
















 家
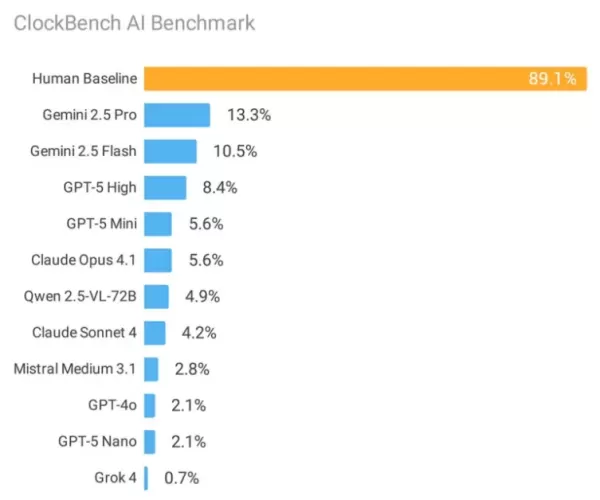
家アナログ時計の読み取りにおいて、11の最先端人工知能システムと人間のパフォーマンスを比較した画期的な評価により、現在の機械学習アーキテクチャの重大な脆弱性が明らかになった。人間の参加者が89.1%という驚異的な正確さを示したのに対し、グーグルの最高性能のAIモデルでさえ、同じテスト条件でわずか13.3%の成功率にとどまった。
研究者のアレック・サファルが率先して行ったClockBenchの調査は、子供たちが通常マスターする基本的な視覚的推論タスクが、いかに最も洗練されたAIアルゴリズムに挑戦し続けているかを明確に示している。この厳密な評価では、グーグル、OpenAI、Anthropicなど業界をリードするプラットフォームが、特別に作られた180個のアナログ時計のデザインを用いて検証された。
これらの知見は、ニューラルネットワークが視覚データを処理・解釈する方法における、より深い構造的問題を指摘している。「アナログ時計を正確に読み取るには、視覚的な文脈の中で洗練された空間的推論が必要です」とサファル氏は発表された研究の中で説明している。この多段階の認知プロセスには、手の認識、位置分析、数値変換が含まれる。
エラーのパターンのコントラストが特に明らかになった。人間のミスは通常、約3分のわずかなズレをもたらしたが、AIシステムは平均1~3時間という不正確な見積もりを出した。
主なパフォーマンスの限界
人工知能プラットフォームは、以下の点で顕著な困難を示した:
- ローマ数字の時計の文字盤(わずか3.2%の精度しか達成できなかった)
- 時計の向きが逆または鏡面
- 視覚的に複雑な背景や芸術的なデザイン
- 秒針の位置の正確な測定
AIシステムが最初の時計の読み方を正しく解釈した場合、その後、変換や算術のような時間ベースの計算を得意とするようになった。これは、数学的な処理能力よりも、視覚的な理解力に主な障害があることを示している。
業界比較分析
GoogleのGemini 2.5 Proが13.3%の精度で商用製品をリードし、僅差でGemini 2.5 Flashが10.5%で続いた。OpenAIのGPT-5は8.4%の正答率を達成したが、AnthropicのClaudeモデルは、Claude 4 Sonnetが4.2%、Claude 4.1 Opusが5.6%にとどまり、パフォーマンスを落とした。
xAIのGrok 4は0.7%の精度で特に気になる結果を出したが、その主な原因は、有効な時計表示の63%を不可能な時間を示していると誤って認識したことである。
AIの進歩に対する基本的な意味合い
この研究は、ARC-AGIやSimpleBenchのようなイニシアチブに代表される「人間-単純、AI-複雑」ベンチマークのパラダイムを拡張するものである。人工知能は多くの知識ベースの評価や専門的な試験で超人的なパフォーマンスを達成しているが、原始的な視覚的推論には根強い課題がある。
Safarの分析によると、モデルサイズや学習データを拡張する現在の方法論では、こうした視覚処理の限界に効果的に対処できない可能性がある。トレーニング・コーパスにおけるアナログ時計の表現が不十分であること、グラフィカルな時計コンポーネントとテキスト表現間の空間的関係を翻訳することが困難であることが、2つの要因であると考えられる。
ClockBenchは、明らかでないAI能力のギャップを明らかにするために設計された診断ツールの拡張スイートに加わります。評価の完全性を維持するため、将来のモデルトレーニングの汚染を防ぐために、全データセットは制限されたままであり、検証のために利用できるのは制御されたサンプルのサブセットのみである。
この発見は、既存のアーキテクチャの段階的な改善によって推論の欠陥を埋めることができるのか、それとも根本的に新しいアプローチが必要なのかについて、重要な問題を提起している。
当面の間、機械式アナログ時計は、人間の知能の予想外に頑健なベンチマークとして立ちはだかる。私たちが難なく解釈できる技術でありながら、最先端の計算創造物を困惑させ続けているのだ。





































