
















 首页
首页OpenAI 发布两款先进的开源权重 AI 模型
OpenAI 在周二宣布推出两款开源权重 AI 推理模型,其性能可与 o 系列媲美。两款模型均可在 Hugging Face 上免费下载,OpenAI 宣称它们在多个开源模型基准测试中表现“顶尖”。
模型提供两种变体:功能强大的 gpt-oss-120b,可在一块 Nvidia GPU 上运行;轻量级 gpt-oss-20b,设计为可在配备 16GB 内存的普通笔记本电脑上运行。
此次发布是 OpenAI 自五年前推出 GPT-2 以来首次发布开源语言模型。
在简报会上,OpenAI 表示,其开源模型可通过连接到更先进的云端 AI 系统来处理复杂查询,正如 TechCrunch 此前报道的那样。这允许开发者在需要时将开源模型链接到 OpenAI 的专有模型,以执行如图像处理等任务。
尽管 OpenAI 最初拥抱开源 AI 模型,但其发展模式已基本转向专有,依靠向企业和开发者提供 API 访问权限,业务蓬勃发展。
今年 1 月,首席执行官 Sam Altman 承认,OpenAI 在未优先发展开源技术方面可能犯了错误。公司现面临来自中国 AI 实验室(如 DeepSeek、Alibaba 的 Qwen 和 Moonshot AI)的激烈竞争,这些实验室凭借高性能的开源模型获得了市场吸引力。(Meta 的 Llama 模型曾是开源 AI 领域的领导者,但在过去一年已落后。)
7 月,特朗普政府鼓励美国 AI 开发者开放更多技术,以推动全球范围内符合美国价值观的 AI 发展。
科技与风投领袖亮相 Disrupt 2025
Netflix、ElevenLabs、Wayve 和 Sequoia Capital 等知名企业名列 Disrupt 2025 议程,分享推动创业成功和创新的见解。不要错过 TechCrunch Disrupt 二十周年纪念,与科技顶尖声音学习的机会——现在购票,在 8 月 7 日价格上涨前可节省高达 675 美元。
科技与风投领袖亮相 Disrupt 2025
Netflix、ElevenLabs、Wayve 和 Sequoia Capital 等知名企业名列 Disrupt 2025 议程,分享推动创业成功和创新的见解。不要错过 TechCrunch Disrupt 二十周年纪念,与科技顶尖声音学习的机会——现在购票,在 8 月 7 日价格上涨前可节省高达 675 美元。
旧金山 | 2025 年 10 月 27-29 日 立即注册通过 gpt-oss,OpenAI 旨在吸引开发者并响应特朗普政府的推动,双方均注意到中国 AI 实验室在开源领域的崛起。
“自 2015 年成立以来,OpenAI 的使命一直是推进 AGI 以造福全人类,”首席执行官 Sam Altman 在对 TechCrunch 的声明中表示。“我们很高兴看到世界基于植根于美国民主价值观的开源 AI 框架进行构建,自由访问且广泛有益。”

(图片由 Tomohiro Ohsumi/Getty Images 提供)图片来源:Tomohiro Ohsumi / Getty Images 模型性能概览
OpenAI 设计其开源模型以在开源权重 AI 系统中领先,公司声称已实现这一目标。
在 Codeforces 的竞争性编程测试(使用工具)中,gpt-oss-120b 得分 2622,gpt-oss-20b 得分 2516,超越 DeepSeek 的 R1,但落后于 o3 和 o4-mini。
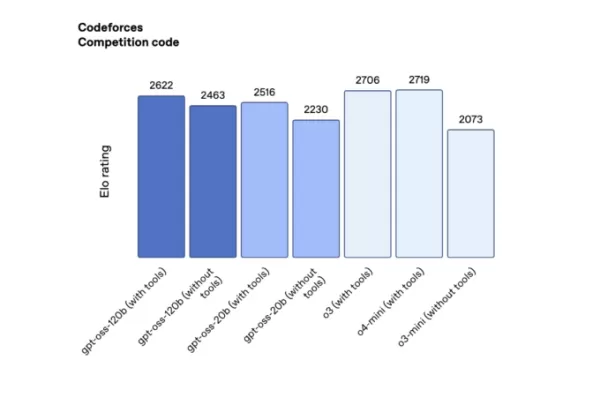
OpenAI 开源模型在 Codeforces 上的性能(来源:OpenAI)。 在“人类最后考试”(一项覆盖多学科的严格众包测试,使用工具)中,gpt-oss-120b 和 gpt-oss-20b 分别获得 19% 和 17.3% 的成绩,优于 DeepSeek 和 Qwen 的领先开源模型,但不及 o3。
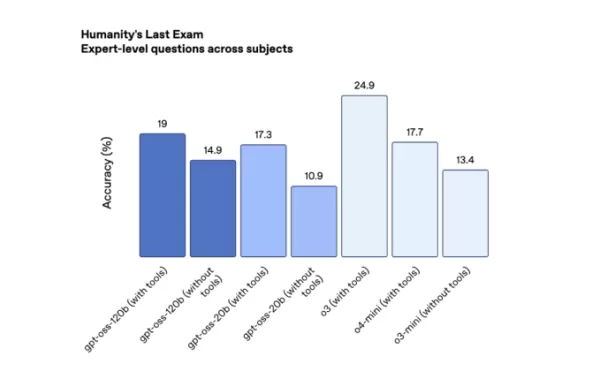
OpenAI 开源模型在 HLE 上的性能(来源:OpenAI)。 值得注意的是,OpenAI 的开源模型幻觉率明显高于其最新推理模型 o3 和 o4-mini。
幻觉现象在 OpenAI 近期 AI 推理模型中变得更加明显,公司承认仍在调查原因。在一份白皮书中,OpenAI 指出:“知识较少的较小模型预计比大型前沿模型更容易产生幻觉。”
在 OpenAI 内部用于评估模型关于个体准确性的基准 PersonQA 上,gpt-oss-120b 和 gpt-oss-20b 分别在 49% 和 53% 的回答中出现幻觉,是 o1 模型(16%)的三倍以上,高于 o4-mini(36%)。
训练新模型
OpenAI 表示,其开源模型采用与专有模型类似的技术开发。每种模型均使用专家混合(MoE)方法,每次查询激活较少的参数以提高效率。对于 gpt-oss-120b,共有 1170 亿个参数,每 token 仅使用 51 亿个参数。
开源模型通过高计算强化学习(RL)进行训练,这是一种使用 Nvidia GPU 集群在模拟环境中优化 AI 决策的后训练方法。这与 OpenAI o 系列的训练方式类似,包括链式推理过程,需要额外时间和资源来推理回答。
这种训练使开源模型在驱动 AI 代理方面表现出色,支持如网络搜索或 Python 代码执行等工具在其推理过程中。然而,它们仅限于文本任务,无法处理或生成图像或音频,与 OpenAI 的其他模型不同。
gpt-oss-120b 和 gpt-oss-20b 模型在 Apache 2.0 许可下发布,允许企业无需向 OpenAI 支付费用或获得许可即可将其商业化。
与 AI2 等实验室的完全开源模型不同,OpenAI 不会公开其开源模型的训练数据,这一决定可能受到关于 AI 训练中使用版权材料不当的持续诉讼影响。
OpenAI 多次推迟其开源模型的发布以解决安全问题。除标准安全协议外,公司还评估了恶意行为者是否可能将 gpt-oss 微调用于有害目的,如网络攻击或制造生物或化学武器。
OpenAI 和外部评估者的测试发现,gpt-oss 可能略微增强生物能力,但即使经过微调,也未达到公司“高危”阈值。
虽然 OpenAI 的模型在开源模型中领先,但开发者们正在期待 DeepSeek 的 R2 和 Meta 超级智能实验室的新开源模型的发布。
相关文章
 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
格雷格·布罗克曼揭秘埃隆·马斯克如何离开OpenAI
2017年8月下旬,OpenAI(当时还是一家小型非营利研究实验室)的核心成员召开会议,商讨如何成立一家营利性实体,以实现技术的商业化,并筹集实现通用人工智能(AGI)所需的资金。埃隆·马斯克要求全面掌控公司,并刚刚向每位联合创始人赠送了一辆特斯拉Model 3。首席技术官格雷格·布罗克曼表示,他认为这是马斯克试图收买人心,当时马斯克和萨姆·阿尔特曼正就各自对公司未来愿景的支持展开角逐。 Open
相关专题推荐
漫画创作
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
格雷格·布罗克曼揭秘埃隆·马斯克如何离开OpenAI
2017年8月下旬,OpenAI(当时还是一家小型非营利研究实验室)的核心成员召开会议,商讨如何成立一家营利性实体,以实现技术的商业化,并筹集实现通用人工智能(AGI)所需的资金。埃隆·马斯克要求全面掌控公司,并刚刚向每位联合创始人赠送了一辆特斯拉Model 3。首席技术官格雷格·布罗克曼表示,他认为这是马斯克试图收买人心,当时马斯克和萨姆·阿尔特曼正就各自对公司未来愿景的支持展开角逐。 Open
相关专题推荐
漫画创作
 少年漫画顶级AI生成器:打造高能动作场面与特效
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
 15 个工具
15 个工具
 xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

 评论 (2)
0/500
评论 (2)
0/500
![CharlesYoung]()
OpenAI qui met ses modèles en libre accès sur Hugging Face, c'est assez inattendu venant d'eux... À la fois je suis impressionné par la performance revendiquée, et légèrement inquiet de la concurrence déloyale que ça pourrait créer pour les petits joueurs. Mais bon, en tant que développeur, je vais certainement télécharger et tester ça tout de suite ! 😄
![NicholasDavis]()
居然可以免費下載!OpenAI這次真的很大方,不過開源模型的效能真的能比上o-series嗎?有點懷疑🤔 希望不是行銷手法啦...
OpenAI 在周二宣布推出两款开源权重 AI 推理模型,其性能可与 o 系列媲美。两款模型均可在 Hugging Face 上免费下载,OpenAI 宣称它们在多个开源模型基准测试中表现“顶尖”。
模型提供两种变体:功能强大的 gpt-oss-120b,可在一块 Nvidia GPU 上运行;轻量级 gpt-oss-20b,设计为可在配备 16GB 内存的普通笔记本电脑上运行。
此次发布是 OpenAI 自五年前推出 GPT-2 以来首次发布开源语言模型。
在简报会上,OpenAI 表示,其开源模型可通过连接到更先进的云端 AI 系统来处理复杂查询,正如 TechCrunch 此前报道的那样。这允许开发者在需要时将开源模型链接到 OpenAI 的专有模型,以执行如图像处理等任务。
尽管 OpenAI 最初拥抱开源 AI 模型,但其发展模式已基本转向专有,依靠向企业和开发者提供 API 访问权限,业务蓬勃发展。
今年 1 月,首席执行官 Sam Altman 承认,OpenAI 在未优先发展开源技术方面可能犯了错误。公司现面临来自中国 AI 实验室(如 DeepSeek、Alibaba 的 Qwen 和 Moonshot AI)的激烈竞争,这些实验室凭借高性能的开源模型获得了市场吸引力。(Meta 的 Llama 模型曾是开源 AI 领域的领导者,但在过去一年已落后。)
7 月,特朗普政府鼓励美国 AI 开发者开放更多技术,以推动全球范围内符合美国价值观的 AI 发展。
科技与风投领袖亮相 Disrupt 2025
Netflix、ElevenLabs、Wayve 和 Sequoia Capital 等知名企业名列 Disrupt 2025 议程,分享推动创业成功和创新的见解。不要错过 TechCrunch Disrupt 二十周年纪念,与科技顶尖声音学习的机会——现在购票,在 8 月 7 日价格上涨前可节省高达 675 美元。
科技与风投领袖亮相 Disrupt 2025
Netflix、ElevenLabs、Wayve 和 Sequoia Capital 等知名企业名列 Disrupt 2025 议程,分享推动创业成功和创新的见解。不要错过 TechCrunch Disrupt 二十周年纪念,与科技顶尖声音学习的机会——现在购票,在 8 月 7 日价格上涨前可节省高达 675 美元。
旧金山 | 2025 年 10 月 27-29 日 立即注册通过 gpt-oss,OpenAI 旨在吸引开发者并响应特朗普政府的推动,双方均注意到中国 AI 实验室在开源领域的崛起。
“自 2015 年成立以来,OpenAI 的使命一直是推进 AGI 以造福全人类,”首席执行官 Sam Altman 在对 TechCrunch 的声明中表示。“我们很高兴看到世界基于植根于美国民主价值观的开源 AI 框架进行构建,自由访问且广泛有益。”
模型性能概览
OpenAI 设计其开源模型以在开源权重 AI 系统中领先,公司声称已实现这一目标。
在 Codeforces 的竞争性编程测试(使用工具)中,gpt-oss-120b 得分 2622,gpt-oss-20b 得分 2516,超越 DeepSeek 的 R1,但落后于 o3 和 o4-mini。
在“人类最后考试”(一项覆盖多学科的严格众包测试,使用工具)中,gpt-oss-120b 和 gpt-oss-20b 分别获得 19% 和 17.3% 的成绩,优于 DeepSeek 和 Qwen 的领先开源模型,但不及 o3。
值得注意的是,OpenAI 的开源模型幻觉率明显高于其最新推理模型 o3 和 o4-mini。
幻觉现象在 OpenAI 近期 AI 推理模型中变得更加明显,公司承认仍在调查原因。在一份白皮书中,OpenAI 指出:“知识较少的较小模型预计比大型前沿模型更容易产生幻觉。”
在 OpenAI 内部用于评估模型关于个体准确性的基准 PersonQA 上,gpt-oss-120b 和 gpt-oss-20b 分别在 49% 和 53% 的回答中出现幻觉,是 o1 模型(16%)的三倍以上,高于 o4-mini(36%)。
训练新模型
OpenAI 表示,其开源模型采用与专有模型类似的技术开发。每种模型均使用专家混合(MoE)方法,每次查询激活较少的参数以提高效率。对于 gpt-oss-120b,共有 1170 亿个参数,每 token 仅使用 51 亿个参数。
开源模型通过高计算强化学习(RL)进行训练,这是一种使用 Nvidia GPU 集群在模拟环境中优化 AI 决策的后训练方法。这与 OpenAI o 系列的训练方式类似,包括链式推理过程,需要额外时间和资源来推理回答。
这种训练使开源模型在驱动 AI 代理方面表现出色,支持如网络搜索或 Python 代码执行等工具在其推理过程中。然而,它们仅限于文本任务,无法处理或生成图像或音频,与 OpenAI 的其他模型不同。
gpt-oss-120b 和 gpt-oss-20b 模型在 Apache 2.0 许可下发布,允许企业无需向 OpenAI 支付费用或获得许可即可将其商业化。
与 AI2 等实验室的完全开源模型不同,OpenAI 不会公开其开源模型的训练数据,这一决定可能受到关于 AI 训练中使用版权材料不当的持续诉讼影响。
OpenAI 多次推迟其开源模型的发布以解决安全问题。除标准安全协议外,公司还评估了恶意行为者是否可能将 gpt-oss 微调用于有害目的,如网络攻击或制造生物或化学武器。
OpenAI 和外部评估者的测试发现,gpt-oss 可能略微增强生物能力,但即使经过微调,也未达到公司“高危”阈值。
虽然 OpenAI 的模型在开源模型中领先,但开发者们正在期待 DeepSeek 的 R2 和 Meta 超级智能实验室的新开源模型的发布。










 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
 OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
 格雷格·布罗克曼揭秘埃隆·马斯克如何离开OpenAI
2017年8月下旬,OpenAI(当时还是一家小型非营利研究实验室)的核心成员召开会议,商讨如何成立一家营利性实体,以实现技术的商业化,并筹集实现通用人工智能(AGI)所需的资金。埃隆·马斯克要求全面掌控公司,并刚刚向每位联合创始人赠送了一辆特斯拉Model 3。首席技术官格雷格·布罗克曼表示,他认为这是马斯克试图收买人心,当时马斯克和萨姆·阿尔特曼正就各自对公司未来愿景的支持展开角逐。 Open
格雷格·布罗克曼揭秘埃隆·马斯克如何离开OpenAI
2017年8月下旬,OpenAI(当时还是一家小型非营利研究实验室)的核心成员召开会议,商讨如何成立一家营利性实体,以实现技术的商业化,并筹集实现通用人工智能(AGI)所需的资金。埃隆·马斯克要求全面掌控公司,并刚刚向每位联合创始人赠送了一辆特斯拉Model 3。首席技术官格雷格·布罗克曼表示,他认为这是马斯克试图收买人心,当时马斯克和萨姆·阿尔特曼正就各自对公司未来愿景的支持展开角逐。 Open

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

OpenAI qui met ses modèles en libre accès sur Hugging Face, c'est assez inattendu venant d'eux... À la fois je suis impressionné par la performance revendiquée, et légèrement inquiet de la concurrence déloyale que ça pourrait créer pour les petits joueurs. Mais bon, en tant que développeur, je vais certainement télécharger et tester ça tout de suite ! 😄
居然可以免費下載!OpenAI這次真的很大方,不過開源模型的效能真的能比上o-series嗎?有點懷疑🤔 希望不是行銷手法啦...













