Ein Team am MIT hat ein innovatives System namens SEAL (Self-Adapting Language Models) entwickelt, das große Sprachmodelle in die Lage versetzt, ihre Fähigkeiten selbständig weiterzuentwickeln. Dieser Durchbruch ermöglicht es KI-Systemen, ihr eigenes Trainingsmaterial und ihre eigenen Lernprotokolle zu generieren, was eine permanente Integration von neuem Wissen und neuen Fähigkeiten ermöglicht.
SEAL stellt einen bedeutenden Fortschritt für KI-Anwendungen in Unternehmen dar, insbesondere für intelligente Agenten, die in fluiden Umgebungen arbeiten, in denen eine kontinuierliche Anpassung entscheidend ist. Das Framework adressiert eine grundlegende Einschränkung der aktuellen LLM-Technologie - die Herausforderung der permanenten Wissensintegration über das temporäre kontextuelle Lernen hinaus.
Die Herausforderung der Adaption in der modernen KI
Obwohl große Sprachmodelle beeindruckende Fähigkeiten aufweisen, bleibt ihre Fähigkeit, wirklich zu lernen und neue Informationen zu verinnerlichen, begrenzt. Aktuelle Anpassungsmethoden wie Feinabstimmung oder kontextbezogenes Lernen behandeln Eingabedaten passiv, ohne sie für die Lernprozesse des Modells zu optimieren.
"Unternehmensanwendungen erfordern mehr als nur den vorübergehenden Abruf von Wissen - sie brauchen eine tiefgreifende, dauerhafte Anpassung", erklärt Jyo Pari, Doktorand am MIT und Mitautor der Studie. "Ob es sich um einen Programmierassistenten handelt, der proprietäre Frameworks beherrscht, oder um eine Kundendienst-KI, die die Vorlieben der Nutzer lernt - dieses Wissen muss in die Kernarchitektur des Modells eingebettet werden."
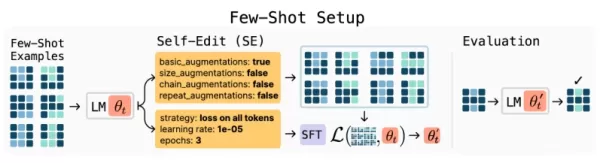
Die SEAL-Architektur
SEAL-Framework-Übersicht (Quelle: arXiv)
Das SEAL-Framework führt einen neuartigen Ansatz des Reinforcement Learning ein, bei dem Modelle "Self-Edits" generieren - spezielle Anweisungen zur Aktualisierung ihrer eigenen Parameter. Diese Bearbeitungen können Informationen umstrukturieren, synthetische Trainingsbeispiele erstellen oder sogar Lernprotokolle definieren, so dass das Modell seinen eigenen Lehrplan erstellen kann.
Das System arbeitet mit zwei Lernzyklen:
Innere Schleife: Führt temporäre Gewichtungsaktualisierungen auf der Grundlage von selbst erstellten Bearbeitungen aus
Äußere Schleife: Bewertet die Wirksamkeit der Aktualisierungen und stärkt erfolgreiche Strategien
Dieser Mechanismus zur kontinuierlichen Selbstverbesserung kombiniert die Erzeugung synthetischer Daten, das Verstärkungslernen und das Training zur Testzeit zu einem zusammenhängenden Lernparadigma.
Bewährte Leistung in verschiedenen Bereichen
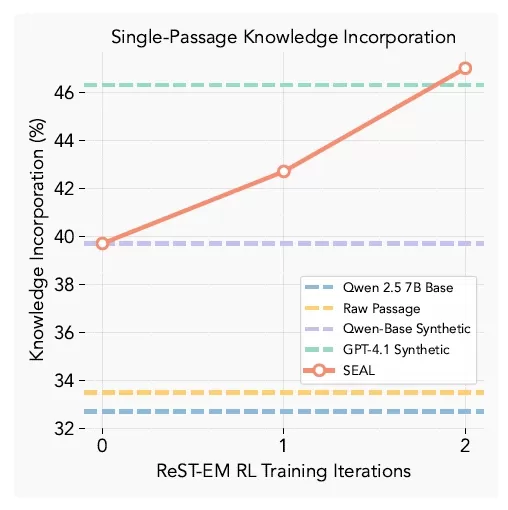
Integration von Wissen
SEAL-Ergebnisse zur Wissensintegration (Quelle: arXiv)
In Tests zur Wissensspeicherung zeigten SEAL-verbesserte Modelle eine Genauigkeit von 47 % bei der Wiedererkennung von Passageninhalten ohne Zugriff auf das Quellmaterial - und übertrafen damit deutlich sowohl die Feinabstimmung der Basisdaten als auch die von GPT-4.1 generierten synthetischen Daten.
Few-Shot-Lernen
SEAL Few-Shot Learning Leistung (Quelle: arXiv)
Bei der Anwendung auf abstrakte Schlussfolgerungen aus dem ARC-Datensatz erreichte SEAL 72,5 % Erfolg - eine dramatische Verbesserung gegenüber standardmäßigen In-Context-Lernansätzen.
Anwendungen für Unternehmen
In Anbetracht der wachsenden Besorgnis über die Erschöpfung qualitativ hochwertiger Trainingsdaten bietet die Fähigkeit von SEAL, Lernmaterialien selbst zu generieren, einen nachhaltigen Weg in die Zukunft. Die Technologie ermöglicht es den Modellen, ihr Verständnis komplexer Dokumente wie Forschungsarbeiten oder Finanzberichte durch iterative Selbsterläuterung selbstständig zu vertiefen.
Der Rahmen ist besonders vielversprechend für die Entwicklung von KI-Agenten, da er es den Systemen ermöglicht, permanent operatives Wissen aus Interaktionen mit der Umwelt zu integrieren. Im Gegensatz zu statischen Programmieransätzen können SEAL-gestützte Agenten ihre Kompetenzen im Laufe der Zeit weiterentwickeln und sind dabei weniger von menschlichen Eingriffen abhängig.
Derzeitige Beschränkungen
Die SEAL-Implementierung steht vor mehreren praktischen Problemen:
Katastrophisches Vergessen: Durch die kontinuierliche Selbstkorrektur besteht die Gefahr, dass zuvor gelernte Informationen überschrieben werden.
Rechnerischer Overhead: Der Anpassungsprozess erfordert erhebliche Rechenzeit
Hybride Implementierung erforderlich: Die Kombination von SEAL mit Retrieval-Augmented Generation (RAG) kann die Speicherverwaltung optimieren
"Wir empfehlen Unternehmen, geplante Aktualisierungszyklen anstelle einer kontinuierlichen Anpassung zu implementieren", rät Pari. "Dies schafft ein Gleichgewicht zwischen den Vorteilen der Anpassung und den praktischen betrieblichen Zwängen.
Die progressive Verbesserung von SEAL (Quelle: arXiv)
Die Forschung zeigt, dass Sprachmodelle nach dem ersten Training nicht statisch bleiben müssen. Indem sie lernen, ihre eigenen Updates zu generieren und anzuwenden, können sie ihr Wissen selbstständig erweitern und sich an neue Herausforderungen anpassen - eine Fähigkeit, die die Implementierung von KI in Unternehmen neu definieren könnte.
Microsoft streicht Jobs trotz robuster FinanzergebnisseMicrosoft kündigt strategische Personalumstrukturierung anMicrosoft hat Personalabbau eingeleitet, von dem etwa 7.000 Mitarbeiter betroffen sind, was 3 % seiner weltweiten Belegschaft entspricht. Wichtig ist, dass diese Veränderungen strategische Pri
Microsoft-Studie: Mehr KI-Token erhöhen DenkfehlerNeue Einsichten in die Effizienz von LLM-ReasoningNeue Forschungsergebnisse von Microsoft zeigen, dass fortschrittliche Schlussfolgerungstechniken in großen Sprachmodellen nicht zu einheitlichen Verbe
Durch das Klicken auf „Alle Cookies akzeptieren“ stimmen Sie zu, dass Cookies auf Ihrem Gerät gespeichert werden, um die Seitennavigation zu verbessern, die Seitennutzung zu analysieren und unsere Marketingbemühungen zu unterstützen.Datenschutzerklärung Hinweis
Beim Besuch einer Website kann diese Informationen in Ihrem Browser speichern oder abrufen, hauptsächlich in Form von Cookies. Diese Informationen können sich auf Sie, Ihre Präferenzen oder Ihr Gerät beziehen und dienen hauptsächlich dazu, dass die Website so funktioniert, wie Sie es erwarten. Die Informationen identifizieren Sie in der Regel nicht direkt, können Ihnen aber ein personalisierteres Web-Erlebnis bieten. Da wir Ihr Recht auf Privatsphäre respektieren, können Sie wählen, dass Sie bestimmte Arten von Cookies nicht zulassen. Klicken Sie auf die verschiedenen Kategorietitel, um mehr zu erfahren und unsere Standardeinstellungen zu ändern. Das Blockieren bestimmter Arten von Cookies kann jedoch Ihre Erfahrung auf der Website und die von uns angebotenen Dienste beeinträchtigen. DatenschutzerklärungErklärung
Einstellungen verwalten
Unbedingt erforderliche Cookies
Immer aktiv
Diese Cookies sind für die Funktionalität der Website erforderlich und können in unseren Systemen nicht deaktiviert werden. Sie werden normalerweise nur in Reaktion auf Ihre Aktionen gesetzt, die einer Dienstanfrage entsprechen, z. B. das Einstellen Ihrer Datenschutzpräferenzen, das Anmelden oder das Ausfüllen von Formularen. Sie können Ihren Browser so einstellen, dass diese Cookies blockiert oder Sie darüber benachrichtigt werden, aber einige Teile der Website werden dann nicht mehr funktionieren. Diese Cookies speichern keine personenbezogenen Daten.







 Microsoft streicht Jobs trotz robuster Finanzergebnisse
Microsoft kündigt strategische Personalumstrukturierung anMicrosoft hat Personalabbau eingeleitet, von dem etwa 7.000 Mitarbeiter betroffen sind, was 3 % seiner weltweiten Belegschaft entspricht. Wichtig ist, dass diese Veränderungen strategische Pri
Microsoft streicht Jobs trotz robuster Finanzergebnisse
Microsoft kündigt strategische Personalumstrukturierung anMicrosoft hat Personalabbau eingeleitet, von dem etwa 7.000 Mitarbeiter betroffen sind, was 3 % seiner weltweiten Belegschaft entspricht. Wichtig ist, dass diese Veränderungen strategische Pri










 Multiverse AI bringt bahnbrechende Miniatur-Hochleistungsmodelle auf den Markt
Ein bahnbrechendes europäisches KI-Startup hat bahnbrechende KI-Modelle in Mikrogröße vorgestellt, die nach Vogel- und Insektengehirnen benannt sind, und damit gezeigt, dass leistungsstarke künstliche
Multiverse AI bringt bahnbrechende Miniatur-Hochleistungsmodelle auf den Markt
Ein bahnbrechendes europäisches KI-Startup hat bahnbrechende KI-Modelle in Mikrogröße vorgestellt, die nach Vogel- und Insektengehirnen benannt sind, und damit gezeigt, dass leistungsstarke künstliche
 Microsoft-Studie: Mehr KI-Token erhöhen Denkfehler
Neue Einsichten in die Effizienz von LLM-ReasoningNeue Forschungsergebnisse von Microsoft zeigen, dass fortschrittliche Schlussfolgerungstechniken in großen Sprachmodellen nicht zu einheitlichen Verbe
Microsoft-Studie: Mehr KI-Token erhöhen Denkfehler
Neue Einsichten in die Effizienz von LLM-ReasoningNeue Forschungsergebnisse von Microsoft zeigen, dass fortschrittliche Schlussfolgerungstechniken in großen Sprachmodellen nicht zu einheitlichen Verbe













