
















 首頁
首頁麻省理工學院推出超越靜態模型的自我學習 AI 架構
麻省理工學院研究人員開創自學人工智能框架
麻省理工學院的研究團隊開發了一套名為 SEAL(Self-Adapting Language Models,自適應語言模型)的創新系統,讓大型語言模型能夠自主進化其能力。這項突破使人工智能系統能夠產生自己的訓練材料和學習協議,允許永久整合新知識和技能。
SEAL 代表了企業級 AI 應用的重大進步,特別是對於在流動環境中運作的智慧型代理人而言,持續適應是非常重要的。此架構解決了目前 LLM 技術中的基本限制 - 即在臨時情境學習之外的永久性知識整合挑戰。
現代人工智能的適應性挑戰
雖然大型語言模型展現出令人印象深刻的能力,但其真正學習和內化新資訊的能力仍然受到限制。目前的適應方法,例如微調或上下文學習,都是被動地處理輸入資料,而沒有針對模型的學習過程進行最佳化。
"麻省理工學院博士生兼論文合著者 Jyo Pari 解釋說:「企業應用需要的不只是暫時的知識回憶,而是深入、持久的適應。「無論是掌握專屬框架的編碼助理,或是學習使用者偏好的客服 AI,這些知識都必須嵌入模型的核心架構中。」
SEAL 架構

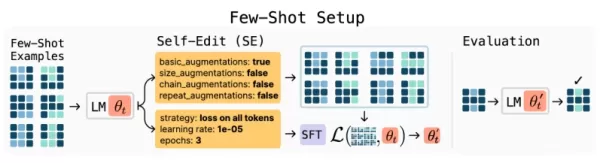
SEAL 架構概觀 (資料來源:arXiv) SEAL 架構引入了一種新穎的強化學習方法,模型會產生「自我編輯」(self-edits),也就是更新自身參數的專門指令。這些編輯可以重組資訊、建立合成訓練範例,甚至定義學習協議,有效地讓模型設計自己的課程。
系統透過雙學習循環來運作:
- 內環:根據自我產生的編輯執行臨時權重更新
- 外環:評估更新的有效性並強化成功的策略
這種持續的自我改進機制將合成資料生成、強化學習和測試時間訓練結合為一個連貫的學習範例。
跨領域的驗證效能
知識整合

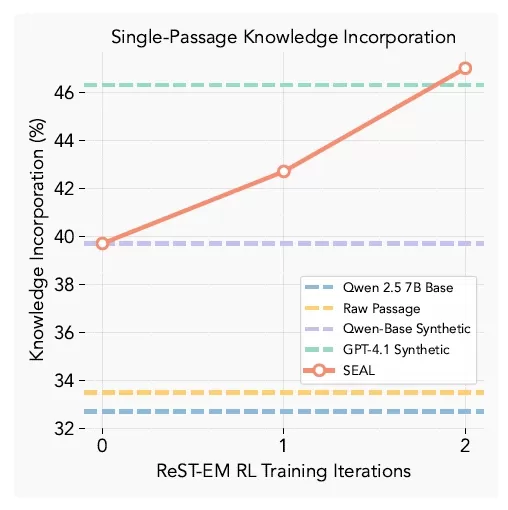
SEAL 知識整合結果 (資料來源:arXiv) 在知識保留測試中,SEAL 增強型模型在不存取原始資料的情況下,回憶段落內容的準確率達到 47%,大幅超越基線微調和 GPT-4.1 產生的合成資料。
少量學習
SEAL 快速學習效能 (資料來源:arXiv) 當應用於 ARC 資料集中的抽象推理挑戰時,SEAL 取得 72.5% 的成功率 - 比標準的情境學習方法有顯著的改善。
企業應用
隨著人們對優質訓練資料枯竭的憂慮與日俱增,SEAL 的自我生成學習材料能力提供了一條可持續發展的道路。該技術可讓模型透過迭代式自我解釋,自主加深對研究論文或財務報告等複雜文件的理解。
此架構對於 AI 代理的開發顯示出特殊的前景,可讓系統永久整合來自環境互動的作業知識。與靜態程式設計方法不同,SEAL 驅動的代理可隨著時間演進其能力,同時減少對人為干預的依賴。
目前的限制
SEAL 的實作面臨幾個實際的考量:
- 災難性遺忘:持續的自我編輯有可能會覆蓋先前學到的資訊
- 運算開銷:適應過程需要大量的處理時間
- 需要混合實作:結合 SEAL 與檢索增量生成 (RAG) 可優化記憶體管理
"我們建議企業實施排程更新週期,而非持續適應,」Pari 表示。「這樣可以平衡適應性優點與實際操作限制」。
SEAL 的逐步改進(資料來源:arXiv) 這項研究證明,語言模型在經過初始訓練後,不需要保持靜態。透過學習產生和應用自己的更新,它們可以自主擴展知識並適應新的挑戰 - 這種能力可以重新定義企業 AI 的實施。
相關文章
 Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
相關專題推薦
商業
Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
相關專題推薦
商業
 最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
 10 個工具
10 個工具
 xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai
代碼
最適合自動化單元測試的最佳AI工具:一鍵生成Jest、PyTest和JUnit測試用例
探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

 評論 (1)
0/500
評論 (1)
0/500
![FredLee]()
This is a game-changer! Imagine AI that can teach itself new tricks without constant human babysitting. The potential for accelerating research is insane, but I can't help but wonder about the 'off-switch' problem. What happens when it decides it wants to learn something we didn't intend? 🤔 The arms race for self-improving models is officially on.
麻省理工學院研究人員開創自學人工智能框架
麻省理工學院的研究團隊開發了一套名為 SEAL(Self-Adapting Language Models,自適應語言模型)的創新系統,讓大型語言模型能夠自主進化其能力。這項突破使人工智能系統能夠產生自己的訓練材料和學習協議,允許永久整合新知識和技能。
SEAL 代表了企業級 AI 應用的重大進步,特別是對於在流動環境中運作的智慧型代理人而言,持續適應是非常重要的。此架構解決了目前 LLM 技術中的基本限制 - 即在臨時情境學習之外的永久性知識整合挑戰。
現代人工智能的適應性挑戰
雖然大型語言模型展現出令人印象深刻的能力,但其真正學習和內化新資訊的能力仍然受到限制。目前的適應方法,例如微調或上下文學習,都是被動地處理輸入資料,而沒有針對模型的學習過程進行最佳化。
"麻省理工學院博士生兼論文合著者 Jyo Pari 解釋說:「企業應用需要的不只是暫時的知識回憶,而是深入、持久的適應。「無論是掌握專屬框架的編碼助理,或是學習使用者偏好的客服 AI,這些知識都必須嵌入模型的核心架構中。」
SEAL 架構
SEAL 架構引入了一種新穎的強化學習方法,模型會產生「自我編輯」(self-edits),也就是更新自身參數的專門指令。這些編輯可以重組資訊、建立合成訓練範例,甚至定義學習協議,有效地讓模型設計自己的課程。
系統透過雙學習循環來運作:
- 內環:根據自我產生的編輯執行臨時權重更新
- 外環:評估更新的有效性並強化成功的策略
這種持續的自我改進機制將合成資料生成、強化學習和測試時間訓練結合為一個連貫的學習範例。
跨領域的驗證效能
知識整合
在知識保留測試中,SEAL 增強型模型在不存取原始資料的情況下,回憶段落內容的準確率達到 47%,大幅超越基線微調和 GPT-4.1 產生的合成資料。
少量學習
當應用於 ARC 資料集中的抽象推理挑戰時,SEAL 取得 72.5% 的成功率 - 比標準的情境學習方法有顯著的改善。
企業應用
隨著人們對優質訓練資料枯竭的憂慮與日俱增,SEAL 的自我生成學習材料能力提供了一條可持續發展的道路。該技術可讓模型透過迭代式自我解釋,自主加深對研究論文或財務報告等複雜文件的理解。
此架構對於 AI 代理的開發顯示出特殊的前景,可讓系統永久整合來自環境互動的作業知識。與靜態程式設計方法不同,SEAL 驅動的代理可隨著時間演進其能力,同時減少對人為干預的依賴。
目前的限制
SEAL 的實作面臨幾個實際的考量:
- 災難性遺忘:持續的自我編輯有可能會覆蓋先前學到的資訊
- 運算開銷:適應過程需要大量的處理時間
- 需要混合實作:結合 SEAL 與檢索增量生成 (RAG) 可優化記憶體管理
"我們建議企業實施排程更新週期,而非持續適應,」Pari 表示。「這樣可以平衡適應性優點與實際操作限制」。
這項研究證明,語言模型在經過初始訓練後,不需要保持靜態。透過學習產生和應用自己的更新,它們可以自主擴展知識並適應新的挑戰 - 這種能力可以重新定義企業 AI 的實施。










 Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
Multiverse Computing 推出免費壓縮生成式人工智慧模型
大型語言模型面臨著重大挑戰:其龐大的體積。西班牙新創公司Multiverse Computing正透過開發壓縮模型來解決此問題,旨在彌合尖端AI能力與企業實際可負擔部署方案之間的差距。其核心創新在於「CompactifAI」壓縮技術——這項受量子運算原理啟發的技術,已被這家巴斯克公司用於優化OpenAI的模型。即日起,開發者可在Hugging Face平台免費使用Multiverse增強版的Hyp
 秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
秘密追蹤數據揭露人工智慧模型遭竊事件
一種新方法能在數秒內對ChatGPT等模型進行隱形水印處理,無需重新訓練,既不會在標準輸出中留下痕跡,又能抵禦所有實際的移除嘗試。 水印技術與「版權誘餌」的核心差異在於:無論可見或隱藏的水印,通常設計為貫穿整個資料集(如圖像資料集)的恆定存在,藉此對隨意複製行為形成持續威懾。相對地,虛構條目是將一小段文字(通常為單詞或定義)植入龐大通用資料庫,旨在證明盜用行為。其原理在於:當整部作品遭未經授權複製
 人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。
人工智慧系統被騙批准荒謬科學論文
最新研究揭示,人工智慧系統現已能生成虛假科學論文,且其他AI模型會誤判其為真實研究。這些偽造研究能成功繞過過往有效的檢測方法,凸顯研究生態系統面臨崩潰風險——可能陷入機器人欺騙機器人的循環漩渦。 諷刺的是,正處於AI創新前沿的學術研究領域,如今卻正面臨主要由AI引發的可信度危機。自約四年前機器學習的潛在影響顯現以來,其已深刻重塑了研究、投稿與同行評審流程。最新爭議涉及低品質問卷調查論文的批量生產。

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

This is a game-changer! Imagine AI that can teach itself new tricks without constant human babysitting. The potential for accelerating research is insane, but I can't help but wonder about the 'off-switch' problem. What happens when it decides it wants to learn something we didn't intend? 🤔 The arms race for self-improving models is officially on.













