
















 Дом
Дом
Новая модель искусственного интеллекта превосходит LLM с 100-кратным увеличением скорости и минимальным количеством обучающих данных
Сингапурская компания Sapient Intelligence разработала новую архитектуру искусственного интеллекта, которая может конкурировать с большими языковыми моделями (LLM) в сложных задачах рассуждения, а в некоторых сценариях и значительно превосходить их, несмотря на гораздо меньший размер модели и потребление гораздо меньшего количества данных.
Эта система, получившая название Hierarchical Reasoning Model (HRM), черпает вдохновение в использовании человеческим мозгом отдельных механизмов для медленного, методичного планирования и быстрой, интуитивной обработки. Модель позволяет добиться замечательных результатов, используя лишь малую часть данных и памяти, требуемых современными LLM. Такая эффективность открывает широкие возможности для развертывания корпоративного ИИ, где данные часто ограничены, а вычислительная мощность - нехватка.
Ограничения цепных рассуждений
При решении сложных задач современные LLM в основном полагаются на подсказки в виде цепочки мыслей (CoT), когда проблемы разбиваются на промежуточные текстовые шаги, что, по сути, заставляет модель вербализовать свой мыслительный процесс по мере продвижения к ответу.
Хотя CoT расширила возможности рассуждений LLM, она страдает от присущих ей недостатков. В своем исследовании команда Sapient Intelligence утверждает, что "CoT - это всего лишь временная мера для рассуждений, а не настоящее решение. Он зависит от жестких, определяемых человеком сбоев, когда один неверный шаг или неправильно выстроенная последовательность действий могут полностью сорвать весь процесс".
Такая зависимость от генерации явного текста привязывает рассуждения модели к уровню токенов, что часто требует огромных наборов обучающих данных и приводит к длительным и медленным ответам. Этот метод также не учитывает "скрытые рассуждения", которые происходят внутри системы, не будучи выраженными непосредственно в словах.
Исследователи отмечают: "Для снижения интенсивности использования данных необходим более рациональный метод".
Иерархическая структура, вдохновленная мозгом
Чтобы выйти за рамки CoT, команда исследовала "скрытые рассуждения", когда модель решает проблемы, используя свои внутренние, абстрактные представления, а не создает осязаемые "мыслительные маркеры". Это более близко к человеческому познанию; в статье упоминается, что "мозг поддерживает расширенные логические цепочки рассуждений с заметной эффективностью в латентном пространстве, не нуждаясь в постоянном преобразовании мыслей обратно в язык".
Однако реализовать подобную глубокую внутреннюю логику в ИИ довольно сложно. Простое добавление слоев в модель глубокого обучения часто вызывает проблему "исчезающего градиента", когда сигналы обучения исчезают в слоях, препятствуя эффективному обучению. И наоборот, рекуррентные модели, которые повторяют вычисления, могут испытывать "раннюю сходимость", когда модель преждевременно фиксируется на решении, не изучив проблему досконально.
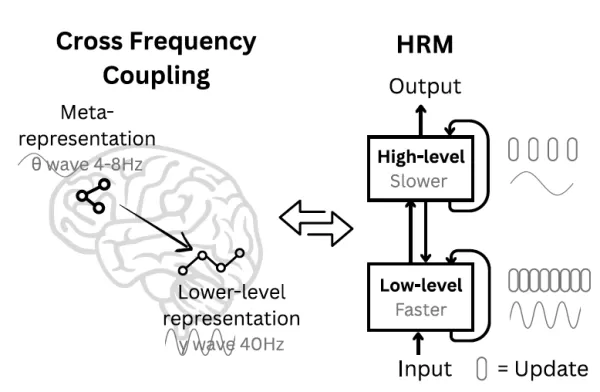
Иерархическая модель рассуждений (Hierarchical Reasoning Model, HRM) вдохновлена структурой мозга Источник: arXiv В поисках лучшего метода команда Sapient обратилась за советом к нейронауке. "Человеческий мозг представляет собой убедительную модель для достижения вычислительной глубины, которой не хватает нынешним искусственным системам", - утверждают исследователи. "Он иерархически структурирует вычисления между областями коры головного мозга, работающими на разных временных масштабах, что позволяет проводить глубокий многоступенчатый анализ".
Под влиянием этого они создали HRM с двумя взаимосвязанными повторяющимися модулями: высокоуровневым (H) модулем для медленной, абстрактной разработки стратегий и низкоуровневым (L) модулем для быстрой, детальной обработки. Такое расположение облегчает работу механизма, который команда назвала "иерархической конвергенцией". По сути, быстрый L-модуль обрабатывает сегмент проблемы, выполняя несколько циклов, пока не найдет стабильный локальный ответ. Затем медленный H-модуль учитывает этот результат, уточняет свой общий план и назначает L-модулю новую, лучше определенную подпроблему. Это эффективно перезагружает L-модуль, предотвращая его стагнацию (ранняя конвергенция) и позволяя всей системе выполнять расширенную серию этапов рассуждений, используя оптимизированную архитектуру, которая позволяет избежать исчезающих градиентов.
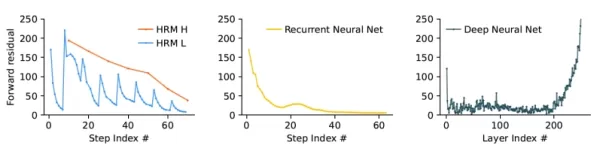
HRM (слева) плавно сходится к решению на протяжении всех циклов вычислений, избегая ранней сходимости (в центре, РНС) и исчезающих градиентов (справа, классические глубокие нейронные сети) Источник: arXiv Согласно статье, "этот механизм позволяет HRM выполнять последовательность отдельных, устойчивых, вложенных друг в друга вычислений, где H-модуль направляет глобальный подход к решению проблемы, а L-модуль выполняет интенсивный поиск или уточнение для каждой фазы". Такая архитектура вложенного цикла позволяет модели проводить глубокий анализ в своем латентном пространстве, не требуя расширенных подсказок CoT или огромных наборов данных.
Закономерно возникает вопрос, не жертвует ли такое "скрытое рассуждение" интерпретируемостью. Гуань Ван, основатель и генеральный директор Sapient Intelligence, опровергает это мнение, поясняя, что внутренние операции модели могут быть интерпретированы и проиллюстрированы, подобно тому как CoT предлагает понимание познания модели. Он также отмечает, что сам CoT может быть ненадежным. "CoT неточно отражает истинные внутренние рассуждения модели", - сообщил Ванг в интервью VentureBeat, ссылаясь на исследования, показывающие, что модели могут иногда выдавать правильные ответы при ошибочных рассуждениях, а иногда наоборот. "Она по-прежнему остается непрозрачной".

Пример того, как HRM решает задачу с лабиринтом на разных вычислительных циклах Источник: arXiv HRM за работой
Чтобы оценить свою модель, исследователи сравнили HRM с эталонами, требующими интенсивного поиска и обратного пути, такими как корпус абстракций и рассуждений (ARC-AGI), сложнейшие головоломки судоку и сложные задачи по прохождению лабиринта.
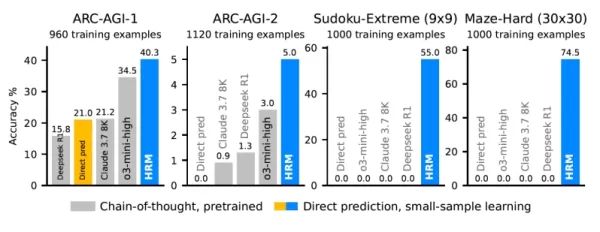
Результаты показывают, что HRM учится решать задачи, которые не под силу даже сложным LLM. Например, в тестах "Sudoku-Extreme" и "Maze-Hard" лучшие модели CoT полностью провалились, зафиксировав точность 0%. В то же время HRM достигла практически безупречной точности после обучения всего на 1 000 примеров для каждой задачи.
В тесте ARC-AGI, измеряющем абстрактное мышление и обобщение, HRM с 27 М-параметрами достигла 40,3%. Это превосходит такие известные модели на основе CoT, как гораздо более крупная o3-mini-high (34,5 %) и Claude 3.7 Sonnet (21,2 %). Это достижение, реализованное без обширного набора данных для предварительного обучения и с минимальным количеством данных, подчеркивает силу и эффективность его дизайна.
HRM превосходит большие модели в сложных задачах рассуждения Источник: arXiv В то время как решение головоломок демонстрирует возможности модели, ее практическая отдача проявляется в другой категории задач. По мнению Ванга, разработчикам следует продолжать использовать LLM для решения задач, ориентированных на язык или творчество, но для "сложных или детерминированных задач" фреймворк в стиле HRM обеспечивает превосходные результаты с меньшим количеством галлюцинаций. Он выделяет "последовательные задачи, требующие сложного принятия решений или долгосрочного планирования", особенно в областях, критичных к задержкам, таких как воплощенный ИИ и робототехника, или в областях с редкими данными, например в научных исследованиях.
В таких ситуациях HRM не просто находит решения, а учится улучшать их. "В наших тестах судоку на уровне мастера... HRM постепенно требует все меньше шагов по мере обучения - подобно тому, как новичок превращается в специалиста", - уточняет Ванг.
Для бизнеса эффективность архитектуры влияет на прибыльность. Вместо последовательного производства токенов в CoT, параллельные вычисления HRM позволяют, по словам Ванга, "ускорить скорость выполнения задач в 100 раз". Это приводит к сокращению задержек в выводах и возможности работы с расширенными вычислениями на пограничных устройствах.
Финансовые выгоды также значительны. "Специализированные движки рассуждений, такие как HRM, представляют собой более жизнеспособный вариант для конкретных сложных задач рассуждения по сравнению с большими, дорогими и высокозамедленными моделями, управляемыми API", - заявил Ванг. Для иллюстрации эффективности он отметил, что обучение модели для профессионального судоку требует около двух часов работы GPU, а для требовательного бенчмарка ARC-AGI - от 50 до 200 часов работы GPU - минимальная доля ресурсов, необходимых для огромных базовых моделей. Это дает возможность решать специализированные бизнес-задачи, от планирования логистики до устранения сложных системных неполадок, в условиях, когда ограничены как данные, так и финансирование.
В дальнейшем Sapient Intelligence уже работает над тем, чтобы превратить HRM из нишевого инструмента для решения проблем в более широкий компонент рассуждений общего назначения. "Мы активно создаем модели, вдохновленные мозгом, на основе HRM", - говорит Ванг, указывая на обнадеживающие первые результаты в здравоохранении, прогнозировании климата и робототехнике. Он намекнул, что эти будущие модели будут существенно отличаться от нынешних текстовых систем, в частности за счет интеграции функций самокоррекции.
Исследование предполагает, что для ряда проблем, которые ставят в тупик современных лидеров в области ИИ, путь вперед может лежать не через большие модели, а через более интеллектуальные, лучше организованные структуры, смоделированные на основе самой передовой системы рассуждений - человеческого мозга.
Связанная статья
 Компания Bain прогнозирует, что рынок SaaS в сфере автоматизации на базе агентного ИИ достигнет 100 млрд долларов США
По оценкам компании Bain & Company, объем рынка SaaS-компаний, использующих агентский ИИ, в США составляет 100 миллиардов долларов. По мнению компании, этот рынок формируется за счет автоматизации зад
Kakao Mobility представляет план развития автономного вождения 4-го уровня с использованием физического ИИ
Компания Kakao Mobility планирует самостоятельно разрабатывать технологии автономного вождения 4-го уровня в рамках своей стратегии «физического ИИ».На конференции World IT Show 2026, прошедшей в сеу
Искусственный интеллект все ближе подходит к производственным цехам, поскольку гуманоидные роботы проходят испытания
Как сообщает агентство Reuters, британская технологическая компания Humanoid планирует внедрить гуманоидных роботов на заводах немецкого промышленного поставщика Schaeffler.По словам представителя Hu
Рекомендации по связанным специальным темам
Создание комиксов
Компания Bain прогнозирует, что рынок SaaS в сфере автоматизации на базе агентного ИИ достигнет 100 млрд долларов США
По оценкам компании Bain & Company, объем рынка SaaS-компаний, использующих агентский ИИ, в США составляет 100 миллиардов долларов. По мнению компании, этот рынок формируется за счет автоматизации зад
Kakao Mobility представляет план развития автономного вождения 4-го уровня с использованием физического ИИ
Компания Kakao Mobility планирует самостоятельно разрабатывать технологии автономного вождения 4-го уровня в рамках своей стратегии «физического ИИ».На конференции World IT Show 2026, прошедшей в сеу
Искусственный интеллект все ближе подходит к производственным цехам, поскольку гуманоидные роботы проходят испытания
Как сообщает агентство Reuters, британская технологическая компания Humanoid планирует внедрить гуманоидных роботов на заводах немецкого промышленного поставщика Schaeffler.По словам представителя Hu
Рекомендации по связанным специальным темам
Создание комиксов
 Лучшие инструменты для автоматической раскраски манги с помощью ИИ: нанесение плоских цветов без ошибок в цветовом решении
Лучшие инструменты для автоматической раскраски манги с помощью ИИ: нанесение плоских цветов без ошибок в цветовом решении
Откройте для себя лучшие инструменты для автоматической раскраски манги с помощью ИИ в 2026 году на сайте XIX.AI. В нашем тщательно составленном списке представлены самые популярные и революционные решения, которые наносят плоские цвета без единой ошибки в цветовом соответствии, что значительно повышает вашу продуктивность. Изучите сравнения бесплатных и платных версий, результаты реальных тестов и еженедельно обновляемые рейтинги, чтобы найти идеальный вариант для себя. Воспользуйтесь преимуществами ИИ уже сегодня.
 10 инструментов
10 инструментов
 xix.ai
письмо
Лучшие программы для создания персонажей в жанре научной фантастики: генерация последовательных мотиваций персонажей и их роковых недостатков
xix.ai
письмо
Лучшие программы для создания персонажей в жанре научной фантастики: генерация последовательных мотиваций персонажей и их роковых недостатков
Откройте для себя 20 лучших инструментов 2026 года для создания персонажей с помощью искусственного интеллекта, которые помогут вам придать своим героям глубину. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, способные генерировать правдоподобные мотивации и роковые недостатки персонажей. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой потенциал в области создания историй уже сейчас.
10 инструментов
xix.ai
Бизнес
Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
10 инструментов
xix.ai
код
Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai
Преобразование текста в речь
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai
Создание комиксов
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

 Комментарии (0)
Комментарии (0)
Сингапурская компания Sapient Intelligence разработала новую архитектуру искусственного интеллекта, которая может конкурировать с большими языковыми моделями (LLM) в сложных задачах рассуждения, а в некоторых сценариях и значительно превосходить их, несмотря на гораздо меньший размер модели и потребление гораздо меньшего количества данных.
Эта система, получившая название Hierarchical Reasoning Model (HRM), черпает вдохновение в использовании человеческим мозгом отдельных механизмов для медленного, методичного планирования и быстрой, интуитивной обработки. Модель позволяет добиться замечательных результатов, используя лишь малую часть данных и памяти, требуемых современными LLM. Такая эффективность открывает широкие возможности для развертывания корпоративного ИИ, где данные часто ограничены, а вычислительная мощность - нехватка.
Ограничения цепных рассуждений
При решении сложных задач современные LLM в основном полагаются на подсказки в виде цепочки мыслей (CoT), когда проблемы разбиваются на промежуточные текстовые шаги, что, по сути, заставляет модель вербализовать свой мыслительный процесс по мере продвижения к ответу.
Хотя CoT расширила возможности рассуждений LLM, она страдает от присущих ей недостатков. В своем исследовании команда Sapient Intelligence утверждает, что "CoT - это всего лишь временная мера для рассуждений, а не настоящее решение. Он зависит от жестких, определяемых человеком сбоев, когда один неверный шаг или неправильно выстроенная последовательность действий могут полностью сорвать весь процесс".
Такая зависимость от генерации явного текста привязывает рассуждения модели к уровню токенов, что часто требует огромных наборов обучающих данных и приводит к длительным и медленным ответам. Этот метод также не учитывает "скрытые рассуждения", которые происходят внутри системы, не будучи выраженными непосредственно в словах.
Исследователи отмечают: "Для снижения интенсивности использования данных необходим более рациональный метод".
Иерархическая структура, вдохновленная мозгом
Чтобы выйти за рамки CoT, команда исследовала "скрытые рассуждения", когда модель решает проблемы, используя свои внутренние, абстрактные представления, а не создает осязаемые "мыслительные маркеры". Это более близко к человеческому познанию; в статье упоминается, что "мозг поддерживает расширенные логические цепочки рассуждений с заметной эффективностью в латентном пространстве, не нуждаясь в постоянном преобразовании мыслей обратно в язык".
Однако реализовать подобную глубокую внутреннюю логику в ИИ довольно сложно. Простое добавление слоев в модель глубокого обучения часто вызывает проблему "исчезающего градиента", когда сигналы обучения исчезают в слоях, препятствуя эффективному обучению. И наоборот, рекуррентные модели, которые повторяют вычисления, могут испытывать "раннюю сходимость", когда модель преждевременно фиксируется на решении, не изучив проблему досконально.
В поисках лучшего метода команда Sapient обратилась за советом к нейронауке. "Человеческий мозг представляет собой убедительную модель для достижения вычислительной глубины, которой не хватает нынешним искусственным системам", - утверждают исследователи. "Он иерархически структурирует вычисления между областями коры головного мозга, работающими на разных временных масштабах, что позволяет проводить глубокий многоступенчатый анализ".
Под влиянием этого они создали HRM с двумя взаимосвязанными повторяющимися модулями: высокоуровневым (H) модулем для медленной, абстрактной разработки стратегий и низкоуровневым (L) модулем для быстрой, детальной обработки. Такое расположение облегчает работу механизма, который команда назвала "иерархической конвергенцией". По сути, быстрый L-модуль обрабатывает сегмент проблемы, выполняя несколько циклов, пока не найдет стабильный локальный ответ. Затем медленный H-модуль учитывает этот результат, уточняет свой общий план и назначает L-модулю новую, лучше определенную подпроблему. Это эффективно перезагружает L-модуль, предотвращая его стагнацию (ранняя конвергенция) и позволяя всей системе выполнять расширенную серию этапов рассуждений, используя оптимизированную архитектуру, которая позволяет избежать исчезающих градиентов.
Согласно статье, "этот механизм позволяет HRM выполнять последовательность отдельных, устойчивых, вложенных друг в друга вычислений, где H-модуль направляет глобальный подход к решению проблемы, а L-модуль выполняет интенсивный поиск или уточнение для каждой фазы". Такая архитектура вложенного цикла позволяет модели проводить глубокий анализ в своем латентном пространстве, не требуя расширенных подсказок CoT или огромных наборов данных.
Закономерно возникает вопрос, не жертвует ли такое "скрытое рассуждение" интерпретируемостью. Гуань Ван, основатель и генеральный директор Sapient Intelligence, опровергает это мнение, поясняя, что внутренние операции модели могут быть интерпретированы и проиллюстрированы, подобно тому как CoT предлагает понимание познания модели. Он также отмечает, что сам CoT может быть ненадежным. "CoT неточно отражает истинные внутренние рассуждения модели", - сообщил Ванг в интервью VentureBeat, ссылаясь на исследования, показывающие, что модели могут иногда выдавать правильные ответы при ошибочных рассуждениях, а иногда наоборот. "Она по-прежнему остается непрозрачной".
HRM за работой
Чтобы оценить свою модель, исследователи сравнили HRM с эталонами, требующими интенсивного поиска и обратного пути, такими как корпус абстракций и рассуждений (ARC-AGI), сложнейшие головоломки судоку и сложные задачи по прохождению лабиринта.
Результаты показывают, что HRM учится решать задачи, которые не под силу даже сложным LLM. Например, в тестах "Sudoku-Extreme" и "Maze-Hard" лучшие модели CoT полностью провалились, зафиксировав точность 0%. В то же время HRM достигла практически безупречной точности после обучения всего на 1 000 примеров для каждой задачи.
В тесте ARC-AGI, измеряющем абстрактное мышление и обобщение, HRM с 27 М-параметрами достигла 40,3%. Это превосходит такие известные модели на основе CoT, как гораздо более крупная o3-mini-high (34,5 %) и Claude 3.7 Sonnet (21,2 %). Это достижение, реализованное без обширного набора данных для предварительного обучения и с минимальным количеством данных, подчеркивает силу и эффективность его дизайна.
В то время как решение головоломок демонстрирует возможности модели, ее практическая отдача проявляется в другой категории задач. По мнению Ванга, разработчикам следует продолжать использовать LLM для решения задач, ориентированных на язык или творчество, но для "сложных или детерминированных задач" фреймворк в стиле HRM обеспечивает превосходные результаты с меньшим количеством галлюцинаций. Он выделяет "последовательные задачи, требующие сложного принятия решений или долгосрочного планирования", особенно в областях, критичных к задержкам, таких как воплощенный ИИ и робототехника, или в областях с редкими данными, например в научных исследованиях.
В таких ситуациях HRM не просто находит решения, а учится улучшать их. "В наших тестах судоку на уровне мастера... HRM постепенно требует все меньше шагов по мере обучения - подобно тому, как новичок превращается в специалиста", - уточняет Ванг.
Для бизнеса эффективность архитектуры влияет на прибыльность. Вместо последовательного производства токенов в CoT, параллельные вычисления HRM позволяют, по словам Ванга, "ускорить скорость выполнения задач в 100 раз". Это приводит к сокращению задержек в выводах и возможности работы с расширенными вычислениями на пограничных устройствах.
Финансовые выгоды также значительны. "Специализированные движки рассуждений, такие как HRM, представляют собой более жизнеспособный вариант для конкретных сложных задач рассуждения по сравнению с большими, дорогими и высокозамедленными моделями, управляемыми API", - заявил Ванг. Для иллюстрации эффективности он отметил, что обучение модели для профессионального судоку требует около двух часов работы GPU, а для требовательного бенчмарка ARC-AGI - от 50 до 200 часов работы GPU - минимальная доля ресурсов, необходимых для огромных базовых моделей. Это дает возможность решать специализированные бизнес-задачи, от планирования логистики до устранения сложных системных неполадок, в условиях, когда ограничены как данные, так и финансирование.
В дальнейшем Sapient Intelligence уже работает над тем, чтобы превратить HRM из нишевого инструмента для решения проблем в более широкий компонент рассуждений общего назначения. "Мы активно создаем модели, вдохновленные мозгом, на основе HRM", - говорит Ванг, указывая на обнадеживающие первые результаты в здравоохранении, прогнозировании климата и робототехнике. Он намекнул, что эти будущие модели будут существенно отличаться от нынешних текстовых систем, в частности за счет интеграции функций самокоррекции.
Исследование предполагает, что для ряда проблем, которые ставят в тупик современных лидеров в области ИИ, путь вперед может лежать не через большие модели, а через более интеллектуальные, лучше организованные структуры, смоделированные на основе самой передовой системы рассуждений - человеческого мозга.









 Компания Bain прогнозирует, что рынок SaaS в сфере автоматизации на базе агентного ИИ достигнет 100 млрд долларов США
По оценкам компании Bain & Company, объем рынка SaaS-компаний, использующих агентский ИИ, в США составляет 100 миллиардов долларов. По мнению компании, этот рынок формируется за счет автоматизации зад
Kakao Mobility представляет план развития автономного вождения 4-го уровня с использованием физического ИИ
Компания Kakao Mobility планирует самостоятельно разрабатывать технологии автономного вождения 4-го уровня в рамках своей стратегии «физического ИИ».На конференции World IT Show 2026, прошедшей в сеу
Искусственный интеллект все ближе подходит к производственным цехам, поскольку гуманоидные роботы проходят испытания
Как сообщает агентство Reuters, британская технологическая компания Humanoid планирует внедрить гуманоидных роботов на заводах немецкого промышленного поставщика Schaeffler.По словам представителя Hu
Компания Bain прогнозирует, что рынок SaaS в сфере автоматизации на базе агентного ИИ достигнет 100 млрд долларов США
По оценкам компании Bain & Company, объем рынка SaaS-компаний, использующих агентский ИИ, в США составляет 100 миллиардов долларов. По мнению компании, этот рынок формируется за счет автоматизации зад
Kakao Mobility представляет план развития автономного вождения 4-го уровня с использованием физического ИИ
Компания Kakao Mobility планирует самостоятельно разрабатывать технологии автономного вождения 4-го уровня в рамках своей стратегии «физического ИИ».На конференции World IT Show 2026, прошедшей в сеу
Искусственный интеллект все ближе подходит к производственным цехам, поскольку гуманоидные роботы проходят испытания
Как сообщает агентство Reuters, британская технологическая компания Humanoid планирует внедрить гуманоидных роботов на заводах немецкого промышленного поставщика Schaeffler.По словам представителя Hu

Откройте для себя лучшие инструменты для автоматической раскраски манги с помощью ИИ в 2026 году на сайте XIX.AI. В нашем тщательно составленном списке представлены самые популярные и революционные решения, которые наносят плоские цвета без единой ошибки в цветовом соответствии, что значительно повышает вашу продуктивность. Изучите сравнения бесплатных и платных версий, результаты реальных тестов и еженедельно обновляемые рейтинги, чтобы найти идеальный вариант для себя. Воспользуйтесь преимуществами ИИ уже сегодня.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов 2026 года для создания персонажей с помощью искусственного интеллекта, которые помогут вам придать своим героям глубину. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, способные генерировать правдоподобные мотивации и роковые недостатки персонажей. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой потенциал в области создания историй уже сейчас.
10 инструментов
xix.ai

Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
10 инструментов
xix.ai

Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai













