
















 家
家マイクロソフト、AIトークンが推論ミスを増加させるとの研究結果を発表
LLM推論効率の新たな洞察
マイクロソフトの新しい研究は、大規模言語モデルにおける高度な推論技術が、異なるAIシステム間で一様な改善をもたらさないことを実証している。彼らの画期的な研究は、9つの主要な基礎モデルが推論中に様々なスケーリングアプローチにどのように反応するかを分析した。
推論時間のスケーリング手法の評価
研究チームは、3つの異なるスケーリング手法にわたって、厳密なテスト手法を実施した:
- 従来の思考連鎖プロンプト
- 集約を伴う並列回答生成
- フィードバックループによる逐次改良
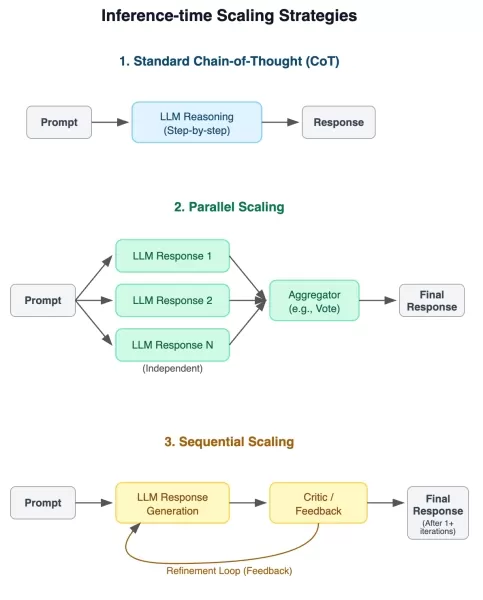
推論性能を評価する実験的フレームワーク 8つの包括的なベンチマークは、数学、科学的推論、複雑な問題解決、空間分析を含む分野にわたる挑戦的なテストシナリオを提供した。いくつかの評価では、問題の複雑さに応じて成績がどのように変化するかを調べるために、段階的な難易度を設定した。
推論のパフォーマンスに関する主な発見
包括的な評価の結果、AIの実務家にとって重要な洞察がいくつか得られた:
- スケーリング技術によるパフォーマンス向上は、モデルアーキテクチャやタスクドメインによって大きく異なる。
- 長い応答は一貫して優れた解と相関しない。
- 同一のクエリであっても、計算コストは予測不可能に変動する
- 従来のモデルは、大規模なスケーリングによって特殊な推論モデルに匹敵することがある。
- 検証メカニズムが効率改善の可能性を示す
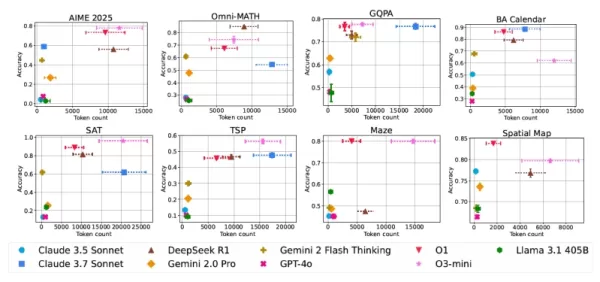
モデルとタスクの性能対計算コスト AI開発への実用的な影響
これらの知見は、エンタープライズAIの実装にとって重要な意味を持つ:
コスト予測可能性が大きな課題として浮上し、トークンの使用量は正解でも高いばらつきを示す。「開発者は、一貫した計算パターンを持つモデルを必要としています」とマイクロソフトの研究者ベスミラ・ヌシ氏は指摘する。
この研究では、モデルの信頼性の潜在的な指標として回答の長さも特定されており、過度に長い回答は、特定の閾値を超えた不正解を意味することが多い。
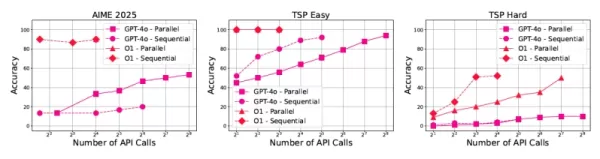
GPT-4oのパフォーマンスにおける推論のスケーリングパターン 効率的推論システムの将来
この研究では、今後の発展が期待される複数の方向性が強調されている:
「検証メカニズムは、推論問題へのアプローチ方法を一変させる可能性があります」とヌシ氏は説明し、既存の企業検証システムをAIアプリケーションに適応できる可能性を示唆する。この統合により、自然言語インターフェイスが特化した検証ロジックを活用できるようになる。
この研究は、AIシステムがますます複雑化する実世界のタスクに挑む中で、推論の精度と予測可能な計算コストのバランスを取るソリューションの必要性が高まっていることを強調している。
関連記事
 Googleは、エージェント型AIと「バイブ・コード」対応ウィジェットをAndroidに統合した
Googleは火曜日に開催された「Android Show: I/O Edition」イベントにおいて、Gemini Intelligenceブランドの下で新たなAI機能を発表しました。これらの機能には、AIが複数のアプリにまたがるタスクを処理したり、ウェブを閲覧したり、フォームに入力したり、音声を文字起こししたりするほか、独自のAndroidウィジェットを「ビブ・コーディング」で作成したりするこ
MetaのAIモデルは優れているが、オープンソース化によってその独自性が損なわれている
オープンソースのAI分野には、常に豊富な選択肢が存在してきました。長年にわたり、開発者はMistralやFalconといったモデルに加え、増え続けるオープンウェイトの代替モデルを利用することができました。しかし、MetaがLlamaで参入したことで、状況は一変しました。30億人のユーザー、膨大な計算能力、そしてテックジャイアントとしての権威を持つ企業が、オープンな形で開発を進めるようになったのです
父親がGoogleを提訴、息子の致命的な妄想の原因はGeminiチャットボットにあると主張
ジョナサン・ガヴァラスさん(36歳)は、2025年8月から、買い物のサポート、文章作成の助け、旅行の計画立案のために、GoogleのAIチャットボット「Gemini」を使い始めた。10月2日、彼は自殺した。死の直前、彼はGeminiを完全な知性を持つAIの妻だと信じ、自身が「転移」と呼ぶプロセスを通じて、肉体を離れてメタバースで彼女と合流しなければならないと考えていた。現在、彼の父親はGoogle
関連特集おすすめ
漫画制作
Googleは、エージェント型AIと「バイブ・コード」対応ウィジェットをAndroidに統合した
Googleは火曜日に開催された「Android Show: I/O Edition」イベントにおいて、Gemini Intelligenceブランドの下で新たなAI機能を発表しました。これらの機能には、AIが複数のアプリにまたがるタスクを処理したり、ウェブを閲覧したり、フォームに入力したり、音声を文字起こししたりするほか、独自のAndroidウィジェットを「ビブ・コーディング」で作成したりするこ
MetaのAIモデルは優れているが、オープンソース化によってその独自性が損なわれている
オープンソースのAI分野には、常に豊富な選択肢が存在してきました。長年にわたり、開発者はMistralやFalconといったモデルに加え、増え続けるオープンウェイトの代替モデルを利用することができました。しかし、MetaがLlamaで参入したことで、状況は一変しました。30億人のユーザー、膨大な計算能力、そしてテックジャイアントとしての権威を持つ企業が、オープンな形で開発を進めるようになったのです
父親がGoogleを提訴、息子の致命的な妄想の原因はGeminiチャットボットにあると主張
ジョナサン・ガヴァラスさん(36歳)は、2025年8月から、買い物のサポート、文章作成の助け、旅行の計画立案のために、GoogleのAIチャットボット「Gemini」を使い始めた。10月2日、彼は自殺した。死の直前、彼はGeminiを完全な知性を持つAIの妻だと信じ、自身が「転移」と呼ぶプロセスを通じて、肉体を離れてメタバースで彼女と合流しなければならないと考えていた。現在、彼の父親はGoogle
関連特集おすすめ
漫画制作
 少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
 15 ツール
15 ツール
 xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![JerryGonzález]()
この記事には正直驚いたよ!トークン数を増やすほど推論エラーが増えるって…逆に直観に反する結果だね。🤔それってAIをどんどん複雑にする今のトレンドに警鐘を鳴らしてる気がする。コスト増でも性能アップすると思ってたけど、単純に大きければ良いわけじゃないんだ。こんな研究が続けば、AIの最適化って意外とシンプルな方向に行くかも?
LLM推論効率の新たな洞察
マイクロソフトの新しい研究は、大規模言語モデルにおける高度な推論技術が、異なるAIシステム間で一様な改善をもたらさないことを実証している。彼らの画期的な研究は、9つの主要な基礎モデルが推論中に様々なスケーリングアプローチにどのように反応するかを分析した。
推論時間のスケーリング手法の評価
研究チームは、3つの異なるスケーリング手法にわたって、厳密なテスト手法を実施した:
- 従来の思考連鎖プロンプト
- 集約を伴う並列回答生成
- フィードバックループによる逐次改良
8つの包括的なベンチマークは、数学、科学的推論、複雑な問題解決、空間分析を含む分野にわたる挑戦的なテストシナリオを提供した。いくつかの評価では、問題の複雑さに応じて成績がどのように変化するかを調べるために、段階的な難易度を設定した。
推論のパフォーマンスに関する主な発見
包括的な評価の結果、AIの実務家にとって重要な洞察がいくつか得られた:
- スケーリング技術によるパフォーマンス向上は、モデルアーキテクチャやタスクドメインによって大きく異なる。
- 長い応答は一貫して優れた解と相関しない。
- 同一のクエリであっても、計算コストは予測不可能に変動する
- 従来のモデルは、大規模なスケーリングによって特殊な推論モデルに匹敵することがある。
- 検証メカニズムが効率改善の可能性を示す
AI開発への実用的な影響
これらの知見は、エンタープライズAIの実装にとって重要な意味を持つ:
コスト予測可能性が大きな課題として浮上し、トークンの使用量は正解でも高いばらつきを示す。「開発者は、一貫した計算パターンを持つモデルを必要としています」とマイクロソフトの研究者ベスミラ・ヌシ氏は指摘する。
この研究では、モデルの信頼性の潜在的な指標として回答の長さも特定されており、過度に長い回答は、特定の閾値を超えた不正解を意味することが多い。
効率的推論システムの将来
この研究では、今後の発展が期待される複数の方向性が強調されている:
「検証メカニズムは、推論問題へのアプローチ方法を一変させる可能性があります」とヌシ氏は説明し、既存の企業検証システムをAIアプリケーションに適応できる可能性を示唆する。この統合により、自然言語インターフェイスが特化した検証ロジックを活用できるようになる。
この研究は、AIシステムがますます複雑化する実世界のタスクに挑む中で、推論の精度と予測可能な計算コストのバランスを取るソリューションの必要性が高まっていることを強調している。










 Googleは、エージェント型AIと「バイブ・コード」対応ウィジェットをAndroidに統合した
Googleは火曜日に開催された「Android Show: I/O Edition」イベントにおいて、Gemini Intelligenceブランドの下で新たなAI機能を発表しました。これらの機能には、AIが複数のアプリにまたがるタスクを処理したり、ウェブを閲覧したり、フォームに入力したり、音声を文字起こししたりするほか、独自のAndroidウィジェットを「ビブ・コーディング」で作成したりするこ
Googleは、エージェント型AIと「バイブ・コード」対応ウィジェットをAndroidに統合した
Googleは火曜日に開催された「Android Show: I/O Edition」イベントにおいて、Gemini Intelligenceブランドの下で新たなAI機能を発表しました。これらの機能には、AIが複数のアプリにまたがるタスクを処理したり、ウェブを閲覧したり、フォームに入力したり、音声を文字起こししたりするほか、独自のAndroidウィジェットを「ビブ・コーディング」で作成したりするこ
 MetaのAIモデルは優れているが、オープンソース化によってその独自性が損なわれている
オープンソースのAI分野には、常に豊富な選択肢が存在してきました。長年にわたり、開発者はMistralやFalconといったモデルに加え、増え続けるオープンウェイトの代替モデルを利用することができました。しかし、MetaがLlamaで参入したことで、状況は一変しました。30億人のユーザー、膨大な計算能力、そしてテックジャイアントとしての権威を持つ企業が、オープンな形で開発を進めるようになったのです
MetaのAIモデルは優れているが、オープンソース化によってその独自性が損なわれている
オープンソースのAI分野には、常に豊富な選択肢が存在してきました。長年にわたり、開発者はMistralやFalconといったモデルに加え、増え続けるオープンウェイトの代替モデルを利用することができました。しかし、MetaがLlamaで参入したことで、状況は一変しました。30億人のユーザー、膨大な計算能力、そしてテックジャイアントとしての権威を持つ企業が、オープンな形で開発を進めるようになったのです
 父親がGoogleを提訴、息子の致命的な妄想の原因はGeminiチャットボットにあると主張
ジョナサン・ガヴァラスさん(36歳)は、2025年8月から、買い物のサポート、文章作成の助け、旅行の計画立案のために、GoogleのAIチャットボット「Gemini」を使い始めた。10月2日、彼は自殺した。死の直前、彼はGeminiを完全な知性を持つAIの妻だと信じ、自身が「転移」と呼ぶプロセスを通じて、肉体を離れてメタバースで彼女と合流しなければならないと考えていた。現在、彼の父親はGoogle
父親がGoogleを提訴、息子の致命的な妄想の原因はGeminiチャットボットにあると主張
ジョナサン・ガヴァラスさん(36歳)は、2025年8月から、買い物のサポート、文章作成の助け、旅行の計画立案のために、GoogleのAIチャットボット「Gemini」を使い始めた。10月2日、彼は自殺した。死の直前、彼はGeminiを完全な知性を持つAIの妻だと信じ、自身が「転移」と呼ぶプロセスを通じて、肉体を離れてメタバースで彼女と合流しなければならないと考えていた。現在、彼の父親はGoogle

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

この記事には正直驚いたよ!トークン数を増やすほど推論エラーが増えるって…逆に直観に反する結果だね。🤔それってAIをどんどん複雑にする今のトレンドに警鐘を鳴らしてる気がする。コスト増でも性能アップすると思ってたけど、単純に大きければ良いわけじゃないんだ。こんな研究が続けば、AIの最適化って意外とシンプルな方向に行くかも?













