
















 Дом
ДомПионеры ИИ выигрывают награду Тьюринга за прорывы в обучении подкреплению
В 2024 году престижная премия Тьюринга, часто называемая «Нобелевской премией в области вычислительной техники», была присуждена двум выдающимся ученым-компьютерщикам, Эндрю Г. Барто и Ричарду С. Саттону, за их новаторский вклад в обучение с подкреплением. Эта область, в которой машины учатся, ориентируясь на метод проб и ошибок на основе вознаграждений, позволяет им адаптироваться в ограниченных или постоянно меняющихся средах.
Барто, ныне почетный профессор Университета Массачусетса в Амхерсте, и Саттон, профессор Университета Альберты, сыграли ключевую роль с 1980-х годов. Они разработали важные алгоритмы и теории в серии влиятельных статей, включая работы по методу, известному как обучение с временной разницей. Их усилия завершились публикацией основополагающего учебника «Обучение с подкреплением: Введение», который стал краеугольным камнем в этой области.
Премия Тьюринга названа в честь легендарного математика Алана Тьюринга, который исследовал схожие концепции в своей статье 1950-х годов «Вычислительные машины и интеллект», размышляя над вопросом, могут ли машины думать и учиться на основе опыта.
В последние годы интерес к обучению с подкреплением резко возрос, особенно после того, как Google DeepMind использовала его для создания ИИ, который одержал победу над лучшими игроками в AlphaGo. Недавно китайский стартап в области ИИ DeepSeek привлек внимание своей инновационной моделью рассуждений R1, которая в значительной степени опиралась на обучение с подкреплением для разработки более экономичных базовых моделей.

Эндрю Г. Барто и Ричард С. СаттонИзображение предоставлено: ACM Премия Тьюринга, управляемая Ассоциацией вычислительной техники (ACM), занимает особое место в мире вычислений. Хотя Нобелевская премия также начала отмечать достижения в области вычислений, особенно в ИИ, с наградами Джеффу Хинтону и Джону Хопфилду в прошлом году за основополагающую работу в области ИИ, а также Демису Хассабису и Джону Джамперу из DeepMind за их работу над AlphaFold, премия Тьюринга остается вершиной признания в области вычислений.
Яннис Иоаннидис, президент ACM, высоко оценил работу Барто и Саттона, заявив: «Области исследований, от когнитивных наук и психологии до нейронаук, вдохновили развитие обучения с подкреплением, которое заложило основы для некоторых из наиболее значимых достижений в ИИ и дало нам более глубокое понимание работы мозга». Он подчеркнул, что обучение с подкреплением — это не только достижение прошлого, но и область с потенциалом для дальнейших прорывов.
Другие светила в области ИИ, такие как главный ученый по ИИ компании Meta Янн ЛеКун, также получили премию Тьюринга. ЛеКун вместе с Джеффом Хинтоном и Йошуа Бенджио был удостоен награды в 2018 году за их работу над глубокими нейронными сетями.
Барто и Саттон разделят приз в размере 1 миллиона долларов, финансируемый Google, продолжая вдохновлять и прокладывать путь в этой динамичной области.
Связанная статья
 Заметки Талата по искусственному интеллекту хранятся прямо на вашем устройстве, а не в облаке
Granola — приложение для ведения заметок на базе искусственного интеллекта, оцениваемое в 250 миллионов долларов, — завоевало популярность среди основателей технологических компаний и венчурных инвест
Новый Roewe i6 поступил в продажу по цене 659 000 юаней; в его основе лежат процессор Snapdragon 8155 и большая модель Doubao
Сегодня компания SAIC Roewe представила новый Roewe i6 — компактный седан, полностью воплотивший в себе стилистику модели Roewe D7. Характерная большая вертикальная решетка радиатора и горизонтальная
Как защитить имущество, здания и собственное здоровье?
В этом непредсказуемом мире защита стала стратегической необходимостью, а не просто одним из возможных вариантов. Будь то обеспечение финансовой безопасности, укрепление зданий или забота о собственно
Рекомендации по связанным специальным темам
письмо
Заметки Талата по искусственному интеллекту хранятся прямо на вашем устройстве, а не в облаке
Granola — приложение для ведения заметок на базе искусственного интеллекта, оцениваемое в 250 миллионов долларов, — завоевало популярность среди основателей технологических компаний и венчурных инвест
Новый Roewe i6 поступил в продажу по цене 659 000 юаней; в его основе лежат процессор Snapdragon 8155 и большая модель Doubao
Сегодня компания SAIC Roewe представила новый Roewe i6 — компактный седан, полностью воплотивший в себе стилистику модели Roewe D7. Характерная большая вертикальная решетка радиатора и горизонтальная
Как защитить имущество, здания и собственное здоровье?
В этом непредсказуемом мире защита стала стратегической необходимостью, а не просто одним из возможных вариантов. Будь то обеспечение финансовой безопасности, укрепление зданий или забота о собственно
Рекомендации по связанным специальным темам
письмо
 Лучшие программы для создания персонажей в жанре научной фантастики: генерация последовательных мотиваций персонажей и их роковых недостатков
Лучшие программы для создания персонажей в жанре научной фантастики: генерация последовательных мотиваций персонажей и их роковых недостатков
Откройте для себя 20 лучших инструментов 2026 года для создания персонажей с помощью искусственного интеллекта, которые помогут вам придать своим героям глубину. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, способные генерировать правдоподобные мотивации и роковые недостатки персонажей. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой потенциал в области создания историй уже сейчас.
 10 инструментов
10 инструментов
 xix.ai
Бизнес
Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
xix.ai
Бизнес
Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
10 инструментов
xix.ai
код
Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai
Преобразование текста в речь
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai
Создание комиксов
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

 Комментарии (17)
Комментарии (17)
![RobertWhite]()
Ces chercheurs méritent vraiment ce prix Turing ! 🎉 Leurs travaux sur l'apprentissage par renforcement ont ouvert la voie à tellement d'innovations en IA. Ça me fait penser à AlphaGo... C'est fou comment une recherche fondamentale peut changer notre quotidien des années plus tard.
![EdwardYoung]()
Super cool to see Barto and Sutton get the Turing Award! 🥳 Reinforcement learning is wild—machines learning like kids exploring a playground. Makes me wonder how far AI will go in mimicking human smarts!
![EricRoberts]()
バートとサットンにチューリング賞おめでとう!彼らの強化学習の仕事は驚異的です。🤯 まるで機械が私たちよりもゲームを上手に学ぶのを見ているようです!この技術が次にどこへ向かうのか楽しみです。もしかしたらAIが私たちに人生の生き方を教えるようになるかも?😂
![RogerSanchez]()
바르토와 서튼에게 튜링상을 축하드립니다! 그들의 강화 학습 연구는 정말 놀랍습니다. 🤯 마치 기계가 우리보다 게임을 더 잘 배우는 것을 보는 것 같아요! 이 기술이 다음에 어디로 갈지 기대됩니다. 어쩌면 AI가 우리에게 삶을 어떻게 살아야 하는지 가르쳐줄까요? 😂
![AlbertLee]()
¡Felicidades a Barto y Sutton por el premio Turing! Su trabajo en aprendizaje por refuerzo es impresionante. 🤯 Es como ver a las máquinas aprender a jugar juegos mejor que nosotros. Estoy emocionado de ver hacia dónde va esta tecnología a continuación. ¿Quizás la IA comience a enseñarnos cómo vivir la vida? 😂
![WilliamMiller]()
Nossa, Barto e Sutton ganhando o Prêmio Turing por aprendizado por reforço? Isso é enorme! O trabalho deles realmente expandiu os limites do que as máquinas podem aprender. Eu não sou um especialista em tecnologia, mas até eu posso ver como isso pode mudar o jogo. Parabéns a eles, e mal posso esperar para ver o que vem a seguir! 🎉
В 2024 году престижная премия Тьюринга, часто называемая «Нобелевской премией в области вычислительной техники», была присуждена двум выдающимся ученым-компьютерщикам, Эндрю Г. Барто и Ричарду С. Саттону, за их новаторский вклад в обучение с подкреплением. Эта область, в которой машины учатся, ориентируясь на метод проб и ошибок на основе вознаграждений, позволяет им адаптироваться в ограниченных или постоянно меняющихся средах.
Барто, ныне почетный профессор Университета Массачусетса в Амхерсте, и Саттон, профессор Университета Альберты, сыграли ключевую роль с 1980-х годов. Они разработали важные алгоритмы и теории в серии влиятельных статей, включая работы по методу, известному как обучение с временной разницей. Их усилия завершились публикацией основополагающего учебника «Обучение с подкреплением: Введение», который стал краеугольным камнем в этой области.
Премия Тьюринга названа в честь легендарного математика Алана Тьюринга, который исследовал схожие концепции в своей статье 1950-х годов «Вычислительные машины и интеллект», размышляя над вопросом, могут ли машины думать и учиться на основе опыта.
В последние годы интерес к обучению с подкреплением резко возрос, особенно после того, как Google DeepMind использовала его для создания ИИ, который одержал победу над лучшими игроками в AlphaGo. Недавно китайский стартап в области ИИ DeepSeek привлек внимание своей инновационной моделью рассуждений R1, которая в значительной степени опиралась на обучение с подкреплением для разработки более экономичных базовых моделей.
Премия Тьюринга, управляемая Ассоциацией вычислительной техники (ACM), занимает особое место в мире вычислений. Хотя Нобелевская премия также начала отмечать достижения в области вычислений, особенно в ИИ, с наградами Джеффу Хинтону и Джону Хопфилду в прошлом году за основополагающую работу в области ИИ, а также Демису Хассабису и Джону Джамперу из DeepMind за их работу над AlphaFold, премия Тьюринга остается вершиной признания в области вычислений.
Яннис Иоаннидис, президент ACM, высоко оценил работу Барто и Саттона, заявив: «Области исследований, от когнитивных наук и психологии до нейронаук, вдохновили развитие обучения с подкреплением, которое заложило основы для некоторых из наиболее значимых достижений в ИИ и дало нам более глубокое понимание работы мозга». Он подчеркнул, что обучение с подкреплением — это не только достижение прошлого, но и область с потенциалом для дальнейших прорывов.
Другие светила в области ИИ, такие как главный ученый по ИИ компании Meta Янн ЛеКун, также получили премию Тьюринга. ЛеКун вместе с Джеффом Хинтоном и Йошуа Бенджио был удостоен награды в 2018 году за их работу над глубокими нейронными сетями.
Барто и Саттон разделят приз в размере 1 миллиона долларов, финансируемый Google, продолжая вдохновлять и прокладывать путь в этой динамичной области.










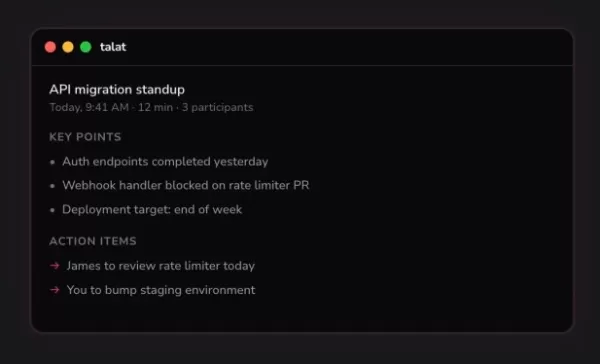 Заметки Талата по искусственному интеллекту хранятся прямо на вашем устройстве, а не в облаке
Granola — приложение для ведения заметок на базе искусственного интеллекта, оцениваемое в 250 миллионов долларов, — завоевало популярность среди основателей технологических компаний и венчурных инвест
Заметки Талата по искусственному интеллекту хранятся прямо на вашем устройстве, а не в облаке
Granola — приложение для ведения заметок на базе искусственного интеллекта, оцениваемое в 250 миллионов долларов, — завоевало популярность среди основателей технологических компаний и венчурных инвест
 Новый Roewe i6 поступил в продажу по цене 659 000 юаней; в его основе лежат процессор Snapdragon 8155 и большая модель Doubao
Сегодня компания SAIC Roewe представила новый Roewe i6 — компактный седан, полностью воплотивший в себе стилистику модели Roewe D7. Характерная большая вертикальная решетка радиатора и горизонтальная
Новый Roewe i6 поступил в продажу по цене 659 000 юаней; в его основе лежат процессор Snapdragon 8155 и большая модель Doubao
Сегодня компания SAIC Roewe представила новый Roewe i6 — компактный седан, полностью воплотивший в себе стилистику модели Roewe D7. Характерная большая вертикальная решетка радиатора и горизонтальная
 Как защитить имущество, здания и собственное здоровье?
В этом непредсказуемом мире защита стала стратегической необходимостью, а не просто одним из возможных вариантов. Будь то обеспечение финансовой безопасности, укрепление зданий или забота о собственно
Как защитить имущество, здания и собственное здоровье?
В этом непредсказуемом мире защита стала стратегической необходимостью, а не просто одним из возможных вариантов. Будь то обеспечение финансовой безопасности, укрепление зданий или забота о собственно

Откройте для себя 20 лучших инструментов 2026 года для создания персонажей с помощью искусственного интеллекта, которые помогут вам придать своим героям глубину. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, способные генерировать правдоподобные мотивации и роковые недостатки персонажей. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой потенциал в области создания историй уже сейчас.
10 инструментов
xix.ai

Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
10 инструментов
xix.ai

Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Ces chercheurs méritent vraiment ce prix Turing ! 🎉 Leurs travaux sur l'apprentissage par renforcement ont ouvert la voie à tellement d'innovations en IA. Ça me fait penser à AlphaGo... C'est fou comment une recherche fondamentale peut changer notre quotidien des années plus tard.
Super cool to see Barto and Sutton get the Turing Award! 🥳 Reinforcement learning is wild—machines learning like kids exploring a playground. Makes me wonder how far AI will go in mimicking human smarts!
バートとサットンにチューリング賞おめでとう!彼らの強化学習の仕事は驚異的です。🤯 まるで機械が私たちよりもゲームを上手に学ぶのを見ているようです!この技術が次にどこへ向かうのか楽しみです。もしかしたらAIが私たちに人生の生き方を教えるようになるかも?😂
바르토와 서튼에게 튜링상을 축하드립니다! 그들의 강화 학습 연구는 정말 놀랍습니다. 🤯 마치 기계가 우리보다 게임을 더 잘 배우는 것을 보는 것 같아요! 이 기술이 다음에 어디로 갈지 기대됩니다. 어쩌면 AI가 우리에게 삶을 어떻게 살아야 하는지 가르쳐줄까요? 😂
¡Felicidades a Barto y Sutton por el premio Turing! Su trabajo en aprendizaje por refuerzo es impresionante. 🤯 Es como ver a las máquinas aprender a jugar juegos mejor que nosotros. Estoy emocionado de ver hacia dónde va esta tecnología a continuación. ¿Quizás la IA comience a enseñarnos cómo vivir la vida? 😂
Nossa, Barto e Sutton ganhando o Prêmio Turing por aprendizado por reforço? Isso é enorme! O trabalho deles realmente expandiu os limites do que as máquinas podem aprender. Eu não sou um especialista em tecnologia, mas até eu posso ver como isso pode mudar o jogo. Parabéns a eles, e mal posso esperar para ver o que vem a seguir! 🎉













