
















 Lar
Lar
O plug-in vLLM-ATOM da AMD otimiza a inferência para grandes modelos de IA de uso doméstico
A AMD lançou oficialmente o plug-in vLLM-ATOM, projetado especificamente para a implantação de grandes modelos de linguagem. Esse plug-in visa melhorar significativamente o desempenho de inferência de grandes modelos nacionais de uso comum, como o DeepSeek-R1 e o Kimi-K2, em hardware AMD, sem interromper os fluxos de trabalho existentes.
Como uma estrutura de inferência de código aberto criada para cenários de alta simultaneidade, o vLLM é reconhecido por sua alta eficiência de memória. O novo plug-in da AMD oferece uma solução de otimização mais personalizada para suas GPUs da série Instinct, permitindo que os desenvolvedores realizem a migração técnica com o mínimo de esforço de aprendizagem.
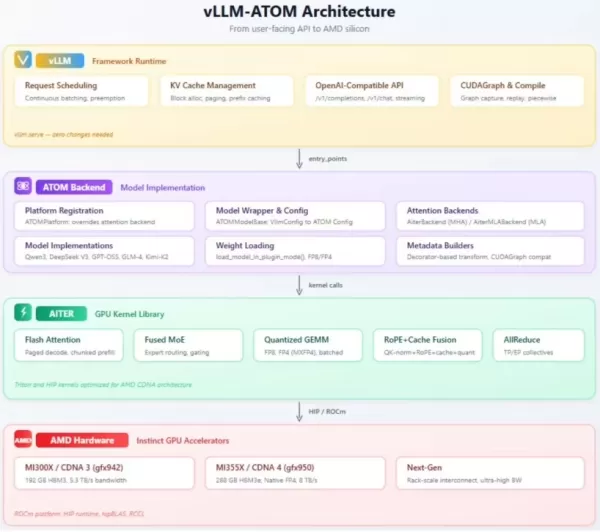
Melhoria de desempenho sem interrupções
A principal vantagem do plug-in vLLM-ATOM é sua implantação de “custo zero”. Os usuários não precisam modificar suas APIs existentes nem seus fluxos de trabalho de ponta a ponta. O plug-in gerencia e otimiza automaticamente o agendamento de solicitações e o ajuste do kernel em segundo plano, permitindo que os serviços atuais façam uma transição suave para o backend de hardware da AMD.
Em termos de arquitetura, o plug-in é estruturado em três camadas: a camada superior garante a compatibilidade com a interface OpenAI, a camada intermediária lida com a execução e o roteamento do modelo, e a camada inferior fornece os kernels principais da GPU. Esse design integra efetivamente tecnologias de mistura de especialistas (MoE) e quantização, garantindo suporte robusto para implantações em grande escala.
Ampla compatibilidade em ecossistemas de computação
O plug-in é voltado para as GPUs de alto desempenho das séries Instinct MI350 e MI400 da AMD. Ele oferece suporte não apenas aos principais modelos de linguagem de grande porte da China, como Qwen3 e GLM, mas também abrange de forma abrangente diversos cenários de aplicação, incluindo modelos densos, modelos de mistura de especialistas e modelos de visão-linguagem (VLMs).
Artigo relacionado
 A OpenAI retoma suas atividades no setor de robótica; a Automan busca engenheiros para pesquisa e desenvolvimento de infraestrutura
Em 1º de junho, o CEO da OpenAI, Sam Altman, anunciou nas redes sociais que a empresa está voltando ao setor de robótica, divulgando vagas para a equipe da OpenAI Robotics. A empresa está contratando
A Bain prevê um mercado de SaaS de US$ 100 bilhões na automação por IA agênica
A Bain & Company estimou um mercado de US$ 100 bilhões nos EUA para empresas de SaaS que utilizam IA agentiva. A empresa afirmou que esse mercado decorre da automação de tarefas de coordenação dentro
Política obrigatória de pesquisa com IA impulsiona êxodo; DuckDuckGo registra aumento no número de usuários
Após o anúncio feito pela Google na conferência I/O de 2026 sobre uma reformulação completa do seu mecanismo de busca com IA, muitos usuários começaram a procurar alternativas mais controláveis, já qu
Recomendações de tópicos especiais relacionados
código
A OpenAI retoma suas atividades no setor de robótica; a Automan busca engenheiros para pesquisa e desenvolvimento de infraestrutura
Em 1º de junho, o CEO da OpenAI, Sam Altman, anunciou nas redes sociais que a empresa está voltando ao setor de robótica, divulgando vagas para a equipe da OpenAI Robotics. A empresa está contratando
A Bain prevê um mercado de SaaS de US$ 100 bilhões na automação por IA agênica
A Bain & Company estimou um mercado de US$ 100 bilhões nos EUA para empresas de SaaS que utilizam IA agentiva. A empresa afirmou que esse mercado decorre da automação de tarefas de coordenação dentro
Política obrigatória de pesquisa com IA impulsiona êxodo; DuckDuckGo registra aumento no número de usuários
Após o anúncio feito pela Google na conferência I/O de 2026 sobre uma reformulação completa do seu mecanismo de busca com IA, muitos usuários começaram a procurar alternativas mais controláveis, já qu
Recomendações de tópicos especiais relacionados
código
 Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
 10 ferramentas
10 ferramentas
 xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

 Comentários (0)
Comentários (0)
A AMD lançou oficialmente o plug-in vLLM-ATOM, projetado especificamente para a implantação de grandes modelos de linguagem. Esse plug-in visa melhorar significativamente o desempenho de inferência de grandes modelos nacionais de uso comum, como o DeepSeek-R1 e o Kimi-K2, em hardware AMD, sem interromper os fluxos de trabalho existentes.
Como uma estrutura de inferência de código aberto criada para cenários de alta simultaneidade, o vLLM é reconhecido por sua alta eficiência de memória. O novo plug-in da AMD oferece uma solução de otimização mais personalizada para suas GPUs da série Instinct, permitindo que os desenvolvedores realizem a migração técnica com o mínimo de esforço de aprendizagem.
Melhoria de desempenho sem interrupções
A principal vantagem do plug-in vLLM-ATOM é sua implantação de “custo zero”. Os usuários não precisam modificar suas APIs existentes nem seus fluxos de trabalho de ponta a ponta. O plug-in gerencia e otimiza automaticamente o agendamento de solicitações e o ajuste do kernel em segundo plano, permitindo que os serviços atuais façam uma transição suave para o backend de hardware da AMD.
Em termos de arquitetura, o plug-in é estruturado em três camadas: a camada superior garante a compatibilidade com a interface OpenAI, a camada intermediária lida com a execução e o roteamento do modelo, e a camada inferior fornece os kernels principais da GPU. Esse design integra efetivamente tecnologias de mistura de especialistas (MoE) e quantização, garantindo suporte robusto para implantações em grande escala.
Ampla compatibilidade em ecossistemas de computação
O plug-in é voltado para as GPUs de alto desempenho das séries Instinct MI350 e MI400 da AMD. Ele oferece suporte não apenas aos principais modelos de linguagem de grande porte da China, como Qwen3 e GLM, mas também abrange de forma abrangente diversos cenários de aplicação, incluindo modelos densos, modelos de mistura de especialistas e modelos de visão-linguagem (VLMs).










 A OpenAI retoma suas atividades no setor de robótica; a Automan busca engenheiros para pesquisa e desenvolvimento de infraestrutura
Em 1º de junho, o CEO da OpenAI, Sam Altman, anunciou nas redes sociais que a empresa está voltando ao setor de robótica, divulgando vagas para a equipe da OpenAI Robotics. A empresa está contratando
A Bain prevê um mercado de SaaS de US$ 100 bilhões na automação por IA agênica
A Bain & Company estimou um mercado de US$ 100 bilhões nos EUA para empresas de SaaS que utilizam IA agentiva. A empresa afirmou que esse mercado decorre da automação de tarefas de coordenação dentro
A OpenAI retoma suas atividades no setor de robótica; a Automan busca engenheiros para pesquisa e desenvolvimento de infraestrutura
Em 1º de junho, o CEO da OpenAI, Sam Altman, anunciou nas redes sociais que a empresa está voltando ao setor de robótica, divulgando vagas para a equipe da OpenAI Robotics. A empresa está contratando
A Bain prevê um mercado de SaaS de US$ 100 bilhões na automação por IA agênica
A Bain & Company estimou um mercado de US$ 100 bilhões nos EUA para empresas de SaaS que utilizam IA agentiva. A empresa afirmou que esse mercado decorre da automação de tarefas de coordenação dentro
 Política obrigatória de pesquisa com IA impulsiona êxodo; DuckDuckGo registra aumento no número de usuários
Após o anúncio feito pela Google na conferência I/O de 2026 sobre uma reformulação completa do seu mecanismo de busca com IA, muitos usuários começaram a procurar alternativas mais controláveis, já qu
Política obrigatória de pesquisa com IA impulsiona êxodo; DuckDuckGo registra aumento no número de usuários
Após o anúncio feito pela Google na conferência I/O de 2026 sobre uma reformulação completa do seu mecanismo de busca com IA, muitos usuários começaram a procurar alternativas mais controláveis, já qu

Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai













