
















 Home
HomeGoogle's GEPA Enhances LLM Performance, Bypassing Expensive Reinforcement Learning Needs
Researchers from UC Berkeley, Stanford University, and Databricks have introduced a new AI optimization method called GEPA, which demonstrates remarkable improvements over traditional reinforcement learning techniques for adapting large language models to specialized tasks.
GEPA departs from the conventional approach of learning through thousands of trial-and-error attempts driven by simple numerical scores. Instead, it uses an LLM's internal language capabilities to analyze its performance, identify mistakes, and progressively refine its instructions. Beyond achieving higher accuracy than established methods, GEPA is far more efficient, delivering superior outcomes with up to 35 times fewer trial runs.
For companies developing complex AI agents and workflows, this breakthrough means faster development, significantly lower computing costs, and more powerful, dependable applications.
The High Cost of Optimizing Modern AI Systems
Modern enterprise AI applications seldom rely on a single call to an LLM. They are typically "compound AI systems"—sophisticated workflows that combine multiple LLM modules, external tools like databases or code interpreters, and custom logic to execute complex tasks, such as multi-step research and data analysis.
A common optimization strategy for these systems is reinforcement learning, exemplified by techniques like Group Relative Policy Optimization used in advanced reasoning models. These methods treat the AI system as a black box, assessing a task through a basic success metric. This limited feedback is then used to gradually adjust the model’s parameters toward better performance.
RL's primary limitation is its inefficiency. To learn effectively from minimal numerical scores, RL often requires tens or even hundreds of thousands of trial runs. For any real-world enterprise application involving costly tool calls or proprietary models, this process is prohibitively slow and expensive.
As explained by Lakshya A Agrawal, a co-author and doctoral student at UC Berkeley, this complexity presents a major obstacle for many organizations. "For numerous teams, RL is impractical due to its expense and complexity—their default approach has largely been manual prompt engineering," Agrawal noted. GEPA is designed for teams working with high-performance models that often cannot be fine-tuned, allowing them to enhance performance without managing specialized hardware.
The research team frames the challenge this way: "How can we extract the maximum learning signal from every costly trial to enable effective adaptation of complex, modular AI systems under tight data or budget constraints?"
An Optimizer That Learns Through Language

GEPA framework Source: arXiv GEPA addresses this challenge by replacing sparse reward signals with detailed, natural language feedback. It capitalizes on the fact that an AI system's entire execution—its reasoning steps, tool calls, and error messages—can be represented as text for an LLM to process. This methodology is founded on three core principles.
The first is "genetic prompt evolution," where GEPA treats a set of prompts as a gene pool, iteratively modifying them to generate new and potentially improved versions. This mutation process is guided by the second principle: "reflection with natural language feedback." After several trial runs, GEPA presents an LLM with the complete execution history and outcomes. The LLM then analyzes this information to diagnose issues and draft a more precise, enhanced prompt. For example, instead of just receiving a low score for code generation, it might examine a compiler error and determine that the prompt must specify a particular library version.
The third principle is "Pareto-based selection," which promotes intelligent exploration. Instead of solely focusing on the single highest-scoring prompt, which risks settling for a suboptimal solution, GEPA maintains a diverse collection of specialized prompts. It identifies which prompts excel on different test cases, compiling a roster of leading candidates. By sampling from this variety of successful strategies, GEPA explores a broader solution space and is more likely to discover a prompt that performs well across diverse inputs.

Focusing on a single top candidate can trap models in local minima, while Pareto selection explores more options to find optimal solutions Source: arXiv The success of this entire process depends on what the researchers term "feedback engineering." Agrawal emphasizes that the key is to capture the rich textual details systems already produce but often ignore. "Conventional pipelines typically condense this information into a single numerical reward, hiding the reasons behind specific outcomes," he explained. "GEPA’s core approach is to structure feedback that reveals not just final results but also intermediate steps and errors in plain text—the same evidence a human expert would use to analyze system behavior."
For instance, for a document retrieval system, this would involve listing which documents were correctly retrieved and which were missed, rather than only reporting a final accuracy score.
GEPA in Practice
The research team evaluated GEPA across four distinct tasks, from multi-hop question answering to privacy-preserving queries. They tested both open-source and proprietary models, comparing GEPA against RL-based GRPO and the advanced prompt optimizer MIPROv2.
Across all evaluations, GEPA significantly outperformed GRPO, achieving up to a 19% improvement in score while using up to 35 times fewer trial runs. Agrawal illustrated this efficiency with a specific example: "We optimized a question-answering system with GEPA in about 3 hours, compared to GRPO’s 24 hours—an eightfold reduction in development time, paired with a 20% performance gain," he stated. "RL-based optimization for the same test scenario cost around $300 in GPU compute, while GEPA achieved better results for under $20—a 15-fold cost reduction in our experiments."
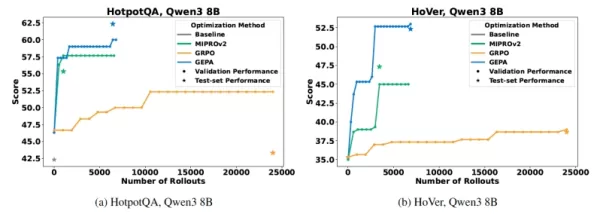
GEPA outperforms other benchmark methods on key performance measures Source: arXiv Beyond raw metrics, the researchers observed that GEPA-optimized systems are more reliable when handling new, unseen data, as indicated by a smaller "generalization gap." Agrawal suggests this improved robustness stems from GEPA learning from richer feedback. "GEPA’s smaller generalization gap likely comes from its use of detailed natural-language feedback on each outcome—clarifying what succeeded, what failed, and why—instead of relying on a single numerical score," he said. "This encourages the system to develop instructions and strategies based on a comprehensive understanding of success, rather than simply memorizing patterns from the training data." For businesses, this enhanced reliability translates to more robust and adaptable AI applications in customer-facing scenarios.
A key practical advantage is that GEPA's final instructions are up to 9.2 times shorter than prompts generated by optimizers like MIPROv2, which often include numerous examples. Shorter prompts reduce latency and lower costs for API-based models, making the final application both faster and more economical to run in production.
The paper also explores promising applications of GEPA as an "inference-time" search strategy, transforming an AI from a single-step answer generator into an iterative problem solver. Agrawal described a potential integration into a company’s development pipeline, where GEPA could automatically create and refine multiple optimized versions of a system, test their performance, and submit the best variant for engineering review. "This turns optimization into a continuous, automated process—quickly producing solutions that often meet or exceed the quality of expert manual tuning," Agrawal added. In tests on CUDA code generation, this method elevated performance to an expert level on 20% of tasks, compared to 0% for a single attempt with a model like GPT-4o.
The authors view GEPA as a foundational step toward a new paradigm in AI development. However, beyond fostering more human-like AI, its most immediate impact may be in democratizing the creation of high-performance systems.
"We anticipate GEPA will foster a positive shift in AI system construction—making optimization accessible to end-users who possess deep domain expertise for the task but may lack the time or desire to master complex RL techniques," Agrawal concluded. "It empowers the stakeholders who have the precise, task-specific knowledge."
Related article
 China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Related Special Topic Recommendations
writing
China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Related Special Topic Recommendations
writing
 Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
Discover the 2026 best AI assistants for crafting epic xianxia & wuxia tales. XIX.AI's curated list features top-rated, game-changing tools to master cultivation progression and martial arts choreography. Compare free vs paid options with real-world tests. Unlock your creative potential and start writing today!
 10 tools
10 tools
 xix.ai
code
AI Mobile App Coding Tools: Generate Cross-Platform Flutter & React Native Code from Prompts
xix.ai
code
AI Mobile App Coding Tools: Generate Cross-Platform Flutter & React Native Code from Prompts
Discover the 2026 best AI mobile app coding tools for Flutter & React Native. Our curated, top-rated list features powerful, game-changing solutions that generate cross-platform code from prompts. Compare free vs paid options with real-world tests. Unlock faster development and build better apps. Explore the rankings on XIX.AI now!
10 tools
xix.ai
code
Best AI Chrome Extension Generators: Create Custom Browser Add-ons with Zero Coding Experience
Discover the 2026 best AI Chrome extension generators on XIX.AI. Our curated list features top-rated, must-try tools that let you create custom browser add-ons with zero coding. Compare free vs paid options, see real-world tests, and unlock your productivity. Explore the latest rankings and find your perfect tool today!
10 tools
xix.ai
Text-to-speech
Best AI Multilingual TTS: Generate Authentic Native-Accent Speech in 50+ Languages
Discover the 2026 best AI multilingual TTS tools for authentic native-accent speech in 50+ languages. Explore our top-rated, curated rankings with free vs paid comparisons and real-world tests. Find your perfect voice tool on XIX.AI and unlock global communication today.
10 tools
xix.ai
Meeting Assistant
Best AI Meeting Automation Tools for Smarter and Faster Collaboration
Discover the 2026 latest top-rated AI meeting automation tools for smarter, faster collaboration. Our curated list features powerful, game-changing solutions to automate notes, summaries, and action items. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock peak team productivity. Explore the best picks now at XIX.AI.
10 tools
xix.ai
Prompt
AI Prompts for Infrastructure-as-Code: Deploy Terraform & Docker Configurations Safely
Discover the 2026 latest top-rated AI prompts for Infrastructure-as-Code. XIX.AI's curated selection helps you safely deploy Terraform & Docker configurations, automate cloud setups, and boost DevOps productivity. Compare free vs paid options with real-world tests. Explore now and unlock your AI edge.
10 tools
xix.ai

 Comments (0)
0/500
Comments (0)
0/500
Researchers from UC Berkeley, Stanford University, and Databricks have introduced a new AI optimization method called GEPA, which demonstrates remarkable improvements over traditional reinforcement learning techniques for adapting large language models to specialized tasks.
GEPA departs from the conventional approach of learning through thousands of trial-and-error attempts driven by simple numerical scores. Instead, it uses an LLM's internal language capabilities to analyze its performance, identify mistakes, and progressively refine its instructions. Beyond achieving higher accuracy than established methods, GEPA is far more efficient, delivering superior outcomes with up to 35 times fewer trial runs.
For companies developing complex AI agents and workflows, this breakthrough means faster development, significantly lower computing costs, and more powerful, dependable applications.
The High Cost of Optimizing Modern AI Systems
Modern enterprise AI applications seldom rely on a single call to an LLM. They are typically "compound AI systems"—sophisticated workflows that combine multiple LLM modules, external tools like databases or code interpreters, and custom logic to execute complex tasks, such as multi-step research and data analysis.
A common optimization strategy for these systems is reinforcement learning, exemplified by techniques like Group Relative Policy Optimization used in advanced reasoning models. These methods treat the AI system as a black box, assessing a task through a basic success metric. This limited feedback is then used to gradually adjust the model’s parameters toward better performance.
RL's primary limitation is its inefficiency. To learn effectively from minimal numerical scores, RL often requires tens or even hundreds of thousands of trial runs. For any real-world enterprise application involving costly tool calls or proprietary models, this process is prohibitively slow and expensive.
As explained by Lakshya A Agrawal, a co-author and doctoral student at UC Berkeley, this complexity presents a major obstacle for many organizations. "For numerous teams, RL is impractical due to its expense and complexity—their default approach has largely been manual prompt engineering," Agrawal noted. GEPA is designed for teams working with high-performance models that often cannot be fine-tuned, allowing them to enhance performance without managing specialized hardware.
The research team frames the challenge this way: "How can we extract the maximum learning signal from every costly trial to enable effective adaptation of complex, modular AI systems under tight data or budget constraints?"
An Optimizer That Learns Through Language
GEPA addresses this challenge by replacing sparse reward signals with detailed, natural language feedback. It capitalizes on the fact that an AI system's entire execution—its reasoning steps, tool calls, and error messages—can be represented as text for an LLM to process. This methodology is founded on three core principles.
The first is "genetic prompt evolution," where GEPA treats a set of prompts as a gene pool, iteratively modifying them to generate new and potentially improved versions. This mutation process is guided by the second principle: "reflection with natural language feedback." After several trial runs, GEPA presents an LLM with the complete execution history and outcomes. The LLM then analyzes this information to diagnose issues and draft a more precise, enhanced prompt. For example, instead of just receiving a low score for code generation, it might examine a compiler error and determine that the prompt must specify a particular library version.
The third principle is "Pareto-based selection," which promotes intelligent exploration. Instead of solely focusing on the single highest-scoring prompt, which risks settling for a suboptimal solution, GEPA maintains a diverse collection of specialized prompts. It identifies which prompts excel on different test cases, compiling a roster of leading candidates. By sampling from this variety of successful strategies, GEPA explores a broader solution space and is more likely to discover a prompt that performs well across diverse inputs.
The success of this entire process depends on what the researchers term "feedback engineering." Agrawal emphasizes that the key is to capture the rich textual details systems already produce but often ignore. "Conventional pipelines typically condense this information into a single numerical reward, hiding the reasons behind specific outcomes," he explained. "GEPA’s core approach is to structure feedback that reveals not just final results but also intermediate steps and errors in plain text—the same evidence a human expert would use to analyze system behavior."
For instance, for a document retrieval system, this would involve listing which documents were correctly retrieved and which were missed, rather than only reporting a final accuracy score.
GEPA in Practice
The research team evaluated GEPA across four distinct tasks, from multi-hop question answering to privacy-preserving queries. They tested both open-source and proprietary models, comparing GEPA against RL-based GRPO and the advanced prompt optimizer MIPROv2.
Across all evaluations, GEPA significantly outperformed GRPO, achieving up to a 19% improvement in score while using up to 35 times fewer trial runs. Agrawal illustrated this efficiency with a specific example: "We optimized a question-answering system with GEPA in about 3 hours, compared to GRPO’s 24 hours—an eightfold reduction in development time, paired with a 20% performance gain," he stated. "RL-based optimization for the same test scenario cost around $300 in GPU compute, while GEPA achieved better results for under $20—a 15-fold cost reduction in our experiments."
Beyond raw metrics, the researchers observed that GEPA-optimized systems are more reliable when handling new, unseen data, as indicated by a smaller "generalization gap." Agrawal suggests this improved robustness stems from GEPA learning from richer feedback. "GEPA’s smaller generalization gap likely comes from its use of detailed natural-language feedback on each outcome—clarifying what succeeded, what failed, and why—instead of relying on a single numerical score," he said. "This encourages the system to develop instructions and strategies based on a comprehensive understanding of success, rather than simply memorizing patterns from the training data." For businesses, this enhanced reliability translates to more robust and adaptable AI applications in customer-facing scenarios.
A key practical advantage is that GEPA's final instructions are up to 9.2 times shorter than prompts generated by optimizers like MIPROv2, which often include numerous examples. Shorter prompts reduce latency and lower costs for API-based models, making the final application both faster and more economical to run in production.
The paper also explores promising applications of GEPA as an "inference-time" search strategy, transforming an AI from a single-step answer generator into an iterative problem solver. Agrawal described a potential integration into a company’s development pipeline, where GEPA could automatically create and refine multiple optimized versions of a system, test their performance, and submit the best variant for engineering review. "This turns optimization into a continuous, automated process—quickly producing solutions that often meet or exceed the quality of expert manual tuning," Agrawal added. In tests on CUDA code generation, this method elevated performance to an expert level on 20% of tasks, compared to 0% for a single attempt with a model like GPT-4o.
The authors view GEPA as a foundational step toward a new paradigm in AI development. However, beyond fostering more human-like AI, its most immediate impact may be in democratizing the creation of high-performance systems.
"We anticipate GEPA will foster a positive shift in AI system construction—making optimization accessible to end-users who possess deep domain expertise for the task but may lack the time or desire to master complex RL techniques," Agrawal concluded. "It empowers the stakeholders who have the precise, task-specific knowledge."










 China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
China Telecom Invests in Mianbi Intelligence, Raises Capital to 713,000 Yuan for LLM & Data Infra
The "national team" and the leading figure from Tsinghua University in the large model space are deepening their strategic alignment. On March 1, 2026, according to the latest business registration data from Qichacha, Beijing Mianbi Intelligent Techn
 Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
Taotian Group Accelerates AI-Native Restructuring, Grants Interns Free Token Quotas
TaoTian Group recently introduced the "AI Productivity Plan," designed to accelerate the integration of AI technology into e-commerce operations and R&D workflows through resource allocation and tool subsidies. The program is now available to all int
 Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i
Glean targets enterprise AI infrastructure in land grab
The race to dominate enterprise AI is accelerating. Microsoft is embedding Copilot into Office, Google is integrating Gemini into Workspace, and both OpenAI and Anthropic are selling directly to corporations. Meanwhile, nearly every SaaS vendor now i

Discover the 2026 best AI assistants for crafting epic xianxia & wuxia tales. XIX.AI's curated list features top-rated, game-changing tools to master cultivation progression and martial arts choreography. Compare free vs paid options with real-world tests. Unlock your creative potential and start writing today!
10 tools
xix.ai

Discover the 2026 best AI mobile app coding tools for Flutter & React Native. Our curated, top-rated list features powerful, game-changing solutions that generate cross-platform code from prompts. Compare free vs paid options with real-world tests. Unlock faster development and build better apps. Explore the rankings on XIX.AI now!
10 tools
xix.ai

Discover the 2026 best AI Chrome extension generators on XIX.AI. Our curated list features top-rated, must-try tools that let you create custom browser add-ons with zero coding. Compare free vs paid options, see real-world tests, and unlock your productivity. Explore the latest rankings and find your perfect tool today!
10 tools
xix.ai

Discover the 2026 best AI multilingual TTS tools for authentic native-accent speech in 50+ languages. Explore our top-rated, curated rankings with free vs paid comparisons and real-world tests. Find your perfect voice tool on XIX.AI and unlock global communication today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI meeting automation tools for smarter, faster collaboration. Our curated list features powerful, game-changing solutions to automate notes, summaries, and action items. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock peak team productivity. Explore the best picks now at XIX.AI.
10 tools
xix.ai

Discover the 2026 latest top-rated AI prompts for Infrastructure-as-Code. XIX.AI's curated selection helps you safely deploy Terraform & Docker configurations, automate cloud setups, and boost DevOps productivity. Compare free vs paid options with real-world tests. Explore now and unlock your AI edge.
10 tools
xix.ai













