
















 Maison
Maison
Le plugin vLLM-ATOM d'AMD améliore les performances d'inférence des grands modèles d'IA destinés à un usage domestique
AMD a officiellement lancé le plugin vLLM-ATOM, spécialement conçu pour le déploiement de grands modèles linguistiques. Ce plugin vise à améliorer considérablement les performances d'inférence des grands modèles nationaux courants, tels que DeepSeek-R1 et Kimi-K2, sur le matériel AMD, sans perturber les flux de travail existants.
En tant que framework d'inférence open source conçu pour les scénarios à forte concurrence, vLLM est réputé pour son excellente efficacité mémoire. Le nouveau plugin d'AMD offre une solution d'optimisation plus personnalisée pour ses GPU de la série Instinct, permettant aux développeurs de réaliser une migration technique avec un effort d'apprentissage minimal.
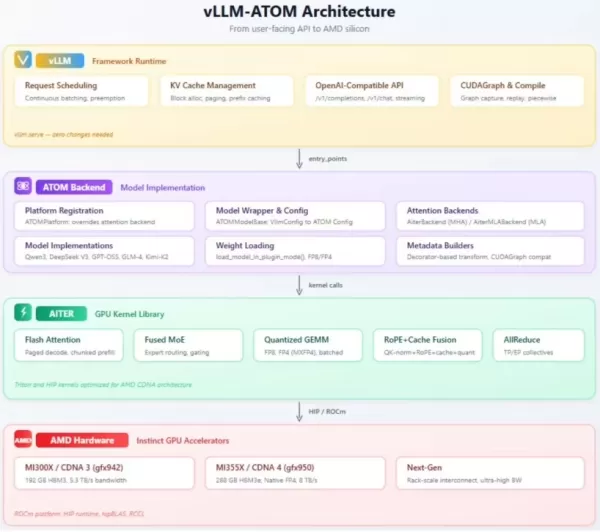
Amélioration transparente des performances
Le principal avantage du plugin vLLM-ATOM réside dans son déploiement « sans coût ». Les utilisateurs n’ont pas besoin de modifier leurs API existantes ni leurs workflows de bout en bout. Le plugin gère et optimise automatiquement la planification des requêtes et le réglage du noyau en arrière-plan, permettant aux services actuels de migrer en douceur vers le backend matériel AMD.
Sur le plan architectural, le plugin est structuré en trois couches : la couche supérieure assure la compatibilité avec l'interface OpenAI, la couche intermédiaire gère l'exécution et le routage des modèles, et la couche inférieure fournit les noyaux GPU de base. Cette conception intègre efficacement les technologies de « mixture-of-experts » (MoE) et de quantification, garantissant une prise en charge robuste pour les déploiements à grande échelle.
Large compatibilité avec les écosystèmes de calcul
Le plugin cible les GPU haute performance des séries Instinct MI350 et MI400 d'AMD. Il prend en charge non seulement les principaux modèles linguistiques chinois de grande envergure tels que Qwen3 et GLM, mais couvre également de manière exhaustive divers scénarios d'application, y compris les modèles denses, les modèles de type « mixture-of-experts » et les modèles vision-langage (VLM).
Article connexe
 Google I/O 2026 dévoile l'interaction vocale avec la boîte de réception Gmail
Google continue d'intégrer l'IA à votre boîte de réception. Lors de la conférence des développeurs IO 2026 qui s'est tenue mardi, l'entreprise a enrichi sa fonctionnalité « AI Inbox » de Gmail d'une I
iFlytek lance ses lunettes intelligentes dotées de l’assistant GlassClaw pour 4299 yuans chinois.
À mesure que les grands modèles d'IA se déplacent de plus en plus vers le matériel périphérique, le marché des appareils portables intelligents voit arriver un nouveau joueur important. Le 28 mai, iFLYTEK a officiellement lancé ses « lunettes AI iFLY
Lei Jun confirme que l'agent IA de bureau de Xiaomi, MiClaw, est en cours de développement, tandis que MiMo-V2-Pro est lancé sur toutes les plateformes
Lors du Forum de haut niveau sur le développement de la Chine 2026, Lei Jun, du groupe Xiaomi, a confirmé que la version de bureau tant attendue de l'agent IA « MiClaw » (crabe) figurait désormais dan
Recommandations de sujets spéciaux liés
code
Google I/O 2026 dévoile l'interaction vocale avec la boîte de réception Gmail
Google continue d'intégrer l'IA à votre boîte de réception. Lors de la conférence des développeurs IO 2026 qui s'est tenue mardi, l'entreprise a enrichi sa fonctionnalité « AI Inbox » de Gmail d'une I
iFlytek lance ses lunettes intelligentes dotées de l’assistant GlassClaw pour 4299 yuans chinois.
À mesure que les grands modèles d'IA se déplacent de plus en plus vers le matériel périphérique, le marché des appareils portables intelligents voit arriver un nouveau joueur important. Le 28 mai, iFLYTEK a officiellement lancé ses « lunettes AI iFLY
Lei Jun confirme que l'agent IA de bureau de Xiaomi, MiClaw, est en cours de développement, tandis que MiMo-V2-Pro est lancé sur toutes les plateformes
Lors du Forum de haut niveau sur le développement de la Chine 2026, Lei Jun, du groupe Xiaomi, a confirmé que la version de bureau tant attendue de l'agent IA « MiClaw » (crabe) figurait désormais dan
Recommandations de sujets spéciaux liés
code
 Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
 10 outils
10 outils
 xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
AMD a officiellement lancé le plugin vLLM-ATOM, spécialement conçu pour le déploiement de grands modèles linguistiques. Ce plugin vise à améliorer considérablement les performances d'inférence des grands modèles nationaux courants, tels que DeepSeek-R1 et Kimi-K2, sur le matériel AMD, sans perturber les flux de travail existants.
En tant que framework d'inférence open source conçu pour les scénarios à forte concurrence, vLLM est réputé pour son excellente efficacité mémoire. Le nouveau plugin d'AMD offre une solution d'optimisation plus personnalisée pour ses GPU de la série Instinct, permettant aux développeurs de réaliser une migration technique avec un effort d'apprentissage minimal.
Amélioration transparente des performances
Le principal avantage du plugin vLLM-ATOM réside dans son déploiement « sans coût ». Les utilisateurs n’ont pas besoin de modifier leurs API existantes ni leurs workflows de bout en bout. Le plugin gère et optimise automatiquement la planification des requêtes et le réglage du noyau en arrière-plan, permettant aux services actuels de migrer en douceur vers le backend matériel AMD.
Sur le plan architectural, le plugin est structuré en trois couches : la couche supérieure assure la compatibilité avec l'interface OpenAI, la couche intermédiaire gère l'exécution et le routage des modèles, et la couche inférieure fournit les noyaux GPU de base. Cette conception intègre efficacement les technologies de « mixture-of-experts » (MoE) et de quantification, garantissant une prise en charge robuste pour les déploiements à grande échelle.
Large compatibilité avec les écosystèmes de calcul
Le plugin cible les GPU haute performance des séries Instinct MI350 et MI400 d'AMD. Il prend en charge non seulement les principaux modèles linguistiques chinois de grande envergure tels que Qwen3 et GLM, mais couvre également de manière exhaustive divers scénarios d'application, y compris les modèles denses, les modèles de type « mixture-of-experts » et les modèles vision-langage (VLM).










 Google I/O 2026 dévoile l'interaction vocale avec la boîte de réception Gmail
Google continue d'intégrer l'IA à votre boîte de réception. Lors de la conférence des développeurs IO 2026 qui s'est tenue mardi, l'entreprise a enrichi sa fonctionnalité « AI Inbox » de Gmail d'une I
Google I/O 2026 dévoile l'interaction vocale avec la boîte de réception Gmail
Google continue d'intégrer l'IA à votre boîte de réception. Lors de la conférence des développeurs IO 2026 qui s'est tenue mardi, l'entreprise a enrichi sa fonctionnalité « AI Inbox » de Gmail d'une I
 iFlytek lance ses lunettes intelligentes dotées de l’assistant GlassClaw pour 4299 yuans chinois.
À mesure que les grands modèles d'IA se déplacent de plus en plus vers le matériel périphérique, le marché des appareils portables intelligents voit arriver un nouveau joueur important. Le 28 mai, iFLYTEK a officiellement lancé ses « lunettes AI iFLY
iFlytek lance ses lunettes intelligentes dotées de l’assistant GlassClaw pour 4299 yuans chinois.
À mesure que les grands modèles d'IA se déplacent de plus en plus vers le matériel périphérique, le marché des appareils portables intelligents voit arriver un nouveau joueur important. Le 28 mai, iFLYTEK a officiellement lancé ses « lunettes AI iFLY
 Lei Jun confirme que l'agent IA de bureau de Xiaomi, MiClaw, est en cours de développement, tandis que MiMo-V2-Pro est lancé sur toutes les plateformes
Lors du Forum de haut niveau sur le développement de la Chine 2026, Lei Jun, du groupe Xiaomi, a confirmé que la version de bureau tant attendue de l'agent IA « MiClaw » (crabe) figurait désormais dan
Lei Jun confirme que l'agent IA de bureau de Xiaomi, MiClaw, est en cours de développement, tandis que MiMo-V2-Pro est lancé sur toutes les plateformes
Lors du Forum de haut niveau sur le développement de la Chine 2026, Lei Jun, du groupe Xiaomi, a confirmé que la version de bureau tant attendue de l'agent IA « MiClaw » (crabe) figurait désormais dan

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai













