
















 Hogar
Hogar
Un nuevo modelo de IA supera a los LLM con una velocidad 100 veces superior y datos de entrenamiento mínimos
La empresa de IA Sapient Intelligence, con sede en Singapur, ha diseñado una novedosa arquitectura de IA que puede rivalizar -y, en algunos casos, superar con creces- a los grandes modelos lingüísticos (LLM) en tareas de razonamiento complejas, a pesar de utilizar un modelo mucho más pequeño y consumir muchos menos datos.
Este sistema, denominado Modelo de Razonamiento Jerárquico (MRH), se inspira en el uso que hace el cerebro humano de mecanismos separados para la planificación lenta y metódica y el procesamiento rápido e intuitivo. El modelo ofrece resultados notables utilizando sólo una fracción de los datos y la memoria que exigen los LLM modernos. Esta eficiencia encierra un gran potencial para las implantaciones de IA en las empresas, donde los datos suelen ser limitados y la potencia de cálculo es una restricción.
Las limitaciones del razonamiento en cadena
Cuando se enfrentan a una tarea compleja, los LLM contemporáneos dependen principalmente de la cadena de pensamiento (CoT), en la que los problemas se dividen en pasos intermedios basados en texto, obligando al modelo a verbalizar su proceso de pensamiento a medida que avanza hacia una respuesta.
Aunque el CoT ha mejorado las capacidades de razonamiento de los LLM, adolece de debilidades inherentes. En su artículo de investigación, el equipo de Sapient Intelligence afirma que "CoT es un mero parche para el razonamiento, no una verdadera solución. Depende de desgloses rígidos, determinados por el ser humano, en los que un paso equivocado o una secuencia desordenada pueden hacer descarrilar por completo todo el proceso".
Esta dependencia de la generación de texto explícito ata el razonamiento del modelo al nivel de los tokens, exigiendo con frecuencia enormes conjuntos de datos de entrenamiento y dando lugar a respuestas largas y lentas. Este método también pasa por alto el tipo de "razonamiento latente" que se produce internamente, sin expresarse directamente en palabras.
Los investigadores observan: "Es esencial un método más racionalizado para reducir estas necesidades intensivas de datos".
Un marco jerárquico inspirado en el cerebro
Para avanzar más allá del CoT, el equipo investigó el "razonamiento latente", en el que el modelo piensa a través de problemas utilizando sus representaciones internas y abstractas en lugar de producir "fichas de pensamiento" tangibles. Esto se ajusta más a la cognición humana; el artículo menciona que "el cerebro mantiene cadenas de razonamiento lógico extendidas con notable eficiencia en un espacio latente, sin necesidad de convertir continuamente los pensamientos de nuevo en lenguaje".
Sin embargo, implementar este tipo de razonamiento interno y profundo en la IA es difícil. La mera adición de capas a un modelo de aprendizaje profundo suele desencadenar el problema del "gradiente evanescente", en el que las señales de aprendizaje se desvanecen a través de las capas, lo que dificulta un entrenamiento eficaz. A la inversa, los diseños recurrentes que iteran a través de cálculos pueden experimentar una "convergencia temprana", en la que el modelo se fija en una solución prematuramente sin examinar a fondo el problema.
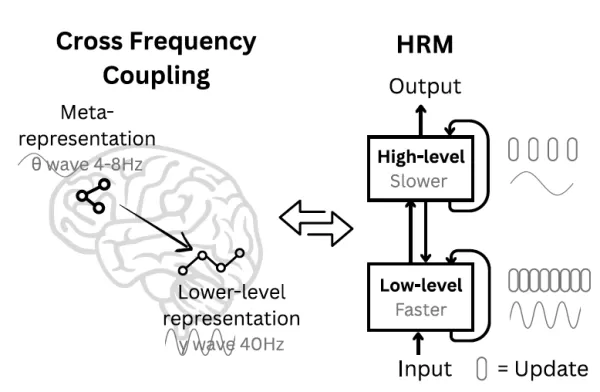
El Modelo de Razonamiento Jerárquico (MRH) se inspira en la estructura del cerebro Fuente: arXiv En busca de un método superior, el equipo de Sapient buscó orientación en la neurociencia. "El cerebro humano presenta un modelo convincente para alcanzar la profundidad computacional que les falta a los sistemas artificiales actuales", afirman los investigadores. "Estructura el cálculo jerárquicamente a través de áreas corticales que trabajan a distintas escalas de tiempo, lo que permite un análisis profundo y multietapa".
Influidos por esto, crearon HRM con dos módulos interconectados y recurrentes: un módulo de alto nivel (H) para la elaboración de estrategias lentas y abstractas, y un módulo de bajo nivel (L) para el procesamiento rápido y detallado. Esta disposición facilita un mecanismo que el equipo denomina "convergencia jerárquica". Esencialmente, el módulo L rápido aborda un segmento del problema, ejecutando varios ciclos hasta que encuentra una respuesta local estable. Entonces, el módulo H lento incorpora este resultado, refina su plan general y asigna al módulo L un nuevo subproblema mejor definido. De este modo, se reinicia el módulo L, impidiendo que se estanque (convergencia temprana) y permitiendo que el sistema completo lleve a cabo una serie ampliada de etapas de razonamiento utilizando una arquitectura racionalizada que evita los gradientes de fuga.
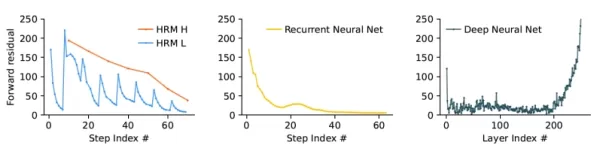
HRM (izquierda) converge suavemente en la solución a través de ciclos de cálculo y evita la convergencia temprana (centro, RNNs) y los gradientes de fuga (derecha, redes neuronales profundas clásicas) Fuente: arXiv Según el artículo, "este mecanismo permite a la HRM realizar una sucesión de cálculos separados, constantes y anidados, en los que el módulo H guía el enfoque global de resolución del problema y el módulo L lleva a cabo la búsqueda intensiva o el refinamiento de cada fase". Esta arquitectura de bucle anidado permite al modelo llevar a cabo análisis profundos en su espacio latente sin requerir indicaciones ampliadas de CoT ni conjuntos de datos masivos.
Una preocupación lógica es si este "razonamiento latente" sacrifica la interpretabilidad. Guan Wang, fundador y consejero delegado de Sapient Intelligence, cuestiona esta idea y aclara que las operaciones internas del modelo pueden interpretarse e ilustrarse, del mismo modo que CoT ofrece una visión de la cognición de un modelo. Señala además que el propio CoT puede ser poco fiable. "CoT no representa con exactitud el verdadero razonamiento interno de un modelo", explica Wang a VentureBeat, citando estudios que indican que los modelos pueden dar en ocasiones respuestas correctas con un razonamiento erróneo, y lo contrario. "Sigue siendo fundamentalmente opaco".

Ejemplo de cómo HRM razona un problema de laberinto en distintos ciclos de cálculo Fuente: arXiv HRM en acción
Para evaluar su modelo, los investigadores compararon el HRM con pruebas de referencia que exigían una búsqueda y un seguimiento intensivos, como el Corpus de Abstracción y Razonamiento (ARC-AGI), rompecabezas Sudoku de gran dificultad y complejas tareas de navegación por laberintos.
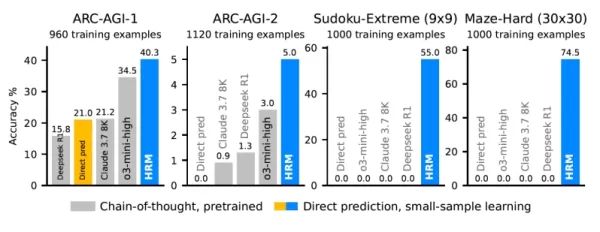
Los resultados revelan que HRM aprende a resolver problemas irresolubles incluso para los LLM más sofisticados. Por ejemplo, en las pruebas "Sudoku-Extreme" y "Maze-Hard", los modelos CoT de primer nivel fracasaron por completo, registrando un 0% de precisión. Mientras tanto, HRM alcanzó una precisión casi perfecta tras entrenarse con sólo 1.000 ejemplos por tarea.
En la prueba ARC-AGI, que mide el razonamiento abstracto y la generalización, el HRM de 27 parámetros obtuvo un 40,3%. Supera así a otros modelos basados en CoT, como el mucho mayor o3-mini-high (34,5%) y Claude 3.7 Sonnet (21,2%). Este logro, realizado sin un amplio conjunto de datos de preentrenamiento y con datos mínimos, subraya la solidez y eficacia de su diseño.
HRM supera a los grandes modelos en tareas de razonamiento complejas Fuente: arXiv Mientras que la resolución de puzles muestra la capacidad del modelo, su impacto práctico se aprecia en una categoría diferente de retos. Según Wang, los desarrolladores deberían seguir utilizando LLM para tareas centradas en el lenguaje o creativas, pero para "tareas complejas o deterministas", un marco al estilo de HRM proporciona resultados superiores con menos alucinaciones. Destaca los "problemas secuenciales que requieren una intrincada toma de decisiones o una planificación a largo plazo", sobre todo en áreas en las que la latencia es crítica, como la IA encarnada y la robótica, o en dominios con datos escasos, como la investigación científica.
En estas situaciones, HRM no se limita a encontrar soluciones, sino que aprende a mejorar la resolución de problemas. "En nuestras pruebas de Sudoku de nivel maestro... La gestión de recursos humanos requiere cada vez menos pasos a medida que avanza el entrenamiento, como si un principiante se convirtiera en especialista", explica Wang.
Para las empresas, aquí es donde la eficacia de la arquitectura repercute en la rentabilidad. En lugar de la producción secuencial, ficha a ficha, de CoT, el cálculo paralelo de HRM permite lo que Wang aproxima como una "aceleración de 100 veces en la velocidad de finalización de tareas". Esto se traduce en una latencia de inferencia reducida y en la capacidad de operar razonamientos avanzados en dispositivos periféricos.
Las ventajas económicas también son considerables. "Los motores de razonamiento especializados como HRM presentan una opción más viable para determinadas tareas de razonamiento complejas en comparación con los modelos grandes, caros y de alta latencia basados en API", declaró Wang. Para ilustrar la eficiencia, mencionó que el entrenamiento del modelo para el Sudoku profesional requiere unas dos horas de GPU y, para el exigente benchmark ARC-AGI, entre 50 y 200 horas de GPU, una mínima parte de los recursos necesarios para los enormes modelos de fundamentos. Esto brinda la oportunidad de abordar cuestiones empresariales especializadas, desde la planificación logística hasta la resolución de complicados problemas de sistemas, en contextos en los que tanto los datos como la financiación son limitados.
De cara al futuro, Sapient Intelligence ya está avanzando para transformar la GRH de una herramienta especializada de resolución de problemas en un componente de razonamiento más amplio y de uso general. "Estamos construyendo activamente modelos inspirados en el cerebro basados en la GRH", afirma Wang, señalando los alentadores resultados iniciales en asistencia sanitaria, predicción climática y robótica. Insinuó que estos futuros modelos serán sustancialmente distintos de los actuales sistemas basados en texto, sobre todo gracias a la integración de funciones de autocorrección.
La investigación implica que para una serie de problemas que han confundido a los líderes actuales de la IA, el camino a seguir podría no ser modelos más grandes, sino marcos más inteligentes y mejor organizados, modelados a partir del sistema de razonamiento más avanzado: el cerebro humano.
Artículo relacionado
 Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
La IA física se acerca cada vez más a las plantas de producción a medida que se realizan pruebas con robots humanoides
Según Reuters, Humanoid, una empresa tecnológica británica, tiene previsto instalar robots humanoides en las fábricas del proveedor industrial alemán Schaeffler.Según un portavoz de Humanoid, se espe
Recomendaciones de temas especiales relacionados
Creación de cómics
Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
La IA física se acerca cada vez más a las plantas de producción a medida que se realizan pruebas con robots humanoides
Según Reuters, Humanoid, una empresa tecnológica británica, tiene previsto instalar robots humanoides en las fábricas del proveedor industrial alemán Schaeffler.Según un portavoz de Humanoid, se espe
Recomendaciones de temas especiales relacionados
Creación de cómics
 Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Las mejores herramientas de coloración automática con IA para manga: aplica colores planos sin ningún error de coherencia
Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
 10 herramientas
10 herramientas
 xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
xix.ai
escribiendo
Los mejores creadores de perfiles de ficción con IA: cómo generar motivaciones y defectos fatales coherentes para los personajes
Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai
Negocio
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai
Texto a voz
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
La empresa de IA Sapient Intelligence, con sede en Singapur, ha diseñado una novedosa arquitectura de IA que puede rivalizar -y, en algunos casos, superar con creces- a los grandes modelos lingüísticos (LLM) en tareas de razonamiento complejas, a pesar de utilizar un modelo mucho más pequeño y consumir muchos menos datos.
Este sistema, denominado Modelo de Razonamiento Jerárquico (MRH), se inspira en el uso que hace el cerebro humano de mecanismos separados para la planificación lenta y metódica y el procesamiento rápido e intuitivo. El modelo ofrece resultados notables utilizando sólo una fracción de los datos y la memoria que exigen los LLM modernos. Esta eficiencia encierra un gran potencial para las implantaciones de IA en las empresas, donde los datos suelen ser limitados y la potencia de cálculo es una restricción.
Las limitaciones del razonamiento en cadena
Cuando se enfrentan a una tarea compleja, los LLM contemporáneos dependen principalmente de la cadena de pensamiento (CoT), en la que los problemas se dividen en pasos intermedios basados en texto, obligando al modelo a verbalizar su proceso de pensamiento a medida que avanza hacia una respuesta.
Aunque el CoT ha mejorado las capacidades de razonamiento de los LLM, adolece de debilidades inherentes. En su artículo de investigación, el equipo de Sapient Intelligence afirma que "CoT es un mero parche para el razonamiento, no una verdadera solución. Depende de desgloses rígidos, determinados por el ser humano, en los que un paso equivocado o una secuencia desordenada pueden hacer descarrilar por completo todo el proceso".
Esta dependencia de la generación de texto explícito ata el razonamiento del modelo al nivel de los tokens, exigiendo con frecuencia enormes conjuntos de datos de entrenamiento y dando lugar a respuestas largas y lentas. Este método también pasa por alto el tipo de "razonamiento latente" que se produce internamente, sin expresarse directamente en palabras.
Los investigadores observan: "Es esencial un método más racionalizado para reducir estas necesidades intensivas de datos".
Un marco jerárquico inspirado en el cerebro
Para avanzar más allá del CoT, el equipo investigó el "razonamiento latente", en el que el modelo piensa a través de problemas utilizando sus representaciones internas y abstractas en lugar de producir "fichas de pensamiento" tangibles. Esto se ajusta más a la cognición humana; el artículo menciona que "el cerebro mantiene cadenas de razonamiento lógico extendidas con notable eficiencia en un espacio latente, sin necesidad de convertir continuamente los pensamientos de nuevo en lenguaje".
Sin embargo, implementar este tipo de razonamiento interno y profundo en la IA es difícil. La mera adición de capas a un modelo de aprendizaje profundo suele desencadenar el problema del "gradiente evanescente", en el que las señales de aprendizaje se desvanecen a través de las capas, lo que dificulta un entrenamiento eficaz. A la inversa, los diseños recurrentes que iteran a través de cálculos pueden experimentar una "convergencia temprana", en la que el modelo se fija en una solución prematuramente sin examinar a fondo el problema.
En busca de un método superior, el equipo de Sapient buscó orientación en la neurociencia. "El cerebro humano presenta un modelo convincente para alcanzar la profundidad computacional que les falta a los sistemas artificiales actuales", afirman los investigadores. "Estructura el cálculo jerárquicamente a través de áreas corticales que trabajan a distintas escalas de tiempo, lo que permite un análisis profundo y multietapa".
Influidos por esto, crearon HRM con dos módulos interconectados y recurrentes: un módulo de alto nivel (H) para la elaboración de estrategias lentas y abstractas, y un módulo de bajo nivel (L) para el procesamiento rápido y detallado. Esta disposición facilita un mecanismo que el equipo denomina "convergencia jerárquica". Esencialmente, el módulo L rápido aborda un segmento del problema, ejecutando varios ciclos hasta que encuentra una respuesta local estable. Entonces, el módulo H lento incorpora este resultado, refina su plan general y asigna al módulo L un nuevo subproblema mejor definido. De este modo, se reinicia el módulo L, impidiendo que se estanque (convergencia temprana) y permitiendo que el sistema completo lleve a cabo una serie ampliada de etapas de razonamiento utilizando una arquitectura racionalizada que evita los gradientes de fuga.
Según el artículo, "este mecanismo permite a la HRM realizar una sucesión de cálculos separados, constantes y anidados, en los que el módulo H guía el enfoque global de resolución del problema y el módulo L lleva a cabo la búsqueda intensiva o el refinamiento de cada fase". Esta arquitectura de bucle anidado permite al modelo llevar a cabo análisis profundos en su espacio latente sin requerir indicaciones ampliadas de CoT ni conjuntos de datos masivos.
Una preocupación lógica es si este "razonamiento latente" sacrifica la interpretabilidad. Guan Wang, fundador y consejero delegado de Sapient Intelligence, cuestiona esta idea y aclara que las operaciones internas del modelo pueden interpretarse e ilustrarse, del mismo modo que CoT ofrece una visión de la cognición de un modelo. Señala además que el propio CoT puede ser poco fiable. "CoT no representa con exactitud el verdadero razonamiento interno de un modelo", explica Wang a VentureBeat, citando estudios que indican que los modelos pueden dar en ocasiones respuestas correctas con un razonamiento erróneo, y lo contrario. "Sigue siendo fundamentalmente opaco".
HRM en acción
Para evaluar su modelo, los investigadores compararon el HRM con pruebas de referencia que exigían una búsqueda y un seguimiento intensivos, como el Corpus de Abstracción y Razonamiento (ARC-AGI), rompecabezas Sudoku de gran dificultad y complejas tareas de navegación por laberintos.
Los resultados revelan que HRM aprende a resolver problemas irresolubles incluso para los LLM más sofisticados. Por ejemplo, en las pruebas "Sudoku-Extreme" y "Maze-Hard", los modelos CoT de primer nivel fracasaron por completo, registrando un 0% de precisión. Mientras tanto, HRM alcanzó una precisión casi perfecta tras entrenarse con sólo 1.000 ejemplos por tarea.
En la prueba ARC-AGI, que mide el razonamiento abstracto y la generalización, el HRM de 27 parámetros obtuvo un 40,3%. Supera así a otros modelos basados en CoT, como el mucho mayor o3-mini-high (34,5%) y Claude 3.7 Sonnet (21,2%). Este logro, realizado sin un amplio conjunto de datos de preentrenamiento y con datos mínimos, subraya la solidez y eficacia de su diseño.
Mientras que la resolución de puzles muestra la capacidad del modelo, su impacto práctico se aprecia en una categoría diferente de retos. Según Wang, los desarrolladores deberían seguir utilizando LLM para tareas centradas en el lenguaje o creativas, pero para "tareas complejas o deterministas", un marco al estilo de HRM proporciona resultados superiores con menos alucinaciones. Destaca los "problemas secuenciales que requieren una intrincada toma de decisiones o una planificación a largo plazo", sobre todo en áreas en las que la latencia es crítica, como la IA encarnada y la robótica, o en dominios con datos escasos, como la investigación científica.
En estas situaciones, HRM no se limita a encontrar soluciones, sino que aprende a mejorar la resolución de problemas. "En nuestras pruebas de Sudoku de nivel maestro... La gestión de recursos humanos requiere cada vez menos pasos a medida que avanza el entrenamiento, como si un principiante se convirtiera en especialista", explica Wang.
Para las empresas, aquí es donde la eficacia de la arquitectura repercute en la rentabilidad. En lugar de la producción secuencial, ficha a ficha, de CoT, el cálculo paralelo de HRM permite lo que Wang aproxima como una "aceleración de 100 veces en la velocidad de finalización de tareas". Esto se traduce en una latencia de inferencia reducida y en la capacidad de operar razonamientos avanzados en dispositivos periféricos.
Las ventajas económicas también son considerables. "Los motores de razonamiento especializados como HRM presentan una opción más viable para determinadas tareas de razonamiento complejas en comparación con los modelos grandes, caros y de alta latencia basados en API", declaró Wang. Para ilustrar la eficiencia, mencionó que el entrenamiento del modelo para el Sudoku profesional requiere unas dos horas de GPU y, para el exigente benchmark ARC-AGI, entre 50 y 200 horas de GPU, una mínima parte de los recursos necesarios para los enormes modelos de fundamentos. Esto brinda la oportunidad de abordar cuestiones empresariales especializadas, desde la planificación logística hasta la resolución de complicados problemas de sistemas, en contextos en los que tanto los datos como la financiación son limitados.
De cara al futuro, Sapient Intelligence ya está avanzando para transformar la GRH de una herramienta especializada de resolución de problemas en un componente de razonamiento más amplio y de uso general. "Estamos construyendo activamente modelos inspirados en el cerebro basados en la GRH", afirma Wang, señalando los alentadores resultados iniciales en asistencia sanitaria, predicción climática y robótica. Insinuó que estos futuros modelos serán sustancialmente distintos de los actuales sistemas basados en texto, sobre todo gracias a la integración de funciones de autocorrección.
La investigación implica que para una serie de problemas que han confundido a los líderes actuales de la IA, el camino a seguir podría no ser modelos más grandes, sino marcos más inteligentes y mejor organizados, modelados a partir del sistema de razonamiento más avanzado: el cerebro humano.









 Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
La IA física se acerca cada vez más a las plantas de producción a medida que se realizan pruebas con robots humanoides
Según Reuters, Humanoid, una empresa tecnológica británica, tiene previsto instalar robots humanoides en las fábricas del proveedor industrial alemán Schaeffler.Según un portavoz de Humanoid, se espe
Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
Kakao Mobility presenta su hoja de ruta para la conducción autónoma de nivel 4 basada en la IA física
Kakao Mobility tiene previsto desarrollar internamente tecnologías de conducción autónoma de nivel 4 como parte de su estrategia de IA física.En la conferencia World IT Show 2026, celebrada en el COE
La IA física se acerca cada vez más a las plantas de producción a medida que se realizan pruebas con robots humanoides
Según Reuters, Humanoid, una empresa tecnológica británica, tiene previsto instalar robots humanoides en las fábricas del proveedor industrial alemán Schaeffler.Según un portavoz de Humanoid, se espe

Descubre las mejores herramientas de coloración automática con IA para manga de 2026 en XIX.AI. Nuestra lista seleccionada incluye soluciones revolucionarias y mejor valoradas que aplican colores planos sin ningún error de consistencia, lo que potencia tu productividad. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones actualizadas semanalmente para encontrar la opción perfecta para ti. Aprovecha hoy mismo las ventajas de la IA.
10 herramientas
xix.ai

Descubre los mejores creadores de perfiles de ficción con IA de 2026 para dar vida a personajes profundos. La selección de XIX.AI incluye herramientas de primera categoría y revolucionarias que generan motivaciones coherentes y defectos fatales. Compara las opciones gratuitas con las de pago mediante pruebas en el mundo real. Libera ahora tu potencial narrativo.
10 herramientas
xix.ai

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai













