
















 Maison
Maison
Un nouveau modèle d'IA surpasse les LLM avec une vitesse multipliée par 100 et des données d'entraînement minimales
Sapient Intelligence, une jeune entreprise d'IA basée à Singapour, a mis au point une nouvelle architecture d'IA capable de rivaliser avec les grands modèles de langage (LLM) - et dans certains scénarios, de les surpasser de manière spectaculaire - sur des défis de raisonnement complexes, malgré l'utilisation d'un modèle de taille beaucoup plus réduite et la consommation d'une quantité de données beaucoup moins importante.
Ce système, appelé modèle de raisonnement hiérarchique (MRH), s'inspire de l'utilisation par le cerveau humain de mécanismes distincts pour la planification lente et méthodique et le traitement rapide et intuitif. Le modèle produit des résultats remarquables en n'utilisant qu'une fraction des données et de la mémoire requises par les LLM modernes. Une telle efficacité offre un potentiel important pour les déploiements d'IA dans les entreprises, où les données sont souvent limitées et où la puissance de calcul est une contrainte.
Les limites du raisonnement par chaîne de pensée
Lorsqu'ils sont confrontés à une tâche complexe, les LLM contemporains dépendent principalement de la chaîne de pensée (CoT), où les problèmes sont décomposés en étapes intermédiaires sous forme de texte, obligeant ainsi le modèle à verbaliser son processus de réflexion au fur et à mesure qu'il progresse vers une réponse.
Bien que le CoT ait amélioré les capacités de raisonnement des LLM, il souffre de faiblesses inhérentes. Dans son document de recherche, l'équipe de Sapient Intelligence affirme que "CoT n'est qu'un palliatif pour le raisonnement, pas une véritable solution. Il dépend de ruptures rigides, déterminées par l'homme, où une mauvaise étape ou une séquence mal ordonnée peut complètement faire dérailler l'ensemble du processus".
Cette dépendance à l'égard de la génération d'un texte explicite lie le raisonnement du modèle au niveau du jeton, exigeant souvent d'énormes ensembles de données d'entraînement et entraînant des réponses longues et lentes. Cette méthode ne tient pas compte non plus du type de "raisonnement latent" qui se produit en interne, sans être directement exprimé par des mots.
Les chercheurs observent qu'"une méthode plus rationnelle est essentielle pour réduire ces besoins intensifs en données".
Un cadre hiérarchique inspiré du cerveau
Pour aller plus loin que le CoT, l'équipe a étudié le "raisonnement latent", dans lequel le modèle réfléchit aux problèmes en utilisant ses représentations internes abstraites au lieu de produire des "jetons de réflexion" tangibles. Cela correspond mieux à la cognition humaine ; l'article mentionne que "le cerveau maintient des chaînes de raisonnement logiques étendues avec une efficacité notable dans un espace latent, sans avoir besoin de convertir continuellement les pensées en langage".
Cependant, il est difficile de mettre en œuvre ce type de raisonnement interne profond dans l'IA. Le simple fait d'ajouter des couches à un modèle d'apprentissage profond déclenche fréquemment le problème du "gradient de disparition", où les signaux d'apprentissage s'estompent à travers les couches, ce qui entrave l'efficacité de l'entraînement. À l'inverse, les modèles récurrents qui itèrent à travers les calculs peuvent connaître une "convergence précoce", où le modèle se fixe prématurément sur une solution sans avoir examiné le problème en profondeur.
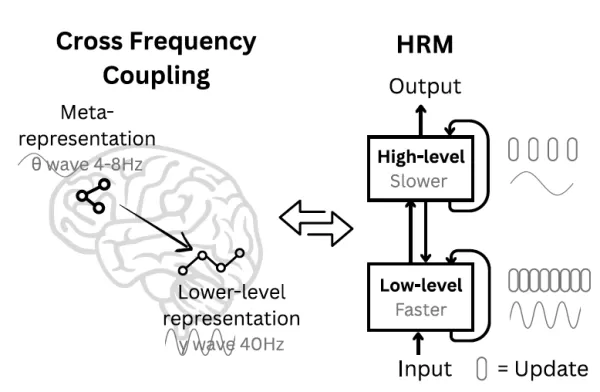
Le modèle de raisonnement hiérarchique (MRH) s'inspire de la structure du cerveau Source : arXiv À la recherche d'une méthode supérieure, l'équipe de Sapient s'est tournée vers les neurosciences. "Le cerveau humain présente un modèle convaincant pour atteindre la profondeur de calcul qui manque aux systèmes artificiels actuels", affirment les chercheurs. "Il structure le calcul de manière hiérarchique à travers des zones corticales travaillant à différentes échelles de temps, ce qui permet une analyse profonde en plusieurs étapes.
Influencés par cette idée, ils ont créé la GRH avec deux modules interconnectés et récurrents : un module de haut niveau (H) pour l'élaboration lente et abstraite de stratégies, et un module de bas niveau (L) pour le traitement rapide et détaillé. Cette disposition facilite un mécanisme que l'équipe appelle "convergence hiérarchique". Essentiellement, le module L rapide s'attaque à un segment du problème et exécute plusieurs cycles jusqu'à ce qu'il trouve une réponse locale stable. Ensuite, le module H lent intègre ce résultat, affine son plan global et assigne au module L un nouveau sous-problème mieux défini. Le module L est ainsi redémarré, ce qui l'empêche de stagner (convergence précoce) et permet au système complet d'effectuer une série étendue d'étapes de raisonnement à l'aide d'une architecture rationalisée qui évite les gradients d'évanouissement.
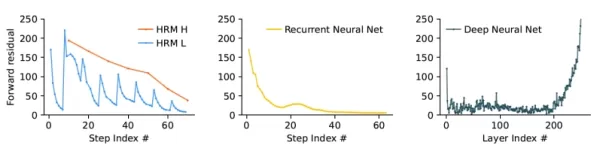
La GRH (à gauche) converge en douceur vers la solution à travers les cycles de calcul et évite la convergence précoce (au centre, les RNN) et les gradients de disparition (à droite, les réseaux neuronaux profonds classiques) Source : arXiv Selon l'article, "ce mécanisme permet au MRH d'effectuer une succession de calculs distincts, réguliers et imbriqués, où le module H guide l'approche globale de résolution du problème et le module L effectue la recherche intensive ou le raffinement pour chaque phase". Cette architecture en boucle imbriquée permet au modèle d'effectuer des analyses approfondies dans son espace latent sans nécessiter d'invites CoT étendues ou d'ensembles de données massifs.
Une préoccupation logique est de savoir si ce "raisonnement latent" sacrifie l'interprétabilité. Guan Wang, fondateur et PDG de Sapient Intelligence, conteste cette notion, précisant que les opérations internes du modèle peuvent être interprétées et illustrées, de la même manière que CoT offre un aperçu de la cognition d'un modèle. Il note en outre que le CoT lui-même peut être peu fiable. "CoT ne représente pas avec précision le véritable raisonnement interne d'un modèle", a déclaré Wang à VentureBeat, citant des recherches indiquant que les modèles peuvent parfois produire des réponses correctes avec un raisonnement erroné, et l'inverse. "Il reste fondamentalement opaque.

Exemple de raisonnement de la GRH sur un problème de labyrinthe à travers différents cycles de calcul Source : arXiv La GRH à l'œuvre
Pour évaluer leur modèle, les chercheurs ont comparé la GRH à des repères exigeant des recherches intensives et des retours en arrière, tels que le Corpus d'abstraction et de raisonnement (ARC-AGI), des puzzles Sudoku très difficiles et des tâches complexes de navigation dans un labyrinthe.
Les résultats révèlent que la GRH apprend à résoudre des problèmes qui sont insolubles même pour des LLM sophistiqués. Par exemple, lors des tests "Sudoku-Extreme" et "Maze-Hard", les modèles CoT de haut niveau ont complètement échoué, enregistrant une précision de 0 %. En revanche, le modèle HRM a atteint une précision quasi parfaite après s'être entraîné sur seulement 1 000 exemples par tâche.
Sur le test de référence ARC-AGI, qui mesure le raisonnement abstrait et la généralisation, le modèle HRM à 27 paramètres a atteint une précision de 40,3 %. Il surpasse ainsi d'éminents modèles basés sur le CoT, tels que le modèle beaucoup plus grand o3-mini-high (34,5 %) et Claude 3.7 Sonnet (21,2 %). Cette performance, réalisée sans un vaste ensemble de données de pré-entraînement et avec un minimum de données, souligne la force et l'efficacité de sa conception.
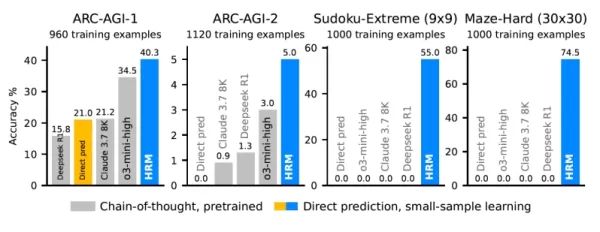
La GRH surpasse les grands modèles dans les tâches de raisonnement complexes Source : arXiv Si la résolution d'énigmes met en évidence les capacités du modèle, son impact pratique est perceptible dans une autre catégorie de défis. Selon Wang, les développeurs devraient continuer à utiliser les LLM pour les tâches créatives ou centrées sur le langage, mais pour les "tâches complexes ou déterministes", un cadre de type HRM fournit des résultats supérieurs avec moins d'hallucinations. Il met l'accent sur les "problèmes séquentiels nécessitant une prise de décision complexe ou une planification à long terme", en particulier dans les domaines où le temps de latence est critique, comme l'IA incarnée et la robotique, ou dans les domaines où les données sont peu nombreuses, comme la recherche scientifique.
Dans ces situations, la GRH ne se contente pas de trouver des solutions, elle apprend à améliorer sa résolution de problèmes. "Dans nos tests de Sudoku de niveau maître [...] la GRH a besoin de moins d'étapes au fur et à mesure que la formation se poursuit, un peu comme un débutant qui se transforme en spécialiste", explique M. Wang.
Pour les entreprises, c'est là que l'efficacité de l'architecture influe sur la rentabilité. Plutôt que la production séquentielle, jeton par jeton, du CoT, le calcul parallèle de la MRH permet ce que M. Wang estime être une "accélération de 100 fois de la vitesse d'exécution des tâches". Il en résulte une réduction de la latence d'inférence et la capacité d'opérer des raisonnements avancés sur des appareils périphériques.
Les avantages financiers sont également considérables. "Les moteurs de raisonnement spécialisés comme la GRH représentent une option plus viable pour les tâches de raisonnement complexes particulières que les modèles pilotés par API, qui sont vastes, coûteux et à forte latence", a déclaré M. Wang. Pour illustrer cette efficacité, il a indiqué que l'entraînement du modèle pour le Sudoku professionnel nécessite environ deux heures de GPU, et pour le benchmark ARC-AGI exigeant, entre 50 et 200 heures de GPU, soit une part minime des ressources requises pour les énormes modèles de base. Cela permet d'aborder des questions commerciales spécialisées, de la planification logistique au dépannage de systèmes complexes, dans des contextes où les données et le financement sont limités.
Sapient Intelligence progresse déjà pour transformer la GRH d'un outil de résolution de problèmes de niche en un composant de raisonnement plus large et polyvalent. "Nous construisons activement des modèles inspirés par le cerveau et basés sur la MRH", a déclaré M. Wang, soulignant les premiers résultats encourageants obtenus dans les domaines de la santé, de la prévision climatique et de la robotique. Il a laissé entendre que ces futurs modèles seront sensiblement différents des systèmes actuels basés sur le texte, notamment grâce à l'intégration de fonctions d'autocorrection.
La recherche implique que pour un ensemble de problèmes qui ont déconcerté les leaders actuels de l'IA, la voie à suivre pourrait ne pas être celle de modèles plus grands, mais de cadres plus intelligents et mieux organisés, modelés sur le système de raisonnement le plus avancé : le cerveau humain.
Article connexe
 Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
L'IA physique fait son entrée dans les usines alors que des robots humanoïdes font l'objet d'essais
Selon Reuters, Humanoid, une entreprise technologique britannique, s'apprête à déployer des robots humanoïdes dans les usines du fournisseur industriel allemand Schaeffler.Selon un porte-parole d'Hum
Recommandations de sujets spéciaux liés
Création de bande dessinée
Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
L'IA physique fait son entrée dans les usines alors que des robots humanoïdes font l'objet d'essais
Selon Reuters, Humanoid, une entreprise technologique britannique, s'apprête à déployer des robots humanoïdes dans les usines du fournisseur industriel allemand Schaeffler.Selon un porte-parole d'Hum
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Les meilleurs outils d'auto-coloration IA pour les mangas : appliquez des couleurs unies sans aucune erreur de cohérence
Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
 10 outils
10 outils
 xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
xix.ai
en écrivant
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

 commentaires (0)
commentaires (0)
Sapient Intelligence, une jeune entreprise d'IA basée à Singapour, a mis au point une nouvelle architecture d'IA capable de rivaliser avec les grands modèles de langage (LLM) - et dans certains scénarios, de les surpasser de manière spectaculaire - sur des défis de raisonnement complexes, malgré l'utilisation d'un modèle de taille beaucoup plus réduite et la consommation d'une quantité de données beaucoup moins importante.
Ce système, appelé modèle de raisonnement hiérarchique (MRH), s'inspire de l'utilisation par le cerveau humain de mécanismes distincts pour la planification lente et méthodique et le traitement rapide et intuitif. Le modèle produit des résultats remarquables en n'utilisant qu'une fraction des données et de la mémoire requises par les LLM modernes. Une telle efficacité offre un potentiel important pour les déploiements d'IA dans les entreprises, où les données sont souvent limitées et où la puissance de calcul est une contrainte.
Les limites du raisonnement par chaîne de pensée
Lorsqu'ils sont confrontés à une tâche complexe, les LLM contemporains dépendent principalement de la chaîne de pensée (CoT), où les problèmes sont décomposés en étapes intermédiaires sous forme de texte, obligeant ainsi le modèle à verbaliser son processus de réflexion au fur et à mesure qu'il progresse vers une réponse.
Bien que le CoT ait amélioré les capacités de raisonnement des LLM, il souffre de faiblesses inhérentes. Dans son document de recherche, l'équipe de Sapient Intelligence affirme que "CoT n'est qu'un palliatif pour le raisonnement, pas une véritable solution. Il dépend de ruptures rigides, déterminées par l'homme, où une mauvaise étape ou une séquence mal ordonnée peut complètement faire dérailler l'ensemble du processus".
Cette dépendance à l'égard de la génération d'un texte explicite lie le raisonnement du modèle au niveau du jeton, exigeant souvent d'énormes ensembles de données d'entraînement et entraînant des réponses longues et lentes. Cette méthode ne tient pas compte non plus du type de "raisonnement latent" qui se produit en interne, sans être directement exprimé par des mots.
Les chercheurs observent qu'"une méthode plus rationnelle est essentielle pour réduire ces besoins intensifs en données".
Un cadre hiérarchique inspiré du cerveau
Pour aller plus loin que le CoT, l'équipe a étudié le "raisonnement latent", dans lequel le modèle réfléchit aux problèmes en utilisant ses représentations internes abstraites au lieu de produire des "jetons de réflexion" tangibles. Cela correspond mieux à la cognition humaine ; l'article mentionne que "le cerveau maintient des chaînes de raisonnement logiques étendues avec une efficacité notable dans un espace latent, sans avoir besoin de convertir continuellement les pensées en langage".
Cependant, il est difficile de mettre en œuvre ce type de raisonnement interne profond dans l'IA. Le simple fait d'ajouter des couches à un modèle d'apprentissage profond déclenche fréquemment le problème du "gradient de disparition", où les signaux d'apprentissage s'estompent à travers les couches, ce qui entrave l'efficacité de l'entraînement. À l'inverse, les modèles récurrents qui itèrent à travers les calculs peuvent connaître une "convergence précoce", où le modèle se fixe prématurément sur une solution sans avoir examiné le problème en profondeur.
À la recherche d'une méthode supérieure, l'équipe de Sapient s'est tournée vers les neurosciences. "Le cerveau humain présente un modèle convaincant pour atteindre la profondeur de calcul qui manque aux systèmes artificiels actuels", affirment les chercheurs. "Il structure le calcul de manière hiérarchique à travers des zones corticales travaillant à différentes échelles de temps, ce qui permet une analyse profonde en plusieurs étapes.
Influencés par cette idée, ils ont créé la GRH avec deux modules interconnectés et récurrents : un module de haut niveau (H) pour l'élaboration lente et abstraite de stratégies, et un module de bas niveau (L) pour le traitement rapide et détaillé. Cette disposition facilite un mécanisme que l'équipe appelle "convergence hiérarchique". Essentiellement, le module L rapide s'attaque à un segment du problème et exécute plusieurs cycles jusqu'à ce qu'il trouve une réponse locale stable. Ensuite, le module H lent intègre ce résultat, affine son plan global et assigne au module L un nouveau sous-problème mieux défini. Le module L est ainsi redémarré, ce qui l'empêche de stagner (convergence précoce) et permet au système complet d'effectuer une série étendue d'étapes de raisonnement à l'aide d'une architecture rationalisée qui évite les gradients d'évanouissement.
Selon l'article, "ce mécanisme permet au MRH d'effectuer une succession de calculs distincts, réguliers et imbriqués, où le module H guide l'approche globale de résolution du problème et le module L effectue la recherche intensive ou le raffinement pour chaque phase". Cette architecture en boucle imbriquée permet au modèle d'effectuer des analyses approfondies dans son espace latent sans nécessiter d'invites CoT étendues ou d'ensembles de données massifs.
Une préoccupation logique est de savoir si ce "raisonnement latent" sacrifie l'interprétabilité. Guan Wang, fondateur et PDG de Sapient Intelligence, conteste cette notion, précisant que les opérations internes du modèle peuvent être interprétées et illustrées, de la même manière que CoT offre un aperçu de la cognition d'un modèle. Il note en outre que le CoT lui-même peut être peu fiable. "CoT ne représente pas avec précision le véritable raisonnement interne d'un modèle", a déclaré Wang à VentureBeat, citant des recherches indiquant que les modèles peuvent parfois produire des réponses correctes avec un raisonnement erroné, et l'inverse. "Il reste fondamentalement opaque.
La GRH à l'œuvre
Pour évaluer leur modèle, les chercheurs ont comparé la GRH à des repères exigeant des recherches intensives et des retours en arrière, tels que le Corpus d'abstraction et de raisonnement (ARC-AGI), des puzzles Sudoku très difficiles et des tâches complexes de navigation dans un labyrinthe.
Les résultats révèlent que la GRH apprend à résoudre des problèmes qui sont insolubles même pour des LLM sophistiqués. Par exemple, lors des tests "Sudoku-Extreme" et "Maze-Hard", les modèles CoT de haut niveau ont complètement échoué, enregistrant une précision de 0 %. En revanche, le modèle HRM a atteint une précision quasi parfaite après s'être entraîné sur seulement 1 000 exemples par tâche.
Sur le test de référence ARC-AGI, qui mesure le raisonnement abstrait et la généralisation, le modèle HRM à 27 paramètres a atteint une précision de 40,3 %. Il surpasse ainsi d'éminents modèles basés sur le CoT, tels que le modèle beaucoup plus grand o3-mini-high (34,5 %) et Claude 3.7 Sonnet (21,2 %). Cette performance, réalisée sans un vaste ensemble de données de pré-entraînement et avec un minimum de données, souligne la force et l'efficacité de sa conception.
Si la résolution d'énigmes met en évidence les capacités du modèle, son impact pratique est perceptible dans une autre catégorie de défis. Selon Wang, les développeurs devraient continuer à utiliser les LLM pour les tâches créatives ou centrées sur le langage, mais pour les "tâches complexes ou déterministes", un cadre de type HRM fournit des résultats supérieurs avec moins d'hallucinations. Il met l'accent sur les "problèmes séquentiels nécessitant une prise de décision complexe ou une planification à long terme", en particulier dans les domaines où le temps de latence est critique, comme l'IA incarnée et la robotique, ou dans les domaines où les données sont peu nombreuses, comme la recherche scientifique.
Dans ces situations, la GRH ne se contente pas de trouver des solutions, elle apprend à améliorer sa résolution de problèmes. "Dans nos tests de Sudoku de niveau maître [...] la GRH a besoin de moins d'étapes au fur et à mesure que la formation se poursuit, un peu comme un débutant qui se transforme en spécialiste", explique M. Wang.
Pour les entreprises, c'est là que l'efficacité de l'architecture influe sur la rentabilité. Plutôt que la production séquentielle, jeton par jeton, du CoT, le calcul parallèle de la MRH permet ce que M. Wang estime être une "accélération de 100 fois de la vitesse d'exécution des tâches". Il en résulte une réduction de la latence d'inférence et la capacité d'opérer des raisonnements avancés sur des appareils périphériques.
Les avantages financiers sont également considérables. "Les moteurs de raisonnement spécialisés comme la GRH représentent une option plus viable pour les tâches de raisonnement complexes particulières que les modèles pilotés par API, qui sont vastes, coûteux et à forte latence", a déclaré M. Wang. Pour illustrer cette efficacité, il a indiqué que l'entraînement du modèle pour le Sudoku professionnel nécessite environ deux heures de GPU, et pour le benchmark ARC-AGI exigeant, entre 50 et 200 heures de GPU, soit une part minime des ressources requises pour les énormes modèles de base. Cela permet d'aborder des questions commerciales spécialisées, de la planification logistique au dépannage de systèmes complexes, dans des contextes où les données et le financement sont limités.
Sapient Intelligence progresse déjà pour transformer la GRH d'un outil de résolution de problèmes de niche en un composant de raisonnement plus large et polyvalent. "Nous construisons activement des modèles inspirés par le cerveau et basés sur la MRH", a déclaré M. Wang, soulignant les premiers résultats encourageants obtenus dans les domaines de la santé, de la prévision climatique et de la robotique. Il a laissé entendre que ces futurs modèles seront sensiblement différents des systèmes actuels basés sur le texte, notamment grâce à l'intégration de fonctions d'autocorrection.
La recherche implique que pour un ensemble de problèmes qui ont déconcerté les leaders actuels de l'IA, la voie à suivre pourrait ne pas être celle de modèles plus grands, mais de cadres plus intelligents et mieux organisés, modelés sur le système de raisonnement le plus avancé : le cerveau humain.









 Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
L'IA physique fait son entrée dans les usines alors que des robots humanoïdes font l'objet d'essais
Selon Reuters, Humanoid, une entreprise technologique britannique, s'apprête à déployer des robots humanoïdes dans les usines du fournisseur industriel allemand Schaeffler.Selon un porte-parole d'Hum
Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
L'IA physique fait son entrée dans les usines alors que des robots humanoïdes font l'objet d'essais
Selon Reuters, Humanoid, une entreprise technologique britannique, s'apprête à déployer des robots humanoïdes dans les usines du fournisseur industriel allemand Schaeffler.Selon un porte-parole d'Hum

Découvrez les meilleurs outils d'auto-coloration IA pour mangas de 2026 sur XIX.AI. Notre sélection regroupe des solutions de premier plan qui changent la donne : elles appliquent des couleurs unies sans aucune erreur de cohérence, ce qui booste votre productivité. Consultez nos comparatifs entre versions gratuites et payantes, nos tests en conditions réelles et nos classements mis à jour chaque semaine pour trouver l'outil qui vous convient le mieux. Profitez dès aujourd'hui de l'avantage de l'IA.
10 outils
xix.ai

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai













