
















 집
집MIT, 정적 모델을 뛰어넘는 자가 학습 AI 프레임워크 공개
MIT 연구진, 자가 학습 AI 프레임워크 개척
MIT 연구팀은 대규모 언어 모델이 자율적으로 기능을 발전시킬 수 있도록 지원하는 혁신적인 시스템인 SEAL(Self-Adapting Language Models)을 개발했습니다. 이 획기적인 기술을 통해 AI 시스템이 자체적으로 학습 자료와 학습 프로토콜을 생성하여 새로운 지식과 기술을 영구적으로 통합할 수 있게 되었습니다.
SEAL은 엔터프라이즈 AI 애플리케이션, 특히 지속적인 적응이 중요한 유동적인 환경에서 작동하는 지능형 에이전트를 위한 중요한 발전을 의미합니다. 이 프레임워크는 현재 LLM 기술의 근본적인 한계, 즉 일시적인 상황 학습을 넘어선 영구적인 지식 통합이라는 과제를 해결합니다.
현대 AI의 적응 과제
대규모 언어 모델은 인상적인 능력을 보여주지만 새로운 정보를 진정으로 학습하고 내면화하는 능력에는 여전히 제약이 있습니다. 미세 조정이나 문맥 내 학습과 같은 현재의 적응 방식은 입력 데이터를 모델의 학습 프로세스에 최적화하지 않고 수동적으로 처리합니다.
"엔터프라이즈 애플리케이션에는 일시적인 지식 리콜 이상의 심층적이고 지속적인 적응이 필요합니다."라고 논문 공동 저자이자 MIT 박사 과정생인 Jyo Pari는 설명합니다. "독점 프레임워크를 마스터하는 코딩 어시스턴트든 사용자 선호도를 학습하는 고객 서비스 AI든, 이러한 지식은 모델의 핵심 아키텍처에 내장되어야 합니다."라고 설명합니다.
SEAL 아키텍처

SEAL 프레임워크 개요(출처: arXiv) SEAL 프레임워크는 모델이 자체 매개변수를 업데이트하기 위한 특수 지침인 '자체 편집'을 생성하는 새로운 강화 학습 접근 방식을 도입합니다. 이러한 편집을 통해 정보를 재구성하고, 합성 훈련 예제를 생성하거나, 학습 프로토콜을 정의하여 모델이 자체 커리큘럼을 효과적으로 설계할 수 있습니다.
이 시스템은 이중 학습 주기를 통해 작동합니다:
- 내부 루프: 자체 생성된 편집 내용을 기반으로 임시 가중치 업데이트를 실행합니다.
- 외부 루프: 업데이트 효과를 평가하고 성공적인 전략을 강화합니다.
이러한 지속적인 자기 개선 메커니즘은 합성 데이터 생성, 강화 학습, 테스트 시간 훈련을 일관된 학습 패러다임으로 결합합니다.
다양한 영역에서 입증된 성능
지식 통합

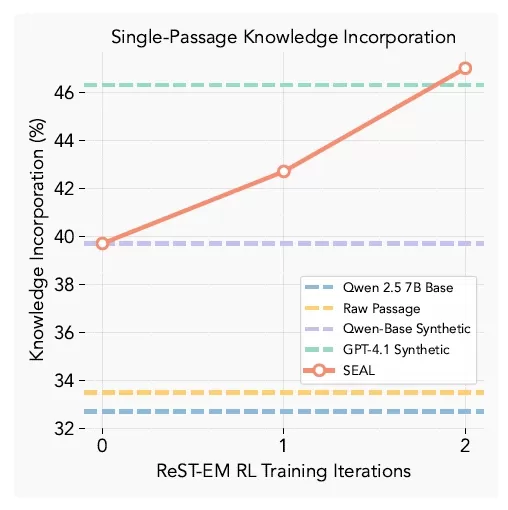
SEAL 지식 통합 결과(출처: arXiv) 지식 유지 테스트에서 SEAL로 강화된 모델은 소스 자료에 대한 액세스 없이도 47%의 정확도로 구절 내용을 리콜하여 기본 미세 조정 및 GPT-4.1로 생성된 합성 데이터보다 훨씬 뛰어난 성능을 보여주었습니다.
소수 샷 학습
SEAL Few-Shot 학습 성능(출처: arXiv) ARC 데이터 세트의 추상 추론 과제에 적용했을 때 SEAL은 72.5%의 성공을 거두었으며, 이는 표준 인컨텍스트 학습 접근 방식에 비해 크게 개선된 수치입니다.
엔터프라이즈 애플리케이션
고품질 학습 데이터의 고갈에 대한 우려가 커지고 있는 가운데, 자체 생성 학습 자료에 대한 SEAL의 역량은 지속 가능한 길을 제시합니다. 이 기술을 통해 모델은 반복적인 자기 설명을 통해 연구 논문이나 재무 보고서와 같은 복잡한 문서에 대한 이해를 자율적으로 심화할 수 있습니다.
이 프레임워크는 시스템이 환경 상호작용에서 얻은 운영 지식을 영구적으로 통합할 수 있도록 하여 AI 에이전트 개발에 특히 유망합니다. 정적 프로그래밍 접근 방식과 달리 SEAL 기반 에이전트는 시간이 지남에 따라 역량을 발전시키면서 사람의 개입에 대한 의존도를 줄일 수 있습니다.
현재의 한계
SEAL의 구현에는 몇 가지 실질적인 고려 사항이 있습니다:
- 치명적인 망각: 지속적인 자체 편집은 이전에 학습한 정보를 덮어쓸 위험이 있습니다.
- 계산 오버헤드: 적응 프로세스에는 상당한 처리 시간이 필요합니다.
- 하이브리드 구현 필요: SEAL과 검색 증강 생성(RAG)을 결합하면 메모리 관리를 최적화할 수 있습니다.
"기업에서는 지속적인 적응보다는 예약된 업데이트 주기를 구현하는 것이 좋습니다."라고 Pari는 조언합니다. "이렇게 하면 적응의 이점과 실질적인 운영상의 제약이 균형을 이룰 수 있습니다."
SEAL의 점진적 개선(출처: arXiv) 이 연구는 언어 모델이 초기 훈련 후에도 고정된 상태로 유지될 필요가 없음을 보여줍니다. 자체 업데이트를 생성하고 적용하는 방법을 학습함으로써 자율적으로 지식을 확장하고 새로운 과제에 적응할 수 있으며, 이는 엔터프라이즈 AI 구현을 재정의할 수 있는 역량입니다.
관련 기사
 멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된
관련 특별 주제 추천
생산력
멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된
관련 특별 주제 추천
생산력
 AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
 10 도구
10 도구
 xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai
챗봇
최고의 AI 유혹 및 대화 트레이너: 실시간으로 사회적 매력과 자신감을 높여보세요
XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai
암호
자동화된 단위 테스트를 위한 최고의 AI 도구들: 한 번의 클릭으로 Jest, PyTest, JUnit 테스트 케이스를 생성하세요.
2026년에 출시된 최신이자 가장 높은 평가를 받는 AI 도구들을 만나보세요. 저희가 엄선한 이 도구들은 Jest, PyTest, JUnit 테스트 케이스를 즉시 생성할 수 있게 해주는 강력하고 혁신적인 솔루션들을 제공합니다. XIX.AI에서 무료 옵션과 유료 옵션을 실제 테스트 결과와 함께 비교해보시고, 매주 업데이트되는 순위를 확인해보세요. 지금 바로 AI의 장점을 활용하여 개발 생산성을 높이세요.
10 도구
xix.ai
데이터 분석
최고의 AI 데이터 시각화 도구: 원본 파일에서 대화형 BI 대시보드를 자동 생성
XIX.AI에서 2026년 최고의 AI 데이터 시각화 도구를 만나보세요. 저희가 엄선한 최고 평점의 도구들을 통해 원시 파일에서 강력하고 상호작용이 가능한 BI 대시보드를 즉시 자동 생성할 수 있습니다. 실제 테스트와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 데이터의 잠재력을 발휘해 보세요.
10 도구
xix.ai

 의견 (1)
0/500
의견 (1)
0/500
![FredLee]()
This is a game-changer! Imagine AI that can teach itself new tricks without constant human babysitting. The potential for accelerating research is insane, but I can't help but wonder about the 'off-switch' problem. What happens when it decides it wants to learn something we didn't intend? 🤔 The arms race for self-improving models is officially on.
MIT 연구진, 자가 학습 AI 프레임워크 개척
MIT 연구팀은 대규모 언어 모델이 자율적으로 기능을 발전시킬 수 있도록 지원하는 혁신적인 시스템인 SEAL(Self-Adapting Language Models)을 개발했습니다. 이 획기적인 기술을 통해 AI 시스템이 자체적으로 학습 자료와 학습 프로토콜을 생성하여 새로운 지식과 기술을 영구적으로 통합할 수 있게 되었습니다.
SEAL은 엔터프라이즈 AI 애플리케이션, 특히 지속적인 적응이 중요한 유동적인 환경에서 작동하는 지능형 에이전트를 위한 중요한 발전을 의미합니다. 이 프레임워크는 현재 LLM 기술의 근본적인 한계, 즉 일시적인 상황 학습을 넘어선 영구적인 지식 통합이라는 과제를 해결합니다.
현대 AI의 적응 과제
대규모 언어 모델은 인상적인 능력을 보여주지만 새로운 정보를 진정으로 학습하고 내면화하는 능력에는 여전히 제약이 있습니다. 미세 조정이나 문맥 내 학습과 같은 현재의 적응 방식은 입력 데이터를 모델의 학습 프로세스에 최적화하지 않고 수동적으로 처리합니다.
"엔터프라이즈 애플리케이션에는 일시적인 지식 리콜 이상의 심층적이고 지속적인 적응이 필요합니다."라고 논문 공동 저자이자 MIT 박사 과정생인 Jyo Pari는 설명합니다. "독점 프레임워크를 마스터하는 코딩 어시스턴트든 사용자 선호도를 학습하는 고객 서비스 AI든, 이러한 지식은 모델의 핵심 아키텍처에 내장되어야 합니다."라고 설명합니다.
SEAL 아키텍처
SEAL 프레임워크는 모델이 자체 매개변수를 업데이트하기 위한 특수 지침인 '자체 편집'을 생성하는 새로운 강화 학습 접근 방식을 도입합니다. 이러한 편집을 통해 정보를 재구성하고, 합성 훈련 예제를 생성하거나, 학습 프로토콜을 정의하여 모델이 자체 커리큘럼을 효과적으로 설계할 수 있습니다.
이 시스템은 이중 학습 주기를 통해 작동합니다:
- 내부 루프: 자체 생성된 편집 내용을 기반으로 임시 가중치 업데이트를 실행합니다.
- 외부 루프: 업데이트 효과를 평가하고 성공적인 전략을 강화합니다.
이러한 지속적인 자기 개선 메커니즘은 합성 데이터 생성, 강화 학습, 테스트 시간 훈련을 일관된 학습 패러다임으로 결합합니다.
다양한 영역에서 입증된 성능
지식 통합
지식 유지 테스트에서 SEAL로 강화된 모델은 소스 자료에 대한 액세스 없이도 47%의 정확도로 구절 내용을 리콜하여 기본 미세 조정 및 GPT-4.1로 생성된 합성 데이터보다 훨씬 뛰어난 성능을 보여주었습니다.
소수 샷 학습
ARC 데이터 세트의 추상 추론 과제에 적용했을 때 SEAL은 72.5%의 성공을 거두었으며, 이는 표준 인컨텍스트 학습 접근 방식에 비해 크게 개선된 수치입니다.
엔터프라이즈 애플리케이션
고품질 학습 데이터의 고갈에 대한 우려가 커지고 있는 가운데, 자체 생성 학습 자료에 대한 SEAL의 역량은 지속 가능한 길을 제시합니다. 이 기술을 통해 모델은 반복적인 자기 설명을 통해 연구 논문이나 재무 보고서와 같은 복잡한 문서에 대한 이해를 자율적으로 심화할 수 있습니다.
이 프레임워크는 시스템이 환경 상호작용에서 얻은 운영 지식을 영구적으로 통합할 수 있도록 하여 AI 에이전트 개발에 특히 유망합니다. 정적 프로그래밍 접근 방식과 달리 SEAL 기반 에이전트는 시간이 지남에 따라 역량을 발전시키면서 사람의 개입에 대한 의존도를 줄일 수 있습니다.
현재의 한계
SEAL의 구현에는 몇 가지 실질적인 고려 사항이 있습니다:
- 치명적인 망각: 지속적인 자체 편집은 이전에 학습한 정보를 덮어쓸 위험이 있습니다.
- 계산 오버헤드: 적응 프로세스에는 상당한 처리 시간이 필요합니다.
- 하이브리드 구현 필요: SEAL과 검색 증강 생성(RAG)을 결합하면 메모리 관리를 최적화할 수 있습니다.
"기업에서는 지속적인 적응보다는 예약된 업데이트 주기를 구현하는 것이 좋습니다."라고 Pari는 조언합니다. "이렇게 하면 적응의 이점과 실질적인 운영상의 제약이 균형을 이룰 수 있습니다."
이 연구는 언어 모델이 초기 훈련 후에도 고정된 상태로 유지될 필요가 없음을 보여줍니다. 자체 업데이트를 생성하고 적용하는 방법을 학습함으로써 자율적으로 지식을 확장하고 새로운 과제에 적응할 수 있으며, 이는 엔터프라이즈 AI 구현을 재정의할 수 있는 역량입니다.










 멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
 비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
 인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된
인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

2026년에 출시된 최신이자 가장 높은 평가를 받는 AI 도구들을 만나보세요. 저희가 엄선한 이 도구들은 Jest, PyTest, JUnit 테스트 케이스를 즉시 생성할 수 있게 해주는 강력하고 혁신적인 솔루션들을 제공합니다. XIX.AI에서 무료 옵션과 유료 옵션을 실제 테스트 결과와 함께 비교해보시고, 매주 업데이트되는 순위를 확인해보세요. 지금 바로 AI의 장점을 활용하여 개발 생산성을 높이세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 데이터 시각화 도구를 만나보세요. 저희가 엄선한 최고 평점의 도구들을 통해 원시 파일에서 강력하고 상호작용이 가능한 BI 대시보드를 즉시 자동 생성할 수 있습니다. 실제 테스트와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 데이터의 잠재력을 발휘해 보세요.
10 도구
xix.ai

This is a game-changer! Imagine AI that can teach itself new tricks without constant human babysitting. The potential for accelerating research is insane, but I can't help but wonder about the 'off-switch' problem. What happens when it decides it wants to learn something we didn't intend? 🤔 The arms race for self-improving models is officially on.













