
















 Heim
Heim
Neues KI-Modell übertrifft LLMs mit 100-fachem Geschwindigkeitsschub und minimalen Trainingsdaten
Das in Singapur ansässige KI-Startup Sapient Intelligence hat eine neuartige KI-Architektur entwickelt, die mit großen Sprachmodellen (LLMs) konkurrieren kann - und diese in bestimmten Szenarien sogar deutlich übertrifft - wenn es um komplizierte logische Schlussfolgerungen geht, obwohl das Modell viel kleiner ist und weit weniger Daten verbraucht.
Dieses System mit dem Namen Hierarchical Reasoning Model (HRM) wurde vom menschlichen Gehirn inspiriert, das getrennte Mechanismen für langsame, methodische Planung und schnelle, intuitive Verarbeitung verwendet. Das Modell liefert bemerkenswerte Ergebnisse mit nur einem Bruchteil der Daten und des Speichers, die von modernen LLMs benötigt werden. Diese Effizienz birgt ein erhebliches Potenzial für den Einsatz von KI in Unternehmen, wo Daten oft begrenzt sind und die Rechenleistung eine Einschränkung darstellt.
Die Grenzen der Gedankenkettenlogik
Bei der Bewältigung komplexer Aufgaben sind moderne LLMs meist auf Denkketten angewiesen, bei denen Probleme in textbasierte Zwischenschritte zerlegt werden, so dass das Modell gezwungen ist, seinen Denkprozess zu verbalisieren, während es sich einer Antwort nähert.
CoT hat zwar die Argumentationsfähigkeiten von LLMs verbessert, weist aber auch einige Schwächen auf. In ihrem Forschungspapier behauptet das Team von Sapient Intelligence, dass CoT lediglich eine Zwischenlösung für das logische Denken ist, aber keine echte Lösung. Es hängt von starren, von Menschenhand bestimmten Unterbrechungen ab, bei denen ein falscher Schritt oder eine ungeordnete Abfolge den gesamten Prozess zum Entgleisen bringen kann".
Diese Abhängigkeit von der Generierung expliziten Textes bindet die Argumentation des Modells an die Token-Ebene, was häufig enorme Trainingsdatensätze erfordert und zu langwierigen, schleppenden Antworten führt. Bei dieser Methode wird auch die Art von "latentem Denken" übersehen, das intern abläuft, ohne direkt in Worten ausgedrückt zu werden.
Die Forscher stellen fest: "Eine schlankere Methode ist unerlässlich, um diesen intensiven Datenbedarf zu reduzieren."
Ein vom Gehirn inspirierter hierarchischer Rahmen
Um über die CoT hinauszugehen, untersuchte das Team das "latente Denken", bei dem das Modell Probleme anhand seiner internen, abstrakten Darstellungen durchdenkt, anstatt greifbare "Denksteine" zu produzieren. Dies entspricht eher der menschlichen Kognition; in dem Papier heißt es: "Das Gehirn unterhält ausgedehnte, logische Denkketten mit bemerkenswerter Effizienz in einem latenten Raum, ohne dass Gedanken ständig wieder in Sprache umgewandelt werden müssen."
Es ist jedoch schwierig, diese Art von tiefgreifendem, internem Denken in der KI umzusetzen. Das bloße Hinzufügen von Schichten zu einem Deep-Learning-Modell löst häufig das Problem des "verschwindenden Gradienten" aus, bei dem die Lernsignale über die Schichten hinweg verblassen, was ein effektives Training behindert. Umgekehrt kann es bei rekurrenten Designs, die durch Berechnungen iterieren, zu einer "frühen Konvergenz" kommen, bei der sich das Modell vorzeitig auf eine Lösung festlegt, ohne das Problem gründlich zu untersuchen.
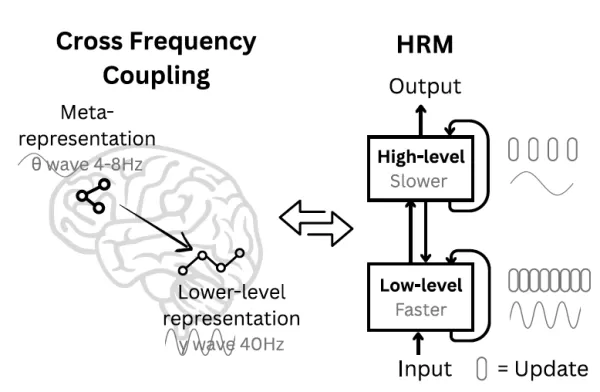
Das Hierarchische Reasoning-Modell (HRM) ist von der Struktur des Gehirns inspiriert Quelle: arXiv Auf der Suche nach einer besseren Methode hat sich das Sapient-Team von den Neurowissenschaften leiten lassen. "Das menschliche Gehirn stellt ein überzeugendes Modell dar, um die Rechentiefe zu erreichen, die derzeitigen künstlichen Systemen fehlt", so die Forscher. "Es strukturiert die Berechnungen hierarchisch über kortikale Bereiche, die auf unterschiedlichen Zeitskalen arbeiten, und ermöglicht so eine tiefgehende, mehrstufige Analyse."
Beeinflusst von dieser Erkenntnis schufen sie HRM mit zwei miteinander verbundenen, wiederkehrenden Modulen: einem High-Level-Modul (H) für langsame, abstrakte Strategiebildung und einem Low-Level-Modul (L) für schnelle, detaillierte Verarbeitung. Diese Anordnung erleichtert einen Mechanismus, den das Team als "hierarchische Konvergenz" bezeichnet. Im Wesentlichen nimmt das schnelle L-Modul einen Teil des Problems in Angriff und führt mehrere Zyklen durch, bis es eine stabile, lokale Antwort findet. Dann nimmt das langsame H-Modul dieses Ergebnis auf, verfeinert seinen übergreifenden Plan und weist dem L-Modul ein neues, besser definiertes Teilproblem zu. Dies führt zu einem Neustart des L-Moduls, verhindert, dass es stagniert (frühe Konvergenz), und ermöglicht es dem Gesamtsystem, eine längere Reihe von Argumentationsschritten unter Verwendung einer rationalisierten Architektur durchzuführen, die verschwindende Gradienten vermeidet.
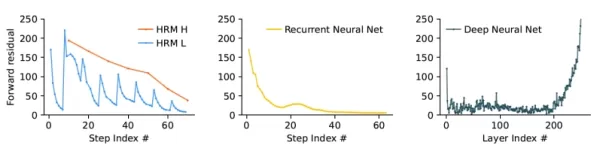
HRM (links) konvergiert über Berechnungszyklen hinweg reibungslos zur Lösung und vermeidet frühe Konvergenz (Mitte, RNNs) und verschwindende Gradienten (rechts, klassische tiefe neuronale Netze) Quelle: arXiv In dem Papier heißt es: "Dieser Mechanismus ermöglicht es dem HRM, eine Abfolge von separaten, stetigen, verschachtelten Berechnungen durchzuführen, wobei das H-Modul den globalen Problemlösungsansatz leitet und das L-Modul die intensive Suche oder Verfeinerung für jede Phase durchführt." Diese verschachtelte Schleifenarchitektur ermöglicht es dem Modell, tiefe Analysen in seinem latenten Raum durchzuführen, ohne dass erweiterte CoT-Aufforderungen oder riesige Datensätze erforderlich sind.
Eine logische Frage ist, ob diese "latente Argumentation" die Interpretierbarkeit beeinträchtigt. Guan Wang, Gründer und CEO von Sapient Intelligence, stellt dies in Frage und erklärt, dass die internen Vorgänge des Modells interpretiert und veranschaulicht werden können, ähnlich wie CoT einen Einblick in die Kognition eines Modells bietet. Er stellt außerdem fest, dass CoT selbst unzuverlässig sein kann. "CoT repräsentiert nicht genau die wahren internen Überlegungen eines Modells", sagte Wang gegenüber VentureBeat und verwies auf Forschungsergebnisse, die zeigen, dass Modelle gelegentlich richtige Antworten mit fehlerhaften Überlegungen geben können, aber auch das Gegenteil. "Es ist immer noch grundlegend undurchsichtig."

Beispiel dafür, wie HRM ein Labyrinthproblem über verschiedene Rechenzyklen hinweg überlegt Quelle: arXiv HRM bei der Arbeit
Um ihr Modell zu bewerten, verglichen die Forscher HRM mit Benchmarks, die intensives Suchen und Backtracking erfordern, wie dem Abstraction and Reasoning Corpus (ARC-AGI), sehr anspruchsvollen Sudoku-Rätseln und komplizierten Labyrinth-Navigationsaufgaben.
Die Ergebnisse zeigen, dass HRM lernt, Probleme zu lösen, die selbst für anspruchsvolle LLMs unlösbar sind. Bei den "Sudoku-Extreme"- und "Maze-Hard"-Tests zum Beispiel versagten die besten CoT-Modelle komplett und erreichten 0 % Genauigkeit. HRM hingegen erreichte eine nahezu fehlerfreie Genauigkeit nach dem Training mit nur 1.000 Beispielen pro Aufgabe.
Beim ARC-AGI-Benchmark, einem Maß für abstraktes Denken und Verallgemeinerung, erreichte das HRM mit 27M-Parametern 40,3%. Damit übertrifft es prominente CoT-basierte Modelle wie das viel größere o3-mini-high (34,5%) und Claude 3.7 Sonnet (21,2%). Diese Leistung, die ohne einen großen Pre-Training-Datensatz und mit minimalen Daten erzielt wurde, unterstreicht die Stärke und Effizienz seines Designs.
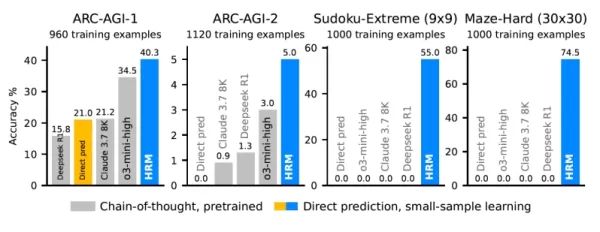
HRM übertrifft große Modelle bei komplexen logischen Aufgaben Quelle: arXiv Während das Lösen von Rätseln die Fähigkeiten des Modells unter Beweis stellt, zeigen sich seine praktischen Auswirkungen in einer anderen Kategorie von Aufgaben. Laut Wang sollten Entwickler weiterhin LLMs für sprachzentrierte oder kreative Aufgaben verwenden, aber für "komplexe oder deterministische Aufgaben" liefert ein HRM-artiges Framework bessere Ergebnisse mit weniger Halluzinationen. Er hebt "sequentielle Probleme hervor, die eine komplizierte Entscheidungsfindung oder langfristige Planung erfordern", insbesondere in latenzkritischen Bereichen wie der verkörpernden KI und der Robotik oder in Bereichen mit spärlichen Daten, wie der wissenschaftlichen Forschung.
In diesen Situationen findet HRM nicht nur Lösungen, sondern lernt auch, seine Problemlösung zu verbessern. "In unseren Sudoku-Tests auf Meisterebene ... benötigt HRM mit fortschreitendem Training immer weniger Schritte - ähnlich wie ein Anfänger, der sich zu einem Spezialisten entwickelt", so Wang weiter.
Für Unternehmen wirkt sich die Effizienz der Architektur hier auf die Rentabilität aus. Anstelle der sequentiellen, Token-für-Token-Produktion von CoT ermöglicht die parallele Berechnung von HRM eine, wie Wang es ausdrückt, "100-fache Beschleunigung der Aufgabenerfüllung". Dies führt zu einer geringeren Latenzzeit bei den Schlussfolgerungen und der Fähigkeit, fortschrittliche Schlussfolgerungen auf Edge-Geräten zu betreiben.
Auch die finanziellen Vorteile sind beträchtlich. "Spezialisierte Reasoning-Engines wie HRM stellen im Vergleich zu großen, teuren und API-gesteuerten Modellen mit hoher Latenz eine praktikablere Option für bestimmte komplexe Reasoning-Aufgaben dar", so Wang. Zur Veranschaulichung der Effizienz erwähnte er, dass das Training des Modells für professionelles Sudoku etwa zwei GPU-Stunden erfordert und für den anspruchsvollen ARC-AGI-Benchmark zwischen 50 und 200 GPU-Stunden - ein minimaler Anteil der Ressourcen, die für enorme Basismodelle erforderlich sind. Dies eröffnet die Möglichkeit, spezielle Geschäftsprobleme zu lösen, von der Logistikplanung bis hin zur komplizierten Fehlersuche in Systemen, bei denen sowohl die Daten als auch die finanziellen Mittel begrenzt sind.
Sapient Intelligence arbeitet bereits daran, HRM von einem Nischenproblemlösungs-Tool in eine breitere, universell einsetzbare Denkkomponente umzuwandeln. "Wir sind aktiv dabei, vom Gehirn inspirierte Modelle auf der Grundlage von HRM zu entwickeln", sagte Wang und verwies auf ermutigende erste Ergebnisse in den Bereichen Gesundheitswesen, Klimavorhersage und Robotik. Er deutete an, dass sich diese zukünftigen Modelle wesentlich von den derzeitigen textbasierten Systemen unterscheiden werden, insbesondere durch die Integration von Selbstkorrekturfunktionen.
Die Forschungsergebnisse deuten darauf hin, dass bei einer Reihe von Problemen, die die heutigen KI-Führungskräfte vor ein Rätsel stellen, der Weg in die Zukunft nicht in größeren Modellen, sondern in intelligenteren, besser organisierten Rahmenwerken liegt, die dem fortschrittlichsten logischen System nachempfunden sind: dem menschlichen Gehirn.
Verwandter Artikel
 Bain prognostiziert einen SaaS-Markt im Wert von 100 Milliarden US-Dollar im Bereich der agentenbasierten KI-Automatisierung
Bain & Company schätzt den Markt für SaaS-Unternehmen, die agentische KI nutzen, in den USA auf 100 Milliarden US-Dollar. Das Unternehmen erklärte, dieser Markt entstamme der Automatisierung von Koord
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
Die physische KI rückt immer näher an die Fertigungshallen heran, während humanoide Roboter getestet werden
Laut Reuters plant das britische Technologieunternehmen Humanoid den Einsatz humanoider Roboter in den Fabriken des deutschen Industriezulieferers Schaeffler.Laut einem Sprecher von Humanoid sollen i
Empfehlungen zu verwandten Spezialthemen
Schreiben
Bain prognostiziert einen SaaS-Markt im Wert von 100 Milliarden US-Dollar im Bereich der agentenbasierten KI-Automatisierung
Bain & Company schätzt den Markt für SaaS-Unternehmen, die agentische KI nutzen, in den USA auf 100 Milliarden US-Dollar. Das Unternehmen erklärte, dieser Markt entstamme der Automatisierung von Koord
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
Die physische KI rückt immer näher an die Fertigungshallen heran, während humanoide Roboter getestet werden
Laut Reuters plant das britische Technologieunternehmen Humanoid den Einsatz humanoider Roboter in den Fabriken des deutschen Industriezulieferers Schaeffler.Laut einem Sprecher von Humanoid sollen i
Empfehlungen zu verwandten Spezialthemen
Schreiben
 Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
 10 Tools
10 Tools
 xix.ai
Geschäft
Die beste Software zur Preisoptimierung mittels KI: Beobachten Sie die Konkurrenz und passen Sie Ihre Shop-Preise automatisch an
xix.ai
Geschäft
Die beste Software zur Preisoptimierung mittels KI: Beobachten Sie die Konkurrenz und passen Sie Ihre Shop-Preise automatisch an
Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai
Code
Die besten KI-Code-Prüfer: Automatisierung der Einhaltung von Clean-Code-Standards und Refactoring von Dateien in älteren Repositorys
Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai
Text-zu-Sprache
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Das in Singapur ansässige KI-Startup Sapient Intelligence hat eine neuartige KI-Architektur entwickelt, die mit großen Sprachmodellen (LLMs) konkurrieren kann - und diese in bestimmten Szenarien sogar deutlich übertrifft - wenn es um komplizierte logische Schlussfolgerungen geht, obwohl das Modell viel kleiner ist und weit weniger Daten verbraucht.
Dieses System mit dem Namen Hierarchical Reasoning Model (HRM) wurde vom menschlichen Gehirn inspiriert, das getrennte Mechanismen für langsame, methodische Planung und schnelle, intuitive Verarbeitung verwendet. Das Modell liefert bemerkenswerte Ergebnisse mit nur einem Bruchteil der Daten und des Speichers, die von modernen LLMs benötigt werden. Diese Effizienz birgt ein erhebliches Potenzial für den Einsatz von KI in Unternehmen, wo Daten oft begrenzt sind und die Rechenleistung eine Einschränkung darstellt.
Die Grenzen der Gedankenkettenlogik
Bei der Bewältigung komplexer Aufgaben sind moderne LLMs meist auf Denkketten angewiesen, bei denen Probleme in textbasierte Zwischenschritte zerlegt werden, so dass das Modell gezwungen ist, seinen Denkprozess zu verbalisieren, während es sich einer Antwort nähert.
CoT hat zwar die Argumentationsfähigkeiten von LLMs verbessert, weist aber auch einige Schwächen auf. In ihrem Forschungspapier behauptet das Team von Sapient Intelligence, dass CoT lediglich eine Zwischenlösung für das logische Denken ist, aber keine echte Lösung. Es hängt von starren, von Menschenhand bestimmten Unterbrechungen ab, bei denen ein falscher Schritt oder eine ungeordnete Abfolge den gesamten Prozess zum Entgleisen bringen kann".
Diese Abhängigkeit von der Generierung expliziten Textes bindet die Argumentation des Modells an die Token-Ebene, was häufig enorme Trainingsdatensätze erfordert und zu langwierigen, schleppenden Antworten führt. Bei dieser Methode wird auch die Art von "latentem Denken" übersehen, das intern abläuft, ohne direkt in Worten ausgedrückt zu werden.
Die Forscher stellen fest: "Eine schlankere Methode ist unerlässlich, um diesen intensiven Datenbedarf zu reduzieren."
Ein vom Gehirn inspirierter hierarchischer Rahmen
Um über die CoT hinauszugehen, untersuchte das Team das "latente Denken", bei dem das Modell Probleme anhand seiner internen, abstrakten Darstellungen durchdenkt, anstatt greifbare "Denksteine" zu produzieren. Dies entspricht eher der menschlichen Kognition; in dem Papier heißt es: "Das Gehirn unterhält ausgedehnte, logische Denkketten mit bemerkenswerter Effizienz in einem latenten Raum, ohne dass Gedanken ständig wieder in Sprache umgewandelt werden müssen."
Es ist jedoch schwierig, diese Art von tiefgreifendem, internem Denken in der KI umzusetzen. Das bloße Hinzufügen von Schichten zu einem Deep-Learning-Modell löst häufig das Problem des "verschwindenden Gradienten" aus, bei dem die Lernsignale über die Schichten hinweg verblassen, was ein effektives Training behindert. Umgekehrt kann es bei rekurrenten Designs, die durch Berechnungen iterieren, zu einer "frühen Konvergenz" kommen, bei der sich das Modell vorzeitig auf eine Lösung festlegt, ohne das Problem gründlich zu untersuchen.
Auf der Suche nach einer besseren Methode hat sich das Sapient-Team von den Neurowissenschaften leiten lassen. "Das menschliche Gehirn stellt ein überzeugendes Modell dar, um die Rechentiefe zu erreichen, die derzeitigen künstlichen Systemen fehlt", so die Forscher. "Es strukturiert die Berechnungen hierarchisch über kortikale Bereiche, die auf unterschiedlichen Zeitskalen arbeiten, und ermöglicht so eine tiefgehende, mehrstufige Analyse."
Beeinflusst von dieser Erkenntnis schufen sie HRM mit zwei miteinander verbundenen, wiederkehrenden Modulen: einem High-Level-Modul (H) für langsame, abstrakte Strategiebildung und einem Low-Level-Modul (L) für schnelle, detaillierte Verarbeitung. Diese Anordnung erleichtert einen Mechanismus, den das Team als "hierarchische Konvergenz" bezeichnet. Im Wesentlichen nimmt das schnelle L-Modul einen Teil des Problems in Angriff und führt mehrere Zyklen durch, bis es eine stabile, lokale Antwort findet. Dann nimmt das langsame H-Modul dieses Ergebnis auf, verfeinert seinen übergreifenden Plan und weist dem L-Modul ein neues, besser definiertes Teilproblem zu. Dies führt zu einem Neustart des L-Moduls, verhindert, dass es stagniert (frühe Konvergenz), und ermöglicht es dem Gesamtsystem, eine längere Reihe von Argumentationsschritten unter Verwendung einer rationalisierten Architektur durchzuführen, die verschwindende Gradienten vermeidet.
In dem Papier heißt es: "Dieser Mechanismus ermöglicht es dem HRM, eine Abfolge von separaten, stetigen, verschachtelten Berechnungen durchzuführen, wobei das H-Modul den globalen Problemlösungsansatz leitet und das L-Modul die intensive Suche oder Verfeinerung für jede Phase durchführt." Diese verschachtelte Schleifenarchitektur ermöglicht es dem Modell, tiefe Analysen in seinem latenten Raum durchzuführen, ohne dass erweiterte CoT-Aufforderungen oder riesige Datensätze erforderlich sind.
Eine logische Frage ist, ob diese "latente Argumentation" die Interpretierbarkeit beeinträchtigt. Guan Wang, Gründer und CEO von Sapient Intelligence, stellt dies in Frage und erklärt, dass die internen Vorgänge des Modells interpretiert und veranschaulicht werden können, ähnlich wie CoT einen Einblick in die Kognition eines Modells bietet. Er stellt außerdem fest, dass CoT selbst unzuverlässig sein kann. "CoT repräsentiert nicht genau die wahren internen Überlegungen eines Modells", sagte Wang gegenüber VentureBeat und verwies auf Forschungsergebnisse, die zeigen, dass Modelle gelegentlich richtige Antworten mit fehlerhaften Überlegungen geben können, aber auch das Gegenteil. "Es ist immer noch grundlegend undurchsichtig."
HRM bei der Arbeit
Um ihr Modell zu bewerten, verglichen die Forscher HRM mit Benchmarks, die intensives Suchen und Backtracking erfordern, wie dem Abstraction and Reasoning Corpus (ARC-AGI), sehr anspruchsvollen Sudoku-Rätseln und komplizierten Labyrinth-Navigationsaufgaben.
Die Ergebnisse zeigen, dass HRM lernt, Probleme zu lösen, die selbst für anspruchsvolle LLMs unlösbar sind. Bei den "Sudoku-Extreme"- und "Maze-Hard"-Tests zum Beispiel versagten die besten CoT-Modelle komplett und erreichten 0 % Genauigkeit. HRM hingegen erreichte eine nahezu fehlerfreie Genauigkeit nach dem Training mit nur 1.000 Beispielen pro Aufgabe.
Beim ARC-AGI-Benchmark, einem Maß für abstraktes Denken und Verallgemeinerung, erreichte das HRM mit 27M-Parametern 40,3%. Damit übertrifft es prominente CoT-basierte Modelle wie das viel größere o3-mini-high (34,5%) und Claude 3.7 Sonnet (21,2%). Diese Leistung, die ohne einen großen Pre-Training-Datensatz und mit minimalen Daten erzielt wurde, unterstreicht die Stärke und Effizienz seines Designs.
Während das Lösen von Rätseln die Fähigkeiten des Modells unter Beweis stellt, zeigen sich seine praktischen Auswirkungen in einer anderen Kategorie von Aufgaben. Laut Wang sollten Entwickler weiterhin LLMs für sprachzentrierte oder kreative Aufgaben verwenden, aber für "komplexe oder deterministische Aufgaben" liefert ein HRM-artiges Framework bessere Ergebnisse mit weniger Halluzinationen. Er hebt "sequentielle Probleme hervor, die eine komplizierte Entscheidungsfindung oder langfristige Planung erfordern", insbesondere in latenzkritischen Bereichen wie der verkörpernden KI und der Robotik oder in Bereichen mit spärlichen Daten, wie der wissenschaftlichen Forschung.
In diesen Situationen findet HRM nicht nur Lösungen, sondern lernt auch, seine Problemlösung zu verbessern. "In unseren Sudoku-Tests auf Meisterebene ... benötigt HRM mit fortschreitendem Training immer weniger Schritte - ähnlich wie ein Anfänger, der sich zu einem Spezialisten entwickelt", so Wang weiter.
Für Unternehmen wirkt sich die Effizienz der Architektur hier auf die Rentabilität aus. Anstelle der sequentiellen, Token-für-Token-Produktion von CoT ermöglicht die parallele Berechnung von HRM eine, wie Wang es ausdrückt, "100-fache Beschleunigung der Aufgabenerfüllung". Dies führt zu einer geringeren Latenzzeit bei den Schlussfolgerungen und der Fähigkeit, fortschrittliche Schlussfolgerungen auf Edge-Geräten zu betreiben.
Auch die finanziellen Vorteile sind beträchtlich. "Spezialisierte Reasoning-Engines wie HRM stellen im Vergleich zu großen, teuren und API-gesteuerten Modellen mit hoher Latenz eine praktikablere Option für bestimmte komplexe Reasoning-Aufgaben dar", so Wang. Zur Veranschaulichung der Effizienz erwähnte er, dass das Training des Modells für professionelles Sudoku etwa zwei GPU-Stunden erfordert und für den anspruchsvollen ARC-AGI-Benchmark zwischen 50 und 200 GPU-Stunden - ein minimaler Anteil der Ressourcen, die für enorme Basismodelle erforderlich sind. Dies eröffnet die Möglichkeit, spezielle Geschäftsprobleme zu lösen, von der Logistikplanung bis hin zur komplizierten Fehlersuche in Systemen, bei denen sowohl die Daten als auch die finanziellen Mittel begrenzt sind.
Sapient Intelligence arbeitet bereits daran, HRM von einem Nischenproblemlösungs-Tool in eine breitere, universell einsetzbare Denkkomponente umzuwandeln. "Wir sind aktiv dabei, vom Gehirn inspirierte Modelle auf der Grundlage von HRM zu entwickeln", sagte Wang und verwies auf ermutigende erste Ergebnisse in den Bereichen Gesundheitswesen, Klimavorhersage und Robotik. Er deutete an, dass sich diese zukünftigen Modelle wesentlich von den derzeitigen textbasierten Systemen unterscheiden werden, insbesondere durch die Integration von Selbstkorrekturfunktionen.
Die Forschungsergebnisse deuten darauf hin, dass bei einer Reihe von Problemen, die die heutigen KI-Führungskräfte vor ein Rätsel stellen, der Weg in die Zukunft nicht in größeren Modellen, sondern in intelligenteren, besser organisierten Rahmenwerken liegt, die dem fortschrittlichsten logischen System nachempfunden sind: dem menschlichen Gehirn.









 Bain prognostiziert einen SaaS-Markt im Wert von 100 Milliarden US-Dollar im Bereich der agentenbasierten KI-Automatisierung
Bain & Company schätzt den Markt für SaaS-Unternehmen, die agentische KI nutzen, in den USA auf 100 Milliarden US-Dollar. Das Unternehmen erklärte, dieser Markt entstamme der Automatisierung von Koord
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
Die physische KI rückt immer näher an die Fertigungshallen heran, während humanoide Roboter getestet werden
Laut Reuters plant das britische Technologieunternehmen Humanoid den Einsatz humanoider Roboter in den Fabriken des deutschen Industriezulieferers Schaeffler.Laut einem Sprecher von Humanoid sollen i
Bain prognostiziert einen SaaS-Markt im Wert von 100 Milliarden US-Dollar im Bereich der agentenbasierten KI-Automatisierung
Bain & Company schätzt den Markt für SaaS-Unternehmen, die agentische KI nutzen, in den USA auf 100 Milliarden US-Dollar. Das Unternehmen erklärte, dieser Markt entstamme der Automatisierung von Koord
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
Die physische KI rückt immer näher an die Fertigungshallen heran, während humanoide Roboter getestet werden
Laut Reuters plant das britische Technologieunternehmen Humanoid den Einsatz humanoider Roboter in den Fabriken des deutschen Industriezulieferers Schaeffler.Laut einem Sprecher von Humanoid sollen i

Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die beste Software zur Preisoptimierung mittels KI für 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die Ihre Mitbewerber beobachten und Ihre Shop-Preise automatisch anpassen, um den maximalen Gewinn zu erzielen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Sichern Sie sich jetzt Ihren Preisvorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai













