
















 首页
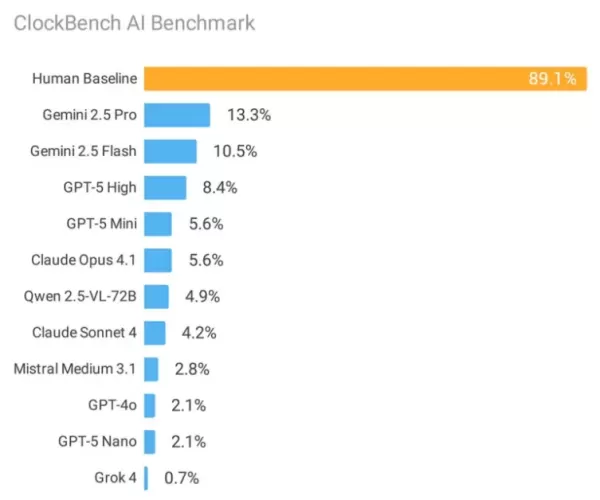
首页一项具有里程碑意义的评估将 11 种尖端人工智能系统与人类读取模拟时钟的表现进行了比较,结果显示,当前的机器学习架构存在重大漏洞。虽然人类参与者在计时方面表现出了 89.1% 的出色准确率,但即使是谷歌表现最出色的人工智能模型,在相同的测试条件下也只取得了 13.3% 的成功率。
由研究员阿列克-萨法尔(Alek Safar)带头进行的 ClockBench 调查强调了儿童通常掌握的基本视觉推理任务如何继续挑战最复杂的人工智能算法。这项严格的评估使用 180 个特别制作的模拟时钟设计,对谷歌、OpenAI 和 Anthropic 等行业领先企业的平台进行了检查。
这些发现指出了神经网络如何处理和解释视觉数据的深层结构问题。"萨法尔在发表的研究报告中解释说:"准确读取模拟时钟需要在视觉环境中进行复杂的空间推理。这个多步骤的认知过程包括手部识别、位置分析和数字转换--这些操作揭示了人工智能的关键缺陷。
事实证明,错误模式的对比尤其具有启发性。人类的错误通常会导致大约三分钟的轻微偏差,而人工智能系统则会产生平均 1-3 小时的严重不准确估计,这实际上相当于在标准钟面上的随机猜测。
关键性能限制
人工智能平台在以下方面表现出明显的困难
- 罗马数字钟面(准确率仅为 3.2)
- 反向或镜像时钟方向
- 视觉上复杂的背景和艺术设计
- 秒针位置的精确测量
我们发现了一个很有说服力的现象:当人工智能系统能够正确解读初始时钟读数时,它们随后在基于时间的计算(如转换和算术)方面表现出色。这表明主要障碍在于视觉理解能力而非数学处理能力。
行业比较分析
谷歌的 Gemini 2.5 Pro 以 13.3% 的准确率领跑商用产品,紧随其后的是 Gemini 2.5 Flash,准确率为 10.5%。OpenAI 的 GPT-5 的正确回答率为 8.4%,而 Anthropic 的 Claude 模型表现不佳,Claude 4 Sonnet 仅为 4.2%,Claude 4.1 Opus 为 5.6%。
xAI 的 Grok 4 得出的结果尤其令人担忧,准确率仅为 0.7%,这主要是由于它错误地将 63% 的有效时钟显示识别为显示不可能的时间--尽管实际上只有 20.6% 的时钟配置不正确。
对人工智能发展的根本影响
这项研究扩展了 ARC-AGI 和 SimpleBench 等计划所体现的 "人类-简单,人工智能-复杂 "基准范式。虽然人工智能已经在众多基于知识的评估和专业考试中取得了超人的成绩,但原始的视觉推理仍面临着持续的挑战。
Safar 的分析表明,当前的模型规模和训练数据扩展方法可能无法有效解决这些视觉处理方面的局限性。两个假设的因素包括:模拟时钟在训练语料库中的代表性不足,以及图形时钟组件和文本表述之间的空间关系转换存在固有困难。
ClockBench 加入了不断扩大的诊断工具套件,旨在发现非显而易见的人工智能能力差距。为了保持评估的完整性,整个数据集仍然受到限制,以防止未来的模型训练受到污染,只有受控样本子集可用于验证。
这些发现提出了一些关键问题,即现有架构的渐进式改进能否弥补这些推理缺陷,或者是否需要从根本上采用新方法--这与其他人工智能领域的创新(如测试时间计算)所带来的历史性突破如出一辙。
在可预见的未来,机械模拟时钟将成为人类智能的一个出乎意料的强大基准--我们可以毫不费力地解读这项技术,但它却一直困惑着我们最先进的计算创造物。





































