
















 Heim
Heim
Das vLLM-ATOM-Plugin von AMD verbessert die Inferenzleistung bei großen KI-Modellen für den Heimgebrauch
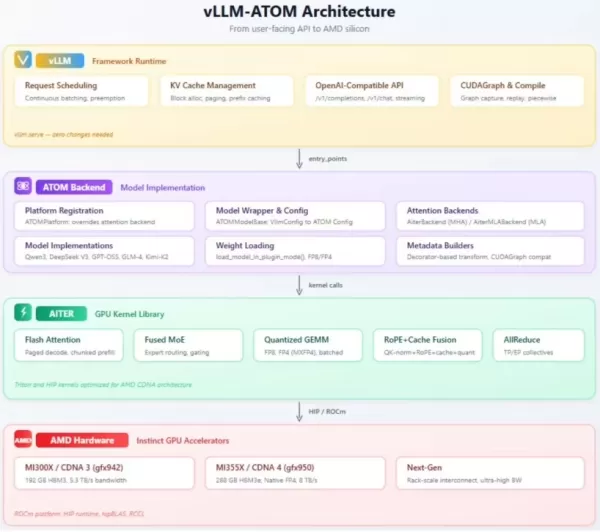
AMD hat das vLLM-ATOM-Plugin offiziell vorgestellt, das speziell für den Einsatz großer Sprachmodelle entwickelt wurde. Dieses Plugin zielt darauf ab, die Inferenzleistung gängiger inländischer Großmodelle wie DeepSeek-R1 und Kimi-K2 auf AMD-Hardware deutlich zu verbessern, ohne dabei bestehende Arbeitsabläufe zu beeinträchtigen.
Als Open-Source-Inferenz-Framework, das für Szenarien mit hoher Parallelität entwickelt wurde, ist vLLM für seine hohe Speichereffizienz bekannt. Das neue Plugin von AMD bietet eine maßgeschneiderte Optimierungslösung für die GPUs der Instinct-Serie und ermöglicht Entwicklern eine technische Migration mit minimalem Lernaufwand.
Nahtlose Leistungssteigerung
Der zentrale Vorteil des vLLM-ATOM-Plugins ist seine „kostenlose“ Bereitstellung. Nutzer müssen ihre bestehenden APIs oder End-to-End-Workflows nicht ändern. Das Plugin verwaltet und optimiert die Anforderungsplanung und die Kernel-Einstellung automatisch im Hintergrund, sodass aktuelle Dienste reibungslos auf das AMD-Hardware-Backend umgestellt werden können.
Architektonisch ist das Plugin in drei Schichten gegliedert: Die oberste Schicht gewährleistet die Kompatibilität mit der OpenAI-Schnittstelle, die mittlere Schicht übernimmt die Modellausführung und das Routing, und die unterste Schicht stellt die zentralen GPU-Kernel bereit. Dieses Design integriert auf effektive Weise „Mixture-of-Experts“- (MoE) und Quantisierungstechnologien und garantiert so eine robuste Unterstützung für groß angelegte Bereitstellungen.
Breite Kompatibilität über Rechenökosysteme hinweg
Das Plugin ist auf die Hochleistungs-GPUs der AMD Instinct MI350- und MI400-Serie ausgerichtet. Es unterstützt nicht nur führende chinesische große Sprachmodelle wie Qwen3 und GLM, sondern deckt auch umfassend verschiedene Anwendungsszenarien ab, darunter dichte Modelle, „Mixture-of-Experts“-Modelle und Vision-Language-Modelle (VLMs).
Verwandter Artikel
 Richtlinie zur obligatorischen KI-Suche führt zu Nutzerabwanderung, DuckDuckGo verzeichnet Nutzeranstieg
Nachdem Google auf seiner I/O-Konferenz 2026 eine umfassende KI-Umgestaltung seiner Suchmaschine angekündigt hatte, suchten viele Nutzer nach besser kontrollierbaren Alternativen, da es keine einfache
Xiaohongshu strukturiert sich neu: Conan wird zum Präsidenten ernannt, die Hauptabteilung für KI „Dots“ und die Auslandsabteilung „Rednote“ werden gegründet
Am 30. April versandte Xiaohongshu ein internes Memo an alle Mitarbeiter, in dem die Einführung einer neuen organisatorischen Umstrukturierung angekündigt wurde. Im Mittelpunkt dieser Veränderung steh
Tencent-Spiel „Xiaolongxia“ übertrifft alle Erwartungen, das Team verzehnfacht seine Kapazitäten, entschuldigt sich und leistet Entschädigung
Tencent hat offiziell „WorkBuddy“ eingeführt, einen KI-Agenten für alle Anwendungsszenarien, der mit seiner hohen Integrationsfähigkeit und niedrigen Einführungshürde eine neue Phase im Wettlauf um di
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
Richtlinie zur obligatorischen KI-Suche führt zu Nutzerabwanderung, DuckDuckGo verzeichnet Nutzeranstieg
Nachdem Google auf seiner I/O-Konferenz 2026 eine umfassende KI-Umgestaltung seiner Suchmaschine angekündigt hatte, suchten viele Nutzer nach besser kontrollierbaren Alternativen, da es keine einfache
Xiaohongshu strukturiert sich neu: Conan wird zum Präsidenten ernannt, die Hauptabteilung für KI „Dots“ und die Auslandsabteilung „Rednote“ werden gegründet
Am 30. April versandte Xiaohongshu ein internes Memo an alle Mitarbeiter, in dem die Einführung einer neuen organisatorischen Umstrukturierung angekündigt wurde. Im Mittelpunkt dieser Veränderung steh
Tencent-Spiel „Xiaolongxia“ übertrifft alle Erwartungen, das Team verzehnfacht seine Kapazitäten, entschuldigt sich und leistet Entschädigung
Tencent hat offiziell „WorkBuddy“ eingeführt, einen KI-Agenten für alle Anwendungsszenarien, der mit seiner hohen Integrationsfähigkeit und niedrigen Einführungshürde eine neue Phase im Wettlauf um di
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
 Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
 10 Tools
10 Tools
 xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
AMD hat das vLLM-ATOM-Plugin offiziell vorgestellt, das speziell für den Einsatz großer Sprachmodelle entwickelt wurde. Dieses Plugin zielt darauf ab, die Inferenzleistung gängiger inländischer Großmodelle wie DeepSeek-R1 und Kimi-K2 auf AMD-Hardware deutlich zu verbessern, ohne dabei bestehende Arbeitsabläufe zu beeinträchtigen.
Als Open-Source-Inferenz-Framework, das für Szenarien mit hoher Parallelität entwickelt wurde, ist vLLM für seine hohe Speichereffizienz bekannt. Das neue Plugin von AMD bietet eine maßgeschneiderte Optimierungslösung für die GPUs der Instinct-Serie und ermöglicht Entwicklern eine technische Migration mit minimalem Lernaufwand.
Nahtlose Leistungssteigerung
Der zentrale Vorteil des vLLM-ATOM-Plugins ist seine „kostenlose“ Bereitstellung. Nutzer müssen ihre bestehenden APIs oder End-to-End-Workflows nicht ändern. Das Plugin verwaltet und optimiert die Anforderungsplanung und die Kernel-Einstellung automatisch im Hintergrund, sodass aktuelle Dienste reibungslos auf das AMD-Hardware-Backend umgestellt werden können.
Architektonisch ist das Plugin in drei Schichten gegliedert: Die oberste Schicht gewährleistet die Kompatibilität mit der OpenAI-Schnittstelle, die mittlere Schicht übernimmt die Modellausführung und das Routing, und die unterste Schicht stellt die zentralen GPU-Kernel bereit. Dieses Design integriert auf effektive Weise „Mixture-of-Experts“- (MoE) und Quantisierungstechnologien und garantiert so eine robuste Unterstützung für groß angelegte Bereitstellungen.
Breite Kompatibilität über Rechenökosysteme hinweg
Das Plugin ist auf die Hochleistungs-GPUs der AMD Instinct MI350- und MI400-Serie ausgerichtet. Es unterstützt nicht nur führende chinesische große Sprachmodelle wie Qwen3 und GLM, sondern deckt auch umfassend verschiedene Anwendungsszenarien ab, darunter dichte Modelle, „Mixture-of-Experts“-Modelle und Vision-Language-Modelle (VLMs).










 Richtlinie zur obligatorischen KI-Suche führt zu Nutzerabwanderung, DuckDuckGo verzeichnet Nutzeranstieg
Nachdem Google auf seiner I/O-Konferenz 2026 eine umfassende KI-Umgestaltung seiner Suchmaschine angekündigt hatte, suchten viele Nutzer nach besser kontrollierbaren Alternativen, da es keine einfache
Richtlinie zur obligatorischen KI-Suche führt zu Nutzerabwanderung, DuckDuckGo verzeichnet Nutzeranstieg
Nachdem Google auf seiner I/O-Konferenz 2026 eine umfassende KI-Umgestaltung seiner Suchmaschine angekündigt hatte, suchten viele Nutzer nach besser kontrollierbaren Alternativen, da es keine einfache
 Xiaohongshu strukturiert sich neu: Conan wird zum Präsidenten ernannt, die Hauptabteilung für KI „Dots“ und die Auslandsabteilung „Rednote“ werden gegründet
Am 30. April versandte Xiaohongshu ein internes Memo an alle Mitarbeiter, in dem die Einführung einer neuen organisatorischen Umstrukturierung angekündigt wurde. Im Mittelpunkt dieser Veränderung steh
Xiaohongshu strukturiert sich neu: Conan wird zum Präsidenten ernannt, die Hauptabteilung für KI „Dots“ und die Auslandsabteilung „Rednote“ werden gegründet
Am 30. April versandte Xiaohongshu ein internes Memo an alle Mitarbeiter, in dem die Einführung einer neuen organisatorischen Umstrukturierung angekündigt wurde. Im Mittelpunkt dieser Veränderung steh
 Tencent-Spiel „Xiaolongxia“ übertrifft alle Erwartungen, das Team verzehnfacht seine Kapazitäten, entschuldigt sich und leistet Entschädigung
Tencent hat offiziell „WorkBuddy“ eingeführt, einen KI-Agenten für alle Anwendungsszenarien, der mit seiner hohen Integrationsfähigkeit und niedrigen Einführungshürde eine neue Phase im Wettlauf um di
Tencent-Spiel „Xiaolongxia“ übertrifft alle Erwartungen, das Team verzehnfacht seine Kapazitäten, entschuldigt sich und leistet Entschädigung
Tencent hat offiziell „WorkBuddy“ eingeführt, einen KI-Agenten für alle Anwendungsszenarien, der mit seiner hohen Integrationsfähigkeit und niedrigen Einführungshürde eine neue Phase im Wettlauf um di

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai













