
















 Heim
HeimOpenAI verbessert seine Transkriptions- und Sprach-generierende KI-Modelle
OpenAI führt neue KI-Modelle für Transkription und Sprachgenerierung über seine API ein und verspricht erhebliche Verbesserungen gegenüber den früheren Versionen. Diese Updates sind Teil der umfassenderen „agentischen“ Vision von OpenAI, die darauf abzielt, autonome Systeme zu schaffen, die Aufgaben unabhängig für Nutzer ausführen können. Während der Begriff „Agent“ diskutiert werden kann, sieht Olivier Godement, Leiter der Produktabteilung bei OpenAI, ihn als Chatbot, der mit den Kunden eines Unternehmens interagieren kann.
„Wir werden in den kommenden Monaten immer mehr Agenten sehen“, teilte Godement TechCrunch während eines Briefings mit. „Das übergeordnete Ziel ist es, Kunden und Entwicklern zu helfen, Agenten zu nutzen, die nützlich, zugänglich und präzise sind.“
Das neueste Text-to-Speech-Modell von OpenAI, genannt „gpt-4o-mini-tts“, zielt nicht nur darauf ab, lebensechtere und nuanciertere Sprache zu erzeugen, sondern ist auch anpassungsfähiger als seine Vorgänger. Entwickler können das Modell nun mit natürlichen Sprachbefehlen steuern, wie z. B. „sprich wie ein verrückter Wissenschaftler“ oder „verwende eine ruhige Stimme, wie ein Achtsamkeitslehrer“. Dieses Maß an Kontrolle ermöglicht eine personalisiertere Spracherfahrung.
Hier ist ein Beispiel für eine „True-Crime-Stil“-Stimme, die verwittert klingt:
Und hier ist ein Beispiel für eine weibliche „professionelle“ Stimme:
Jeff Harris, Mitglied des Produktteams von OpenAI, betonte gegenüber TechCrunch, dass das Ziel darin besteht, Entwicklern die Anpassung sowohl der Sprach-„Erfahrung“ als auch des „Kontexts“ zu ermöglichen. „In verschiedenen Szenarien möchte man keine monotone Stimme“, erklärte Harris. „Zum Beispiel in einer Kundensupport-Situation, in der die Stimme reumütig klingen soll, wenn ein Fehler passiert ist, kann man diese Emotion in die Stimme einfließen lassen. Wir sind fest davon überzeugt, dass Entwickler und Nutzer nicht nur den Inhalt, sondern auch die Art der Sprache kontrollieren möchten.“
In Bezug auf die neuen Speech-to-Text-Angebote von OpenAI, „gpt-4o-transcribe“ und „gpt-4o-mini-transcribe“, sollen diese Modelle das veraltete Whisper-Transkriptionsmodell ersetzen. Sie wurden mit einer vielfältigen Auswahl an hochwertigen Audiodaten trainiert und sollen akzentuierte und abwechslungsreiche Sprache besser verarbeiten, selbst in lauten Umgebungen. Zudem sind diese Modelle weniger anfällig für „Halluzinationen“, ein Problem, bei dem Whisper manchmal Wörter oder ganze Passagen erfand und Ungenauigkeiten wie rassistische Kommentare oder fiktive medizinische Behandlungen in Transkripte einfügte.
„Diese Modelle zeigen in dieser Hinsicht deutliche Verbesserungen gegenüber Whisper“, bemerkte Harris. „Die Genauigkeit des Modells ist entscheidend für eine zuverlässige Spracherfahrung, und mit Genauigkeit meinen wir, dass die Modelle die gesprochenen Wörter korrekt erfassen, ohne nicht gesprochene Inhalte hinzuzufügen.“
Die Leistung kann jedoch je nach Sprache variieren. Interne Benchmarks von OpenAI zeigen, dass gpt-4o-transcribe, das präzisere der beiden Modelle, eine „Wortfehlerrate“ von fast 30 % für indische und dravidische Sprachen wie Tamil, Telugu, Malayalam und Kannada aufweist. Dies deutet darauf hin, dass etwa drei von zehn Wörtern in diesen Sprachen von einer menschlichen Transkription abweichen könnten.
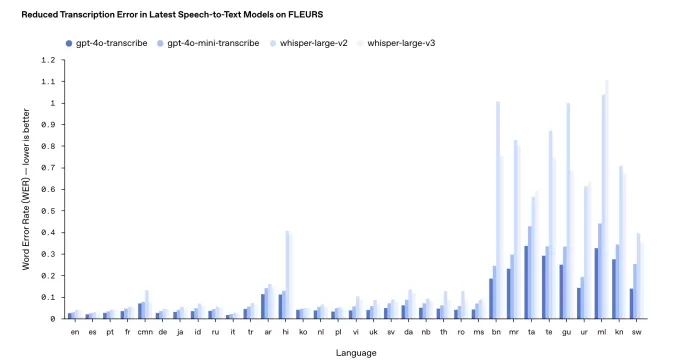
Die Ergebnisse aus dem OpenAI Transkriptions-Benchmarking. Bildnachweis: OpenAI Entgegen ihrer üblichen Praxis wird OpenAI diese neuen Transkriptionsmodelle nicht kostenlos zur Verfügung stellen. Historisch gesehen wurden neue Whisper-Versionen unter einer MIT-Lizenz für kommerzielle Nutzung freigegeben. Harris wies darauf hin, dass gpt-4o-transcribe und gpt-4o-mini-transcribe deutlich größer als Whisper sind, was sie für eine offene Freigabe ungeeignet macht.
„Diese Modelle sind zu groß, um auf einem typischen Laptop wie Whisper ausgeführt zu werden“, fügte Harris hinzu. „Wenn wir Modelle offen freigeben, wollen wir dies durchdacht tun und sicherstellen, dass sie für spezifische Bedürfnisse zugeschnitten sind. Wir sehen Endnutzergeräte als einen Hauptanwendungsbereich für Open-Source-Modelle.“
Aktualisiert am 20. März 2025, 11:54 Uhr PT, um die Formulierung zur Wortfehlerrate zu präzisieren und das Benchmark-Ergebnisdiagramm mit einer neueren Version zu aktualisieren.
Verwandter Artikel
 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
 Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
 15 Tools
15 Tools
 xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

 Kommentare (33)
Kommentare (33)
![LeviKing]()
음성 생성 모델 향상이라... 이게 결국 콜센터 직원 대체 같은 데 쓰이면 실업률 걱정이네요. 기술 좋지만 사회적 영향도 고민해야 할 문제 같아요.
![FrankMartínez]()
The new OpenAI models sound like a game-changer for voice tech! Can't wait to see how devs use this to make apps talk smoother than ever. 😎
![BenHernández]()
Wow, OpenAI's new transcription and voice models sound like a game-changer! I'm curious how these 'agentic' systems will stack up against real-world tasks. Could they finally nail natural-sounding convos? 🤔
![GeorgeTaylor]()
Os novos modelos de transcrição e geração de voz da OpenAI são um divisor de águas! Estou usando no meu podcast e as melhorias são impressionantes. O único ponto negativo? São um pouco caros, mas se você puder pagar, vale cada centavo! 🎙️💸
![GregoryAllen]()
OpenAI's new transcription and voice models are a game changer! I've been using them for my podcast and the improvements are night and day. The only downside? They're a bit pricey, but if you can swing it, they're worth every penny! 🎙️💸
![StevenAllen]()
OpenAI의 새로운 음성 인식 및 음성 생성 모델은 정말 혁신적이에요! 제 팟캐스트에서 사용 중인데, 개선이 눈에 띄어요. 단점은 조금 비싸다는 건데, 감당할 수 있다면 그만한 가치가 있어요! 🎙️💸
OpenAI führt neue KI-Modelle für Transkription und Sprachgenerierung über seine API ein und verspricht erhebliche Verbesserungen gegenüber den früheren Versionen. Diese Updates sind Teil der umfassenderen „agentischen“ Vision von OpenAI, die darauf abzielt, autonome Systeme zu schaffen, die Aufgaben unabhängig für Nutzer ausführen können. Während der Begriff „Agent“ diskutiert werden kann, sieht Olivier Godement, Leiter der Produktabteilung bei OpenAI, ihn als Chatbot, der mit den Kunden eines Unternehmens interagieren kann.
„Wir werden in den kommenden Monaten immer mehr Agenten sehen“, teilte Godement TechCrunch während eines Briefings mit. „Das übergeordnete Ziel ist es, Kunden und Entwicklern zu helfen, Agenten zu nutzen, die nützlich, zugänglich und präzise sind.“
Das neueste Text-to-Speech-Modell von OpenAI, genannt „gpt-4o-mini-tts“, zielt nicht nur darauf ab, lebensechtere und nuanciertere Sprache zu erzeugen, sondern ist auch anpassungsfähiger als seine Vorgänger. Entwickler können das Modell nun mit natürlichen Sprachbefehlen steuern, wie z. B. „sprich wie ein verrückter Wissenschaftler“ oder „verwende eine ruhige Stimme, wie ein Achtsamkeitslehrer“. Dieses Maß an Kontrolle ermöglicht eine personalisiertere Spracherfahrung.
Hier ist ein Beispiel für eine „True-Crime-Stil“-Stimme, die verwittert klingt:
Und hier ist ein Beispiel für eine weibliche „professionelle“ Stimme:
Jeff Harris, Mitglied des Produktteams von OpenAI, betonte gegenüber TechCrunch, dass das Ziel darin besteht, Entwicklern die Anpassung sowohl der Sprach-„Erfahrung“ als auch des „Kontexts“ zu ermöglichen. „In verschiedenen Szenarien möchte man keine monotone Stimme“, erklärte Harris. „Zum Beispiel in einer Kundensupport-Situation, in der die Stimme reumütig klingen soll, wenn ein Fehler passiert ist, kann man diese Emotion in die Stimme einfließen lassen. Wir sind fest davon überzeugt, dass Entwickler und Nutzer nicht nur den Inhalt, sondern auch die Art der Sprache kontrollieren möchten.“
In Bezug auf die neuen Speech-to-Text-Angebote von OpenAI, „gpt-4o-transcribe“ und „gpt-4o-mini-transcribe“, sollen diese Modelle das veraltete Whisper-Transkriptionsmodell ersetzen. Sie wurden mit einer vielfältigen Auswahl an hochwertigen Audiodaten trainiert und sollen akzentuierte und abwechslungsreiche Sprache besser verarbeiten, selbst in lauten Umgebungen. Zudem sind diese Modelle weniger anfällig für „Halluzinationen“, ein Problem, bei dem Whisper manchmal Wörter oder ganze Passagen erfand und Ungenauigkeiten wie rassistische Kommentare oder fiktive medizinische Behandlungen in Transkripte einfügte.
„Diese Modelle zeigen in dieser Hinsicht deutliche Verbesserungen gegenüber Whisper“, bemerkte Harris. „Die Genauigkeit des Modells ist entscheidend für eine zuverlässige Spracherfahrung, und mit Genauigkeit meinen wir, dass die Modelle die gesprochenen Wörter korrekt erfassen, ohne nicht gesprochene Inhalte hinzuzufügen.“
Die Leistung kann jedoch je nach Sprache variieren. Interne Benchmarks von OpenAI zeigen, dass gpt-4o-transcribe, das präzisere der beiden Modelle, eine „Wortfehlerrate“ von fast 30 % für indische und dravidische Sprachen wie Tamil, Telugu, Malayalam und Kannada aufweist. Dies deutet darauf hin, dass etwa drei von zehn Wörtern in diesen Sprachen von einer menschlichen Transkription abweichen könnten.
Entgegen ihrer üblichen Praxis wird OpenAI diese neuen Transkriptionsmodelle nicht kostenlos zur Verfügung stellen. Historisch gesehen wurden neue Whisper-Versionen unter einer MIT-Lizenz für kommerzielle Nutzung freigegeben. Harris wies darauf hin, dass gpt-4o-transcribe und gpt-4o-mini-transcribe deutlich größer als Whisper sind, was sie für eine offene Freigabe ungeeignet macht.
„Diese Modelle sind zu groß, um auf einem typischen Laptop wie Whisper ausgeführt zu werden“, fügte Harris hinzu. „Wenn wir Modelle offen freigeben, wollen wir dies durchdacht tun und sicherstellen, dass sie für spezifische Bedürfnisse zugeschnitten sind. Wir sehen Endnutzergeräte als einen Hauptanwendungsbereich für Open-Source-Modelle.“
Aktualisiert am 20. März 2025, 11:54 Uhr PT, um die Formulierung zur Wortfehlerrate zu präzisieren und das Benchmark-Ergebnisdiagramm mit einer neueren Version zu aktualisieren.










 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
 OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
 Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

음성 생성 모델 향상이라... 이게 결국 콜센터 직원 대체 같은 데 쓰이면 실업률 걱정이네요. 기술 좋지만 사회적 영향도 고민해야 할 문제 같아요.
The new OpenAI models sound like a game-changer for voice tech! Can't wait to see how devs use this to make apps talk smoother than ever. 😎
Wow, OpenAI's new transcription and voice models sound like a game-changer! I'm curious how these 'agentic' systems will stack up against real-world tasks. Could they finally nail natural-sounding convos? 🤔
Os novos modelos de transcrição e geração de voz da OpenAI são um divisor de águas! Estou usando no meu podcast e as melhorias são impressionantes. O único ponto negativo? São um pouco caros, mas se você puder pagar, vale cada centavo! 🎙️💸
OpenAI's new transcription and voice models are a game changer! I've been using them for my podcast and the improvements are night and day. The only downside? They're a bit pricey, but if you can swing it, they're worth every penny! 🎙️💸
OpenAI의 새로운 음성 인식 및 음성 생성 모델은 정말 혁신적이에요! 제 팟캐스트에서 사용 중인데, 개선이 눈에 띄어요. 단점은 조금 비싸다는 건데, 감당할 수 있다면 그만한 가치가 있어요! 🎙️💸













