
















 Home
HomeAMD's vLLM-ATOM Plugin Boosts Inference for Domestic Large AI Models
AMD has officially launched the vLLM-ATOM plugin, specifically designed for deploying large language models. This plugin aims to significantly enhance the inference performance of mainstream domestic large models like DeepSeek-R1 and Kimi-K2 on AMD hardware, all without disrupting existing workflows.
As an open-source inference framework built for high-concurrency scenarios, vLLM is renowned for its high memory efficiency. The new plugin from AMD delivers a more customized optimization solution for its Instinct series GPUs, enabling developers to achieve technical migration with minimal learning effort.
Seamless Performance Enhancement
The core advantage of the vLLM-ATOM plugin is its "zero-cost" deployment. Users are not required to modify their existing APIs or end-to-end workflows. The plugin automatically manages and optimizes request scheduling and kernel tuning in the background, allowing current services to transition smoothly to the AMD hardware backend.
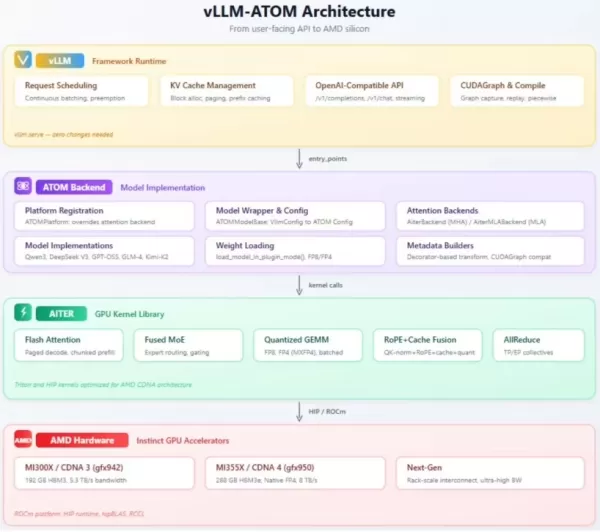
Architecturally, the plugin is structured in three layers: the top layer ensures compatibility with the OpenAI interface, the middle layer handles model execution and routing, and the bottom layer provides the core GPU kernels. This design effectively integrates mixture-of-experts (MoE) and quantization technologies, guaranteeing robust support for large-scale deployments.
Broad Compatibility Across Compute Ecosystems
The plugin targets AMD's Instinct MI350 and MI400 series high-performance GPUs. It supports not only leading Chinese large language models such as Qwen3 and GLM but also comprehensively covers diverse application scenarios, including dense models, mixture-of-experts models, and vision-language models (VLMs).
Related article
 Tencent's Xiaolongxia Surges Beyond Expectations, Team Expands Capacity 10x, Apologizes and Compensates
Tencent has officially launched WorkBuddy, an all-scenario AI intelligent agent, marking a new phase in the large model application layer race with high integration and a low deployment threshold.The product drew immediate industry attention on its l
Suno Lead Investor: Deleting Posts Won't Plug Copyright Lawsuit Hole
The much-anticipated AI music generation platform Suno is facing a tough copyright battle, and a candid remark from its lead investor may have handed the opposing side exactly the evidence they were hoping for. C.C. Gong, a partner at Menlo Ventures
Claude Opus 4.7 Launches with Reliability Valued Over Intelligence
Anthropic has maintained an aggressive pace this year, rolling out new features almost every other day. The much-anticipated Claude Opus 4.7 has just been officially released, and interestingly, Anthropic was upfront in the announcement: "This is not
Related Special Topic Recommendations
Comic Creation
Tencent's Xiaolongxia Surges Beyond Expectations, Team Expands Capacity 10x, Apologizes and Compensates
Tencent has officially launched WorkBuddy, an all-scenario AI intelligent agent, marking a new phase in the large model application layer race with high integration and a low deployment threshold.The product drew immediate industry attention on its l
Suno Lead Investor: Deleting Posts Won't Plug Copyright Lawsuit Hole
The much-anticipated AI music generation platform Suno is facing a tough copyright battle, and a candid remark from its lead investor may have handed the opposing side exactly the evidence they were hoping for. C.C. Gong, a partner at Menlo Ventures
Claude Opus 4.7 Launches with Reliability Valued Over Intelligence
Anthropic has maintained an aggressive pace this year, rolling out new features almost every other day. The much-anticipated Claude Opus 4.7 has just been officially released, and interestingly, Anthropic was upfront in the announcement: "This is not
Related Special Topic Recommendations
Comic Creation
 Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
 15 tools
15 tools
 xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

 Comments (0)
0/500
Comments (0)
0/500
AMD has officially launched the vLLM-ATOM plugin, specifically designed for deploying large language models. This plugin aims to significantly enhance the inference performance of mainstream domestic large models like DeepSeek-R1 and Kimi-K2 on AMD hardware, all without disrupting existing workflows.
As an open-source inference framework built for high-concurrency scenarios, vLLM is renowned for its high memory efficiency. The new plugin from AMD delivers a more customized optimization solution for its Instinct series GPUs, enabling developers to achieve technical migration with minimal learning effort.
Seamless Performance Enhancement
The core advantage of the vLLM-ATOM plugin is its "zero-cost" deployment. Users are not required to modify their existing APIs or end-to-end workflows. The plugin automatically manages and optimizes request scheduling and kernel tuning in the background, allowing current services to transition smoothly to the AMD hardware backend.
Architecturally, the plugin is structured in three layers: the top layer ensures compatibility with the OpenAI interface, the middle layer handles model execution and routing, and the bottom layer provides the core GPU kernels. This design effectively integrates mixture-of-experts (MoE) and quantization technologies, guaranteeing robust support for large-scale deployments.
Broad Compatibility Across Compute Ecosystems
The plugin targets AMD's Instinct MI350 and MI400 series high-performance GPUs. It supports not only leading Chinese large language models such as Qwen3 and GLM but also comprehensively covers diverse application scenarios, including dense models, mixture-of-experts models, and vision-language models (VLMs).










 Tencent's Xiaolongxia Surges Beyond Expectations, Team Expands Capacity 10x, Apologizes and Compensates
Tencent has officially launched WorkBuddy, an all-scenario AI intelligent agent, marking a new phase in the large model application layer race with high integration and a low deployment threshold.The product drew immediate industry attention on its l
Tencent's Xiaolongxia Surges Beyond Expectations, Team Expands Capacity 10x, Apologizes and Compensates
Tencent has officially launched WorkBuddy, an all-scenario AI intelligent agent, marking a new phase in the large model application layer race with high integration and a low deployment threshold.The product drew immediate industry attention on its l
 Suno Lead Investor: Deleting Posts Won't Plug Copyright Lawsuit Hole
The much-anticipated AI music generation platform Suno is facing a tough copyright battle, and a candid remark from its lead investor may have handed the opposing side exactly the evidence they were hoping for. C.C. Gong, a partner at Menlo Ventures
Suno Lead Investor: Deleting Posts Won't Plug Copyright Lawsuit Hole
The much-anticipated AI music generation platform Suno is facing a tough copyright battle, and a candid remark from its lead investor may have handed the opposing side exactly the evidence they were hoping for. C.C. Gong, a partner at Menlo Ventures
 Claude Opus 4.7 Launches with Reliability Valued Over Intelligence
Anthropic has maintained an aggressive pace this year, rolling out new features almost every other day. The much-anticipated Claude Opus 4.7 has just been officially released, and interestingly, Anthropic was upfront in the announcement: "This is not
Claude Opus 4.7 Launches with Reliability Valued Over Intelligence
Anthropic has maintained an aggressive pace this year, rolling out new features almost every other day. The much-anticipated Claude Opus 4.7 has just been officially released, and interestingly, Anthropic was upfront in the announcement: "This is not

Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai













