
















 Heim
Heim
Nvidia stellt Open-Source-KI-Modell Nemotron-Nano-9B-v2 mit umschaltbarem Denkvermögen vor
Kleine Sprachmodelle sorgen für Aufsehen. Nach der Vorstellung des Smartwatch-großen Bildverarbeitungsmodells von Liquid AI, einem Spin-off des MIT, und des Smartphone-fähigen Modells von Google betritt nun auch Nvidia die Bühne mit seinem eigenen schlanken Konkurrenten: Nemotron-Nano-9B-V2. Dieses neue Modell ist in wichtigen Benchmarks führend und verfügt über eine einzigartige Funktion, mit der Benutzer das „Reasoning” der KI aktivieren oder deaktivieren können – im Wesentlichen ein Selbstprüfungsprozess vor der Ausgabe einer endgültigen Antwort.
Obwohl 9 Milliarden Parameter die Größenordnung der von uns kürzlich vorgestellten Mikro-Modelle mit mehreren Millionen Parametern übersteigen, hebt Nvidia dies als bedeutende Optimierung gegenüber den ursprünglichen 12 Milliarden Parametern hervor. Die überarbeitete Größe wurde speziell für den Betrieb auf einer einzigen, weit verbreiteten Nvidia A10-GPU entwickelt.
Oleksii Kuchiaev, Director of AI Model Post-Training bei Nvidia, erklärte in Antwort auf eine Frage zu X: „Wir haben das 12-Milliarden-Modell auf 9 Milliarden reduziert, damit es perfekt auf die A10 passt, eine beliebte GPU für den Einsatz. Es handelt sich außerdem um eine hybride Architektur, die es ermöglicht, größere Batch-Größen zu verarbeiten und Geschwindigkeiten zu erreichen, die bis zu sechsmal schneller sind als bei herkömmlichen Transformer-Modellen ähnlicher Größe.“
Zum Vergleich: Viele führende große Sprachmodelle arbeiten im Bereich von über 70 Milliarden Parametern. Parameter sind die internen Einstellungen, die das Verhalten eines Modells definieren, wobei höhere Werte in der Regel eine größere Leistungsfähigkeit bedeuten, aber auch deutlich mehr Rechenleistung erfordern.
Das Modell unterstützt mehrere Sprachen, darunter Englisch, Deutsch, Spanisch, Französisch, Italienisch und Japanisch. Erweiterte Funktionen decken auch Koreanisch, Portugiesisch, Russisch und Chinesisch ab. Es eignet sich gut für Aufgaben, die vom Befolgen von Anweisungen bis zum Generieren von Code reichen.
Nemotron-Nano-9B-V2 und seine Vorab-Trainingsdatensätze sind derzeit auf Hugging Face und über den eigenen Modellkatalog von Nvidia verfügbar.
Eine Fusion aus Transformer- und Mamba-Architekturen
Das Modell basiert auf Nemotron-H, einer Familie von hybriden Mamba-Transformer-Modellen, die als Grundlage für die neuesten KI-Angebote von Nvidia dienen.
Während dominante LLMs in der Regel ausschließlich auf der Transformer-Architektur und ihren Aufmerksamkeitsmechanismen basieren, können diese in Bezug auf Speicher und Rechenleistung mit zunehmender Länge der Eingabesequenzen unerschwinglich teuer werden.
Nemotron-H-Modelle und andere Modelle, die die Mamba-Architektur nutzen – entwickelt von Forschern der Carnegie Mellon University und der Princeton University – enthalten selektive Zustandsraummodelle (SSMs). Diese SSMs verwalten extrem lange Sequenzen effizient, indem sie einen internen Zustand aufrechterhalten.
Diese Schichten skalieren linear mit der Sequenzlänge, sodass sie viel längere Kontexte als die Standard-Selbstaufmerksamkeit ohne den gleichen Rechenaufwand verarbeiten können.
Ein hybrides Mamba-Transformer-Design reduziert die Kosten, indem es die meisten Aufmerksamkeits-Schichten durch lineare Zustandsraum-Schichten ersetzt. Dies kann zu einem bis zu 2- bis 3-mal höheren Durchsatz bei Aufgaben mit langem Kontext führen, während die Genauigkeit vergleichbar bleibt.
Nvidia ist mit diesem Ansatz nicht allein; andere KI-Forschungslabore, wie z. B. AI2, haben ebenfalls Modelle auf Basis der Mamba-Architektur veröffentlicht.
Schalten Sie das Schlussfolgern mit einfachen Befehlen ein oder aus
Nemotron-Nano-9B-v2 ist als einheitliches, rein textbasiertes Modell konzipiert, das sowohl zu Konversationsinteraktionen als auch zu komplexen Schlussfolgerungen fähig ist und vollständig von Grund auf trainiert wurde.
Standardmäßig generiert das System eine detaillierte Argumentationskette, bevor es seine endgültige Antwort gibt. Benutzer können dieses Verhalten mit einfachen Befehlstoken wie /think oder /no_think steuern.
Das Modell führt außerdem ein Laufzeit-„Denkbudget”-Management ein. Damit können Entwickler eine maximale Grenze für die Anzahl der Tokens festlegen, die das Modell für interne Schlussfolgerungen verwenden kann, bevor es eine Antwort liefern muss.
Dieser Mechanismus soll ein Gleichgewicht zwischen Genauigkeit und Antwortverzögerung herstellen, was für Anwendungen wie Chatbots im Kundensupport oder autonome Agenten von entscheidender Bedeutung ist.
Benchmarks zeigen starke Leistung
Die Bewertungsergebnisse zeigen eine wettbewerbsfähige Genauigkeit im Vergleich zu anderen führenden kleinen offenen Modellen. Bei Tests mit aktivierter Argumentation unter Verwendung der NeMo-Skills-Suite erzielte Nemotron-Nano-9B-v2 Ergebnisse von 72,1 % bei AIME25, 97,8 % bei MATH500, 64,0 % bei GPQA und 71,1 % bei LiveCodeBench.
Auch die Ergebnisse bei den Benchmarks für die Befolgung von Anweisungen und langen Kontexten sind stark: 90,3 % bei IFEval und 78,9 % beim RULER 128K-Test, mit zusätzlichen messbaren Gewinnen bei BFCL v3 und dem HLE-Benchmark.
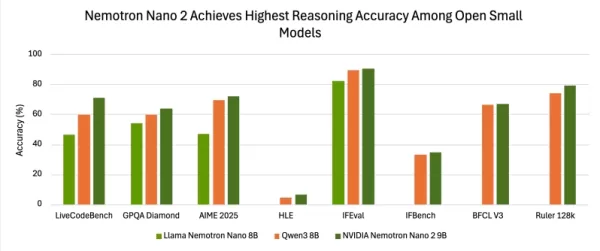
In mehreren Bewertungen zeigt Nano-9B-v2 durchweg eine höhere Genauigkeit als ein gängiger Vergleichspunkt, das Qwen3-8B-Modell.
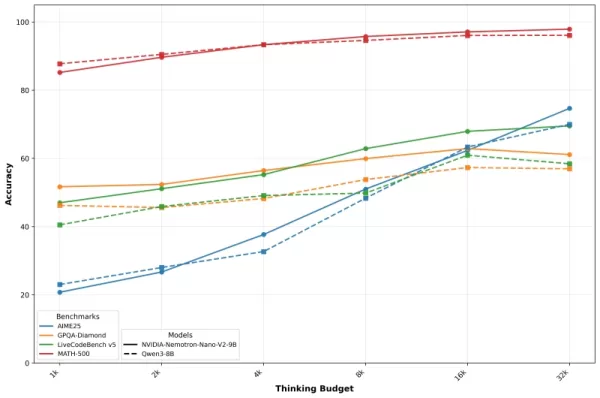
Nvidia präsentiert diese Ergebnisse mit Genauigkeits-Budget-Kurven, die veranschaulichen, wie sich die Leistung mit steigender Token-Zuteilung für die Schlussfolgerung verbessert. Das Unternehmen weist darauf hin, dass eine sorgfältige Budgetkontrolle es Entwicklern ermöglicht, sowohl die Qualität als auch die Geschwindigkeit in Produktionsumgebungen zu optimieren.
Trainiert auf synthetischen Datensätzen
Sowohl das Nano-Modell als auch die breitere Nemotron-H-Familie wurden mit einer Mischung aus sorgfältig kuratierten Webdaten, proprietären Quellen und synthetischen Trainingsdaten trainiert.
Die Trainingskorpora umfassen allgemeine Texte, Code, Mathematik, wissenschaftliche Literatur, juristische und finanzielle Dokumente sowie auf die Abstimmung ausgerichtete Frage-Antwort-Datensätze.
Nvidia bestätigt die Verwendung synthetischer Schlussfolgerungsspuren, die von anderen großen Modellen generiert wurden, um die Leistung bei komplexen Benchmark-Aufgaben zu verbessern.
Lizenzierung und kommerzielle Nutzung
Das Nano-9B-v2-Modell wird unter der Nvidia Open Model License Agreement veröffentlicht, die zuletzt im Juni 2025 aktualisiert wurde.
Diese Lizenz ist so gestaltet, dass sie freizügig und unternehmensfreundlich ist. Nvidia erklärt ausdrücklich, dass die Modelle sofort kommerziell nutzbar sind und dass Entwickler frei sind, abgeleitete Werke zu erstellen und zu verbreiten.
Entscheidend ist, dass Nvidia keine Eigentumsrechte an den vom Modell generierten Ergebnissen beansprucht, sodass alle Rechte und Pflichten bei dem Entwickler oder der Organisation verbleiben, die das Modell verwenden.
Für Unternehmensentwickler bedeutet dies, dass das Modell sofort in der Produktion eingesetzt werden kann, ohne dass eine separate kommerzielle Lizenz ausgehandelt oder Gebühren auf Basis des Nutzungsvolumens, des Umsatzes oder der Nutzerzahl gezahlt werden müssen. Im Gegensatz zu einigen gestaffelten offenen Lizenzen anderer Anbieter gibt es keine Klauseln, die eine kostenpflichtige Lizenzpflicht auslösen, sobald ein Unternehmen eine bestimmte Größe erreicht hat.
Allerdings enthält die Vereinbarung mehrere wichtige Bedingungen, die Unternehmen einhalten müssen:
- Sicherheitsvorkehrungen: Benutzer dürfen die integrierten Sicherheitsmechanismen (sogenannte „Sicherheitsvorkehrungen“) nicht umgehen oder deaktivieren, ohne geeignete, gleichwertige Ersatzmaßnahmen für ihre spezifische Bereitstellung zu implementieren.
- Weitergabe: Jede Weitergabe des Modells oder seiner Derivate muss den vollständigen Text der Nvidia Open Model License und die entsprechende Quellenangabe („Lizenziert von Nvidia Corporation unter der Nvidia Open Model License“) enthalten.
- Compliance: Benutzer müssen alle geltenden Handelsvorschriften und -beschränkungen einhalten, wie z. B. die US-Exportkontrollgesetze.
- Bedingungen für vertrauenswürdige KI: Die Nutzung muss mit den Richtlinien von Nvidia für vertrauenswürdige KI übereinstimmen, die Grundsätze für einen verantwortungsvollen Einsatz und ethische Überlegungen umfassen.
- Streitbeilegungsklausel: Die Lizenz erlischt automatisch, wenn ein Nutzer einen Urheberrechts- oder Patentstreit gegen eine andere Partei einleitet und eine Verletzung im Zusammenhang mit dem Modell geltend macht.
Diese Bedingungen konzentrieren sich auf die Gewährleistung der Einhaltung gesetzlicher Vorschriften und einer verantwortungsvollen Nutzung und nicht auf die Einschränkung des kommerziellen Umfangs. Unternehmen müssen keine zusätzliche Genehmigung einholen oder Lizenzgebühren an Nvidia zahlen, um Produkte zu entwickeln, Dienste zu monetarisieren oder ihre Nutzerbasis zu vergrößern. Stattdessen müssen sie sicherstellen, dass ihre Einsatzpraktiken die Sicherheit respektieren, eine ordnungsgemäße Quellenangabe enthalten und alle Compliance-Verpflichtungen erfüllen.
Marktpositionierung
Mit Nemotron-Nano-9B-v2 richtet sich Nvidia an Entwickler, die ein Gleichgewicht zwischen Rechenleistung und Effizienz bei der Bereitstellung in kleinerem Maßstab finden müssen.
Die Funktionen zur Laufzeitbudgetkontrolle und zum Umschalten der Schlussfolgerungsfunktion sollen Systementwicklern mehr Flexibilität bei der Abwägung zwischen Genauigkeit und Reaktionsgeschwindigkeit bieten.
Ihre Verfügbarkeit auf Hugging Face und im Modellkatalog von Nvidia signalisiert die Absicht einer breiten Zugänglichkeit und fördert Experimente und Integration.
Die Veröffentlichung von Nemotron-Nano-9B-v2 durch Nvidia unterstreicht den anhaltenden Fokus des Unternehmens auf Effizienz und kontrollierbares Schlussfolgern in Sprachmodellen.
Durch die Zusammenführung hybrider Architekturen mit fortschrittlichen Komprimierungs- und Trainingstechniken möchte Nvidia Entwicklern Tools zur Verfügung stellen, die eine hohe Genauigkeit gewährleisten und gleichzeitig sowohl die Betriebskosten als auch die Latenz reduzieren.
Verwandter Artikel
 Nvidias OpenClaw-Variante könnte die größte Herausforderung lösen: die Sicherheit
Jensen Huang, CEO von Nvidia, ist der Ansicht, dass jedes Unternehmen eine OpenClaw-Strategie benötigt – und Nvidia ist bereit, diese bereitzustellen.Während seiner GTC-Keynote am Montag kündigte Huan
Das Pentagon schließt Vereinbarungen mit Nvidia, Microsoft und AWS ab, um KI in gesicherten Netzwerken einzusetzen.
Nachdem zuvor Einigungen mit Google, SpaceX und OpenAI erreicht worden waren, gab das US-Verteidigungsministerium am Freitag bekannt, dass es nun auch Vereinbarungen mit Nvidia, Microsoft, Amazon Web Services und Reflection AI unterzeichnet hat, um d
Nvidia stellt auf der GTC NemoClaw, den Roboter Olaf und eine 1-Billionen-Dollar-Wette vor
Der Player wird geladen…CEO Jensen Huang betrat diese Woche in seiner charakteristischen Lederjacke die Bühne der GTC-Konferenz von Nvidia, um eine zweieinhalbstündige Keynote zu halten, in der er bis
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
Nvidias OpenClaw-Variante könnte die größte Herausforderung lösen: die Sicherheit
Jensen Huang, CEO von Nvidia, ist der Ansicht, dass jedes Unternehmen eine OpenClaw-Strategie benötigt – und Nvidia ist bereit, diese bereitzustellen.Während seiner GTC-Keynote am Montag kündigte Huan
Das Pentagon schließt Vereinbarungen mit Nvidia, Microsoft und AWS ab, um KI in gesicherten Netzwerken einzusetzen.
Nachdem zuvor Einigungen mit Google, SpaceX und OpenAI erreicht worden waren, gab das US-Verteidigungsministerium am Freitag bekannt, dass es nun auch Vereinbarungen mit Nvidia, Microsoft, Amazon Web Services und Reflection AI unterzeichnet hat, um d
Nvidia stellt auf der GTC NemoClaw, den Roboter Olaf und eine 1-Billionen-Dollar-Wette vor
Der Player wird geladen…CEO Jensen Huang betrat diese Woche in seiner charakteristischen Lederjacke die Bühne der GTC-Konferenz von Nvidia, um eine zweieinhalbstündige Keynote zu halten, in der er bis
Empfehlungen zu verwandten Spezialthemen
Comic-Erstellung
 Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
 15 Tools
15 Tools
 xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

 Kommentare (1)
Kommentare (1)
![DanielThomas]()
이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.
Kleine Sprachmodelle sorgen für Aufsehen. Nach der Vorstellung des Smartwatch-großen Bildverarbeitungsmodells von Liquid AI, einem Spin-off des MIT, und des Smartphone-fähigen Modells von Google betritt nun auch Nvidia die Bühne mit seinem eigenen schlanken Konkurrenten: Nemotron-Nano-9B-V2. Dieses neue Modell ist in wichtigen Benchmarks führend und verfügt über eine einzigartige Funktion, mit der Benutzer das „Reasoning” der KI aktivieren oder deaktivieren können – im Wesentlichen ein Selbstprüfungsprozess vor der Ausgabe einer endgültigen Antwort.
Obwohl 9 Milliarden Parameter die Größenordnung der von uns kürzlich vorgestellten Mikro-Modelle mit mehreren Millionen Parametern übersteigen, hebt Nvidia dies als bedeutende Optimierung gegenüber den ursprünglichen 12 Milliarden Parametern hervor. Die überarbeitete Größe wurde speziell für den Betrieb auf einer einzigen, weit verbreiteten Nvidia A10-GPU entwickelt.
Oleksii Kuchiaev, Director of AI Model Post-Training bei Nvidia, erklärte in Antwort auf eine Frage zu X: „Wir haben das 12-Milliarden-Modell auf 9 Milliarden reduziert, damit es perfekt auf die A10 passt, eine beliebte GPU für den Einsatz. Es handelt sich außerdem um eine hybride Architektur, die es ermöglicht, größere Batch-Größen zu verarbeiten und Geschwindigkeiten zu erreichen, die bis zu sechsmal schneller sind als bei herkömmlichen Transformer-Modellen ähnlicher Größe.“
Zum Vergleich: Viele führende große Sprachmodelle arbeiten im Bereich von über 70 Milliarden Parametern. Parameter sind die internen Einstellungen, die das Verhalten eines Modells definieren, wobei höhere Werte in der Regel eine größere Leistungsfähigkeit bedeuten, aber auch deutlich mehr Rechenleistung erfordern.
Das Modell unterstützt mehrere Sprachen, darunter Englisch, Deutsch, Spanisch, Französisch, Italienisch und Japanisch. Erweiterte Funktionen decken auch Koreanisch, Portugiesisch, Russisch und Chinesisch ab. Es eignet sich gut für Aufgaben, die vom Befolgen von Anweisungen bis zum Generieren von Code reichen.
Nemotron-Nano-9B-V2 und seine Vorab-Trainingsdatensätze sind derzeit auf Hugging Face und über den eigenen Modellkatalog von Nvidia verfügbar.
Eine Fusion aus Transformer- und Mamba-Architekturen
Das Modell basiert auf Nemotron-H, einer Familie von hybriden Mamba-Transformer-Modellen, die als Grundlage für die neuesten KI-Angebote von Nvidia dienen.
Während dominante LLMs in der Regel ausschließlich auf der Transformer-Architektur und ihren Aufmerksamkeitsmechanismen basieren, können diese in Bezug auf Speicher und Rechenleistung mit zunehmender Länge der Eingabesequenzen unerschwinglich teuer werden.
Nemotron-H-Modelle und andere Modelle, die die Mamba-Architektur nutzen – entwickelt von Forschern der Carnegie Mellon University und der Princeton University – enthalten selektive Zustandsraummodelle (SSMs). Diese SSMs verwalten extrem lange Sequenzen effizient, indem sie einen internen Zustand aufrechterhalten.
Diese Schichten skalieren linear mit der Sequenzlänge, sodass sie viel längere Kontexte als die Standard-Selbstaufmerksamkeit ohne den gleichen Rechenaufwand verarbeiten können.
Ein hybrides Mamba-Transformer-Design reduziert die Kosten, indem es die meisten Aufmerksamkeits-Schichten durch lineare Zustandsraum-Schichten ersetzt. Dies kann zu einem bis zu 2- bis 3-mal höheren Durchsatz bei Aufgaben mit langem Kontext führen, während die Genauigkeit vergleichbar bleibt.
Nvidia ist mit diesem Ansatz nicht allein; andere KI-Forschungslabore, wie z. B. AI2, haben ebenfalls Modelle auf Basis der Mamba-Architektur veröffentlicht.
Schalten Sie das Schlussfolgern mit einfachen Befehlen ein oder aus
Nemotron-Nano-9B-v2 ist als einheitliches, rein textbasiertes Modell konzipiert, das sowohl zu Konversationsinteraktionen als auch zu komplexen Schlussfolgerungen fähig ist und vollständig von Grund auf trainiert wurde.
Standardmäßig generiert das System eine detaillierte Argumentationskette, bevor es seine endgültige Antwort gibt. Benutzer können dieses Verhalten mit einfachen Befehlstoken wie /think oder /no_think steuern.
Das Modell führt außerdem ein Laufzeit-„Denkbudget”-Management ein. Damit können Entwickler eine maximale Grenze für die Anzahl der Tokens festlegen, die das Modell für interne Schlussfolgerungen verwenden kann, bevor es eine Antwort liefern muss.
Dieser Mechanismus soll ein Gleichgewicht zwischen Genauigkeit und Antwortverzögerung herstellen, was für Anwendungen wie Chatbots im Kundensupport oder autonome Agenten von entscheidender Bedeutung ist.
Benchmarks zeigen starke Leistung
Die Bewertungsergebnisse zeigen eine wettbewerbsfähige Genauigkeit im Vergleich zu anderen führenden kleinen offenen Modellen. Bei Tests mit aktivierter Argumentation unter Verwendung der NeMo-Skills-Suite erzielte Nemotron-Nano-9B-v2 Ergebnisse von 72,1 % bei AIME25, 97,8 % bei MATH500, 64,0 % bei GPQA und 71,1 % bei LiveCodeBench.
Auch die Ergebnisse bei den Benchmarks für die Befolgung von Anweisungen und langen Kontexten sind stark: 90,3 % bei IFEval und 78,9 % beim RULER 128K-Test, mit zusätzlichen messbaren Gewinnen bei BFCL v3 und dem HLE-Benchmark.
In mehreren Bewertungen zeigt Nano-9B-v2 durchweg eine höhere Genauigkeit als ein gängiger Vergleichspunkt, das Qwen3-8B-Modell.
Nvidia präsentiert diese Ergebnisse mit Genauigkeits-Budget-Kurven, die veranschaulichen, wie sich die Leistung mit steigender Token-Zuteilung für die Schlussfolgerung verbessert. Das Unternehmen weist darauf hin, dass eine sorgfältige Budgetkontrolle es Entwicklern ermöglicht, sowohl die Qualität als auch die Geschwindigkeit in Produktionsumgebungen zu optimieren.
Trainiert auf synthetischen Datensätzen
Sowohl das Nano-Modell als auch die breitere Nemotron-H-Familie wurden mit einer Mischung aus sorgfältig kuratierten Webdaten, proprietären Quellen und synthetischen Trainingsdaten trainiert.
Die Trainingskorpora umfassen allgemeine Texte, Code, Mathematik, wissenschaftliche Literatur, juristische und finanzielle Dokumente sowie auf die Abstimmung ausgerichtete Frage-Antwort-Datensätze.
Nvidia bestätigt die Verwendung synthetischer Schlussfolgerungsspuren, die von anderen großen Modellen generiert wurden, um die Leistung bei komplexen Benchmark-Aufgaben zu verbessern.
Lizenzierung und kommerzielle Nutzung
Das Nano-9B-v2-Modell wird unter der Nvidia Open Model License Agreement veröffentlicht, die zuletzt im Juni 2025 aktualisiert wurde.
Diese Lizenz ist so gestaltet, dass sie freizügig und unternehmensfreundlich ist. Nvidia erklärt ausdrücklich, dass die Modelle sofort kommerziell nutzbar sind und dass Entwickler frei sind, abgeleitete Werke zu erstellen und zu verbreiten.
Entscheidend ist, dass Nvidia keine Eigentumsrechte an den vom Modell generierten Ergebnissen beansprucht, sodass alle Rechte und Pflichten bei dem Entwickler oder der Organisation verbleiben, die das Modell verwenden.
Für Unternehmensentwickler bedeutet dies, dass das Modell sofort in der Produktion eingesetzt werden kann, ohne dass eine separate kommerzielle Lizenz ausgehandelt oder Gebühren auf Basis des Nutzungsvolumens, des Umsatzes oder der Nutzerzahl gezahlt werden müssen. Im Gegensatz zu einigen gestaffelten offenen Lizenzen anderer Anbieter gibt es keine Klauseln, die eine kostenpflichtige Lizenzpflicht auslösen, sobald ein Unternehmen eine bestimmte Größe erreicht hat.
Allerdings enthält die Vereinbarung mehrere wichtige Bedingungen, die Unternehmen einhalten müssen:
- Sicherheitsvorkehrungen: Benutzer dürfen die integrierten Sicherheitsmechanismen (sogenannte „Sicherheitsvorkehrungen“) nicht umgehen oder deaktivieren, ohne geeignete, gleichwertige Ersatzmaßnahmen für ihre spezifische Bereitstellung zu implementieren.
- Weitergabe: Jede Weitergabe des Modells oder seiner Derivate muss den vollständigen Text der Nvidia Open Model License und die entsprechende Quellenangabe („Lizenziert von Nvidia Corporation unter der Nvidia Open Model License“) enthalten.
- Compliance: Benutzer müssen alle geltenden Handelsvorschriften und -beschränkungen einhalten, wie z. B. die US-Exportkontrollgesetze.
- Bedingungen für vertrauenswürdige KI: Die Nutzung muss mit den Richtlinien von Nvidia für vertrauenswürdige KI übereinstimmen, die Grundsätze für einen verantwortungsvollen Einsatz und ethische Überlegungen umfassen.
- Streitbeilegungsklausel: Die Lizenz erlischt automatisch, wenn ein Nutzer einen Urheberrechts- oder Patentstreit gegen eine andere Partei einleitet und eine Verletzung im Zusammenhang mit dem Modell geltend macht.
Diese Bedingungen konzentrieren sich auf die Gewährleistung der Einhaltung gesetzlicher Vorschriften und einer verantwortungsvollen Nutzung und nicht auf die Einschränkung des kommerziellen Umfangs. Unternehmen müssen keine zusätzliche Genehmigung einholen oder Lizenzgebühren an Nvidia zahlen, um Produkte zu entwickeln, Dienste zu monetarisieren oder ihre Nutzerbasis zu vergrößern. Stattdessen müssen sie sicherstellen, dass ihre Einsatzpraktiken die Sicherheit respektieren, eine ordnungsgemäße Quellenangabe enthalten und alle Compliance-Verpflichtungen erfüllen.
Marktpositionierung
Mit Nemotron-Nano-9B-v2 richtet sich Nvidia an Entwickler, die ein Gleichgewicht zwischen Rechenleistung und Effizienz bei der Bereitstellung in kleinerem Maßstab finden müssen.
Die Funktionen zur Laufzeitbudgetkontrolle und zum Umschalten der Schlussfolgerungsfunktion sollen Systementwicklern mehr Flexibilität bei der Abwägung zwischen Genauigkeit und Reaktionsgeschwindigkeit bieten.
Ihre Verfügbarkeit auf Hugging Face und im Modellkatalog von Nvidia signalisiert die Absicht einer breiten Zugänglichkeit und fördert Experimente und Integration.
Die Veröffentlichung von Nemotron-Nano-9B-v2 durch Nvidia unterstreicht den anhaltenden Fokus des Unternehmens auf Effizienz und kontrollierbares Schlussfolgern in Sprachmodellen.
Durch die Zusammenführung hybrider Architekturen mit fortschrittlichen Komprimierungs- und Trainingstechniken möchte Nvidia Entwicklern Tools zur Verfügung stellen, die eine hohe Genauigkeit gewährleisten und gleichzeitig sowohl die Betriebskosten als auch die Latenz reduzieren.










 Nvidias OpenClaw-Variante könnte die größte Herausforderung lösen: die Sicherheit
Jensen Huang, CEO von Nvidia, ist der Ansicht, dass jedes Unternehmen eine OpenClaw-Strategie benötigt – und Nvidia ist bereit, diese bereitzustellen.Während seiner GTC-Keynote am Montag kündigte Huan
Nvidias OpenClaw-Variante könnte die größte Herausforderung lösen: die Sicherheit
Jensen Huang, CEO von Nvidia, ist der Ansicht, dass jedes Unternehmen eine OpenClaw-Strategie benötigt – und Nvidia ist bereit, diese bereitzustellen.Während seiner GTC-Keynote am Montag kündigte Huan
 Das Pentagon schließt Vereinbarungen mit Nvidia, Microsoft und AWS ab, um KI in gesicherten Netzwerken einzusetzen.
Nachdem zuvor Einigungen mit Google, SpaceX und OpenAI erreicht worden waren, gab das US-Verteidigungsministerium am Freitag bekannt, dass es nun auch Vereinbarungen mit Nvidia, Microsoft, Amazon Web Services und Reflection AI unterzeichnet hat, um d
Das Pentagon schließt Vereinbarungen mit Nvidia, Microsoft und AWS ab, um KI in gesicherten Netzwerken einzusetzen.
Nachdem zuvor Einigungen mit Google, SpaceX und OpenAI erreicht worden waren, gab das US-Verteidigungsministerium am Freitag bekannt, dass es nun auch Vereinbarungen mit Nvidia, Microsoft, Amazon Web Services und Reflection AI unterzeichnet hat, um d
 Nvidia stellt auf der GTC NemoClaw, den Roboter Olaf und eine 1-Billionen-Dollar-Wette vor
Der Player wird geladen…CEO Jensen Huang betrat diese Woche in seiner charakteristischen Lederjacke die Bühne der GTC-Konferenz von Nvidia, um eine zweieinhalbstündige Keynote zu halten, in der er bis
Nvidia stellt auf der GTC NemoClaw, den Roboter Olaf und eine 1-Billionen-Dollar-Wette vor
Der Player wird geladen…CEO Jensen Huang betrat diese Woche in seiner charakteristischen Lederjacke die Bühne der GTC-Konferenz von Nvidia, um eine zweieinhalbstündige Keynote zu halten, in der er bis

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.













