
















 首頁
首頁研究發現:實際測試中,AI 程式碼的效能被高估了
METR 研究所的研究指出,廣泛用於評估 AI 程式設計能力的 SWE-bench Verified 基準測試,可能嚴重高估了 AI 代理在實際軟體開發中的表現。該研究發現,約有一半由 AI 生成的程式碼解決方案雖被該基準測試標記為「通過」,但在實際專案的程式碼審查過程中,很可能遭到專案維護人員拒絕,這凸顯了自動化評估結果與實際程式碼品質之間存在著顯著差距。
SWE-bench Verified 長期以來被視為評估 AI 輔助軟體工程的關鍵標準,用於測試模型能否解決開源專案中的真實編程任務,並驗證程式碼變更是否通過專案的自動化測試套件。包括 Anthropic 和 OpenAI 在內的多家 AI 公司,經常引用此基準測試的結果來展示模型的進展。
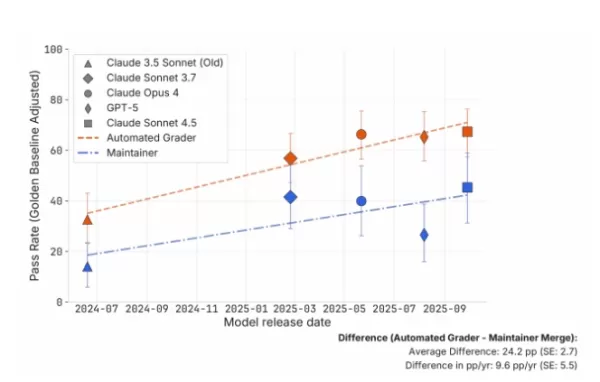
在這項研究中,METR 團隊邀請了四位負責維護 scikit-learn、Sphinx 和 pytest 等開源專案的資深開發者,對 296 段由 AI 生成的程式碼進行人工審查。這些程式碼範例由五種不同的模型產生:Claude 3.5 Sonnet、Claude 3.7 Sonnet、Claude 4 Opus、Claude 4.5 Sonnet 以及 GPT-5。 結果顯示,維護者實際的接受率平均比 SWE-bench 的自動化評分低約 24 個百分點——這是一個具有統計學意義的差異。
研究還指出,被拒絕的 AI 程式碼主要並非源於風格問題,而是更實質的工程缺陷。維護人員將問題歸類為三大類:程式碼品質未達專案規格、破壞現有程式碼結構,以及根本性的功能錯誤。其中相當一部分案例涉及功能錯誤,即儘管通過了自動化測試,程式碼卻未能正確解決預期的問題。
在模型比較方面,研究發現從 Claude 3.5 Sonnet 升級至 Claude 3.7 Sonnet 雖顯著提升了基準測試通過率,但維護人員標記的功能性錯誤數量也隨之增加。 從 Claude 3.7 Sonnet 過渡到 Claude 3.7 Sonnet 期間,問題傾向轉向更多程式碼品質問題,而 Claude 4.5 Sonnet 則在程式碼品質方面有所改善。相較之下,在此次人工評估中,GPT-5 的整體表現明顯遜於 Anthropic 模型系列。

研究團隊還針對「任務完成時間」進行了估算分析:根據 SWE-bench 自動化評估結果,若以 50% 的成功率完成任務,Claude 4.5 Sonnet 相當於需耗費約 50 分鐘的人工時間。然而,根據維護人員的評分,估算時間僅約 8 分鐘,這表明該基準測試可能將能力高估了多達七倍。
不過,研究人員也強調,這項研究並不意味著 AI 程式設計代理的能力存在根本性限制。透過改進提示策略、增加人類反饋,或進行多次迭代循環,自動化評估與人工審查之間的差距有望縮小。此外,實驗設置與實際開發流程有所不同——例如,AI 代理僅有一次提交機會,而人類開發者通常能根據反饋反覆修改程式碼。
總而言之,該研究結論指出,若僅依賴基準測試分數來評估 AI 程式設計代理的實際效用,可能會引入系統性偏差。隨著 AI 編碼模型的快速演進,開發能更真實反映實際開發環境的評估系統,已成為 AI 軟體工程領域中至關重要的研究方向。
相關文章
 DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
OpenAI 悄悄修改章程,使解僱阿爾特曼變得更困難
繼 2023 年的「政變式」事件後,OpenAI 透過更新公司章程,進一步鞏固了對執行長山姆·奧特曼(Sam Altman)的保障。近期公布的法院文件顯示,奧特曼的職位如今已穩如磐石,面對外部干預或內部董事會試圖罷免他的行動,其職位設有大幅提高的防線。在伊隆·馬斯克(Elon Musk)對 OpenAI 提起的訴訟中,一名專家證人指出,這些變更是在公司轉型為營利模式的過程中悄然進行的。與先前僅需簡
相關專題推薦
商業
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
OpenAI 悄悄修改章程,使解僱阿爾特曼變得更困難
繼 2023 年的「政變式」事件後,OpenAI 透過更新公司章程,進一步鞏固了對執行長山姆·奧特曼(Sam Altman)的保障。近期公布的法院文件顯示,奧特曼的職位如今已穩如磐石,面對外部干預或內部董事會試圖罷免他的行動,其職位設有大幅提高的防線。在伊隆·馬斯克(Elon Musk)對 OpenAI 提起的訴訟中,一名專家證人指出,這些變更是在公司轉型為營利模式的過程中悄然進行的。與先前僅需簡
相關專題推薦
商業
 最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
 10 個工具
10 個工具
 xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai
代碼
最適合自動化單元測試的最佳AI工具:一鍵生成Jest、PyTest和JUnit測試用例
探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

 評論 (1)
0/500
評論 (1)
0/500
![GregoryRamirez]()
Interessant, aber irgendwie auch nicht überraschend. Benchmarks sind oft zu optimistisch, weil sie in einer kontrollierten Umgebung laufen. In der echten Welt mit Legacy-Code, unklaren Anforderungen und Teamarbeit sieht es dann anders aus. 🤔 Vielleicht sollten wir weniger auf die Marketing-Hypes hören und mehr auf praktische Tests setzen. Wer hat schon Erfahrung mit AI-Coding-Tools im Alltag gemacht?
METR 研究所的研究指出,廣泛用於評估 AI 程式設計能力的 SWE-bench Verified 基準測試,可能嚴重高估了 AI 代理在實際軟體開發中的表現。該研究發現,約有一半由 AI 生成的程式碼解決方案雖被該基準測試標記為「通過」,但在實際專案的程式碼審查過程中,很可能遭到專案維護人員拒絕,這凸顯了自動化評估結果與實際程式碼品質之間存在著顯著差距。
SWE-bench Verified 長期以來被視為評估 AI 輔助軟體工程的關鍵標準,用於測試模型能否解決開源專案中的真實編程任務,並驗證程式碼變更是否通過專案的自動化測試套件。包括 Anthropic 和 OpenAI 在內的多家 AI 公司,經常引用此基準測試的結果來展示模型的進展。
在這項研究中,METR 團隊邀請了四位負責維護 scikit-learn、Sphinx 和 pytest 等開源專案的資深開發者,對 296 段由 AI 生成的程式碼進行人工審查。這些程式碼範例由五種不同的模型產生:Claude 3.5 Sonnet、Claude 3.7 Sonnet、Claude 4 Opus、Claude 4.5 Sonnet 以及 GPT-5。 結果顯示,維護者實際的接受率平均比 SWE-bench 的自動化評分低約 24 個百分點——這是一個具有統計學意義的差異。
研究還指出,被拒絕的 AI 程式碼主要並非源於風格問題,而是更實質的工程缺陷。維護人員將問題歸類為三大類:程式碼品質未達專案規格、破壞現有程式碼結構,以及根本性的功能錯誤。其中相當一部分案例涉及功能錯誤,即儘管通過了自動化測試,程式碼卻未能正確解決預期的問題。
在模型比較方面,研究發現從 Claude 3.5 Sonnet 升級至 Claude 3.7 Sonnet 雖顯著提升了基準測試通過率,但維護人員標記的功能性錯誤數量也隨之增加。 從 Claude 3.7 Sonnet 過渡到 Claude 3.7 Sonnet 期間,問題傾向轉向更多程式碼品質問題,而 Claude 4.5 Sonnet 則在程式碼品質方面有所改善。相較之下,在此次人工評估中,GPT-5 的整體表現明顯遜於 Anthropic 模型系列。
研究團隊還針對「任務完成時間」進行了估算分析:根據 SWE-bench 自動化評估結果,若以 50% 的成功率完成任務,Claude 4.5 Sonnet 相當於需耗費約 50 分鐘的人工時間。然而,根據維護人員的評分,估算時間僅約 8 分鐘,這表明該基準測試可能將能力高估了多達七倍。
不過,研究人員也強調,這項研究並不意味著 AI 程式設計代理的能力存在根本性限制。透過改進提示策略、增加人類反饋,或進行多次迭代循環,自動化評估與人工審查之間的差距有望縮小。此外,實驗設置與實際開發流程有所不同——例如,AI 代理僅有一次提交機會,而人類開發者通常能根據反饋反覆修改程式碼。
總而言之,該研究結論指出,若僅依賴基準測試分數來評估 AI 程式設計代理的實際效用,可能會引入系統性偏差。隨著 AI 編碼模型的快速演進,開發能更真實反映實際開發環境的評估系統,已成為 AI 軟體工程領域中至關重要的研究方向。










 DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
 馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
 OpenAI 悄悄修改章程,使解僱阿爾特曼變得更困難
繼 2023 年的「政變式」事件後,OpenAI 透過更新公司章程,進一步鞏固了對執行長山姆·奧特曼(Sam Altman)的保障。近期公布的法院文件顯示,奧特曼的職位如今已穩如磐石,面對外部干預或內部董事會試圖罷免他的行動,其職位設有大幅提高的防線。在伊隆·馬斯克(Elon Musk)對 OpenAI 提起的訴訟中,一名專家證人指出,這些變更是在公司轉型為營利模式的過程中悄然進行的。與先前僅需簡
OpenAI 悄悄修改章程,使解僱阿爾特曼變得更困難
繼 2023 年的「政變式」事件後,OpenAI 透過更新公司章程,進一步鞏固了對執行長山姆·奧特曼(Sam Altman)的保障。近期公布的法院文件顯示,奧特曼的職位如今已穩如磐石,面對外部干預或內部董事會試圖罷免他的行動,其職位設有大幅提高的防線。在伊隆·馬斯克(Elon Musk)對 OpenAI 提起的訴訟中,一名專家證人指出,這些變更是在公司轉型為營利模式的過程中悄然進行的。與先前僅需簡

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

Interessant, aber irgendwie auch nicht überraschend. Benchmarks sind oft zu optimistisch, weil sie in einer kontrollierten Umgebung laufen. In der echten Welt mit Legacy-Code, unklaren Anforderungen und Teamarbeit sieht es dann anders aus. 🤔 Vielleicht sollten wir weniger auf die Marketing-Hypes hören und mehr auf praktische Tests setzen. Wer hat schon Erfahrung mit AI-Coding-Tools im Alltag gemacht?













