Исследователи Массачусетского технологического института разработали самообучающуюся систему искусственного интеллекта
Группа исследователей из Массачусетского технологического института разработала инновационную систему под названием SEAL (Self-Adapting Language Models), которая позволяет большим языковым моделям автономно развивать свои возможности. Этот прорыв позволяет системам искусственного интеллекта генерировать собственные учебные материалы и протоколы обучения, обеспечивая постоянную интеграцию новых знаний и навыков.
SEAL представляет собой значительное достижение для корпоративных приложений ИИ, особенно для интеллектуальных агентов, работающих в изменчивых средах, где непрерывная адаптация имеет решающее значение. Эта система решает фундаментальное ограничение текущей технологии LLM - проблему постоянной интеграции знаний помимо временного контекстуального обучения.
Проблема адаптации в современном ИИ
Хотя большие языковые модели демонстрируют впечатляющие возможности, их способность по-настоящему учиться и усваивать новую информацию остается ограниченной. Существующие методы адаптации, такие как тонкая настройка или контекстное обучение, относятся к входным данным пассивно, не оптимизируя их для процессов обучения модели.
"Корпоративные приложения требуют не просто временного запоминания знаний - им нужна глубокая и длительная адаптация", - объясняет Дзио Пари, кандидат наук Массачусетского технологического института и соавтор статьи. "Будь то ассистент по кодированию, осваивающий фирменные фреймворки, или ИИ для обслуживания клиентов, изучающий предпочтения пользователей, эти знания должны быть встроены в основную архитектуру модели".
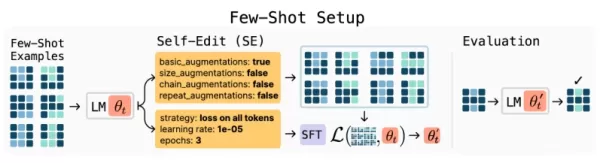
Архитектура SEAL
Обзор фреймворка SEAL (Источник: arXiv)
Фреймворк SEAL представляет собой новый подход к обучению с подкреплением, при котором модели генерируют "саморедактирование" - специализированные инструкции для обновления собственных параметров. Эти правки могут реструктурировать информацию, создавать синтетические обучающие примеры или даже определять протоколы обучения, фактически позволяя модели разрабатывать свой собственный учебный план.
Система работает по двум циклам обучения:
Внутренний цикл: Выполняет временные обновления весов на основе самостоятельно созданных изменений.
Внешний цикл: Оценивает эффективность обновлений и усиливает успешные стратегии.
Этот механизм непрерывного самосовершенствования объединяет генерацию синтетических данных, обучение с подкреплением и обучение в тестовом режиме в единую парадигму обучения.
Доказанная эффективность в различных областях
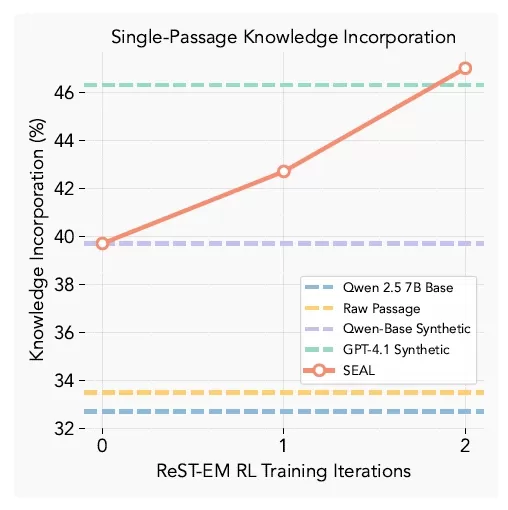
Интеграция знаний
Результаты интеграции знаний SEAL (Источник: arXiv)
В тестах на запоминание знаний модели, усовершенствованные SEAL, продемонстрировали точность 47 % при запоминании содержания отрывков без доступа к исходному материалу, что значительно превосходит как базовую тонкую настройку, так и синтетические данные, сгенерированные GPT-4.1.
Обучение по нескольким снимкам
Результаты обучения по нескольким снимкам SEAL (Источник: arXiv)
Когда SEAL был применен к задачам абстрактного мышления из набора данных ARC, он достиг 72,5 % успеха - это значительное улучшение по сравнению со стандартными подходами к обучению в контексте.
Корпоративные приложения
В условиях растущей озабоченности по поводу исчерпания высококачественных обучающих данных способность SEAL к самостоятельному генерированию учебных материалов предлагает устойчивый путь вперед. Технология позволяет моделям автономно углублять понимание сложных документов, таких как научные статьи или финансовые отчеты, путем итеративного самообъяснения.
Концепция показывает особые перспективы для разработки агентов ИИ, позволяя системам постоянно интегрировать оперативные знания, полученные в результате взаимодействия с окружающей средой. В отличие от статических подходов к программированию, агенты на базе SEAL могут развивать свои компетенции с течением времени, снижая зависимость от вмешательства человека.
Текущие ограничения
Реализация SEAL сталкивается с несколькими практическими проблемами:
Катастрофическая забывчивость: Непрерывное саморедактирование чревато перезаписью ранее усвоенной информации
Перерасход вычислительных ресурсов: Процесс адаптации требует значительного времени обработки.
Необходима гибридная реализация: Сочетание SEAL с генерацией с расширением поиска (RAG) может оптимизировать управление памятью.
"Мы рекомендуем предприятиям внедрять циклы обновления по расписанию, а не непрерывную адаптацию", - советует Пари. "Это позволит сбалансировать преимущества адаптации с практическими операционными ограничениями".
Прогрессивное совершенствование SEAL (Источник: arXiv)
Исследование демонстрирует, что языковые модели не обязательно должны оставаться статичными после первоначального обучения. Научившись генерировать и применять собственные обновления, они могут автономно расширять свои знания и адаптироваться к новым задачам - способность, которая может переосмыслить внедрение корпоративного ИИ.
При нажатии на «Принять все файлы cookie» вы соглашаетесь на хранение файлов cookie на вашем устройстве для улучшения навигации по сайту, анализа использования сайта и поддержки наших маркетинговых усилий.Политика конфиденциальности Уведомление
При посещении любого веб-сайта он может хранить или получать информацию в вашем браузере, главным образом в виде файлов cookie. Эта информация может относиться к вам, вашим предпочтениям или вашему устройству и в основном используется для того, чтобы сайт работал так, как вы ожидаете. Эта информация обычно не идентифицирует вас напрямую, но может предоставить вам более персонализированный веб-опыт. Поскольку мы уважаем ваше право на конфиденциальность, вы можете отказаться от разрешения определенных типов файлов cookie. Нажмите на разные заголовки категорий, чтобы узнать больше и изменить наши параметры по умолчанию. Однако блокировка некоторых типов файлов cookie может повлиять на ваше восприятие сайта и предоставляемые нами услуги. Политика конфиденциальностиЗаявление
Управление предпочтениями
Строго необходимые файлы cookie
Всегда активен
Эти файлы cookie необходимы для работы веб-сайта и не могут быть отключены в наших системах. Обычно они устанавливаются только в ответ на ваши действия, которые являются запросом на предоставление услуг, например, настройка предпочтений конфиденциальности, вход в систему или заполнение форм. Вы можете настроить браузер на блокировку этих файлов cookie или оповещение о них, но тогда некоторые части сайта не будут работать. Эти файлы cookie не хранят никакой персональной информации, позволяющей идентифицировать вас.







 Multiverse AI запускает новые миниатюрные высокопроизводительные модели
Новаторский европейский ИИ-стартап представил революционные микроразмерные модели ИИ, названные в честь мозга птиц и насекомых, демонстрируя, что мощный искусственный интеллект не требует огромных мас
Multiverse AI запускает новые миниатюрные высокопроизводительные модели
Новаторский европейский ИИ-стартап представил революционные микроразмерные модели ИИ, названные в честь мозга птиц и насекомых, демонстрируя, что мощный искусственный интеллект не требует огромных мас










 Multiverse AI запускает новые миниатюрные высокопроизводительные модели
Новаторский европейский ИИ-стартап представил революционные микроразмерные модели ИИ, названные в честь мозга птиц и насекомых, демонстрируя, что мощный искусственный интеллект не требует огромных мас
Multiverse AI запускает новые миниатюрные высокопроизводительные модели
Новаторский европейский ИИ-стартап представил революционные микроразмерные модели ИИ, названные в честь мозга птиц и насекомых, демонстрируя, что мощный искусственный интеллект не требует огромных мас
 Исследование Microsoft показало, что большее количество ИИ-токенов увеличивает количество ошибок в рассуждениях
Новые сведения об эффективности рассуждений в LLMНовое исследование компании Microsoft демонстрирует, что передовые методы рассуждений в больших языковых моделях не дают одинаковых улучшений в разных
Исследование Microsoft показало, что большее количество ИИ-токенов увеличивает количество ошибок в рассуждениях
Новые сведения об эффективности рассуждений в LLMНовое исследование компании Microsoft демонстрирует, что передовые методы рассуждений в больших языковых моделях не дают одинаковых улучшений в разных
 Почему магистранты игнорируют инструкции и как это эффективно исправить
Понимание того, почему большие языковые модели пропускают инструкцииБольшие языковые модели (БЯМ) изменили способы взаимодействия с искусственным интеллектом, позволяя создавать самые разнообразные п
Почему магистранты игнорируют инструкции и как это эффективно исправить
Понимание того, почему большие языковые модели пропускают инструкцииБольшие языковые модели (БЯМ) изменили способы взаимодействия с искусственным интеллектом, позволяя создавать самые разнообразные п













