
















 Hogar
HogarOpenAI actualiza sus modelos de transcripción y generación de voz de voz
OpenAI está lanzando nuevos modelos de IA para transcripción y generación de voz a través de su API, prometiendo mejoras significativas respecto a sus versiones anteriores. Estas actualizaciones forman parte de la visión más amplia de OpenAI, conocida como "agéntica", que se centra en crear sistemas autónomos capaces de realizar tareas de manera independiente para los usuarios. Aunque el término "agente" puede ser debatido, el jefe de producto de OpenAI, Olivier Godement, lo considera como un chatbot que puede interactuar con los clientes de una empresa.
"Vamos a ver cada vez más agentes surgir en los próximos meses," compartió Godement con TechCrunch durante una sesión informativa. "El objetivo principal es ayudar a los clientes y desarrolladores a utilizar agentes que sean útiles, accesibles y precisos."
El último modelo de texto a voz de OpenAI, denominado "gpt-4o-mini-tts," no solo busca producir un habla más realista y matizada, sino que también es más adaptable que sus predecesores. Los desarrolladores ahora pueden guiar al modelo utilizando comandos en lenguaje natural, como "habla como un científico loco" o "usa una voz serena, como un maestro de mindfulness." Este nivel de control permite una experiencia de voz más personalizada.
Aquí hay una muestra de una voz gastada al estilo "true crime":
Y aquí hay un ejemplo de una voz femenina "profesional":
Jeff Harris, miembro del equipo de productos de OpenAI, enfatizó a TechCrunch que el objetivo es permitir a los desarrolladores personalizar tanto la "experiencia" como el "contexto" de la voz. "En diversos escenarios, no quieres una voz monótona," explicó Harris. "Por ejemplo, en un entorno de soporte al cliente donde la voz necesita sonar apologética por un error, puedes infundir esa emoción en la voz. Creemos firmemente que los desarrolladores y usuarios quieren controlar no solo el contenido, sino también la manera de hablar."
Pasando a las nuevas ofertas de voz a texto de OpenAI, "gpt-4o-transcribe" y "gpt-4o-mini-transcribe," estos modelos están destinados a reemplazar el modelo de transcripción obsoleto Whisper. Entrenados con una amplia variedad de datos de audio de alta calidad, afirman manejar mejor el habla con acentos y variada, incluso en entornos ruidosos. Además, estos modelos son menos propensos a "alucinaciones," un problema donde Whisper a veces inventaba palabras o pasajes completos, añadiendo inexactitudes como comentarios raciales o tratamientos médicos ficticios a las transcripciones.
"Estos modelos muestran una mejora significativa respecto a Whisper en este aspecto," señaló Harris. "Garantizar la precisión del modelo es crucial para una experiencia de voz confiable, y por precisión, nos referimos a que los modelos capturan correctamente las palabras habladas sin añadir contenido no expresado."
Sin embargo, el rendimiento puede variar entre idiomas. Los puntos de referencia internos de OpenAI indican que gpt-4o-transcribe, el más preciso de los dos, tiene una "tasa de error de palabras" cercana al 30% para idiomas índicos y dravídicos como tamil, telugu, malayalam y kannada. Esto sugiere que aproximadamente tres de cada diez palabras podrían diferir de una transcripción humana en estos idiomas.
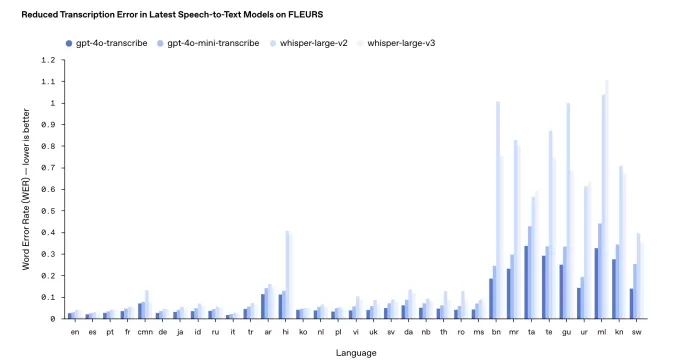
Los resultados de las pruebas de referencia de transcripción de OpenAI. Créditos de la imagen: OpenAI En un cambio respecto a su práctica habitual, OpenAI no hará que estos nuevos modelos de transcripción estén disponibles gratuitamente. Históricamente, lanzaron nuevas versiones de Whisper bajo una licencia MIT para uso comercial. Harris señaló que gpt-4o-transcribe y gpt-4o-mini-transcribe son significativamente más grandes que Whisper, lo que los hace inadecuados para un lanzamiento abierto.
"Estos modelos son demasiado grandes para ejecutarse en una laptop típica como podía hacer Whisper," añadió Harris. "Cuando lanzamos modelos abiertamente, queremos hacerlo de manera reflexiva, asegurándonos de que estén adaptados a necesidades específicas. Vemos los dispositivos de los usuarios finales como un área principal para modelos de código abierto."
Actualizado el 20 de marzo de 2025, 11:54 a.m. PT para aclarar el lenguaje en torno a la tasa de error de palabras y actualizar el gráfico de resultados de referencia con una versión más reciente.
Artículo relacionado
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Recomendaciones de temas especiales relacionados
Creación de cómics
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Recomendaciones de temas especiales relacionados
Creación de cómics
 Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
 15 herramientas
15 herramientas
 xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

 comentario (33)
0/500
comentario (33)
0/500
![LeviKing]()
음성 생성 모델 향상이라... 이게 결국 콜센터 직원 대체 같은 데 쓰이면 실업률 걱정이네요. 기술 좋지만 사회적 영향도 고민해야 할 문제 같아요.
![FrankMartínez]()
The new OpenAI models sound like a game-changer for voice tech! Can't wait to see how devs use this to make apps talk smoother than ever. 😎
![BenHernández]()
Wow, OpenAI's new transcription and voice models sound like a game-changer! I'm curious how these 'agentic' systems will stack up against real-world tasks. Could they finally nail natural-sounding convos? 🤔
![GeorgeTaylor]()
Os novos modelos de transcrição e geração de voz da OpenAI são um divisor de águas! Estou usando no meu podcast e as melhorias são impressionantes. O único ponto negativo? São um pouco caros, mas se você puder pagar, vale cada centavo! 🎙️💸
![GregoryAllen]()
OpenAI's new transcription and voice models are a game changer! I've been using them for my podcast and the improvements are night and day. The only downside? They're a bit pricey, but if you can swing it, they're worth every penny! 🎙️💸
![StevenAllen]()
OpenAI의 새로운 음성 인식 및 음성 생성 모델은 정말 혁신적이에요! 제 팟캐스트에서 사용 중인데, 개선이 눈에 띄어요. 단점은 조금 비싸다는 건데, 감당할 수 있다면 그만한 가치가 있어요! 🎙️💸
OpenAI está lanzando nuevos modelos de IA para transcripción y generación de voz a través de su API, prometiendo mejoras significativas respecto a sus versiones anteriores. Estas actualizaciones forman parte de la visión más amplia de OpenAI, conocida como "agéntica", que se centra en crear sistemas autónomos capaces de realizar tareas de manera independiente para los usuarios. Aunque el término "agente" puede ser debatido, el jefe de producto de OpenAI, Olivier Godement, lo considera como un chatbot que puede interactuar con los clientes de una empresa.
"Vamos a ver cada vez más agentes surgir en los próximos meses," compartió Godement con TechCrunch durante una sesión informativa. "El objetivo principal es ayudar a los clientes y desarrolladores a utilizar agentes que sean útiles, accesibles y precisos."
El último modelo de texto a voz de OpenAI, denominado "gpt-4o-mini-tts," no solo busca producir un habla más realista y matizada, sino que también es más adaptable que sus predecesores. Los desarrolladores ahora pueden guiar al modelo utilizando comandos en lenguaje natural, como "habla como un científico loco" o "usa una voz serena, como un maestro de mindfulness." Este nivel de control permite una experiencia de voz más personalizada.
Aquí hay una muestra de una voz gastada al estilo "true crime":
Y aquí hay un ejemplo de una voz femenina "profesional":
Jeff Harris, miembro del equipo de productos de OpenAI, enfatizó a TechCrunch que el objetivo es permitir a los desarrolladores personalizar tanto la "experiencia" como el "contexto" de la voz. "En diversos escenarios, no quieres una voz monótona," explicó Harris. "Por ejemplo, en un entorno de soporte al cliente donde la voz necesita sonar apologética por un error, puedes infundir esa emoción en la voz. Creemos firmemente que los desarrolladores y usuarios quieren controlar no solo el contenido, sino también la manera de hablar."
Pasando a las nuevas ofertas de voz a texto de OpenAI, "gpt-4o-transcribe" y "gpt-4o-mini-transcribe," estos modelos están destinados a reemplazar el modelo de transcripción obsoleto Whisper. Entrenados con una amplia variedad de datos de audio de alta calidad, afirman manejar mejor el habla con acentos y variada, incluso en entornos ruidosos. Además, estos modelos son menos propensos a "alucinaciones," un problema donde Whisper a veces inventaba palabras o pasajes completos, añadiendo inexactitudes como comentarios raciales o tratamientos médicos ficticios a las transcripciones.
"Estos modelos muestran una mejora significativa respecto a Whisper en este aspecto," señaló Harris. "Garantizar la precisión del modelo es crucial para una experiencia de voz confiable, y por precisión, nos referimos a que los modelos capturan correctamente las palabras habladas sin añadir contenido no expresado."
Sin embargo, el rendimiento puede variar entre idiomas. Los puntos de referencia internos de OpenAI indican que gpt-4o-transcribe, el más preciso de los dos, tiene una "tasa de error de palabras" cercana al 30% para idiomas índicos y dravídicos como tamil, telugu, malayalam y kannada. Esto sugiere que aproximadamente tres de cada diez palabras podrían diferir de una transcripción humana en estos idiomas.
En un cambio respecto a su práctica habitual, OpenAI no hará que estos nuevos modelos de transcripción estén disponibles gratuitamente. Históricamente, lanzaron nuevas versiones de Whisper bajo una licencia MIT para uso comercial. Harris señaló que gpt-4o-transcribe y gpt-4o-mini-transcribe son significativamente más grandes que Whisper, lo que los hace inadecuados para un lanzamiento abierto.
"Estos modelos son demasiado grandes para ejecutarse en una laptop típica como podía hacer Whisper," añadió Harris. "Cuando lanzamos modelos abiertamente, queremos hacerlo de manera reflexiva, asegurándonos de que estén adaptados a necesidades específicas. Vemos los dispositivos de los usuarios finales como un área principal para modelos de código abierto."
Actualizado el 20 de marzo de 2025, 11:54 a.m. PT para aclarar el lenguaje en torno a la tasa de error de palabras y actualizar el gráfico de resultados de referencia con una versión más reciente.










 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
 OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
 Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

음성 생성 모델 향상이라... 이게 결국 콜센터 직원 대체 같은 데 쓰이면 실업률 걱정이네요. 기술 좋지만 사회적 영향도 고민해야 할 문제 같아요.
The new OpenAI models sound like a game-changer for voice tech! Can't wait to see how devs use this to make apps talk smoother than ever. 😎
Wow, OpenAI's new transcription and voice models sound like a game-changer! I'm curious how these 'agentic' systems will stack up against real-world tasks. Could they finally nail natural-sounding convos? 🤔
Os novos modelos de transcrição e geração de voz da OpenAI são um divisor de águas! Estou usando no meu podcast e as melhorias são impressionantes. O único ponto negativo? São um pouco caros, mas se você puder pagar, vale cada centavo! 🎙️💸
OpenAI's new transcription and voice models are a game changer! I've been using them for my podcast and the improvements are night and day. The only downside? They're a bit pricey, but if you can swing it, they're worth every penny! 🎙️💸
OpenAI의 새로운 음성 인식 및 음성 생성 모델은 정말 혁신적이에요! 제 팟캐스트에서 사용 중인데, 개선이 눈에 띄어요. 단점은 조금 비싸다는 건데, 감당할 수 있다면 그만한 가치가 있어요! 🎙️💸













