
















 Дом
Дом
OpenAI модернизирует свою транскрипционную и генерирующую игенерирующую модели искусственного интеллекта
OpenAI выпускает новые модели ИИ для транскрипции и генерации голоса через свой API, обещающие значительные улучшения по сравнению с предыдущими версиями. Эти обновления являются частью более широкой "агентной" концепции OpenAI, которая сосредоточена на создании автономных систем, способных выполнять задачи самостоятельно для пользователей. Хотя термин "агент" может быть предметом споров, руководитель отдела продуктов OpenAI Оливье Годеман рассматривает его как чат-бота, который может взаимодействовать с клиентами бизнеса.
"В ближайшие месяцы мы увидим появление все большего числа агентов," — поделился Годеман с TechCrunch во время брифинга. "Главная цель — помочь клиентам и разработчикам использовать агентов, которые будут полезны, доступны и точны."
Новейшая модель преобразования текста в речь от OpenAI, названная "gpt-4o-mini-tts," не только стремится создавать более реалистичную и нюансированную речь, но и является более адаптивной, чем ее предшественники. Разработчики теперь могут управлять моделью с помощью команд на естественном языке, таких как "говори как безумный ученый" или "используй спокойный голос, как у учителя медитации." Этот уровень контроля позволяет создавать более персонализированный голосовой опыт.
Вот пример голоса в стиле "true crime", с хрипотцой:
А вот пример женского "профессионального" голоса:
Джефф Харрис, член команды по продуктам OpenAI, подчеркнул в разговоре с TechCrunch, что цель — позволить разработчикам настраивать как голосовой "опыт", так и "контекст". "В разных сценариях вам не нужен монотонный голос," — пояснил Харрис. "Например, в ситуации поддержки клиентов, где голос должен звучать извиняющимся за ошибку, вы можете вложить эту эмоцию в голос. Мы твердо убеждены, что разработчики и пользователи хотят контролировать не только содержание, но и манеру речи."
Переходя к новым предложениям OpenAI по преобразованию речи в текст, модели "gpt-4o-transcribe" и "gpt-4o-mini-transcribe" призваны заменить устаревшую модель транскрипции Whisper. Обученные на разнообразном массиве высококачественных аудиоданных, они, как утверждается, лучше справляются с акцентированной и разнообразной речью, даже в шумных условиях. Кроме того, эти модели менее подвержены "галлюцинациям", проблеме, при которой Whisper иногда придумывал слова или целые отрывки, добавляя неточности, такие как расовые комментарии или вымышленные медицинские процедуры в транскрипты.
"Эти модели показывают значительное улучшение по сравнению с Whisper в этом отношении," — отметил Харрис. "Обеспечение точности модели крайне важно для надежного голосового опыта, и под точностью мы подразумеваем, что модели корректно улавливают произнесенные слова, не добавляя непроизнесенного содержания."
Однако производительность может варьироваться в зависимости от языка. Внутренние тесты OpenAI показывают, что gpt-4o-transcribe, более точная из двух моделей, имеет "уровень ошибок слов" около 30% для индийских и дравидийских языков, таких как тамильский, телугу, малаялам и каннада. Это означает, что примерно три из каждых десяти слов могут отличаться от человеческой транскрипции на этих языках.
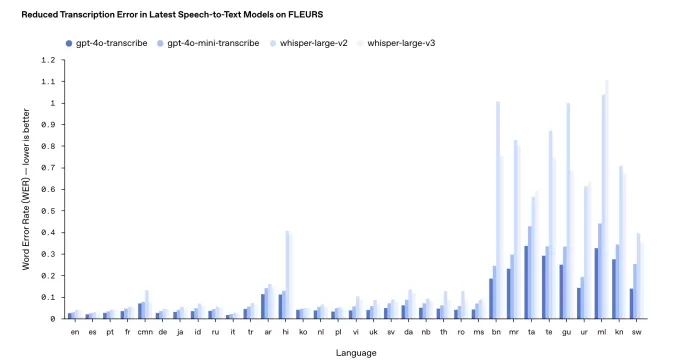
Результаты тестирования транскрипции OpenAI. Источник изображения: OpenAI В отличие от своей обычной практики, OpenAI не будет предоставлять эти новые модели транскрипции бесплатно. Исторически они выпускали новые версии Whisper под лицензией MIT для коммерческого использования. Харрис отметил, что gpt-4o-transcribe и gpt-4o-mini-transcribe значительно крупнее, чем Whisper, что делает их неподходящими для открытого выпуска.
"Эти модели слишком велики, чтобы работать на обычном ноутбуке, как это мог делать Whisper," — добавил Харрис. "Когда мы открыто выпускаем модели, мы хотим делать это продуманно, обеспечивая их адаптацию под конкретные нужды. Мы рассматриваем устройства конечных пользователей как основную область для моделей с открытым исходным кодом."
Обновлено 20 марта 2025 года, 11:54 по тихоокеанскому времени, чтобы уточнить формулировку относительно уровня ошибок слов и обновить график результатов тестирования на более новую версию.
Связанная статья
 Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
OpenAI описывает экономику искусственного интеллекта с участием государственных инвестиционных фондов, налогами на роботов и четырехдневной рабочей неделей
В то время как правительства пытаются справиться с экономическими последствиями появления сверхинтеллектуальных машин, компания OpenAI опубликовала ряд предложений по формированию политики, в которых
Грег Брокман рассказывает, как Илон Маск покинул OpenAI
В конце августа 2017 года ключевые фигуры OpenAI — на тот момент небольшой некоммерческой исследовательской лаборатории — собрались, чтобы обсудить, как создать коммерческую структуру для продвижения
Рекомендации по связанным специальным темам
Преобразование текста в речь
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
OpenAI описывает экономику искусственного интеллекта с участием государственных инвестиционных фондов, налогами на роботов и четырехдневной рабочей неделей
В то время как правительства пытаются справиться с экономическими последствиями появления сверхинтеллектуальных машин, компания OpenAI опубликовала ряд предложений по формированию политики, в которых
Грег Брокман рассказывает, как Илон Маск покинул OpenAI
В конце августа 2017 года ключевые фигуры OpenAI — на тот момент небольшой некоммерческой исследовательской лаборатории — собрались, чтобы обсудить, как создать коммерческую структуру для продвижения
Рекомендации по связанным специальным темам
Преобразование текста в речь
 Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
 10 инструментов
10 инструментов
 xix.ai
Создание комиксов
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
xix.ai
Создание комиксов
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

 Комментарии (33)
Комментарии (33)
![LeviKing]()
음성 생성 모델 향상이라... 이게 결국 콜센터 직원 대체 같은 데 쓰이면 실업률 걱정이네요. 기술 좋지만 사회적 영향도 고민해야 할 문제 같아요.
![FrankMartínez]()
The new OpenAI models sound like a game-changer for voice tech! Can't wait to see how devs use this to make apps talk smoother than ever. 😎
![BenHernández]()
Wow, OpenAI's new transcription and voice models sound like a game-changer! I'm curious how these 'agentic' systems will stack up against real-world tasks. Could they finally nail natural-sounding convos? 🤔
![GeorgeTaylor]()
Os novos modelos de transcrição e geração de voz da OpenAI são um divisor de águas! Estou usando no meu podcast e as melhorias são impressionantes. O único ponto negativo? São um pouco caros, mas se você puder pagar, vale cada centavo! 🎙️💸
![GregoryAllen]()
OpenAI's new transcription and voice models are a game changer! I've been using them for my podcast and the improvements are night and day. The only downside? They're a bit pricey, but if you can swing it, they're worth every penny! 🎙️💸
![StevenAllen]()
OpenAI의 새로운 음성 인식 및 음성 생성 모델은 정말 혁신적이에요! 제 팟캐스트에서 사용 중인데, 개선이 눈에 띄어요. 단점은 조금 비싸다는 건데, 감당할 수 있다면 그만한 가치가 있어요! 🎙️💸
OpenAI выпускает новые модели ИИ для транскрипции и генерации голоса через свой API, обещающие значительные улучшения по сравнению с предыдущими версиями. Эти обновления являются частью более широкой "агентной" концепции OpenAI, которая сосредоточена на создании автономных систем, способных выполнять задачи самостоятельно для пользователей. Хотя термин "агент" может быть предметом споров, руководитель отдела продуктов OpenAI Оливье Годеман рассматривает его как чат-бота, который может взаимодействовать с клиентами бизнеса.
"В ближайшие месяцы мы увидим появление все большего числа агентов," — поделился Годеман с TechCrunch во время брифинга. "Главная цель — помочь клиентам и разработчикам использовать агентов, которые будут полезны, доступны и точны."
Новейшая модель преобразования текста в речь от OpenAI, названная "gpt-4o-mini-tts," не только стремится создавать более реалистичную и нюансированную речь, но и является более адаптивной, чем ее предшественники. Разработчики теперь могут управлять моделью с помощью команд на естественном языке, таких как "говори как безумный ученый" или "используй спокойный голос, как у учителя медитации." Этот уровень контроля позволяет создавать более персонализированный голосовой опыт.
Вот пример голоса в стиле "true crime", с хрипотцой:
А вот пример женского "профессионального" голоса:
Джефф Харрис, член команды по продуктам OpenAI, подчеркнул в разговоре с TechCrunch, что цель — позволить разработчикам настраивать как голосовой "опыт", так и "контекст". "В разных сценариях вам не нужен монотонный голос," — пояснил Харрис. "Например, в ситуации поддержки клиентов, где голос должен звучать извиняющимся за ошибку, вы можете вложить эту эмоцию в голос. Мы твердо убеждены, что разработчики и пользователи хотят контролировать не только содержание, но и манеру речи."
Переходя к новым предложениям OpenAI по преобразованию речи в текст, модели "gpt-4o-transcribe" и "gpt-4o-mini-transcribe" призваны заменить устаревшую модель транскрипции Whisper. Обученные на разнообразном массиве высококачественных аудиоданных, они, как утверждается, лучше справляются с акцентированной и разнообразной речью, даже в шумных условиях. Кроме того, эти модели менее подвержены "галлюцинациям", проблеме, при которой Whisper иногда придумывал слова или целые отрывки, добавляя неточности, такие как расовые комментарии или вымышленные медицинские процедуры в транскрипты.
"Эти модели показывают значительное улучшение по сравнению с Whisper в этом отношении," — отметил Харрис. "Обеспечение точности модели крайне важно для надежного голосового опыта, и под точностью мы подразумеваем, что модели корректно улавливают произнесенные слова, не добавляя непроизнесенного содержания."
Однако производительность может варьироваться в зависимости от языка. Внутренние тесты OpenAI показывают, что gpt-4o-transcribe, более точная из двух моделей, имеет "уровень ошибок слов" около 30% для индийских и дравидийских языков, таких как тамильский, телугу, малаялам и каннада. Это означает, что примерно три из каждых десяти слов могут отличаться от человеческой транскрипции на этих языках.
В отличие от своей обычной практики, OpenAI не будет предоставлять эти новые модели транскрипции бесплатно. Исторически они выпускали новые версии Whisper под лицензией MIT для коммерческого использования. Харрис отметил, что gpt-4o-transcribe и gpt-4o-mini-transcribe значительно крупнее, чем Whisper, что делает их неподходящими для открытого выпуска.
"Эти модели слишком велики, чтобы работать на обычном ноутбуке, как это мог делать Whisper," — добавил Харрис. "Когда мы открыто выпускаем модели, мы хотим делать это продуманно, обеспечивая их адаптацию под конкретные нужды. Мы рассматриваем устройства конечных пользователей как основную область для моделей с открытым исходным кодом."
Обновлено 20 марта 2025 года, 11:54 по тихоокеанскому времени, чтобы уточнить формулировку относительно уровня ошибок слов и обновить график результатов тестирования на более новую версию.










 Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
 OpenAI описывает экономику искусственного интеллекта с участием государственных инвестиционных фондов, налогами на роботов и четырехдневной рабочей неделей
В то время как правительства пытаются справиться с экономическими последствиями появления сверхинтеллектуальных машин, компания OpenAI опубликовала ряд предложений по формированию политики, в которых
OpenAI описывает экономику искусственного интеллекта с участием государственных инвестиционных фондов, налогами на роботов и четырехдневной рабочей неделей
В то время как правительства пытаются справиться с экономическими последствиями появления сверхинтеллектуальных машин, компания OpenAI опубликовала ряд предложений по формированию политики, в которых
 Грег Брокман рассказывает, как Илон Маск покинул OpenAI
В конце августа 2017 года ключевые фигуры OpenAI — на тот момент небольшой некоммерческой исследовательской лаборатории — собрались, чтобы обсудить, как создать коммерческую структуру для продвижения
Грег Брокман рассказывает, как Илон Маск покинул OpenAI
В конце августа 2017 года ключевые фигуры OpenAI — на тот момент небольшой некоммерческой исследовательской лаборатории — собрались, чтобы обсудить, как создать коммерческую структуру для продвижения

Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

음성 생성 모델 향상이라... 이게 결국 콜센터 직원 대체 같은 데 쓰이면 실업률 걱정이네요. 기술 좋지만 사회적 영향도 고민해야 할 문제 같아요.
The new OpenAI models sound like a game-changer for voice tech! Can't wait to see how devs use this to make apps talk smoother than ever. 😎
Wow, OpenAI's new transcription and voice models sound like a game-changer! I'm curious how these 'agentic' systems will stack up against real-world tasks. Could they finally nail natural-sounding convos? 🤔
Os novos modelos de transcrição e geração de voz da OpenAI são um divisor de águas! Estou usando no meu podcast e as melhorias são impressionantes. O único ponto negativo? São um pouco caros, mas se você puder pagar, vale cada centavo! 🎙️💸
OpenAI's new transcription and voice models are a game changer! I've been using them for my podcast and the improvements are night and day. The only downside? They're a bit pricey, but if you can swing it, they're worth every penny! 🎙️💸
OpenAI의 새로운 음성 인식 및 음성 생성 모델은 정말 혁신적이에요! 제 팟캐스트에서 사용 중인데, 개선이 눈에 띄어요. 단점은 조금 비싸다는 건데, 감당할 수 있다면 그만한 가치가 있어요! 🎙️💸













