
















 首頁
首頁新人工智能模型以 100 倍的速度提升和最少的訓練資料超越 LLM
總部位於新加坡的人工智慧新創公司 Sapient Intelligence 已經設計出一套新穎的人工智慧架構,在複雜的推理挑戰上可媲美大型語言模型 (LLM),而且在某些情境下,還能大幅超越大型語言模型,儘管它所使用的模型規模小得多,所消耗的資料也少得多。
這個被命名為階層推理模型 (Hierarchical Reasoning Model, HRM)的系統,靈感來自於人腦對緩慢、有條理的規劃和快速、直覺的處理所採用的獨立機制。該模型僅使用現代 LLM 所需的一小部分資料和記憶體,就能達到顯著的成果。這樣的效率為企業級 AI 部署帶來了巨大的潛力,因為在企業級 AI 部署中,資料往往是有限的,而且計算能力也受到限制。
思維鏈推理的限制
當面對複雜的任務時,當代的 LLM 大多仰賴於思考鏈 (CoT) 提示,將問題分解為以文字為基礎的中間步驟,有效地強迫模型在尋找答案的過程中,口述其思考過程。
雖然 CoT 增強了 LLM 的推理能力,但它也有一些固有的弱點。在他們的研究論文中,Sapient Intelligence 團隊認為「CoT 只是推理的權宜之計,而非真正的解決方案。它依賴於僵化的、人為決定的分解,其中一個錯誤的步驟或錯誤的順序可能會完全擾亂整個流程"。
這種依賴於產生明確文字的方式,將模型的推理束縛在符記層面上,經常需要龐大的訓練資料集,導致回覆冗長、緩慢。這種方法也忽略了內部發生的「潛在推理」,這些推理並沒有直接用文字表達出來。
研究人員指出:「一種更精簡的方法對於減少這些密集的資料需求是非常重要的。
大腦啟發的層次架構
為了超越 CoT,研究團隊研究了「潛在推理」(latent reasoning),在這種推理中,模型使用其內部抽象的表徵來思考問題,而不是產生有形的「思考標記」(thinking tokens)。這更符合人類的認知;論文提到,「大腦在潛在空間中以顯著的效率維持延伸的邏輯推理鏈,而不需要不斷地將想法轉換回語言。
然而,在人工智能中實現這種深刻的內部推理非常困難。僅僅在深度學習模型中增加層級經常會引發「梯度消失」的問題,即學習信號在各層之間逐漸消失,妨礙了有效的訓練。相反地,迭代計算的循環設計可能會出現「早期收斂」的問題,也就是模型在沒有徹底檢視問題之前,就過早固定在某個解決方案上。
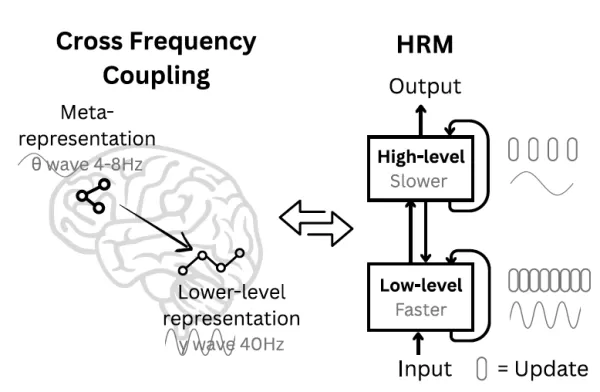
分層推理模型 (HRM) 的靈感來自於大腦結構 資料來源:arXiv 為了尋找更優越的方法,Sapient 團隊向神經科學尋求指引。"研究人員指出:「人腦提出了一個有說服力的模型,可以達到目前人工系統所缺乏的計算深度。"研究人員指出:「人腦的運算結構是分層式的,跨越以不同時間尺度運作的皮層區域,因此能夠進行深層次、多階段的分析。
受此影響,他們創建了 HRM,其中包含兩個相互連繫的循環模組:一個高層次 (H) 模組用於緩慢、抽象的策略制定,另一個低層次 (L) 模組用於快速、詳細的處理。這種安排促進了研究團隊稱為 「層級收斂 」的機制。基本上,快速的 L 模組會處理問題的某一區段,執行數個循環,直到找到穩定的局部答案為止。接著,慢速的 H 模組會整合這個結果、改進其總體計畫,並為 L 模組指派一個新的、定義更明確的子問題。這樣就有效地重新啟動了 L 模組,使其不再停滯不前(早期收斂),並使整個系統能夠使用避免漸層消失的精簡架構,執行一系列延伸的推理階段。
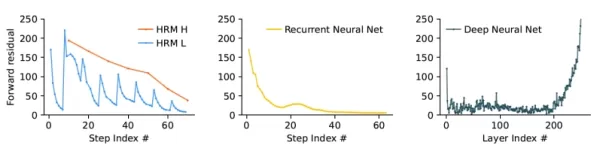
HRM (左) 在不同的計算週期都能順利收斂於解決方案,並避免提早收斂 (中,RNN) 與梯度消失 (右,經典深度神經網路) 資料來源:arXiv 根據這篇論文,「這種機制讓 HRM 能夠執行一連串獨立、穩定的嵌套計算,其中 H 模組引導全局問題解決方法,而 L 模組則執行每個階段的密集搜尋或精煉」。這種巢狀迴圈架構可讓模型在其潛在空間中進行深入分析,而不需要擴展的 CoT 提示或大量資料集。
一個合乎邏輯的顧慮是,這種「潛在推理」是否犧牲了可解釋性。Sapient Intelligence 創辦人兼執行長 Guan Wang 質疑這一觀點,他澄清說,模型的內部運作是可以詮釋和說明的,就像 CoT 提供模型認知的洞察力一樣。他進一步指出,CoT 本身可能不可靠。"CoT 並不能準確代表模型真正的內部推理,」Wang 告知 VentureBeat,並引用研究指出,模型偶爾會以錯誤的推理產生正確的答案,反之亦然。「它在根本上還是不透明的」。

HRM 如何跨不同計算週期推理迷宮問題的範例 資料來源:arXiv 工作中的 HRM
為了評估他們的模型,研究人員將 HRM 與需要密集搜尋與回溯的基準進行比較,例如抽象與推理資料庫(ARC-AGI)、高難度數獨謎題,以及複雜的迷宮導航任務。
研究結果顯示,HRM 學會解決即使是精密的 LLM 也無法解決的問題。例如,在「極限數獨」(Sudoku-Extreme)和「極限迷宮」(Maze-Hard)測試中,頂級 CoT 模型完全失敗,準確率僅為 0%。與此同時,HRM 在每個任務僅訓練 1,000 個範例之後,就達到了幾乎完美的準確度。
在衡量抽象推理和概括能力的 ARC-AGI 基準上,27M 參數的 HRM 達到了 40.3%。這比基於 CoT 的傑出模型,例如更大的 o3-mini-high (34.5%) 和 Claude 3.7 Sonnet (21.2%),還要優勝。這項成就是在沒有龐大的預先訓練資料集和使用最少資料的情況下實現的,強調了其設計的優勢和效率。
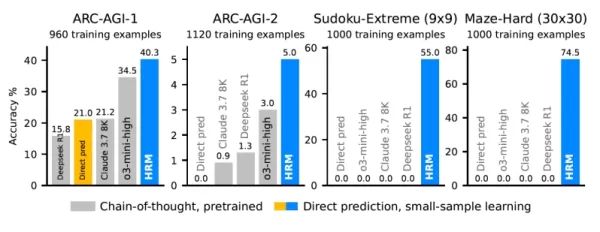
HRM 在複雜推理任務上的表現優於大型模型 資料來源:arXiv 雖然拼圖解決方案展示了模型的能力,但它的實際影響卻出現在不同類別的挑戰中。根據 Wang 的說法,開發人員應該繼續使用 LLM 來處理以語言為中心或具創意的任務,但是對於「複雜或決定性的任務」,HRM 風格的架構可以提供更優異的結果,同時減少幻覺。他強調「需要複雜決策或長期規劃的連續性問題」,尤其是在延遲關鍵領域,例如具體化人工智能與機器人,或是資料稀少的領域,例如科學研究。
在這些情況下,HRM 不僅能找到解決方案,還能學習改善其解決問題的能力。"在我們的大師級數獨測試中隨著訓練的持續,人力資源管理所需的步驟逐漸減少,就像初學者進化為專家一樣,"Wang 闡述道。
對於企業而言,這是架構的效率影響獲利能力的地方。HRM 的並行運算並非如 CoT 般依序、逐個令牌進行,而是讓 Wang 認為「任務完成速度加快了 100 倍」。這可減少推理延遲,並可在邊緣裝置上執行進階推理。
財務效益也相當可觀。"Wang 表示:「相較於大型、昂貴且高延遲的 API 驅動模型,HRM 等專門推理引擎為特定複雜的推理任務提供了更可行的選擇。為了說明效率,他提到專業數獨的模型訓練大約需要 2 個 GPU 小時,而對於要求嚴苛的 ARC-AGI 基準,則需要 50 到 200 個 GPU 小時,這在龐大的基礎模型所需的資源中所佔的比例微乎其微。這創造了一個機會,讓我們可以在資料和資金都受到限制的情況下,解決從物流規劃到複雜系統故障排除等專門的業務問題。
展望未來,Sapient Intelligence 已經開始將 HRM 從利基問題解決工具轉變為更廣泛的通用推理元件。"Wang 表示:「我們正積極建置以 HRM 為基礎的大腦啟發模型。他暗示,這些未來的模型將與目前以文字為基礎的系統大不相同,尤其是透過整合自我修正功能。
這項研究暗示,對於一系列困擾今日人工智慧領導者的問題,未來的出路可能不是更大型的模型,而是更智慧、更有組織的框架,並以最先進的推理系統人腦為藍本。
相關文章
 貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
Kakao Mobility 概述了針對實體人工智慧的第 4 級自動駕駛路線圖
Kakao Mobility 計畫內部開發第 4 級自動駕駛技術,作為其實體人工智慧策略的一環。在首爾COEX舉行的2026年世界資訊科技展(World IT Show)會議上,Kakao Mobility副總裁兼實體AI部門負責人金鎮奎(Kim Jin-kyu)發表了該發展藍圖。他的演講聚焦於實體AI時代以移動平台為核心的自動駕駛服務。據韓聯社報導,這場名為「超越構想,付諸行動:AI 推動現
隨著人形機器人展開試驗,實體人工智慧正逐步進軍工廠現場
據路透社報導,英國科技公司 Humanoid 即將在德國工業供應商舍弗勒(Schaeffler)旗下的工廠部署類人型機器人。Humanoid發言人表示,根據協議,預計到2032年將有1,000至2,000台機器人進駐舍弗勒的全球製造基地。合約金額尚未公開。首批機器人預計將於2026年12月至2027年6月期間,部署在舍弗勒位於德國的兩處廠區。 Humanoid執行長阿特姆·索科洛夫(Artem
相關專題推薦
圖像編輯
貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
Kakao Mobility 概述了針對實體人工智慧的第 4 級自動駕駛路線圖
Kakao Mobility 計畫內部開發第 4 級自動駕駛技術,作為其實體人工智慧策略的一環。在首爾COEX舉行的2026年世界資訊科技展(World IT Show)會議上,Kakao Mobility副總裁兼實體AI部門負責人金鎮奎(Kim Jin-kyu)發表了該發展藍圖。他的演講聚焦於實體AI時代以移動平台為核心的自動駕駛服務。據韓聯社報導,這場名為「超越構想,付諸行動:AI 推動現
隨著人形機器人展開試驗,實體人工智慧正逐步進軍工廠現場
據路透社報導,英國科技公司 Humanoid 即將在德國工業供應商舍弗勒(Schaeffler)旗下的工廠部署類人型機器人。Humanoid發言人表示,根據協議,預計到2032年將有1,000至2,000台機器人進駐舍弗勒的全球製造基地。合約金額尚未公開。首批機器人預計將於2026年12月至2027年6月期間,部署在舍弗勒位於德國的兩處廠區。 Humanoid執行長阿特姆·索科洛夫(Artem
相關專題推薦
圖像編輯
 用於短劇故事板的AI藝術生成工具:幻想與都市浪漫題材的角色設計
用於短劇故事板的AI藝術生成工具:幻想與都市浪漫題材的角色設計
2026最新推薦:探索最適合用於短劇故事板製作的AI藝術生成工具。我們精心挑選了眾多頂級工具,幫助您創作出引人入勝的幻想角色和都市浪漫角色。您可以對比免費與付費選項,檢視實際測試結果,從而找到最適合自己的創意工具。XIX.AI還會每週更新排名並提供專家分析,讓您立即開始將故事視覺化呈現吧!
 10 個工具
10 個工具
 xix.ai
寫作
最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
xix.ai
寫作
最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai
商業
最佳 AI 合約審查軟體:即時發現法律漏洞與合規風險
立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai
動畫創作
專為東華設計的AI動漫生成器:可用於建立網路小說角色及漫畫頭像
探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai
漫畫創作
漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

 評論 (0)
0/500
評論 (0)
0/500
總部位於新加坡的人工智慧新創公司 Sapient Intelligence 已經設計出一套新穎的人工智慧架構,在複雜的推理挑戰上可媲美大型語言模型 (LLM),而且在某些情境下,還能大幅超越大型語言模型,儘管它所使用的模型規模小得多,所消耗的資料也少得多。
這個被命名為階層推理模型 (Hierarchical Reasoning Model, HRM)的系統,靈感來自於人腦對緩慢、有條理的規劃和快速、直覺的處理所採用的獨立機制。該模型僅使用現代 LLM 所需的一小部分資料和記憶體,就能達到顯著的成果。這樣的效率為企業級 AI 部署帶來了巨大的潛力,因為在企業級 AI 部署中,資料往往是有限的,而且計算能力也受到限制。
思維鏈推理的限制
當面對複雜的任務時,當代的 LLM 大多仰賴於思考鏈 (CoT) 提示,將問題分解為以文字為基礎的中間步驟,有效地強迫模型在尋找答案的過程中,口述其思考過程。
雖然 CoT 增強了 LLM 的推理能力,但它也有一些固有的弱點。在他們的研究論文中,Sapient Intelligence 團隊認為「CoT 只是推理的權宜之計,而非真正的解決方案。它依賴於僵化的、人為決定的分解,其中一個錯誤的步驟或錯誤的順序可能會完全擾亂整個流程"。
這種依賴於產生明確文字的方式,將模型的推理束縛在符記層面上,經常需要龐大的訓練資料集,導致回覆冗長、緩慢。這種方法也忽略了內部發生的「潛在推理」,這些推理並沒有直接用文字表達出來。
研究人員指出:「一種更精簡的方法對於減少這些密集的資料需求是非常重要的。
大腦啟發的層次架構
為了超越 CoT,研究團隊研究了「潛在推理」(latent reasoning),在這種推理中,模型使用其內部抽象的表徵來思考問題,而不是產生有形的「思考標記」(thinking tokens)。這更符合人類的認知;論文提到,「大腦在潛在空間中以顯著的效率維持延伸的邏輯推理鏈,而不需要不斷地將想法轉換回語言。
然而,在人工智能中實現這種深刻的內部推理非常困難。僅僅在深度學習模型中增加層級經常會引發「梯度消失」的問題,即學習信號在各層之間逐漸消失,妨礙了有效的訓練。相反地,迭代計算的循環設計可能會出現「早期收斂」的問題,也就是模型在沒有徹底檢視問題之前,就過早固定在某個解決方案上。
為了尋找更優越的方法,Sapient 團隊向神經科學尋求指引。"研究人員指出:「人腦提出了一個有說服力的模型,可以達到目前人工系統所缺乏的計算深度。"研究人員指出:「人腦的運算結構是分層式的,跨越以不同時間尺度運作的皮層區域,因此能夠進行深層次、多階段的分析。
受此影響,他們創建了 HRM,其中包含兩個相互連繫的循環模組:一個高層次 (H) 模組用於緩慢、抽象的策略制定,另一個低層次 (L) 模組用於快速、詳細的處理。這種安排促進了研究團隊稱為 「層級收斂 」的機制。基本上,快速的 L 模組會處理問題的某一區段,執行數個循環,直到找到穩定的局部答案為止。接著,慢速的 H 模組會整合這個結果、改進其總體計畫,並為 L 模組指派一個新的、定義更明確的子問題。這樣就有效地重新啟動了 L 模組,使其不再停滯不前(早期收斂),並使整個系統能夠使用避免漸層消失的精簡架構,執行一系列延伸的推理階段。
根據這篇論文,「這種機制讓 HRM 能夠執行一連串獨立、穩定的嵌套計算,其中 H 模組引導全局問題解決方法,而 L 模組則執行每個階段的密集搜尋或精煉」。這種巢狀迴圈架構可讓模型在其潛在空間中進行深入分析,而不需要擴展的 CoT 提示或大量資料集。
一個合乎邏輯的顧慮是,這種「潛在推理」是否犧牲了可解釋性。Sapient Intelligence 創辦人兼執行長 Guan Wang 質疑這一觀點,他澄清說,模型的內部運作是可以詮釋和說明的,就像 CoT 提供模型認知的洞察力一樣。他進一步指出,CoT 本身可能不可靠。"CoT 並不能準確代表模型真正的內部推理,」Wang 告知 VentureBeat,並引用研究指出,模型偶爾會以錯誤的推理產生正確的答案,反之亦然。「它在根本上還是不透明的」。
工作中的 HRM
為了評估他們的模型,研究人員將 HRM 與需要密集搜尋與回溯的基準進行比較,例如抽象與推理資料庫(ARC-AGI)、高難度數獨謎題,以及複雜的迷宮導航任務。
研究結果顯示,HRM 學會解決即使是精密的 LLM 也無法解決的問題。例如,在「極限數獨」(Sudoku-Extreme)和「極限迷宮」(Maze-Hard)測試中,頂級 CoT 模型完全失敗,準確率僅為 0%。與此同時,HRM 在每個任務僅訓練 1,000 個範例之後,就達到了幾乎完美的準確度。
在衡量抽象推理和概括能力的 ARC-AGI 基準上,27M 參數的 HRM 達到了 40.3%。這比基於 CoT 的傑出模型,例如更大的 o3-mini-high (34.5%) 和 Claude 3.7 Sonnet (21.2%),還要優勝。這項成就是在沒有龐大的預先訓練資料集和使用最少資料的情況下實現的,強調了其設計的優勢和效率。
雖然拼圖解決方案展示了模型的能力,但它的實際影響卻出現在不同類別的挑戰中。根據 Wang 的說法,開發人員應該繼續使用 LLM 來處理以語言為中心或具創意的任務,但是對於「複雜或決定性的任務」,HRM 風格的架構可以提供更優異的結果,同時減少幻覺。他強調「需要複雜決策或長期規劃的連續性問題」,尤其是在延遲關鍵領域,例如具體化人工智能與機器人,或是資料稀少的領域,例如科學研究。
在這些情況下,HRM 不僅能找到解決方案,還能學習改善其解決問題的能力。"在我們的大師級數獨測試中隨著訓練的持續,人力資源管理所需的步驟逐漸減少,就像初學者進化為專家一樣,"Wang 闡述道。
對於企業而言,這是架構的效率影響獲利能力的地方。HRM 的並行運算並非如 CoT 般依序、逐個令牌進行,而是讓 Wang 認為「任務完成速度加快了 100 倍」。這可減少推理延遲,並可在邊緣裝置上執行進階推理。
財務效益也相當可觀。"Wang 表示:「相較於大型、昂貴且高延遲的 API 驅動模型,HRM 等專門推理引擎為特定複雜的推理任務提供了更可行的選擇。為了說明效率,他提到專業數獨的模型訓練大約需要 2 個 GPU 小時,而對於要求嚴苛的 ARC-AGI 基準,則需要 50 到 200 個 GPU 小時,這在龐大的基礎模型所需的資源中所佔的比例微乎其微。這創造了一個機會,讓我們可以在資料和資金都受到限制的情況下,解決從物流規劃到複雜系統故障排除等專門的業務問題。
展望未來,Sapient Intelligence 已經開始將 HRM 從利基問題解決工具轉變為更廣泛的通用推理元件。"Wang 表示:「我們正積極建置以 HRM 為基礎的大腦啟發模型。他暗示,這些未來的模型將與目前以文字為基礎的系統大不相同,尤其是透過整合自我修正功能。
這項研究暗示,對於一系列困擾今日人工智慧領導者的問題,未來的出路可能不是更大型的模型,而是更智慧、更有組織的框架,並以最先進的推理系統人腦為藍本。









 貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
Kakao Mobility 概述了針對實體人工智慧的第 4 級自動駕駛路線圖
Kakao Mobility 計畫內部開發第 4 級自動駕駛技術,作為其實體人工智慧策略的一環。在首爾COEX舉行的2026年世界資訊科技展(World IT Show)會議上,Kakao Mobility副總裁兼實體AI部門負責人金鎮奎(Kim Jin-kyu)發表了該發展藍圖。他的演講聚焦於實體AI時代以移動平台為核心的自動駕駛服務。據韓聯社報導,這場名為「超越構想,付諸行動:AI 推動現
隨著人形機器人展開試驗,實體人工智慧正逐步進軍工廠現場
據路透社報導,英國科技公司 Humanoid 即將在德國工業供應商舍弗勒(Schaeffler)旗下的工廠部署類人型機器人。Humanoid發言人表示,根據協議,預計到2032年將有1,000至2,000台機器人進駐舍弗勒的全球製造基地。合約金額尚未公開。首批機器人預計將於2026年12月至2027年6月期間,部署在舍弗勒位於德國的兩處廠區。 Humanoid執行長阿特姆·索科洛夫(Artem
貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
Kakao Mobility 概述了針對實體人工智慧的第 4 級自動駕駛路線圖
Kakao Mobility 計畫內部開發第 4 級自動駕駛技術,作為其實體人工智慧策略的一環。在首爾COEX舉行的2026年世界資訊科技展(World IT Show)會議上,Kakao Mobility副總裁兼實體AI部門負責人金鎮奎(Kim Jin-kyu)發表了該發展藍圖。他的演講聚焦於實體AI時代以移動平台為核心的自動駕駛服務。據韓聯社報導,這場名為「超越構想,付諸行動:AI 推動現
隨著人形機器人展開試驗,實體人工智慧正逐步進軍工廠現場
據路透社報導,英國科技公司 Humanoid 即將在德國工業供應商舍弗勒(Schaeffler)旗下的工廠部署類人型機器人。Humanoid發言人表示,根據協議,預計到2032年將有1,000至2,000台機器人進駐舍弗勒的全球製造基地。合約金額尚未公開。首批機器人預計將於2026年12月至2027年6月期間,部署在舍弗勒位於德國的兩處廠區。 Humanoid執行長阿特姆·索科洛夫(Artem

2026最新推薦:探索最適合用於短劇故事板製作的AI藝術生成工具。我們精心挑選了眾多頂級工具,幫助您創作出引人入勝的幻想角色和都市浪漫角色。您可以對比免費與付費選項,檢視實際測試結果,從而找到最適合自己的創意工具。XIX.AI還會每週更新排名並提供專家分析,讓您立即開始將故事視覺化呈現吧!
10 個工具
xix.ai

在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai

探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai













