
















 首页
首页Nvidia 推出可切换推理的开源人工智能模型 Nemotron-Nano-9B-v2
小型语言模型正掀起波澜。 继麻省理工学院衍生公司Liquid AI推出智能手表尺寸的视觉模型、谷歌推出智能手机适配产品后,英伟达现携精简版竞品Nemotron-Nano-9B-V2入局。该模型在关键基准测试中领跑同类产品,并引入独特功能:用户可启用或禁用AI"推理"机制——这实质是生成最终答案前的自我检查流程。
尽管90亿参数规模仍远超近期报道的数百万参数微型模型,但英伟达强调这是对其原始120亿参数模型的重大优化。该模型经过专门设计,可在单块广泛适用的Nvidia A10 GPU上运行。
英伟达AI模型后训练总监奥列克西·库恰耶夫在X平台回应提问时解释道:"我们将120亿参数模型精简至90亿,使其完美适配主流部署GPU A10。该模型采用混合架构,可处理更大批量数据,运行速度较同等规模传统Transformer模型提升六倍。"
作为参考,当前多数领先的大型语言模型参数规模在700亿以上。参数是定义模型行为的内部设置,数量越高通常意味着更强的能力,但也需要显著更高的计算资源。
该模型支持英语、德语、西班牙语、法语、意大利语和日语等多语言处理,扩展能力还涵盖韩语、葡萄牙语、俄语及中文。其适用场景广泛,从执行指令到代码生成皆能胜任。
Nemotron-Nano-9B-V2及其预训练数据集现已登陆Hugging Face平台,并可通过英伟达自有模型目录获取。
融合Transformer与Mamba架构
该模型基于Nemotron-H构建,该系列混合Mamba-Transformer模型是英伟达最新AI产品的基础架构。
主流大型语言模型通常仅依赖Transformer架构及其注意力机制,但随着输入序列长度增加,这种架构在内存和计算成本方面会变得极其昂贵。
Nemotron-H 模型及其他采用 Mamba 架构的模型(该架构由卡内基梅隆大学和普林斯顿大学的研究人员率先提出)整合了选择性状态空间模型(SSM)。这些 SSM 通过维护内部状态来高效管理超长序列。
这些层级随序列长度线性扩展,使其能够处理远超标准自注意力模型的上下文长度,且不产生同等计算开销。
混合Mamba-Transformer设计通过用线性时间状态空间层替代多数注意力层来降低成本。在保持相当准确率的前提下,该方案可在长上下文任务中实现2-3倍的吞吐量提升。
英伟达并非唯一采用此方法的机构;其他人工智能研究实验室(如AI2)也发布了基于Mamba架构的模型。
通过简单指令开启或关闭推理功能
Nemotron-Nano-9B-v2作为统一的纯文本模型,兼具对话交互与复杂推理能力,且完全采用从零开始的训练方式。
默认情况下,系统会在生成最终答案前创建详细推理轨迹。用户可通过/think或/no_think等简单命令令牌控制此行为。
该模型还引入了运行时"思考预算"管理机制,开发者可设定模型进行内部推理的最大令牌数量上限,超出后必须立即给出响应。
该机制旨在平衡准确性与响应延迟,这对客服聊天机器人或自主代理等应用至关重要。
基准测试展现强劲性能
评估结果表明,该模型在准确性方面与其他领先的小型开源模型具有竞争力。在启用推理功能并使用NeMo-Skills测试套件进行测试时,Nemotron-Nano-9B-v2在AIME25、MATH500、GPQA和LiveCodeBench测试中分别取得72.1%、97.8%、64.0%和71.1%的得分。
在指令遵循与长上下文基准测试中同样表现优异:IFEval达90.3%,RULER 128K测试达78.9%,并在BFCL v3及HLE基准测试中取得可量化的额外提升。
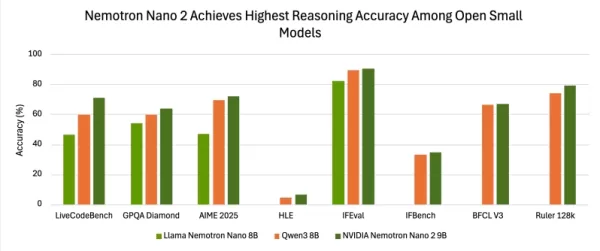
在多项评估中,Nano-9B-v2的准确率始终高于常用对照模型Qwen3-8B。
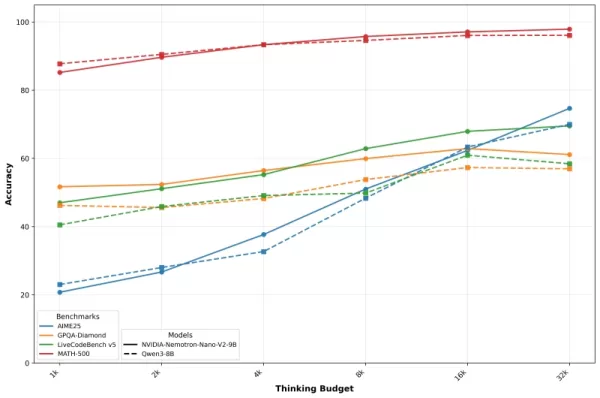
英伟达通过准确率与预算曲线展示这些结果,直观呈现推理令牌配额增加时性能的提升。该公司指出,精确的预算控制使开发者能在生产环境中同时优化质量与速度。
基于合成数据集训练
Nano模型及更广泛的Nemotron-H家族均基于精心筛选的网络数据、专有数据源及合成训练数据混合集进行训练。
训练语料库涵盖通用文本、代码、数学、科学文献、法律及金融文件,以及专注于对齐的问答数据集。
英伟达确认使用其他大型模型生成的合成推理轨迹,以提升复杂基准任务的性能。
许可与商业用途
Nano-9B-v2模型依据英伟达开放模型许可协议发布,该协议最后更新于2025年6月。
该许可协议设计为宽松且企业友好。英伟达明确声明模型开箱即具商业可用性,开发者可自由创建并分发衍生作品。
关键在于,英伟达不主张对模型生成的任何输出内容拥有所有权,所有权利与责任均归属于使用该模型的开发者或组织。
对企业开发者而言,这意味着无需另行协商商业许可协议,也无需根据使用量、营收或用户数量支付费用,即可立即将模型投入生产环境。与其他供应商分层开放许可不同,该协议不含企业规模达到特定门槛即触发付费许可的条款。
不过协议仍包含若干企业需遵守的重要条款:
- 防护机制:用户不得绕过或禁用内置安全机制(即"防护机制"),除非为其特定部署实施了等效替代方案。
- 再分发:模型或其衍生作品的任何再分发行为,必须包含完整的NVIDIA开放模型许可文本及正确署名("由NVIDIA公司根据NVIDIA开放模型许可授权")。
- 合规要求:用户须遵守所有适用的贸易法规与限制,例如美国出口管制法律。
- 可信赖AI条款:使用行为须符合NVIDIA可信赖AI指南,该指南涵盖负责任部署原则及伦理考量。
- 诉讼条款:若用户因模型相关侵权问题对第三方发起版权或专利诉讼,本许可将自动终止。
这些条款侧重于确保法律合规与负责任使用,而非限制商业规模。企业无需为开发产品、服务变现或扩大用户基数向英伟达寻求额外许可或支付版税,但必须确保部署实践符合安全要求、提供正确署名并满足所有合规义务。
市场定位
Nvidia Nemotron-Nano-9B-v2 面向需在小规模部署中平衡推理能力与部署效率的开发者。
其运算预算控制与推理开关功能,旨在赋予系统构建者在精度与响应速度之间灵活权衡的能力。
该模型在Hugging Face和英伟达模型目录的同步上线,彰显了其广泛可及性的战略意图,旨在鼓励实验与集成应用。
Nvidia发布Nemotron-Nano-9B-v2彰显了其在语言模型领域持续聚焦效率与可控推理的战略。
通过融合混合架构与先进压缩及训练技术,英伟达旨在为开发者提供兼顾高精度、低运算成本与低延迟的解决方案。
相关文章
 英伟达的OpenClaw版本或许能解决其最大的难题:安全性
英伟达首席执行官黄仁勋认为,每家公司都需要一套OpenClaw战略——而英伟达已准备好提供这一解决方案。在周一的GTC主题演讲中,黄仁勋宣布英伟达已开发出NemoClaw,这是一个源自广受欢迎的本地AI自主代理的企業级平台。该开源平台本质上是集成了企业级安全与隐私功能的OpenClaw。据英伟达介绍,其目标是将OpenClaw转变为一个安全平台,企业只需一条命令即可访问,从而能够控制代理的行为方式
五角大楼与英伟达、微软和亚马逊网络服务公司签订了协议,以便在机密网络中部署人工智能技术。
在此前与谷歌、SpaceX和OpenAI达成协议之后,美国国防部于周五宣布,它现已与Nvidia、微软、亚马逊网络服务和Reflection AI签订了合同,这些公司将会将其人工智能技术和模型部署在保密网络上,用于“合法的操作用途”。声明中还指出:“这些协议加速了将美国军队建设成为以人工智能为核心作战力量的进程,并将增强我们的战士在所有战争领域保持决策优势的能力。”这些协议的签署,正值五角大楼试图在与Anthropic就使用条款发生争议后,多元化其人工智能供应商的选择。五角大楼希望无限制地使
英伟达GTC大会发布NemoClaw、机器人奥拉夫,并押注万亿美元
正在加载播放器……本周,英伟达CEO黄仁勋身着标志性的皮夹克登上GTC大会的舞台,发表了一场长达两个半小时的主题演讲。他在演讲中预测,到2027年人工智能芯片销售额将达到1万亿美元,并宣称每家公司都需要制定“OpenClaw战略”,最后登场的是一个语无伦次的Olaf机器人,最终不得不被切断麦克风。 其核心信息不言而喻:英伟达希望成为一切事物的基石,从AI训练到自动驾驶汽车,乃至迪士尼乐园。在本期T
相关专题推荐
文字转语音
英伟达的OpenClaw版本或许能解决其最大的难题:安全性
英伟达首席执行官黄仁勋认为,每家公司都需要一套OpenClaw战略——而英伟达已准备好提供这一解决方案。在周一的GTC主题演讲中,黄仁勋宣布英伟达已开发出NemoClaw,这是一个源自广受欢迎的本地AI自主代理的企業级平台。该开源平台本质上是集成了企业级安全与隐私功能的OpenClaw。据英伟达介绍,其目标是将OpenClaw转变为一个安全平台,企业只需一条命令即可访问,从而能够控制代理的行为方式
五角大楼与英伟达、微软和亚马逊网络服务公司签订了协议,以便在机密网络中部署人工智能技术。
在此前与谷歌、SpaceX和OpenAI达成协议之后,美国国防部于周五宣布,它现已与Nvidia、微软、亚马逊网络服务和Reflection AI签订了合同,这些公司将会将其人工智能技术和模型部署在保密网络上,用于“合法的操作用途”。声明中还指出:“这些协议加速了将美国军队建设成为以人工智能为核心作战力量的进程,并将增强我们的战士在所有战争领域保持决策优势的能力。”这些协议的签署,正值五角大楼试图在与Anthropic就使用条款发生争议后,多元化其人工智能供应商的选择。五角大楼希望无限制地使
英伟达GTC大会发布NemoClaw、机器人奥拉夫,并押注万亿美元
正在加载播放器……本周,英伟达CEO黄仁勋身着标志性的皮夹克登上GTC大会的舞台,发表了一场长达两个半小时的主题演讲。他在演讲中预测,到2027年人工智能芯片销售额将达到1万亿美元,并宣称每家公司都需要制定“OpenClaw战略”,最后登场的是一个语无伦次的Olaf机器人,最终不得不被切断麦克风。 其核心信息不言而喻:英伟达希望成为一切事物的基石,从AI训练到自动驾驶汽车,乃至迪士尼乐园。在本期T
相关专题推荐
文字转语音
 专为阅读障碍设计的顶级AI语音合成应用:助力学生提升学习与阅读效率
专为阅读障碍设计的顶级AI语音合成应用:助力学生提升学习与阅读效率
探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
 10 个工具
10 个工具
 xix.ai
漫画创作
少年漫画顶级AI生成器:打造高能动作场面与特效
xix.ai
漫画创作
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

 评论 (1)
0/500
评论 (1)
0/500
![DanielThomas]()
이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.
小型语言模型正掀起波澜。 继麻省理工学院衍生公司Liquid AI推出智能手表尺寸的视觉模型、谷歌推出智能手机适配产品后,英伟达现携精简版竞品Nemotron-Nano-9B-V2入局。该模型在关键基准测试中领跑同类产品,并引入独特功能:用户可启用或禁用AI"推理"机制——这实质是生成最终答案前的自我检查流程。
尽管90亿参数规模仍远超近期报道的数百万参数微型模型,但英伟达强调这是对其原始120亿参数模型的重大优化。该模型经过专门设计,可在单块广泛适用的Nvidia A10 GPU上运行。
英伟达AI模型后训练总监奥列克西·库恰耶夫在X平台回应提问时解释道:"我们将120亿参数模型精简至90亿,使其完美适配主流部署GPU A10。该模型采用混合架构,可处理更大批量数据,运行速度较同等规模传统Transformer模型提升六倍。"
作为参考,当前多数领先的大型语言模型参数规模在700亿以上。参数是定义模型行为的内部设置,数量越高通常意味着更强的能力,但也需要显著更高的计算资源。
该模型支持英语、德语、西班牙语、法语、意大利语和日语等多语言处理,扩展能力还涵盖韩语、葡萄牙语、俄语及中文。其适用场景广泛,从执行指令到代码生成皆能胜任。
Nemotron-Nano-9B-V2及其预训练数据集现已登陆Hugging Face平台,并可通过英伟达自有模型目录获取。
融合Transformer与Mamba架构
该模型基于Nemotron-H构建,该系列混合Mamba-Transformer模型是英伟达最新AI产品的基础架构。
主流大型语言模型通常仅依赖Transformer架构及其注意力机制,但随着输入序列长度增加,这种架构在内存和计算成本方面会变得极其昂贵。
Nemotron-H 模型及其他采用 Mamba 架构的模型(该架构由卡内基梅隆大学和普林斯顿大学的研究人员率先提出)整合了选择性状态空间模型(SSM)。这些 SSM 通过维护内部状态来高效管理超长序列。
这些层级随序列长度线性扩展,使其能够处理远超标准自注意力模型的上下文长度,且不产生同等计算开销。
混合Mamba-Transformer设计通过用线性时间状态空间层替代多数注意力层来降低成本。在保持相当准确率的前提下,该方案可在长上下文任务中实现2-3倍的吞吐量提升。
英伟达并非唯一采用此方法的机构;其他人工智能研究实验室(如AI2)也发布了基于Mamba架构的模型。
通过简单指令开启或关闭推理功能
Nemotron-Nano-9B-v2作为统一的纯文本模型,兼具对话交互与复杂推理能力,且完全采用从零开始的训练方式。
默认情况下,系统会在生成最终答案前创建详细推理轨迹。用户可通过/think或/no_think等简单命令令牌控制此行为。
该模型还引入了运行时"思考预算"管理机制,开发者可设定模型进行内部推理的最大令牌数量上限,超出后必须立即给出响应。
该机制旨在平衡准确性与响应延迟,这对客服聊天机器人或自主代理等应用至关重要。
基准测试展现强劲性能
评估结果表明,该模型在准确性方面与其他领先的小型开源模型具有竞争力。在启用推理功能并使用NeMo-Skills测试套件进行测试时,Nemotron-Nano-9B-v2在AIME25、MATH500、GPQA和LiveCodeBench测试中分别取得72.1%、97.8%、64.0%和71.1%的得分。
在指令遵循与长上下文基准测试中同样表现优异:IFEval达90.3%,RULER 128K测试达78.9%,并在BFCL v3及HLE基准测试中取得可量化的额外提升。
在多项评估中,Nano-9B-v2的准确率始终高于常用对照模型Qwen3-8B。
英伟达通过准确率与预算曲线展示这些结果,直观呈现推理令牌配额增加时性能的提升。该公司指出,精确的预算控制使开发者能在生产环境中同时优化质量与速度。
基于合成数据集训练
Nano模型及更广泛的Nemotron-H家族均基于精心筛选的网络数据、专有数据源及合成训练数据混合集进行训练。
训练语料库涵盖通用文本、代码、数学、科学文献、法律及金融文件,以及专注于对齐的问答数据集。
英伟达确认使用其他大型模型生成的合成推理轨迹,以提升复杂基准任务的性能。
许可与商业用途
Nano-9B-v2模型依据英伟达开放模型许可协议发布,该协议最后更新于2025年6月。
该许可协议设计为宽松且企业友好。英伟达明确声明模型开箱即具商业可用性,开发者可自由创建并分发衍生作品。
关键在于,英伟达不主张对模型生成的任何输出内容拥有所有权,所有权利与责任均归属于使用该模型的开发者或组织。
对企业开发者而言,这意味着无需另行协商商业许可协议,也无需根据使用量、营收或用户数量支付费用,即可立即将模型投入生产环境。与其他供应商分层开放许可不同,该协议不含企业规模达到特定门槛即触发付费许可的条款。
不过协议仍包含若干企业需遵守的重要条款:
- 防护机制:用户不得绕过或禁用内置安全机制(即"防护机制"),除非为其特定部署实施了等效替代方案。
- 再分发:模型或其衍生作品的任何再分发行为,必须包含完整的NVIDIA开放模型许可文本及正确署名("由NVIDIA公司根据NVIDIA开放模型许可授权")。
- 合规要求:用户须遵守所有适用的贸易法规与限制,例如美国出口管制法律。
- 可信赖AI条款:使用行为须符合NVIDIA可信赖AI指南,该指南涵盖负责任部署原则及伦理考量。
- 诉讼条款:若用户因模型相关侵权问题对第三方发起版权或专利诉讼,本许可将自动终止。
这些条款侧重于确保法律合规与负责任使用,而非限制商业规模。企业无需为开发产品、服务变现或扩大用户基数向英伟达寻求额外许可或支付版税,但必须确保部署实践符合安全要求、提供正确署名并满足所有合规义务。
市场定位
Nvidia Nemotron-Nano-9B-v2 面向需在小规模部署中平衡推理能力与部署效率的开发者。
其运算预算控制与推理开关功能,旨在赋予系统构建者在精度与响应速度之间灵活权衡的能力。
该模型在Hugging Face和英伟达模型目录的同步上线,彰显了其广泛可及性的战略意图,旨在鼓励实验与集成应用。
Nvidia发布Nemotron-Nano-9B-v2彰显了其在语言模型领域持续聚焦效率与可控推理的战略。
通过融合混合架构与先进压缩及训练技术,英伟达旨在为开发者提供兼顾高精度、低运算成本与低延迟的解决方案。










 英伟达的OpenClaw版本或许能解决其最大的难题:安全性
英伟达首席执行官黄仁勋认为,每家公司都需要一套OpenClaw战略——而英伟达已准备好提供这一解决方案。在周一的GTC主题演讲中,黄仁勋宣布英伟达已开发出NemoClaw,这是一个源自广受欢迎的本地AI自主代理的企業级平台。该开源平台本质上是集成了企业级安全与隐私功能的OpenClaw。据英伟达介绍,其目标是将OpenClaw转变为一个安全平台,企业只需一条命令即可访问,从而能够控制代理的行为方式
英伟达的OpenClaw版本或许能解决其最大的难题:安全性
英伟达首席执行官黄仁勋认为,每家公司都需要一套OpenClaw战略——而英伟达已准备好提供这一解决方案。在周一的GTC主题演讲中,黄仁勋宣布英伟达已开发出NemoClaw,这是一个源自广受欢迎的本地AI自主代理的企業级平台。该开源平台本质上是集成了企业级安全与隐私功能的OpenClaw。据英伟达介绍,其目标是将OpenClaw转变为一个安全平台,企业只需一条命令即可访问,从而能够控制代理的行为方式
 五角大楼与英伟达、微软和亚马逊网络服务公司签订了协议,以便在机密网络中部署人工智能技术。
在此前与谷歌、SpaceX和OpenAI达成协议之后,美国国防部于周五宣布,它现已与Nvidia、微软、亚马逊网络服务和Reflection AI签订了合同,这些公司将会将其人工智能技术和模型部署在保密网络上,用于“合法的操作用途”。声明中还指出:“这些协议加速了将美国军队建设成为以人工智能为核心作战力量的进程,并将增强我们的战士在所有战争领域保持决策优势的能力。”这些协议的签署,正值五角大楼试图在与Anthropic就使用条款发生争议后,多元化其人工智能供应商的选择。五角大楼希望无限制地使
五角大楼与英伟达、微软和亚马逊网络服务公司签订了协议,以便在机密网络中部署人工智能技术。
在此前与谷歌、SpaceX和OpenAI达成协议之后,美国国防部于周五宣布,它现已与Nvidia、微软、亚马逊网络服务和Reflection AI签订了合同,这些公司将会将其人工智能技术和模型部署在保密网络上,用于“合法的操作用途”。声明中还指出:“这些协议加速了将美国军队建设成为以人工智能为核心作战力量的进程,并将增强我们的战士在所有战争领域保持决策优势的能力。”这些协议的签署,正值五角大楼试图在与Anthropic就使用条款发生争议后,多元化其人工智能供应商的选择。五角大楼希望无限制地使
 英伟达GTC大会发布NemoClaw、机器人奥拉夫,并押注万亿美元
正在加载播放器……本周,英伟达CEO黄仁勋身着标志性的皮夹克登上GTC大会的舞台,发表了一场长达两个半小时的主题演讲。他在演讲中预测,到2027年人工智能芯片销售额将达到1万亿美元,并宣称每家公司都需要制定“OpenClaw战略”,最后登场的是一个语无伦次的Olaf机器人,最终不得不被切断麦克风。 其核心信息不言而喻:英伟达希望成为一切事物的基石,从AI训练到自动驾驶汽车,乃至迪士尼乐园。在本期T
英伟达GTC大会发布NemoClaw、机器人奥拉夫,并押注万亿美元
正在加载播放器……本周,英伟达CEO黄仁勋身着标志性的皮夹克登上GTC大会的舞台,发表了一场长达两个半小时的主题演讲。他在演讲中预测,到2027年人工智能芯片销售额将达到1万亿美元,并宣称每家公司都需要制定“OpenClaw战略”,最后登场的是一个语无伦次的Olaf机器人,最终不得不被切断麦克风。 其核心信息不言而喻:英伟达希望成为一切事物的基石,从AI训练到自动驾驶汽车,乃至迪士尼乐园。在本期T

探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

이 작은 언어 모델 경쟁이 정말 흥미롭네요! Nvidia가 추론 기능을 끄고 켤 수 있는 옵션을 넣은 건 실용적이면서도 재미있는 접근법인 것 같아요. 개인적으로는 이런 경량화 모델들이 스마트워치나 스마트폰 같은 엣지 디바이스에서 어떻게 활용될지 궁금해요. 🤔 AI가 점점 더 일상 속으로 스며들고 있는 느낌이에요.













