
















 Heim
Heim
Googles GEPA verbessert die LLM-Leistung und umgeht die teuren Anforderungen des Reinforcement Learning
Forscher der UC Berkeley, der Stanford University und von Databricks haben eine neue KI-Optimierungsmethode namens GEPA vorgestellt, die bemerkenswerte Verbesserungen im Vergleich zu herkömmlichen Reinforcement-Learning-Techniken für die Anpassung großer Sprachmodelle an spezielle Aufgaben zeigt.
GEPA weicht vom konventionellen Ansatz des Lernens durch Tausende von Versuch-und-Irrtum-Versuchen ab, die durch einfache numerische Werte gesteuert werden. Stattdessen nutzt es die internen Sprachfähigkeiten eines LLM, um seine Leistung zu analysieren, Fehler zu erkennen und seine Anweisungen schrittweise zu verfeinern. GEPA erreicht nicht nur eine höhere Genauigkeit als herkömmliche Methoden, sondern ist auch weitaus effizienter und liefert mit bis zu 35 Mal weniger Versuchsdurchläufen bessere Ergebnisse.
Für Unternehmen, die komplexe KI-Agenten und -Workflows entwickeln, bedeutet dieser Durchbruch eine schnellere Entwicklung, deutlich geringere Rechenkosten und leistungsfähigere, zuverlässigere Anwendungen.
Die hohen Kosten für die Optimierung moderner KI-Systeme
Moderne KI-Anwendungen für Unternehmen basieren selten auf einem einzigen Aufruf eines LLM. Es handelt sich in der Regel um "zusammengesetzte KI-Systeme" - ausgefeilte Workflows, die mehrere LLM-Module, externe Tools wie Datenbanken oder Code-Interpreter und benutzerdefinierte Logik kombinieren, um komplexe Aufgaben wie mehrstufige Recherchen und Datenanalysen durchzuführen.
Eine gängige Optimierungsstrategie für diese Systeme ist das Reinforcement Learning, das durch Techniken wie Group Relative Policy Optimization in fortgeschrittenen Argumentationsmodellen veranschaulicht wird. Bei diesen Methoden wird das KI-System wie eine Blackbox behandelt, die eine Aufgabe anhand einer grundlegenden Erfolgsmetrik bewertet. Diese begrenzte Rückmeldung wird dann verwendet, um die Parameter des Modells schrittweise an eine bessere Leistung anzupassen.
Die wichtigste Einschränkung von RL ist seine Ineffizienz. Um effektiv aus minimalen numerischen Werten zu lernen, erfordert RL oft zehn- oder sogar hunderttausende von Testläufen. Für jede reale Unternehmensanwendung, die kostspielige Tool-Aufrufe oder proprietäre Modelle beinhaltet, ist dieser Prozess unerschwinglich langsam und teuer.
Wie Lakshya A. Agrawal, Mitautor und Doktorand an der UC Berkeley, erklärt, stellt diese Komplexität für viele Unternehmen ein großes Hindernis dar. "Für zahlreiche Teams ist RL aufgrund der Kosten und der Komplexität nicht praktikabel - ihr Standardansatz ist weitgehend die manuelle Eingabeaufforderung", so Agrawal. GEPA wurde für Teams entwickelt, die mit Hochleistungsmodellen arbeiten, die oft nicht feinabgestimmt werden können, und ermöglicht es ihnen, die Leistung zu verbessern, ohne spezielle Hardware zu verwalten.
Das Forschungsteam formuliert die Herausforderung wie folgt: "Wie können wir das maximale Lernsignal aus jedem kostspieligen Versuch extrahieren, um eine effektive Anpassung von komplexen, modularen KI-Systemen unter engen Daten- oder Budgetbeschränkungen zu ermöglichen?"
Ein Optimierer, der durch Sprache lernt

GEPA-Rahmenwerk Quelle: arXiv GEPA geht diese Herausforderung an, indem es die spärlichen Belohnungssignale durch detaillierte, natürlichsprachliche Rückmeldungen ersetzt. Es macht sich die Tatsache zunutze, dass die gesamte Ausführung eines KI-Systems - seine Argumentationsschritte, Werkzeugaufrufe und Fehlermeldungen - als Text dargestellt werden kann, den ein LLM verarbeiten kann. Diese Methodik basiert auf drei Grundprinzipien.
Das erste ist die "genetische Prompt-Evolution", bei der GEPA eine Reihe von Prompts als Genpool behandelt und sie iterativ modifiziert, um neue und möglicherweise verbesserte Versionen zu erzeugen. Dieser Mutationsprozess wird durch das zweite Prinzip geleitet: "Reflexion mit natürlichem Sprachfeedback". Nach mehreren Versuchsläufen legt GEPA einem LLM die vollständige Ausführungshistorie und die Ergebnisse vor. Der LLM analysiert dann diese Informationen, um Probleme zu diagnostizieren und eine präzisere, verbesserte Aufforderung zu verfassen. Anstatt beispielsweise nur eine niedrige Punktzahl für die Codegenerierung zu erhalten, könnte er einen Compilerfehler untersuchen und feststellen, dass die Eingabeaufforderung eine bestimmte Bibliotheksversion angeben muss.
Das dritte Prinzip ist die "Pareto-basierte Auswahl", die eine intelligente Erkundung fördert. Anstatt sich ausschließlich auf die einzige Eingabeaufforderung mit der höchsten Punktzahl zu konzentrieren, was das Risiko birgt, sich mit einer suboptimalen Lösung zufrieden zu geben, unterhält GEPA eine vielfältige Sammlung spezialisierter Eingabeaufforderungen. Es ermittelt, welche Prompts in verschiedenen Testfällen besonders gut abschneiden, und stellt so eine Liste der führenden Kandidaten zusammen. Durch die Auswahl aus dieser Vielzahl erfolgreicher Strategien erkundet GEPA einen breiteren Lösungsraum und findet mit größerer Wahrscheinlichkeit eine Aufforderung, die bei verschiedenen Eingaben gut funktioniert.

Die Konzentration auf einen einzigen Spitzenkandidaten kann dazu führen, dass Modelle in lokalen Minima gefangen sind, während die Pareto-Auswahl mehr Optionen untersucht, um optimale Lösungen zu finden Quelle: arXiv Der Erfolg dieses gesamten Prozesses hängt von dem ab, was die Forscher "Feedback Engineering" nennen. Agrawal betont, dass der Schlüssel darin liegt, die reichhaltigen textuellen Details zu erfassen, die Systeme bereits produzieren, aber oft ignorieren. "Herkömmliche Pipelines verdichten diese Informationen in der Regel zu einer einzigen numerischen Belohnung und verbergen die Gründe für bestimmte Ergebnisse", erklärt er. "Der Kernansatz der GEPA besteht darin, ein Feedback zu strukturieren, das nicht nur die Endergebnisse, sondern auch Zwischenschritte und Fehler im Klartext aufzeigt - dieselben Informationen, die ein menschlicher Experte zur Analyse des Systemverhaltens verwenden würde."
Bei einem System zur Dokumentensuche würde dies beispielsweise bedeuten, dass aufgelistet wird, welche Dokumente korrekt abgerufen wurden und welche nicht, anstatt nur eine endgültige Trefferquote zu melden.
GEPA in der Praxis
Das Forschungsteam bewertete GEPA anhand von vier verschiedenen Aufgaben, von der Beantwortung von Multi-Hop-Fragen bis zu datenschutzfreundlichen Abfragen. Sie testeten sowohl Open-Source- als auch proprietäre Modelle und verglichen GEPA mit dem RL-basierten GRPO und dem erweiterten Prompt-Optimierer MIPROv2.
Bei allen Evaluierungen schnitt GEPA deutlich besser ab als GRPO und erzielte eine Verbesserung der Punktzahl um bis zu 19 %, wobei bis zu 35 Mal weniger Testläufe erforderlich waren. Agrawal veranschaulichte diese Effizienz anhand eines konkreten Beispiels: "Wir haben ein Frage-Antwort-System mit GEPA in etwa 3 Stunden optimiert, im Vergleich zu 24 Stunden mit GRPO - eine achtfache Reduzierung der Entwicklungszeit, gepaart mit einem Leistungsgewinn von 20 %", erklärte er. "Die RL-basierte Optimierung für dasselbe Testszenario kostete rund 300 Dollar an GPU-Rechenleistung, während GEPA bessere Ergebnisse für weniger als 20 Dollar erzielte - eine 15-fache Kostenreduzierung in unseren Experimenten."
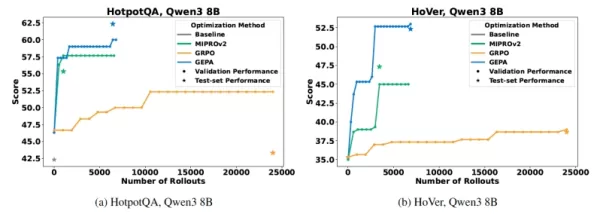
GEPA übertrifft andere Benchmark-Methoden bei wichtigen Leistungskennzahlen Quelle: arXiv Über die reinen Kennzahlen hinaus beobachteten die Forscher, dass GEPA-optimierte Systeme zuverlässiger im Umgang mit neuen, ungesehenen Daten sind, was sich in einer geringeren "Generalisierungslücke" zeigt. Agrawal vermutet, dass diese verbesserte Robustheit darauf zurückzuführen ist, dass GEPA aus umfangreicheren Rückmeldungen lernt. "Die geringere Verallgemeinerungslücke von GEPA ist wahrscheinlich darauf zurückzuführen, dass das System detaillierte Rückmeldungen in natürlicher Sprache zu den einzelnen Ergebnissen gibt - was erfolgreich war, was nicht und warum - anstatt sich auf eine einzige numerische Punktzahl zu verlassen", sagte er. "Dies ermutigt das System, Anweisungen und Strategien auf der Grundlage eines umfassenden Verständnisses von Erfolg zu entwickeln, anstatt einfach nur Muster aus den Trainingsdaten auswendig zu lernen. Für Unternehmen bedeutet diese verbesserte Zuverlässigkeit robustere und anpassungsfähigere KI-Anwendungen in Szenarien mit Kundenkontakt.
Ein wichtiger praktischer Vorteil ist, dass die endgültigen Anweisungen von GEPA bis zu 9,2 Mal kürzer sind als die von Optimierern wie MIPROv2 generierten Prompts, die oft zahlreiche Beispiele enthalten. Kürzere Prompts verringern die Latenzzeit und senken die Kosten für API-basierte Modelle, wodurch die endgültige Anwendung sowohl schneller als auch wirtschaftlicher in der Produktion ausgeführt werden kann.
Das Papier untersucht auch vielversprechende Anwendungen von GEPA als "Inferenzzeit"-Suchstrategie, die eine KI von einem einstufigen Antwortgenerator in einen iterativen Problemlöser verwandelt. Agrawal beschrieb eine mögliche Integration in die Entwicklungspipeline eines Unternehmens, bei der GEPA automatisch mehrere optimierte Versionen eines Systems erstellen und verfeinern, ihre Leistung testen und die beste Variante zur technischen Prüfung vorlegen könnte. "Dadurch wird die Optimierung zu einem kontinuierlichen, automatisierten Prozess, der schnell Lösungen hervorbringt, die oft die Qualität der manuellen Abstimmung durch Experten erreichen oder übertreffen", fügte Agrawal hinzu. In Tests zur CUDA-Code-Generierung konnte diese Methode die Leistung bei 20 % der Aufgaben auf ein Expertenniveau anheben, verglichen mit 0 % bei einem einzigen Versuch mit einem Modell wie GPT-4o.
Die Autoren betrachten GEPA als einen grundlegenden Schritt in Richtung eines neuen Paradigmas in der KI-Entwicklung. Neben der Förderung einer menschenähnlicheren KI könnte seine unmittelbarste Auswirkung jedoch in der Demokratisierung der Entwicklung von Hochleistungssystemen liegen.
"Wir gehen davon aus, dass GEPA einen positiven Wandel in der Konstruktion von KI-Systemen herbeiführen wird, indem es die Optimierung für Endnutzer zugänglich macht, die zwar über tiefes Fachwissen für diese Aufgabe verfügen, aber vielleicht nicht die Zeit oder den Wunsch haben, komplexe RL-Techniken zu beherrschen", so Agrawal abschließend. "Es befähigt die Akteure, die über das präzise, aufgabenspezifische Wissen verfügen."
Verwandter Artikel
 Claude Opus 4.7 startet mit dem Grundsatz, dass Zuverlässigkeit vor Intelligenz geht
Anthropic hat in diesem Jahr ein hohes Tempo beibehalten und fast jeden zweiten Tag neue Funktionen eingeführt. Das mit Spannung erwartete Claude Opus 4.7 wurde soeben offiziell veröffentlicht, und in
Haier bringt den weltweit leichtesten KI-Sport-Exoskelett-Roboter mit einem Gewicht von nur 1,75 kg auf den Markt
Die Haier Group hat den weltweit leichtesten KI-gestützten Exoskelett-Roboter für den Sport vorgestellt – den Haier Exoskeleton Robot W3. Diese Markteinführung stellt einen neuen Branchenrekord in Sac
Yaoke Medias erste AIGC-Serie „Das Geheimnis der Bronzefiguren im Qinling-Gebirge“ startet heute mit KI-generierten Hauptdarstellern
Heute ist der offizielle Starttag von Yaoke Medias AIGC-Fantasy-Mystery-Kurzserie „Die geheime Geschichte der Qinling-Bronze“. Mit den ersten beiden unter Vertrag genommenen KI-Schauspielern des Unter
Empfehlungen zu verwandten Spezialthemen
Geschäft
Claude Opus 4.7 startet mit dem Grundsatz, dass Zuverlässigkeit vor Intelligenz geht
Anthropic hat in diesem Jahr ein hohes Tempo beibehalten und fast jeden zweiten Tag neue Funktionen eingeführt. Das mit Spannung erwartete Claude Opus 4.7 wurde soeben offiziell veröffentlicht, und in
Haier bringt den weltweit leichtesten KI-Sport-Exoskelett-Roboter mit einem Gewicht von nur 1,75 kg auf den Markt
Die Haier Group hat den weltweit leichtesten KI-gestützten Exoskelett-Roboter für den Sport vorgestellt – den Haier Exoskeleton Robot W3. Diese Markteinführung stellt einen neuen Branchenrekord in Sac
Yaoke Medias erste AIGC-Serie „Das Geheimnis der Bronzefiguren im Qinling-Gebirge“ startet heute mit KI-generierten Hauptdarstellern
Heute ist der offizielle Starttag von Yaoke Medias AIGC-Fantasy-Mystery-Kurzserie „Die geheime Geschichte der Qinling-Bronze“. Mit den ersten beiden unter Vertrag genommenen KI-Schauspielern des Unter
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
 10 Tools
10 Tools
 xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

 Kommentare (0)
Kommentare (0)
Forscher der UC Berkeley, der Stanford University und von Databricks haben eine neue KI-Optimierungsmethode namens GEPA vorgestellt, die bemerkenswerte Verbesserungen im Vergleich zu herkömmlichen Reinforcement-Learning-Techniken für die Anpassung großer Sprachmodelle an spezielle Aufgaben zeigt.
GEPA weicht vom konventionellen Ansatz des Lernens durch Tausende von Versuch-und-Irrtum-Versuchen ab, die durch einfache numerische Werte gesteuert werden. Stattdessen nutzt es die internen Sprachfähigkeiten eines LLM, um seine Leistung zu analysieren, Fehler zu erkennen und seine Anweisungen schrittweise zu verfeinern. GEPA erreicht nicht nur eine höhere Genauigkeit als herkömmliche Methoden, sondern ist auch weitaus effizienter und liefert mit bis zu 35 Mal weniger Versuchsdurchläufen bessere Ergebnisse.
Für Unternehmen, die komplexe KI-Agenten und -Workflows entwickeln, bedeutet dieser Durchbruch eine schnellere Entwicklung, deutlich geringere Rechenkosten und leistungsfähigere, zuverlässigere Anwendungen.
Die hohen Kosten für die Optimierung moderner KI-Systeme
Moderne KI-Anwendungen für Unternehmen basieren selten auf einem einzigen Aufruf eines LLM. Es handelt sich in der Regel um "zusammengesetzte KI-Systeme" - ausgefeilte Workflows, die mehrere LLM-Module, externe Tools wie Datenbanken oder Code-Interpreter und benutzerdefinierte Logik kombinieren, um komplexe Aufgaben wie mehrstufige Recherchen und Datenanalysen durchzuführen.
Eine gängige Optimierungsstrategie für diese Systeme ist das Reinforcement Learning, das durch Techniken wie Group Relative Policy Optimization in fortgeschrittenen Argumentationsmodellen veranschaulicht wird. Bei diesen Methoden wird das KI-System wie eine Blackbox behandelt, die eine Aufgabe anhand einer grundlegenden Erfolgsmetrik bewertet. Diese begrenzte Rückmeldung wird dann verwendet, um die Parameter des Modells schrittweise an eine bessere Leistung anzupassen.
Die wichtigste Einschränkung von RL ist seine Ineffizienz. Um effektiv aus minimalen numerischen Werten zu lernen, erfordert RL oft zehn- oder sogar hunderttausende von Testläufen. Für jede reale Unternehmensanwendung, die kostspielige Tool-Aufrufe oder proprietäre Modelle beinhaltet, ist dieser Prozess unerschwinglich langsam und teuer.
Wie Lakshya A. Agrawal, Mitautor und Doktorand an der UC Berkeley, erklärt, stellt diese Komplexität für viele Unternehmen ein großes Hindernis dar. "Für zahlreiche Teams ist RL aufgrund der Kosten und der Komplexität nicht praktikabel - ihr Standardansatz ist weitgehend die manuelle Eingabeaufforderung", so Agrawal. GEPA wurde für Teams entwickelt, die mit Hochleistungsmodellen arbeiten, die oft nicht feinabgestimmt werden können, und ermöglicht es ihnen, die Leistung zu verbessern, ohne spezielle Hardware zu verwalten.
Das Forschungsteam formuliert die Herausforderung wie folgt: "Wie können wir das maximale Lernsignal aus jedem kostspieligen Versuch extrahieren, um eine effektive Anpassung von komplexen, modularen KI-Systemen unter engen Daten- oder Budgetbeschränkungen zu ermöglichen?"
Ein Optimierer, der durch Sprache lernt
GEPA geht diese Herausforderung an, indem es die spärlichen Belohnungssignale durch detaillierte, natürlichsprachliche Rückmeldungen ersetzt. Es macht sich die Tatsache zunutze, dass die gesamte Ausführung eines KI-Systems - seine Argumentationsschritte, Werkzeugaufrufe und Fehlermeldungen - als Text dargestellt werden kann, den ein LLM verarbeiten kann. Diese Methodik basiert auf drei Grundprinzipien.
Das erste ist die "genetische Prompt-Evolution", bei der GEPA eine Reihe von Prompts als Genpool behandelt und sie iterativ modifiziert, um neue und möglicherweise verbesserte Versionen zu erzeugen. Dieser Mutationsprozess wird durch das zweite Prinzip geleitet: "Reflexion mit natürlichem Sprachfeedback". Nach mehreren Versuchsläufen legt GEPA einem LLM die vollständige Ausführungshistorie und die Ergebnisse vor. Der LLM analysiert dann diese Informationen, um Probleme zu diagnostizieren und eine präzisere, verbesserte Aufforderung zu verfassen. Anstatt beispielsweise nur eine niedrige Punktzahl für die Codegenerierung zu erhalten, könnte er einen Compilerfehler untersuchen und feststellen, dass die Eingabeaufforderung eine bestimmte Bibliotheksversion angeben muss.
Das dritte Prinzip ist die "Pareto-basierte Auswahl", die eine intelligente Erkundung fördert. Anstatt sich ausschließlich auf die einzige Eingabeaufforderung mit der höchsten Punktzahl zu konzentrieren, was das Risiko birgt, sich mit einer suboptimalen Lösung zufrieden zu geben, unterhält GEPA eine vielfältige Sammlung spezialisierter Eingabeaufforderungen. Es ermittelt, welche Prompts in verschiedenen Testfällen besonders gut abschneiden, und stellt so eine Liste der führenden Kandidaten zusammen. Durch die Auswahl aus dieser Vielzahl erfolgreicher Strategien erkundet GEPA einen breiteren Lösungsraum und findet mit größerer Wahrscheinlichkeit eine Aufforderung, die bei verschiedenen Eingaben gut funktioniert.
Der Erfolg dieses gesamten Prozesses hängt von dem ab, was die Forscher "Feedback Engineering" nennen. Agrawal betont, dass der Schlüssel darin liegt, die reichhaltigen textuellen Details zu erfassen, die Systeme bereits produzieren, aber oft ignorieren. "Herkömmliche Pipelines verdichten diese Informationen in der Regel zu einer einzigen numerischen Belohnung und verbergen die Gründe für bestimmte Ergebnisse", erklärt er. "Der Kernansatz der GEPA besteht darin, ein Feedback zu strukturieren, das nicht nur die Endergebnisse, sondern auch Zwischenschritte und Fehler im Klartext aufzeigt - dieselben Informationen, die ein menschlicher Experte zur Analyse des Systemverhaltens verwenden würde."
Bei einem System zur Dokumentensuche würde dies beispielsweise bedeuten, dass aufgelistet wird, welche Dokumente korrekt abgerufen wurden und welche nicht, anstatt nur eine endgültige Trefferquote zu melden.
GEPA in der Praxis
Das Forschungsteam bewertete GEPA anhand von vier verschiedenen Aufgaben, von der Beantwortung von Multi-Hop-Fragen bis zu datenschutzfreundlichen Abfragen. Sie testeten sowohl Open-Source- als auch proprietäre Modelle und verglichen GEPA mit dem RL-basierten GRPO und dem erweiterten Prompt-Optimierer MIPROv2.
Bei allen Evaluierungen schnitt GEPA deutlich besser ab als GRPO und erzielte eine Verbesserung der Punktzahl um bis zu 19 %, wobei bis zu 35 Mal weniger Testläufe erforderlich waren. Agrawal veranschaulichte diese Effizienz anhand eines konkreten Beispiels: "Wir haben ein Frage-Antwort-System mit GEPA in etwa 3 Stunden optimiert, im Vergleich zu 24 Stunden mit GRPO - eine achtfache Reduzierung der Entwicklungszeit, gepaart mit einem Leistungsgewinn von 20 %", erklärte er. "Die RL-basierte Optimierung für dasselbe Testszenario kostete rund 300 Dollar an GPU-Rechenleistung, während GEPA bessere Ergebnisse für weniger als 20 Dollar erzielte - eine 15-fache Kostenreduzierung in unseren Experimenten."
Über die reinen Kennzahlen hinaus beobachteten die Forscher, dass GEPA-optimierte Systeme zuverlässiger im Umgang mit neuen, ungesehenen Daten sind, was sich in einer geringeren "Generalisierungslücke" zeigt. Agrawal vermutet, dass diese verbesserte Robustheit darauf zurückzuführen ist, dass GEPA aus umfangreicheren Rückmeldungen lernt. "Die geringere Verallgemeinerungslücke von GEPA ist wahrscheinlich darauf zurückzuführen, dass das System detaillierte Rückmeldungen in natürlicher Sprache zu den einzelnen Ergebnissen gibt - was erfolgreich war, was nicht und warum - anstatt sich auf eine einzige numerische Punktzahl zu verlassen", sagte er. "Dies ermutigt das System, Anweisungen und Strategien auf der Grundlage eines umfassenden Verständnisses von Erfolg zu entwickeln, anstatt einfach nur Muster aus den Trainingsdaten auswendig zu lernen. Für Unternehmen bedeutet diese verbesserte Zuverlässigkeit robustere und anpassungsfähigere KI-Anwendungen in Szenarien mit Kundenkontakt.
Ein wichtiger praktischer Vorteil ist, dass die endgültigen Anweisungen von GEPA bis zu 9,2 Mal kürzer sind als die von Optimierern wie MIPROv2 generierten Prompts, die oft zahlreiche Beispiele enthalten. Kürzere Prompts verringern die Latenzzeit und senken die Kosten für API-basierte Modelle, wodurch die endgültige Anwendung sowohl schneller als auch wirtschaftlicher in der Produktion ausgeführt werden kann.
Das Papier untersucht auch vielversprechende Anwendungen von GEPA als "Inferenzzeit"-Suchstrategie, die eine KI von einem einstufigen Antwortgenerator in einen iterativen Problemlöser verwandelt. Agrawal beschrieb eine mögliche Integration in die Entwicklungspipeline eines Unternehmens, bei der GEPA automatisch mehrere optimierte Versionen eines Systems erstellen und verfeinern, ihre Leistung testen und die beste Variante zur technischen Prüfung vorlegen könnte. "Dadurch wird die Optimierung zu einem kontinuierlichen, automatisierten Prozess, der schnell Lösungen hervorbringt, die oft die Qualität der manuellen Abstimmung durch Experten erreichen oder übertreffen", fügte Agrawal hinzu. In Tests zur CUDA-Code-Generierung konnte diese Methode die Leistung bei 20 % der Aufgaben auf ein Expertenniveau anheben, verglichen mit 0 % bei einem einzigen Versuch mit einem Modell wie GPT-4o.
Die Autoren betrachten GEPA als einen grundlegenden Schritt in Richtung eines neuen Paradigmas in der KI-Entwicklung. Neben der Förderung einer menschenähnlicheren KI könnte seine unmittelbarste Auswirkung jedoch in der Demokratisierung der Entwicklung von Hochleistungssystemen liegen.
"Wir gehen davon aus, dass GEPA einen positiven Wandel in der Konstruktion von KI-Systemen herbeiführen wird, indem es die Optimierung für Endnutzer zugänglich macht, die zwar über tiefes Fachwissen für diese Aufgabe verfügen, aber vielleicht nicht die Zeit oder den Wunsch haben, komplexe RL-Techniken zu beherrschen", so Agrawal abschließend. "Es befähigt die Akteure, die über das präzise, aufgabenspezifische Wissen verfügen."










 Claude Opus 4.7 startet mit dem Grundsatz, dass Zuverlässigkeit vor Intelligenz geht
Anthropic hat in diesem Jahr ein hohes Tempo beibehalten und fast jeden zweiten Tag neue Funktionen eingeführt. Das mit Spannung erwartete Claude Opus 4.7 wurde soeben offiziell veröffentlicht, und in
Claude Opus 4.7 startet mit dem Grundsatz, dass Zuverlässigkeit vor Intelligenz geht
Anthropic hat in diesem Jahr ein hohes Tempo beibehalten und fast jeden zweiten Tag neue Funktionen eingeführt. Das mit Spannung erwartete Claude Opus 4.7 wurde soeben offiziell veröffentlicht, und in
 Haier bringt den weltweit leichtesten KI-Sport-Exoskelett-Roboter mit einem Gewicht von nur 1,75 kg auf den Markt
Die Haier Group hat den weltweit leichtesten KI-gestützten Exoskelett-Roboter für den Sport vorgestellt – den Haier Exoskeleton Robot W3. Diese Markteinführung stellt einen neuen Branchenrekord in Sac
Haier bringt den weltweit leichtesten KI-Sport-Exoskelett-Roboter mit einem Gewicht von nur 1,75 kg auf den Markt
Die Haier Group hat den weltweit leichtesten KI-gestützten Exoskelett-Roboter für den Sport vorgestellt – den Haier Exoskeleton Robot W3. Diese Markteinführung stellt einen neuen Branchenrekord in Sac
 Yaoke Medias erste AIGC-Serie „Das Geheimnis der Bronzefiguren im Qinling-Gebirge“ startet heute mit KI-generierten Hauptdarstellern
Heute ist der offizielle Starttag von Yaoke Medias AIGC-Fantasy-Mystery-Kurzserie „Die geheime Geschichte der Qinling-Bronze“. Mit den ersten beiden unter Vertrag genommenen KI-Schauspielern des Unter
Yaoke Medias erste AIGC-Serie „Das Geheimnis der Bronzefiguren im Qinling-Gebirge“ startet heute mit KI-generierten Hauptdarstellern
Heute ist der offizielle Starttag von Yaoke Medias AIGC-Fantasy-Mystery-Kurzserie „Die geheime Geschichte der Qinling-Bronze“. Mit den ersten beiden unter Vertrag genommenen KI-Schauspielern des Unter

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai













