
















 Дом
Дом
Плагин vLLM-ATOM от AMD повышает эффективность инференса для локальных крупномасштабных моделей искусственного интеллекта
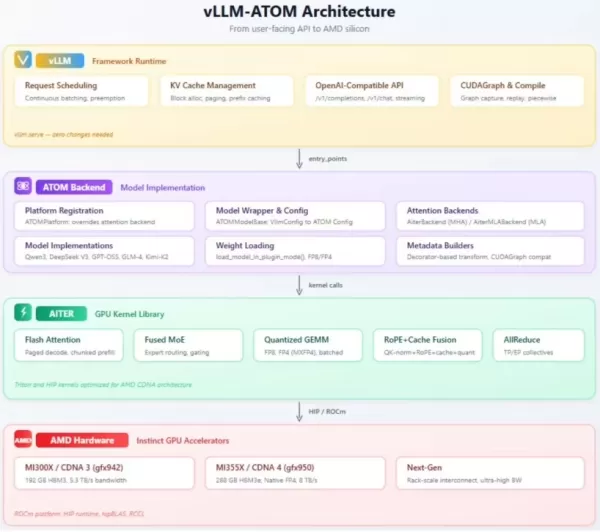
Компания AMD официально представила плагин vLLM-ATOM, специально разработанный для развертывания крупных языковых моделей. Этот плагин призван значительно повысить производительность инференса популярных отечественных крупных моделей, таких как DeepSeek-R1 и Kimi-K2, на аппаратном обеспечении AMD, при этом не нарушая существующие рабочие процессы.
Как открытая среда инференса, созданная для сценариев с высокой степенью параллелизма, vLLM славится высокой эффективностью использования памяти. Новый плагин от AMD предоставляет более адаптированное решение по оптимизации для графических процессоров серии Instinct, позволяя разработчикам осуществлять техническую миграцию с минимальными затратами на освоение.
Беспроблемное повышение производительности
Основным преимуществом плагина vLLM-ATOM является его «бесплатное» развертывание. Пользователям не требуется модифицировать существующие API или сквозные рабочие процессы. Плагин автоматически управляет и оптимизирует планирование запросов и настройку ядра в фоновом режиме, позволяя текущим сервисам плавно переходить на аппаратную платформу AMD.
С архитектурной точки зрения плагин состоит из трех уровней: верхний уровень обеспечивает совместимость с интерфейсом OpenAI, средний уровень обрабатывает выполнение и маршрутизацию моделей, а нижний уровень предоставляет основные ядра графического процессора. Такая конструкция эффективно объединяет технологии смеси экспертов (MoE) и квантования, гарантируя надежную поддержку крупномасштабных развертываний.
Широкая совместимость с различными вычислительными экосистемами
Плагин предназначен для высокопроизводительных графических процессоров AMD серий Instinct MI350 и MI400. Он поддерживает не только ведущие китайские большие языковые модели, такие как Qwen3 и GLM, но и всесторонне охватывает разнообразные сценарии применения, включая плотные модели, модели смеси экспертов и модели «зрение-язык» (VLM).
Связанная статья
 iFlytek представляет свои первые очки с искусственным интеллектом, оснащенные помощником GlassClaw, по цене 4299 юаней.
По мере того как крупные модели искусственного интеллекта все чаще используются в периферийном оборудовании, рынок умных носимых устройств получил нового значимого участника. 28 мая компания iFLYTEK официально представила свои «Очки iFLYTEK AI» на вы
Лэй Цзюнь подтвердил, что компания Xiaomi разрабатывает настольный ИИ-ассистент MiClaw, а MiMo-V2-Pro будет доступен на всех платформах
На Форуме высокого уровня по развитию Китая 2026 года глава Xiaomi Group Лэй Цзюнь подтвердил, что долгожданная настольная версия ИИ-агента «MiClaw» (краб) теперь включена в план разработки. 6 марта X
OpenAI возобновляет работу в сфере робототехники, а Automan ищет инженеров для исследований и разработок в области инфраструктуры
1 июня генеральный директор OpenAI Сэм Альтман объявил в социальных сетях, что компания вновь выходит на рынок робототехники, открыв вакансии в команде OpenAI Robotics. Компания ищет инженеров по аппа
Рекомендации по связанным специальным темам
код
iFlytek представляет свои первые очки с искусственным интеллектом, оснащенные помощником GlassClaw, по цене 4299 юаней.
По мере того как крупные модели искусственного интеллекта все чаще используются в периферийном оборудовании, рынок умных носимых устройств получил нового значимого участника. 28 мая компания iFLYTEK официально представила свои «Очки iFLYTEK AI» на вы
Лэй Цзюнь подтвердил, что компания Xiaomi разрабатывает настольный ИИ-ассистент MiClaw, а MiMo-V2-Pro будет доступен на всех платформах
На Форуме высокого уровня по развитию Китая 2026 года глава Xiaomi Group Лэй Цзюнь подтвердил, что долгожданная настольная версия ИИ-агента «MiClaw» (краб) теперь включена в план разработки. 6 марта X
OpenAI возобновляет работу в сфере робототехники, а Automan ищет инженеров для исследований и разработок в области инфраструктуры
1 июня генеральный директор OpenAI Сэм Альтман объявил в социальных сетях, что компания вновь выходит на рынок робототехники, открыв вакансии в команде OpenAI Robotics. Компания ищет инженеров по аппа
Рекомендации по связанным специальным темам
код
 Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
 10 инструментов
10 инструментов
 xix.ai
Преобразование текста в речь
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
xix.ai
Преобразование текста в речь
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai
Создание комиксов
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

 Комментарии (0)
Комментарии (0)
Компания AMD официально представила плагин vLLM-ATOM, специально разработанный для развертывания крупных языковых моделей. Этот плагин призван значительно повысить производительность инференса популярных отечественных крупных моделей, таких как DeepSeek-R1 и Kimi-K2, на аппаратном обеспечении AMD, при этом не нарушая существующие рабочие процессы.
Как открытая среда инференса, созданная для сценариев с высокой степенью параллелизма, vLLM славится высокой эффективностью использования памяти. Новый плагин от AMD предоставляет более адаптированное решение по оптимизации для графических процессоров серии Instinct, позволяя разработчикам осуществлять техническую миграцию с минимальными затратами на освоение.
Беспроблемное повышение производительности
Основным преимуществом плагина vLLM-ATOM является его «бесплатное» развертывание. Пользователям не требуется модифицировать существующие API или сквозные рабочие процессы. Плагин автоматически управляет и оптимизирует планирование запросов и настройку ядра в фоновом режиме, позволяя текущим сервисам плавно переходить на аппаратную платформу AMD.
С архитектурной точки зрения плагин состоит из трех уровней: верхний уровень обеспечивает совместимость с интерфейсом OpenAI, средний уровень обрабатывает выполнение и маршрутизацию моделей, а нижний уровень предоставляет основные ядра графического процессора. Такая конструкция эффективно объединяет технологии смеси экспертов (MoE) и квантования, гарантируя надежную поддержку крупномасштабных развертываний.
Широкая совместимость с различными вычислительными экосистемами
Плагин предназначен для высокопроизводительных графических процессоров AMD серий Instinct MI350 и MI400. Он поддерживает не только ведущие китайские большие языковые модели, такие как Qwen3 и GLM, но и всесторонне охватывает разнообразные сценарии применения, включая плотные модели, модели смеси экспертов и модели «зрение-язык» (VLM).










 iFlytek представляет свои первые очки с искусственным интеллектом, оснащенные помощником GlassClaw, по цене 4299 юаней.
По мере того как крупные модели искусственного интеллекта все чаще используются в периферийном оборудовании, рынок умных носимых устройств получил нового значимого участника. 28 мая компания iFLYTEK официально представила свои «Очки iFLYTEK AI» на вы
iFlytek представляет свои первые очки с искусственным интеллектом, оснащенные помощником GlassClaw, по цене 4299 юаней.
По мере того как крупные модели искусственного интеллекта все чаще используются в периферийном оборудовании, рынок умных носимых устройств получил нового значимого участника. 28 мая компания iFLYTEK официально представила свои «Очки iFLYTEK AI» на вы
 Лэй Цзюнь подтвердил, что компания Xiaomi разрабатывает настольный ИИ-ассистент MiClaw, а MiMo-V2-Pro будет доступен на всех платформах
На Форуме высокого уровня по развитию Китая 2026 года глава Xiaomi Group Лэй Цзюнь подтвердил, что долгожданная настольная версия ИИ-агента «MiClaw» (краб) теперь включена в план разработки. 6 марта X
Лэй Цзюнь подтвердил, что компания Xiaomi разрабатывает настольный ИИ-ассистент MiClaw, а MiMo-V2-Pro будет доступен на всех платформах
На Форуме высокого уровня по развитию Китая 2026 года глава Xiaomi Group Лэй Цзюнь подтвердил, что долгожданная настольная версия ИИ-агента «MiClaw» (краб) теперь включена в план разработки. 6 марта X
 OpenAI возобновляет работу в сфере робототехники, а Automan ищет инженеров для исследований и разработок в области инфраструктуры
1 июня генеральный директор OpenAI Сэм Альтман объявил в социальных сетях, что компания вновь выходит на рынок робототехники, открыв вакансии в команде OpenAI Robotics. Компания ищет инженеров по аппа
OpenAI возобновляет работу в сфере робототехники, а Automan ищет инженеров для исследований и разработок в области инфраструктуры
1 июня генеральный директор OpenAI Сэм Альтман объявил в социальных сетях, что компания вновь выходит на рынок робототехники, открыв вакансии в команде OpenAI Robotics. Компания ищет инженеров по аппа

Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai













