
















 首頁
首頁OpenAI 發布兩款先進開源 AI 模型
OpenAI 於週二宣布推出兩款開源 AI 推理模型,性能媲美其 o 系列。兩款模型均可在 Hugging Face 免費下載,OpenAI 稱其在多項開源模型基準測試中表現「頂尖」。
模型分為兩種版本:強大的 gpt-oss-120b,僅需單一 Nvidia GPU 即可運行;輕量級 gpt-oss-20b,設計為可在具備 16GB 記憶體的標準筆電上運行。
這是 OpenAI 自五年前推出 GPT-2 後的首款開源語言模型。
在簡報會上,OpenAI 表示,其開源模型可通過連接到更先進的雲端 AI 系統處理複雜查詢,正如 TechCrunch 先前報導。這允許開發者在需要時將開源模型連接到 OpenAI 的專有模型,以執行如圖像處理等任務。
雖然 OpenAI 最初擁抱開源 AI 模型,但其後大多轉向專有開發模式,通過向企業和開發者提供 API 存取,推動蓬勃發展的業務。
今年一月,執行長 Sam Altman 承認 OpenAI 在未優先發展開源技術上可能有所失誤。公司現面臨來自中國 AI 實驗室如 DeepSeek、Alibaba 的 Qwen 及 Moonshot AI 的激烈競爭,這些實驗室以其高性能開源模型獲得關注。(Meta 的 Llama 模型曾是開源 AI 領域的領導者,但在過去一年落後。)
七月,川普政府鼓勵美國 AI 開發者開放更多技術,以推動符合美國價值觀的 AI 在全球發展。
科技與創投領袖亮相 Disrupt 2025
Netflix、ElevenLabs、Wayve 及 Sequoia Capital 等知名品牌將於 Disrupt 2025 議程中分享推動新創成功與創新的見解。不要錯過 TechCrunch Disrupt 20 週年,與科技頂尖聲音學習的機會——立即購票,於 8 月 7 日價格上漲前可節省高達 675 美元。
科技與創投領袖亮相 Disrupt 2025
Netflix、ElevenLabs、Wayve 及 Sequoia Capital 等知名品牌將於 Disrupt 2025 議程中分享推動新創成功與創新的見解。不要錯過 TechCrunch Disrupt 20 週年,與科技頂尖聲音學習的機會——立即購票,於 8 月 7 日價格上漲前可節省高達 675 美元。
舊金山 | 2025 年 10 月 27-29 日 立即註冊透過 gpt-oss,OpenAI 旨在吸引開發者並響應川普政府的推動,雙方均注意到中國 AI 實驗室在開源領域的崛起。
「自 2015 年創立以來,OpenAI 的使命是推進 AGI 以造福全人類,」執行長 Sam Altman 在對 TechCrunch 的聲明中表示。「我們很高興看到全球在基於美國民主價值觀的開源 AI 框架上進行建設,自由存取且廣泛有益。」

(照片由 Tomohiro Ohsumi/Getty Images 提供) 圖片來源:Tomohiro Ohsumi / Getty Images 模型性能概覽
OpenAI 設計其開源模型以領先於開源 AI 系統,公司聲稱已達成此目標。
在 Codeforces 的競賽程式設計測試(使用工具)中,gpt-oss-120b 得分 2622,gpt-oss-20b 得分 2516,超越 DeepSeek 的 R1,但落後於 o3 和 o4-mini。
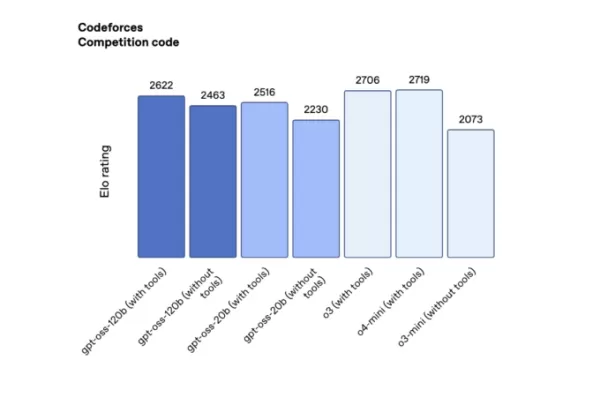
OpenAI 開源模型在 Codeforces 的表現(來源:OpenAI)。 在「人類最後考試」,一項涵蓋多學科的嚴格眾包測試(使用工具)中,gpt-oss-120b 和 gpt-oss-20b 分別獲得 19% 和 17.3%,超越 DeepSeek 和 Qwen 的領先開源模型,但未達 o3 水平。
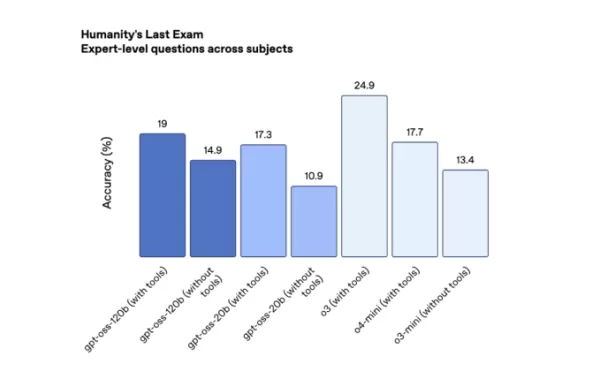
OpenAI 開源模型在 HLE 的表現(來源:OpenAI)。 值得注意的是,OpenAI 的開源模型幻覺率顯著高於其最新推理模型 o3 和 o4-mini。
幻覺問題在 OpenAI 近期 AI 推理模型中更為明顯,公司承認仍在調查原因。在一份白皮書中,OpenAI 指出:「知識較少的較小型模型預計比大型前沿模型更容易產生幻覺。」
在 OpenAI 內部用於評估模型對個人資訊準確性的基準 PersonQA 中,gpt-oss-120b 和 gpt-oss-20b 的幻覺率分別為 49% 和 53%,是 o1 模型(16%)的三倍以上,且高於 o4-mini(36%)。
訓練新模型
OpenAI 表示,其開源模型採用與專有模型相似的技術開發。每款模型使用專家混合(MoE)方法,每個查詢啟用較少的參數以提高效率。對於 gpt-oss-120b,總計 1170 億參數,每個 token 僅使用 51 億參數。
開源模型採用高運算強化學習(RL)進行訓練,這是一種使用 Nvidia GPU 集群在模擬環境中優化 AI 決策的後訓練方法。這與 OpenAI o 系列的訓練相似,並包含思考鏈過程,需要額外時間和資源來推理回應。
此訓練使開源模型擅長驅動 AI 代理,支援如網頁搜尋或 Python 程式碼執行等工具在其推理過程中。然而,它們僅限於文字任務,無法處理或生成圖像或音頻,與 OpenAI 的其他模型不同。
gpt-oss-120b 和 gpt-oss-20b 模型以 Apache 2.0 許可證發布,允許企業無需向 OpenAI 支付費用或取得許可即可商業化。
與 AI2 等實驗室的完全開源模型不同,OpenAI 不會公開其開源模型的訓練數據,此決定可能受到關於 AI 訓練中不當使用版權材料的訴訟影響。
OpenAI 多次推遲開源模型的發布以解決安全問題。除標準安全協議外,公司評估了惡意行為者是否可能將 gpt-oss 微調用於有害目的,如網路攻擊或製造生物或化學武器。
OpenAI 及外部評估者的測試發現,gpt-oss 可能略微增強生物能力,但即使經過微調,也未達到公司設定的「高危險」門檻。
雖然 OpenAI 的模型在開源模型中領先,開發者正期待 DeepSeek 的 R2 及 Meta 超智能實驗室的新開源模型發布。
相關文章
 薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
葛瑞格・布洛克曼揭露伊隆・馬斯克如何離開 OpenAI
2017年8月下旬,OpenAI(當時還是一家小型非營利研究實驗室)的核心成員召開會議,商討如何成立營利實體以將其技術商業化,並籌集實現通用人工智慧(AGI)所需的資金。伊隆·馬斯克要求對公司擁有完全控制權,並剛向每位共同創辦人贈送了一輛特斯拉Model 3。技術長格雷格·布羅克曼表示,他認為這是在馬斯克與山姆·奧特曼為各自對公司未來的願景爭取支持之際,試圖用這份禮物來收買他們。 OpenAI的研
相關專題推薦
代碼
薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
葛瑞格・布洛克曼揭露伊隆・馬斯克如何離開 OpenAI
2017年8月下旬,OpenAI(當時還是一家小型非營利研究實驗室)的核心成員召開會議,商討如何成立營利實體以將其技術商業化,並籌集實現通用人工智慧(AGI)所需的資金。伊隆·馬斯克要求對公司擁有完全控制權,並剛向每位共同創辦人贈送了一輛特斯拉Model 3。技術長格雷格·布羅克曼表示,他認為這是在馬斯克與山姆·奧特曼為各自對公司未來的願景爭取支持之際,試圖用這份禮物來收買他們。 OpenAI的研
相關專題推薦
代碼
 最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
 10 個工具
10 個工具
 xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

 評論 (2)
0/500
評論 (2)
0/500
![CharlesYoung]()
OpenAI qui met ses modèles en libre accès sur Hugging Face, c'est assez inattendu venant d'eux... À la fois je suis impressionné par la performance revendiquée, et légèrement inquiet de la concurrence déloyale que ça pourrait créer pour les petits joueurs. Mais bon, en tant que développeur, je vais certainement télécharger et tester ça tout de suite ! 😄
![NicholasDavis]()
居然可以免費下載!OpenAI這次真的很大方,不過開源模型的效能真的能比上o-series嗎?有點懷疑🤔 希望不是行銷手法啦...
OpenAI 於週二宣布推出兩款開源 AI 推理模型,性能媲美其 o 系列。兩款模型均可在 Hugging Face 免費下載,OpenAI 稱其在多項開源模型基準測試中表現「頂尖」。
模型分為兩種版本:強大的 gpt-oss-120b,僅需單一 Nvidia GPU 即可運行;輕量級 gpt-oss-20b,設計為可在具備 16GB 記憶體的標準筆電上運行。
這是 OpenAI 自五年前推出 GPT-2 後的首款開源語言模型。
在簡報會上,OpenAI 表示,其開源模型可通過連接到更先進的雲端 AI 系統處理複雜查詢,正如 TechCrunch 先前報導。這允許開發者在需要時將開源模型連接到 OpenAI 的專有模型,以執行如圖像處理等任務。
雖然 OpenAI 最初擁抱開源 AI 模型,但其後大多轉向專有開發模式,通過向企業和開發者提供 API 存取,推動蓬勃發展的業務。
今年一月,執行長 Sam Altman 承認 OpenAI 在未優先發展開源技術上可能有所失誤。公司現面臨來自中國 AI 實驗室如 DeepSeek、Alibaba 的 Qwen 及 Moonshot AI 的激烈競爭,這些實驗室以其高性能開源模型獲得關注。(Meta 的 Llama 模型曾是開源 AI 領域的領導者,但在過去一年落後。)
七月,川普政府鼓勵美國 AI 開發者開放更多技術,以推動符合美國價值觀的 AI 在全球發展。
科技與創投領袖亮相 Disrupt 2025
Netflix、ElevenLabs、Wayve 及 Sequoia Capital 等知名品牌將於 Disrupt 2025 議程中分享推動新創成功與創新的見解。不要錯過 TechCrunch Disrupt 20 週年,與科技頂尖聲音學習的機會——立即購票,於 8 月 7 日價格上漲前可節省高達 675 美元。
科技與創投領袖亮相 Disrupt 2025
Netflix、ElevenLabs、Wayve 及 Sequoia Capital 等知名品牌將於 Disrupt 2025 議程中分享推動新創成功與創新的見解。不要錯過 TechCrunch Disrupt 20 週年,與科技頂尖聲音學習的機會——立即購票,於 8 月 7 日價格上漲前可節省高達 675 美元。
舊金山 | 2025 年 10 月 27-29 日 立即註冊透過 gpt-oss,OpenAI 旨在吸引開發者並響應川普政府的推動,雙方均注意到中國 AI 實驗室在開源領域的崛起。
「自 2015 年創立以來,OpenAI 的使命是推進 AGI 以造福全人類,」執行長 Sam Altman 在對 TechCrunch 的聲明中表示。「我們很高興看到全球在基於美國民主價值觀的開源 AI 框架上進行建設,自由存取且廣泛有益。」
模型性能概覽
OpenAI 設計其開源模型以領先於開源 AI 系統,公司聲稱已達成此目標。
在 Codeforces 的競賽程式設計測試(使用工具)中,gpt-oss-120b 得分 2622,gpt-oss-20b 得分 2516,超越 DeepSeek 的 R1,但落後於 o3 和 o4-mini。
在「人類最後考試」,一項涵蓋多學科的嚴格眾包測試(使用工具)中,gpt-oss-120b 和 gpt-oss-20b 分別獲得 19% 和 17.3%,超越 DeepSeek 和 Qwen 的領先開源模型,但未達 o3 水平。
值得注意的是,OpenAI 的開源模型幻覺率顯著高於其最新推理模型 o3 和 o4-mini。
幻覺問題在 OpenAI 近期 AI 推理模型中更為明顯,公司承認仍在調查原因。在一份白皮書中,OpenAI 指出:「知識較少的較小型模型預計比大型前沿模型更容易產生幻覺。」
在 OpenAI 內部用於評估模型對個人資訊準確性的基準 PersonQA 中,gpt-oss-120b 和 gpt-oss-20b 的幻覺率分別為 49% 和 53%,是 o1 模型(16%)的三倍以上,且高於 o4-mini(36%)。
訓練新模型
OpenAI 表示,其開源模型採用與專有模型相似的技術開發。每款模型使用專家混合(MoE)方法,每個查詢啟用較少的參數以提高效率。對於 gpt-oss-120b,總計 1170 億參數,每個 token 僅使用 51 億參數。
開源模型採用高運算強化學習(RL)進行訓練,這是一種使用 Nvidia GPU 集群在模擬環境中優化 AI 決策的後訓練方法。這與 OpenAI o 系列的訓練相似,並包含思考鏈過程,需要額外時間和資源來推理回應。
此訓練使開源模型擅長驅動 AI 代理,支援如網頁搜尋或 Python 程式碼執行等工具在其推理過程中。然而,它們僅限於文字任務,無法處理或生成圖像或音頻,與 OpenAI 的其他模型不同。
gpt-oss-120b 和 gpt-oss-20b 模型以 Apache 2.0 許可證發布,允許企業無需向 OpenAI 支付費用或取得許可即可商業化。
與 AI2 等實驗室的完全開源模型不同,OpenAI 不會公開其開源模型的訓練數據,此決定可能受到關於 AI 訓練中不當使用版權材料的訴訟影響。
OpenAI 多次推遲開源模型的發布以解決安全問題。除標準安全協議外,公司評估了惡意行為者是否可能將 gpt-oss 微調用於有害目的,如網路攻擊或製造生物或化學武器。
OpenAI 及外部評估者的測試發現,gpt-oss 可能略微增強生物能力,但即使經過微調,也未達到公司設定的「高危險」門檻。
雖然 OpenAI 的模型在開源模型中領先,開發者正期待 DeepSeek 的 R2 及 Meta 超智能實驗室的新開源模型發布。










 薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
 OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
 葛瑞格・布洛克曼揭露伊隆・馬斯克如何離開 OpenAI
2017年8月下旬,OpenAI(當時還是一家小型非營利研究實驗室)的核心成員召開會議,商討如何成立營利實體以將其技術商業化,並籌集實現通用人工智慧(AGI)所需的資金。伊隆·馬斯克要求對公司擁有完全控制權,並剛向每位共同創辦人贈送了一輛特斯拉Model 3。技術長格雷格·布羅克曼表示,他認為這是在馬斯克與山姆·奧特曼為各自對公司未來的願景爭取支持之際,試圖用這份禮物來收買他們。 OpenAI的研
葛瑞格・布洛克曼揭露伊隆・馬斯克如何離開 OpenAI
2017年8月下旬,OpenAI(當時還是一家小型非營利研究實驗室)的核心成員召開會議,商討如何成立營利實體以將其技術商業化,並籌集實現通用人工智慧(AGI)所需的資金。伊隆·馬斯克要求對公司擁有完全控制權,並剛向每位共同創辦人贈送了一輛特斯拉Model 3。技術長格雷格·布羅克曼表示,他認為這是在馬斯克與山姆·奧特曼為各自對公司未來的願景爭取支持之際,試圖用這份禮物來收買他們。 OpenAI的研

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

OpenAI qui met ses modèles en libre accès sur Hugging Face, c'est assez inattendu venant d'eux... À la fois je suis impressionné par la performance revendiquée, et légèrement inquiet de la concurrence déloyale que ça pourrait créer pour les petits joueurs. Mais bon, en tant que développeur, je vais certainement télécharger et tester ça tout de suite ! 😄
居然可以免費下載!OpenAI這次真的很大方,不過開源模型的效能真的能比上o-series嗎?有點懷疑🤔 希望不是行銷手法啦...













