
















 家
家MIT、静的モデルを超える自己学習AIフレームワークを発表
MITの研究者が自己学習AIフレームワークを開発
マサチューセッツ工科大学(MIT)の研究チームは、大規模な言語モデルの能力を自律的に進化させる、SEAL(Self-Adapting Language Models)と呼ばれる革新的なシステムを開発した。この画期的なシステムにより、AIシステムは独自のトレーニング教材と学習プロトコルを生成し、新しい知識とスキルの永続的な統合を可能にする。
SEALは、企業のAIアプリケーション、特に継続的な適応が重要な流動的環境で動作するインテリジェント・エージェントにとって、重要な進歩を意味する。このフレームワークは、現在のLLM技術における基本的な限界、すなわち一時的な文脈学習を超えた永続的な知識の統合という課題に対処している。
現代のAIにおける適応の課題
大規模な言語モデルが素晴らしい能力を発揮する一方で、新しい情報を真に学習し内在化する能力には依然として制約がある。ファインチューニングや文脈内学習のような現在の適応手法は、モデルの学習プロセスに最適化することなく、入力データを受動的に扱う。
「エンタープライズ・アプリケーションは、一時的な知識の想起以上のものを要求しています。「コーディング・アシスタントが独自のフレームワークをマスターするにしても、カスタマーサービスAIがユーザーの好みを学習するにしても、この知識はモデルのコア・アーキテクチャに組み込まれなければなりません」。
SEALアーキテクチャ

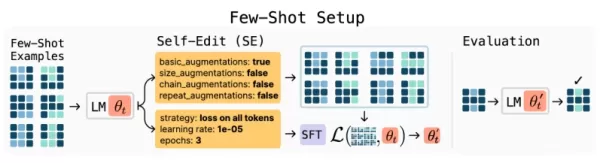
SEALフレームワークの概要(出典:arXiv) SEALフレームワークは、モデルが「自己編集」(自身のパラメーターを更新するための特殊な命令)を生成する、新しい強化学習アプローチを導入している。これらの編集は、情報を再構築したり、合成訓練例を作成したり、あるいは学習プロトコルを定義したりすることができ、モデルが効果的に独自のカリキュラムを設計することを可能にする。
このシステムは、2つの学習サイクルによって動作する:
- インナーループ:自己生成された編集に基づいて、一時的なウェイト更新を実行する。
- 外側のループ:更新の有効性を評価し、成功した戦略を強化する。
この継続的な自己改善メカニズムにより、合成データ生成、強化学習、テスト時間トレーニングが一体化した学習パラダイムとなります。
領域を超えた実証済みのパフォーマンス
知識の統合

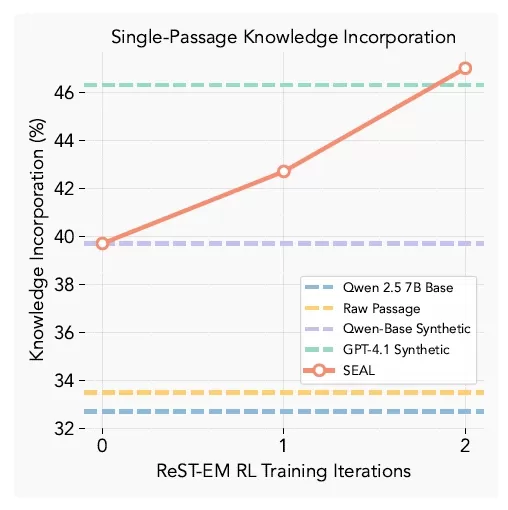
SEALの知識統合結果(出典:arXiv) 知識保持テストにおいて、SEALで強化されたモデルは、原文にアクセスすることなくパッセージの内容を想起する際に47%の精度を示し、ベースラインの微調整とGPT-4.1で生成された合成データの両方を大幅に上回りました。
スモールショット学習
SEAL数発学習のパフォーマンス(出典:arXiv) ARCデータセットの抽象的な推論課題にSEALを適用したところ、72.5%の成功率を達成しました。
企業への応用
高品質な学習データの枯渇が懸念される中、SEALの自己学習教材作成能力は、持続可能な前進の道を提供する。このテクノロジーは、研究論文や財務報告書のような複雑な文書について、モデルが反復的な自己説明を通じて自律的に理解を深めることを可能にする。
このフレームワークは、AIエージェント開発において特に有望であり、システムが環境との相互作用から得られる運用知識を永続的に統合することを可能にする。静的なプログラミングアプローチとは異なり、SEALを搭載したエージェントは、人間の介入への依存を減らしながら、時間をかけて能力を進化させることができる。
現在の限界
SEALの実装は、いくつかの現実的な問題に直面している:
- 致命的な忘却:致命的な忘却:継続的な自己編集は、以前に学習した情報を上書きする危険性がある。
- 計算オーバーヘッド:適応プロセスには多大な処理時間が必要
- ハイブリッド実装の必要性:SEALとRAG(retrieval-augmented generation)を組み合わせることで、メモリ管理を最適化できる可能性がある。
「企業には、継続的な適応ではなく、スケジュールされた更新サイクルを導入することをお勧めします」とPari氏はアドバイスする。「これにより、適応の利点と現実的な運用上の制約のバランスをとることができる。
SEALの漸進的改善(出典:arXiv) この研究は、言語モデルが最初のトレーニングの後、静止したままである必要はないことを示している。独自の更新を生成し適用することを学習することで、言語モデルは自律的に知識を拡大し、新たな課題に適応することができる。
関連記事
 マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか
関連特集おすすめ
チャットボット
マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか
関連特集おすすめ
チャットボット
 高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
 10 ツール
10 ツール
 xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai
データ分析
最高のAIデータ可視化ツール:生データからインタラクティブなBIダッシュボードを自動生成
XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai
ソーシャルメディア
ソーシャルメディア向けAIブランディングキット:すべてのチャネルで一貫したブランドビジュアルを維持
2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![FredLee]()
This is a game-changer! Imagine AI that can teach itself new tricks without constant human babysitting. The potential for accelerating research is insane, but I can't help but wonder about the 'off-switch' problem. What happens when it decides it wants to learn something we didn't intend? 🤔 The arms race for self-improving models is officially on.
MITの研究者が自己学習AIフレームワークを開発
マサチューセッツ工科大学(MIT)の研究チームは、大規模な言語モデルの能力を自律的に進化させる、SEAL(Self-Adapting Language Models)と呼ばれる革新的なシステムを開発した。この画期的なシステムにより、AIシステムは独自のトレーニング教材と学習プロトコルを生成し、新しい知識とスキルの永続的な統合を可能にする。
SEALは、企業のAIアプリケーション、特に継続的な適応が重要な流動的環境で動作するインテリジェント・エージェントにとって、重要な進歩を意味する。このフレームワークは、現在のLLM技術における基本的な限界、すなわち一時的な文脈学習を超えた永続的な知識の統合という課題に対処している。
現代のAIにおける適応の課題
大規模な言語モデルが素晴らしい能力を発揮する一方で、新しい情報を真に学習し内在化する能力には依然として制約がある。ファインチューニングや文脈内学習のような現在の適応手法は、モデルの学習プロセスに最適化することなく、入力データを受動的に扱う。
「エンタープライズ・アプリケーションは、一時的な知識の想起以上のものを要求しています。「コーディング・アシスタントが独自のフレームワークをマスターするにしても、カスタマーサービスAIがユーザーの好みを学習するにしても、この知識はモデルのコア・アーキテクチャに組み込まれなければなりません」。
SEALアーキテクチャ
SEALフレームワークは、モデルが「自己編集」(自身のパラメーターを更新するための特殊な命令)を生成する、新しい強化学習アプローチを導入している。これらの編集は、情報を再構築したり、合成訓練例を作成したり、あるいは学習プロトコルを定義したりすることができ、モデルが効果的に独自のカリキュラムを設計することを可能にする。
このシステムは、2つの学習サイクルによって動作する:
- インナーループ:自己生成された編集に基づいて、一時的なウェイト更新を実行する。
- 外側のループ:更新の有効性を評価し、成功した戦略を強化する。
この継続的な自己改善メカニズムにより、合成データ生成、強化学習、テスト時間トレーニングが一体化した学習パラダイムとなります。
領域を超えた実証済みのパフォーマンス
知識の統合
知識保持テストにおいて、SEALで強化されたモデルは、原文にアクセスすることなくパッセージの内容を想起する際に47%の精度を示し、ベースラインの微調整とGPT-4.1で生成された合成データの両方を大幅に上回りました。
スモールショット学習
ARCデータセットの抽象的な推論課題にSEALを適用したところ、72.5%の成功率を達成しました。
企業への応用
高品質な学習データの枯渇が懸念される中、SEALの自己学習教材作成能力は、持続可能な前進の道を提供する。このテクノロジーは、研究論文や財務報告書のような複雑な文書について、モデルが反復的な自己説明を通じて自律的に理解を深めることを可能にする。
このフレームワークは、AIエージェント開発において特に有望であり、システムが環境との相互作用から得られる運用知識を永続的に統合することを可能にする。静的なプログラミングアプローチとは異なり、SEALを搭載したエージェントは、人間の介入への依存を減らしながら、時間をかけて能力を進化させることができる。
現在の限界
SEALの実装は、いくつかの現実的な問題に直面している:
- 致命的な忘却:致命的な忘却:継続的な自己編集は、以前に学習した情報を上書きする危険性がある。
- 計算オーバーヘッド:適応プロセスには多大な処理時間が必要
- ハイブリッド実装の必要性:SEALとRAG(retrieval-augmented generation)を組み合わせることで、メモリ管理を最適化できる可能性がある。
「企業には、継続的な適応ではなく、スケジュールされた更新サイクルを導入することをお勧めします」とPari氏はアドバイスする。「これにより、適応の利点と現実的な運用上の制約のバランスをとることができる。
この研究は、言語モデルが最初のトレーニングの後、静止したままである必要はないことを示している。独自の更新を生成し適用することを学習することで、言語モデルは自律的に知識を拡大し、新たな課題に適応することができる。










 マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
 秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
 AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか
AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai

This is a game-changer! Imagine AI that can teach itself new tricks without constant human babysitting. The potential for accelerating research is insane, but I can't help but wonder about the 'off-switch' problem. What happens when it decides it wants to learn something we didn't intend? 🤔 The arms race for self-improving models is officially on.













