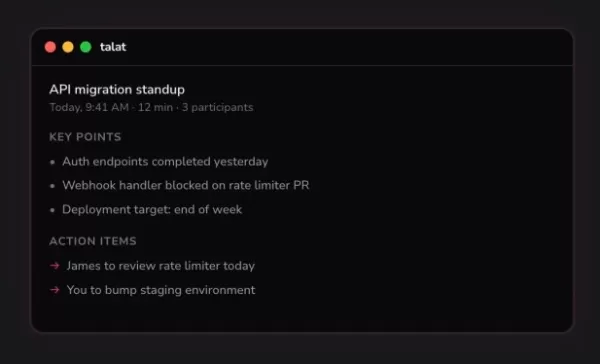 As anotações de reuniões da IA da Talat ficam armazenadas no seu dispositivo, e não na nuvem
O Granola, aplicativo de anotações com inteligência artificial avaliado em US$ 250 milhões, vem ganhando força entre fundadores de empresas de tecnologia e investidores de capital de risco. Mas um des
As anotações de reuniões da IA da Talat ficam armazenadas no seu dispositivo, e não na nuvem
O Granola, aplicativo de anotações com inteligência artificial avaliado em US$ 250 milhões, vem ganhando força entre fundadores de empresas de tecnologia e investidores de capital de risco. Mas um des

Descubra os melhores criadores de perfis de ficção com IA de 2026 para criar personagens complexos. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias que geram motivações consistentes e falhas fatais. Compare as opções gratuitas com as pagas por meio de testes práticos. Liberte agora o seu potencial narrativo.
10 ferramentas
xix.ai

Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai

Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

C'est fou à quel point l'IA multimodale progresse vite ! 🤯 Mais je me demande si Meta va partager ces modèles en open-source comme avant, ou si la concurrence avec OpenAI les pousse à garder leurs cartes cachées...













