
















 Hogar
Hogar
El complemento vLLM-ATOM de AMD mejora la inferencia en modelos de IA de gran tamaño para uso doméstico
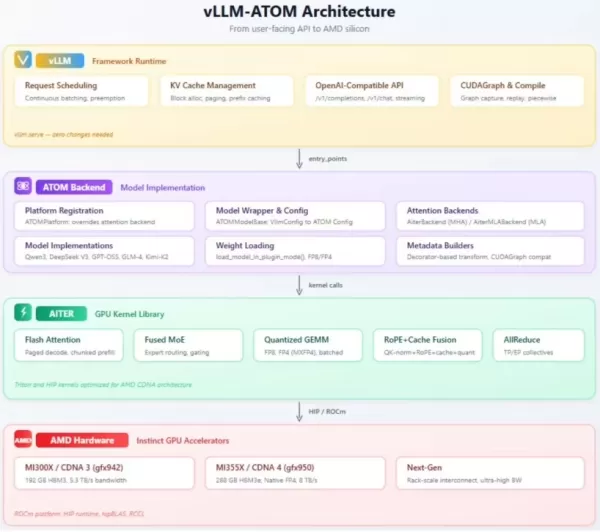
AMD ha lanzado oficialmente el complemento vLLM-ATOM, diseñado específicamente para implementar modelos de lenguaje a gran escala. Este complemento tiene como objetivo mejorar significativamente el rendimiento de inferencia de los principales modelos a gran escala nacionales, como DeepSeek-R1 y Kimi-K2, en hardware de AMD, todo ello sin alterar los flujos de trabajo existentes.
Como marco de inferencia de código abierto creado para escenarios de alta concurrencia, vLLM es conocido por su alta eficiencia de memoria. El nuevo complemento de AMD ofrece una solución de optimización más personalizada para sus GPU de la serie Instinct, lo que permite a los desarrolladores llevar a cabo la migración técnica con un esfuerzo de aprendizaje mínimo.
Mejora del rendimiento sin interrupciones
La principal ventaja del complemento vLLM-ATOM es su implementación «sin coste». Los usuarios no tienen que modificar sus API existentes ni sus flujos de trabajo de extremo a extremo. El complemento gestiona y optimiza automáticamente la programación de solicitudes y el ajuste del kernel en segundo plano, lo que permite que los servicios actuales realicen una transición fluida al backend de hardware de AMD.
Desde el punto de vista arquitectónico, el complemento está estructurado en tres capas: la capa superior garantiza la compatibilidad con la interfaz de OpenAI, la capa intermedia se encarga de la ejecución y el enrutamiento de los modelos, y la capa inferior proporciona los kernels principales de la GPU. Este diseño integra de forma eficaz tecnologías de mezcla de expertos (MoE) y cuantificación, lo que garantiza un soporte robusto para implementaciones a gran escala.
Amplia compatibilidad en todos los ecosistemas de computación
El complemento está destinado a las GPU de alto rendimiento de las series Instinct MI350 y MI400 de AMD. No solo es compatible con los principales modelos de lenguaje grandes chinos, como Qwen3 y GLM, sino que también cubre de forma exhaustiva diversos escenarios de aplicación, incluidos los modelos densos, los modelos de mezcla de expertos y los modelos de visión-lenguaje (VLM).
Artículo relacionado
 OpenAI relanza su negocio de robótica; Automan busca ingenieros para I+D en infraestructuras
El 1 de junio, el director ejecutivo de OpenAI, Sam Altman, anunció en las redes sociales que la empresa vuelve a entrar en el campo de la robótica, con la publicación de ofertas de empleo para el equ
Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
La política de búsqueda con IA obligatoria provoca una fuga de usuarios, mientras que DuckDuckGo registra un aumento de usuarios
Tras el anuncio realizado por Google en la conferencia I/O de 2026 sobre una renovación completa de su motor de búsqueda basada en la IA, muchos usuarios comenzaron a buscar alternativas más controlab
Recomendaciones de temas especiales relacionados
Texto a voz
OpenAI relanza su negocio de robótica; Automan busca ingenieros para I+D en infraestructuras
El 1 de junio, el director ejecutivo de OpenAI, Sam Altman, anunció en las redes sociales que la empresa vuelve a entrar en el campo de la robótica, con la publicación de ofertas de empleo para el equ
Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
La política de búsqueda con IA obligatoria provoca una fuga de usuarios, mientras que DuckDuckGo registra un aumento de usuarios
Tras el anuncio realizado por Google en la conferencia I/O de 2026 sobre una renovación completa de su motor de búsqueda basada en la IA, muchos usuarios comenzaron a buscar alternativas más controlab
Recomendaciones de temas especiales relacionados
Texto a voz
 Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
 10 herramientas
10 herramientas
 xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
AMD ha lanzado oficialmente el complemento vLLM-ATOM, diseñado específicamente para implementar modelos de lenguaje a gran escala. Este complemento tiene como objetivo mejorar significativamente el rendimiento de inferencia de los principales modelos a gran escala nacionales, como DeepSeek-R1 y Kimi-K2, en hardware de AMD, todo ello sin alterar los flujos de trabajo existentes.
Como marco de inferencia de código abierto creado para escenarios de alta concurrencia, vLLM es conocido por su alta eficiencia de memoria. El nuevo complemento de AMD ofrece una solución de optimización más personalizada para sus GPU de la serie Instinct, lo que permite a los desarrolladores llevar a cabo la migración técnica con un esfuerzo de aprendizaje mínimo.
Mejora del rendimiento sin interrupciones
La principal ventaja del complemento vLLM-ATOM es su implementación «sin coste». Los usuarios no tienen que modificar sus API existentes ni sus flujos de trabajo de extremo a extremo. El complemento gestiona y optimiza automáticamente la programación de solicitudes y el ajuste del kernel en segundo plano, lo que permite que los servicios actuales realicen una transición fluida al backend de hardware de AMD.
Desde el punto de vista arquitectónico, el complemento está estructurado en tres capas: la capa superior garantiza la compatibilidad con la interfaz de OpenAI, la capa intermedia se encarga de la ejecución y el enrutamiento de los modelos, y la capa inferior proporciona los kernels principales de la GPU. Este diseño integra de forma eficaz tecnologías de mezcla de expertos (MoE) y cuantificación, lo que garantiza un soporte robusto para implementaciones a gran escala.
Amplia compatibilidad en todos los ecosistemas de computación
El complemento está destinado a las GPU de alto rendimiento de las series Instinct MI350 y MI400 de AMD. No solo es compatible con los principales modelos de lenguaje grandes chinos, como Qwen3 y GLM, sino que también cubre de forma exhaustiva diversos escenarios de aplicación, incluidos los modelos densos, los modelos de mezcla de expertos y los modelos de visión-lenguaje (VLM).










 OpenAI relanza su negocio de robótica; Automan busca ingenieros para I+D en infraestructuras
El 1 de junio, el director ejecutivo de OpenAI, Sam Altman, anunció en las redes sociales que la empresa vuelve a entrar en el campo de la robótica, con la publicación de ofertas de empleo para el equ
Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
OpenAI relanza su negocio de robótica; Automan busca ingenieros para I+D en infraestructuras
El 1 de junio, el director ejecutivo de OpenAI, Sam Altman, anunció en las redes sociales que la empresa vuelve a entrar en el campo de la robótica, con la publicación de ofertas de empleo para el equ
Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
 La política de búsqueda con IA obligatoria provoca una fuga de usuarios, mientras que DuckDuckGo registra un aumento de usuarios
Tras el anuncio realizado por Google en la conferencia I/O de 2026 sobre una renovación completa de su motor de búsqueda basada en la IA, muchos usuarios comenzaron a buscar alternativas más controlab
La política de búsqueda con IA obligatoria provoca una fuga de usuarios, mientras que DuckDuckGo registra un aumento de usuarios
Tras el anuncio realizado por Google en la conferencia I/O de 2026 sobre una renovación completa de su motor de búsqueda basada en la IA, muchos usuarios comenzaron a buscar alternativas más controlab

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai













