
















 Heim
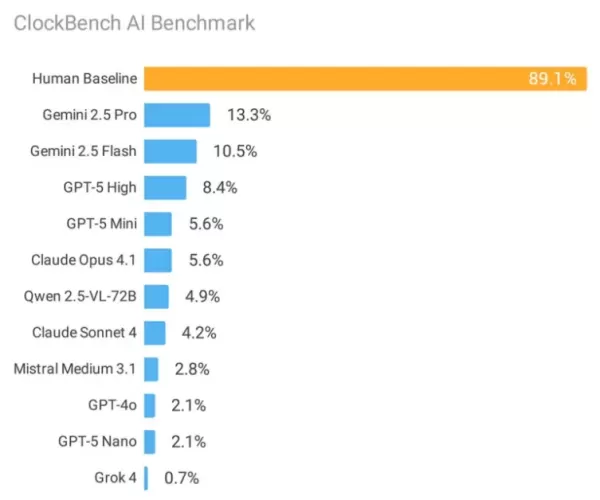
HeimEine bahnbrechende Bewertung, bei der 11 hochmoderne Systeme der künstlichen Intelligenz mit der menschlichen Leistung beim Ablesen analoger Uhren verglichen wurden, hat erhebliche Schwachstellen in den derzeitigen Architekturen des maschinellen Lernens offenbart. Während menschliche Teilnehmer eine bemerkenswerte Genauigkeit von 89,1 % beim Ablesen der Uhrzeit zeigten, erreichte selbst das leistungsstärkste KI-Modell von Google unter identischen Testbedingungen nur eine Erfolgsquote von 13,3 %.
Die von dem Forscher Alek Safar geleitete ClockBench-Untersuchung unterstreicht, dass grundlegende visuelle Denkaufgaben, die Kinder in der Regel beherrschen, auch für die anspruchsvollsten KI-Algorithmen eine Herausforderung darstellen. Die strenge Bewertung untersuchte Plattformen von Branchenführern wie Google, OpenAI und Anthropic unter Verwendung von 180 speziell angefertigten analogen Uhrendesigns.
Die Ergebnisse deuten auf tiefere strukturelle Probleme bei der Verarbeitung und Interpretation visueller Daten durch neuronale Netzwerke hin. "Das genaue Ablesen analoger Uhren erfordert ein ausgeklügeltes räumliches Denken in visuellen Kontexten", erklärt Safar in der veröffentlichten Studie. Der mehrstufige kognitive Prozess umfasst Handerkennung, Positionsanalyse und numerische Umrechnung - Operationen, die kritische KI-Mängel offenbaren.
Der Kontrast in den Fehlermustern ist besonders aufschlussreich. Menschliche Fehler führten in der Regel zu geringfügigen Abweichungen von etwa drei Minuten, während die KI-Systeme sehr ungenaue Schätzungen von durchschnittlich 1 bis 3 Stunden lieferten - was in etwa den zufälligen Schätzungen auf einem Standarduhrblatt entspricht.
Wesentliche Leistungseinschränkungen
Die Plattformen der künstlichen Intelligenz zeigten bemerkenswerte Schwierigkeiten mit:
- Zifferblättern mit römischen Ziffern (nur 3,2 % Genauigkeit)
- Umgekehrte oder gespiegelte Ausrichtungen der Uhr
- Visuell komplexe Hintergründe und künstlerische Designs
- Präzise Messung der Position des Sekundenzeigers
Eine aufschlussreiche Beobachtung: Wenn die KI-Systeme die anfänglichen Uhrenwerte richtig interpretierten, waren sie anschließend bei zeitbasierten Berechnungen wie Umrechnungen und arithmetischen Berechnungen besonders gut. Dies deutet darauf hin, dass das Haupthindernis im visuellen Verständnis und nicht in den mathematischen Verarbeitungsfähigkeiten liegt.
Vergleichende Branchenanalyse
Googles Gemini 2.5 Pro führte die kommerziellen Angebote mit 13,3 % Genauigkeit an, dicht gefolgt von Gemini 2.5 Flash mit 10,5 %. OpenAIs GPT-5 erreichte 8,4 % korrekte Antworten, während die Claude-Modelle von Anthropic mit Claude 4 Sonnet nur 4,2 % und Claude 4.1 Opus 5,6 % erreichten.
Grok 4 von xAI lieferte mit einer Genauigkeit von 0,7 % besonders besorgniserregende Ergebnisse, was in erster Linie darauf zurückzuführen ist, dass 63 % der gültigen Uhrenanzeigen fälschlicherweise als unmögliche Zeiten identifiziert wurden - obwohl nur 20,6 % tatsächlich falsche Konfigurationen enthielten.
Grundlegende Implikationen für den Fortschritt der KI
Diese Forschung erweitert das Paradigma der "Mensch-einfach, KI-komplex"-Benchmarks, das durch Initiativen wie ARC-AGI und SimpleBench veranschaulicht wird. Während künstliche Intelligenz bei zahlreichen wissensbasierten Tests und Berufsprüfungen übermenschliche Leistungen erzielt hat, stellt primitives visuelles Denken eine ständige Herausforderung dar.
Safars Analyse deutet darauf hin, dass die derzeitigen Methoden zur Skalierung der Modellgröße und der Trainingsdaten diese Einschränkungen der visuellen Verarbeitung möglicherweise nicht wirksam angehen. Zu den zwei vermuteten Faktoren gehören die unzureichende Darstellung analoger Uhren in Trainingskorpora und inhärente Schwierigkeiten bei der Übersetzung von räumlichen Beziehungen zwischen grafischen Uhrenkomponenten und textuellen Darstellungen.
ClockBench reiht sich in eine wachsende Reihe von Diagnosetools ein, die dazu dienen, nicht offensichtliche Lücken in der KI-Fähigkeit aufzudecken. Um die Integrität der Bewertung zu wahren, bleibt der gesamte Datensatz eingeschränkt, um eine Kontaminierung des zukünftigen Modelltrainings zu verhindern, wobei nur kontrollierte Teilmengen zur Überprüfung zur Verfügung stehen.
Die Ergebnisse werfen die entscheidende Frage auf, ob inkrementelle Verbesserungen bestehender Architekturen diese Defizite im Denken überbrücken können oder ob grundlegend neue Ansätze erforderlich sind - ähnlich wie bei historischen Durchbrüchen, die durch Innovationen wie die Testzeitberechnung in anderen KI-Bereichen ermöglicht wurden.
Auf absehbare Zeit wird die mechanische Analoguhr ein unerwartet robuster Maßstab für die menschliche Intelligenz sein - eine Technologie, die wir mühelos interpretieren können und die unsere fortschrittlichsten Berechnungen weiterhin vor ein Rätsel stellt.





































