
















 首頁
首頁Google 的 GEPA 可提升 LLM 效能,繞過昂貴的強化學習需求
來自加州大學柏克萊分校、史丹福大學和 Databricks 的研究人員推出了一種名為 GEPA 的新人工智慧最佳化方法,與傳統的強化學習技術相比,GEPA 在調整大型語言模型以適應專門任務方面有顯著的改進。
GEPA 不採用傳統的學習方法,而是透過簡單的數字分數驅動數以千計的試誤嘗試。相反,它使用 LLM 的內部語言能力來分析其表現、識別錯誤並逐步改進其指令。除了達到比既有方法更高的精確度之外,GEPA 的效率也高得多,只需減少 35 倍的試運行就能達到優異的結果。
對於開發複雜 AI 代理和工作流程的公司而言,這項突破意味著更快的開發速度、大幅降低的運算成本,以及更強大、更可靠的應用程式。
優化現代人工智能系統的高成本
現代企業級 AI 應用程式很少依賴單次呼叫 LLM。它們通常是「複合 AI 系統」- 結合多個 LLM 模組、外部工具 (例如資料庫或程式碼解譯器) 以及自訂邏輯的精密工作流程,以執行複雜的任務,例如多步驟研究與資料分析。
這些系統常見的最佳化策略是強化學習,例如在進階推理模型中使用的群組相對政策最佳化 (Group Relative Policy Optimization) 等技術。這些方法將 AI 系統視為黑箱,透過基本的成功指標來評估任務。然後,這個有限的回饋會被用來逐漸調整模型的參數,以達到更好的效能。
RL 的主要限制是其低效率。要從最小的數值分數中有效地學習,RL 通常需要數萬甚至數十萬次的試運行。對於任何涉及高成本工具呼叫或專屬模型的真實世界企業應用程式而言,此過程過於緩慢且昂貴。
正如作者之一、加州大學柏克萊分校博士生 Lakshya A Agrawal 所解釋的,這種複雜性對許多組織而言都是一大障礙。"Agrawal 指出:「對於許多團隊來說,RL 因其費用和複雜性而不切實際,他們的預設方法主要是手動提示工程。GEPA 專為使用高效能模型的團隊所設計,這些模型通常無法微調,讓他們可以在不管理專門硬體的情況下提升效能。
研究團隊以這種方式提出挑戰:"我們如何才能從每個成本高昂的試驗中提取最大的學習信號,以便在緊湊的數據或預算限制下有效地適應複雜的模組化人工智能系統?
透過語言學習的優化器

GEPA 架構 資料來源:arXiv GEPA 以詳細的自然語言回饋取代稀疏的獎勵信號來解決這個挑戰。它充分利用了人工智能系統的整個執行 - 其推理步驟、工具呼叫和錯誤訊息 - 可以表示為文本,供 LLM 處理的事實。這個方法建立在三個核心原則上。
第一個原則是「基因提示進化」,GEPA 將提示集視為基因庫,反覆修改以產生新的、可能改良的版本。這個突變過程由第二個原則引導:「以自然語言反饋作反省」。在多次試運行之後,GEPA 向 LLM 呈現完整的執行歷史和結果。LLM 然後分析這些資訊來診斷問題,並起草更精確、更強化的提示。例如,它可能會檢查編譯器錯誤,並決定提示必須指定特定的函式庫版本,而不只是收到代碼生成的低分。
第三個原則是「以帕累托為基礎的選擇」,促進智慧型探索。GEPA 不會只專注於單一得分最高的提示,因為這樣做有可能會得到次優解決方案。它可以識別出哪些提示在不同的測試案例中表現優異,從而編制出一份領先的候選名單。透過從各種成功的策略中抽樣,GEPA 可以探索更廣闊的解決方案空間,並且更有可能發現在各種輸入中表現優異的提示。

專注於單一頂尖候選人可能會讓模型陷於局部最小值,而帕累托選擇則會探索更多的選項以找到最佳解決方案 資料來源:arXiv 整個過程的成功取決於研究人員所謂的「反饋工程」。Agrawal 強調,關鍵在於捕捉系統已經產生但經常忽略的豐富文字細節。"傳統的管道通常會將這些資訊濃縮為單一的數字獎勵,隱藏了特定結果背後的原因,」他解釋道。"GEPA 的核心方法是結構化回饋,不僅揭示最終結果,還揭示中間步驟和純文本中的錯誤 - 與人類專家分析系統行為所使用的證據相同。
例如,對於文件擷取系統而言,這將包括列出哪些文件被正確擷取,哪些被遺漏,而非僅報告最終的準確度分數。
實踐中的 GEPA
研究團隊在四個不同的任務中評估了 GEPA,從多跳問題回答到隱私保護查詢。他們測試了開放源碼和專有模型,並將 GEPA 與基於 RL 的 GRPO 和先進的提示最佳化器 MIPROv2 進行了比較。
在所有的評估中,GEPA 的表現明顯優於 GRPO,最多可提升 19% 的分數,同時使用的試運行次數減少了 35 倍。Agrawal 用一個具體的例子說明了這種效率:"他說:「我們使用 GEPA 優化一個答題系統只花了約 3 小時,而 GRPO 則花了 24 小時,開發時間縮短了 8 倍,同時性能提升了 20%。「針對相同的測試情境,基於 RL 的最佳化花費了約 300 美元的 GPU 計算費用,而 GEPA 只花費不到 20 美元就獲得了更好的結果--在我們的實驗中,成本降低了 15 倍」。
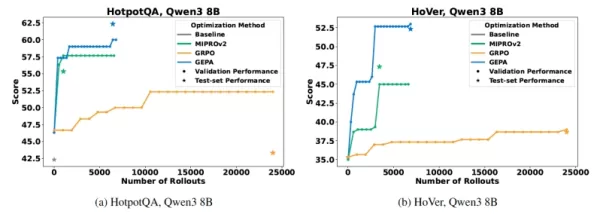
GEPA 在關鍵性能指標上優於其他基準方法 資料來源:arXiv 除了原始指標之外,研究人員觀察到 GEPA 優化過的系統在處理新的、未見過的資料時更可靠,「泛化差距」更小就表示了這一點。Agrawal 認為,這種穩健性的提升源自於 GEPA 從更豐富的回饋中學習。「GEPA 較小的泛化差距可能來自於它對每個結果使用詳細的自然語言回饋,說明哪些成功、哪些失敗以及原因,而不是依賴於單一的數字分數,」他說。"他說:「這能鼓勵系統根據對成功的全面理解來制定指令和策略,而不是簡單地記憶訓練資料中的模式。對於企業來說,這種增強的可靠性可以轉化為在面向客戶的場景中更加強大且適應性更強的人工智能應用。
一個關鍵的實際優勢是,GEPA 的最終指令比 MIPROv2 等優化器產生的提示短達 9.2 倍,而 MIPROv2 通常包含大量示例。對於以 API 為基礎的模型而言,較短的提示可減少延遲並降低成本,使最終應用程式在生產中運行的速度更快、更經濟。
論文也探討了 GEPA 作為「推理時間」搜尋策略的前景應用,將人工智能從單步答案產生器轉換為迭代問題解決器。Agrawal 描述了與公司開發管道整合的可能性,在此過程中,GEPA 可以自動建立並精細化系統的多個最佳化版本,測試其效能,並將最佳變體提交工程審查。"Agrawal 補充:「這將優化轉化為一個持續、自動化的過程,快速產生的解決方案往往能達到或超越專家人工調整的品質。在 CUDA 代碼產生的測試中,此方法將 20% 的任務效能提升至專家級,而使用 GPT-4o 等模型的單次嘗試只有 0%。
作者將 GEPA 視為邁向 AI 開發新範式的奠基性一步。然而,除了培育更類似人類的 AI 之外,其最直接的影響可能在於創造高效能系統的民主化。
"Agrawal 總結道:「我們預期 GEPA 將促進 AI 系統建構的正面轉變,讓那些擁有深厚領域專業知識,但可能缺乏時間或意願去掌握複雜 RL 技術的終端使用者,也能進行最佳化。"Agrawal 總結道:「它賦予了擁有精確、特定任務知識的利害關係人權力。
相關文章
 耀科傳媒首部AIGC劇集《秦嶺青銅之謎》今日上線,主演均由AI選角
今日,耀科傳媒的AIGC奇幻懸疑短劇《秦嶺青銅秘事》正式上線。本劇由該公司首批簽約的兩位AI演員秦凌月與林西妍主演,故事背景設定在神秘莫測的秦嶺礦區。 劇情追隨退休情報官秦月帶領團隊深入該區域,揭開一樁塵封已久的礦難,以及跨越兩代人的血祭真相——這份真相就隱藏在受限的地下區域,正是科學探索與古代巫術交匯之處。作為中國最早完全由AI數位人支持的電影之一,該劇在籌備階段便引發了業界熱烈討論,而關於其A
薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
相關專題推薦
商業
耀科傳媒首部AIGC劇集《秦嶺青銅之謎》今日上線,主演均由AI選角
今日,耀科傳媒的AIGC奇幻懸疑短劇《秦嶺青銅秘事》正式上線。本劇由該公司首批簽約的兩位AI演員秦凌月與林西妍主演,故事背景設定在神秘莫測的秦嶺礦區。 劇情追隨退休情報官秦月帶領團隊深入該區域,揭開一樁塵封已久的礦難,以及跨越兩代人的血祭真相——這份真相就隱藏在受限的地下區域,正是科學探索與古代巫術交匯之處。作為中國最早完全由AI數位人支持的電影之一,該劇在籌備階段便引發了業界熱烈討論,而關於其A
薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
相關專題推薦
商業
 最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
 10 個工具
10 個工具
 xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

 評論 (0)
0/500
評論 (0)
0/500
來自加州大學柏克萊分校、史丹福大學和 Databricks 的研究人員推出了一種名為 GEPA 的新人工智慧最佳化方法,與傳統的強化學習技術相比,GEPA 在調整大型語言模型以適應專門任務方面有顯著的改進。
GEPA 不採用傳統的學習方法,而是透過簡單的數字分數驅動數以千計的試誤嘗試。相反,它使用 LLM 的內部語言能力來分析其表現、識別錯誤並逐步改進其指令。除了達到比既有方法更高的精確度之外,GEPA 的效率也高得多,只需減少 35 倍的試運行就能達到優異的結果。
對於開發複雜 AI 代理和工作流程的公司而言,這項突破意味著更快的開發速度、大幅降低的運算成本,以及更強大、更可靠的應用程式。
優化現代人工智能系統的高成本
現代企業級 AI 應用程式很少依賴單次呼叫 LLM。它們通常是「複合 AI 系統」- 結合多個 LLM 模組、外部工具 (例如資料庫或程式碼解譯器) 以及自訂邏輯的精密工作流程,以執行複雜的任務,例如多步驟研究與資料分析。
這些系統常見的最佳化策略是強化學習,例如在進階推理模型中使用的群組相對政策最佳化 (Group Relative Policy Optimization) 等技術。這些方法將 AI 系統視為黑箱,透過基本的成功指標來評估任務。然後,這個有限的回饋會被用來逐漸調整模型的參數,以達到更好的效能。
RL 的主要限制是其低效率。要從最小的數值分數中有效地學習,RL 通常需要數萬甚至數十萬次的試運行。對於任何涉及高成本工具呼叫或專屬模型的真實世界企業應用程式而言,此過程過於緩慢且昂貴。
正如作者之一、加州大學柏克萊分校博士生 Lakshya A Agrawal 所解釋的,這種複雜性對許多組織而言都是一大障礙。"Agrawal 指出:「對於許多團隊來說,RL 因其費用和複雜性而不切實際,他們的預設方法主要是手動提示工程。GEPA 專為使用高效能模型的團隊所設計,這些模型通常無法微調,讓他們可以在不管理專門硬體的情況下提升效能。
研究團隊以這種方式提出挑戰:"我們如何才能從每個成本高昂的試驗中提取最大的學習信號,以便在緊湊的數據或預算限制下有效地適應複雜的模組化人工智能系統?
透過語言學習的優化器
GEPA 以詳細的自然語言回饋取代稀疏的獎勵信號來解決這個挑戰。它充分利用了人工智能系統的整個執行 - 其推理步驟、工具呼叫和錯誤訊息 - 可以表示為文本,供 LLM 處理的事實。這個方法建立在三個核心原則上。
第一個原則是「基因提示進化」,GEPA 將提示集視為基因庫,反覆修改以產生新的、可能改良的版本。這個突變過程由第二個原則引導:「以自然語言反饋作反省」。在多次試運行之後,GEPA 向 LLM 呈現完整的執行歷史和結果。LLM 然後分析這些資訊來診斷問題,並起草更精確、更強化的提示。例如,它可能會檢查編譯器錯誤,並決定提示必須指定特定的函式庫版本,而不只是收到代碼生成的低分。
第三個原則是「以帕累托為基礎的選擇」,促進智慧型探索。GEPA 不會只專注於單一得分最高的提示,因為這樣做有可能會得到次優解決方案。它可以識別出哪些提示在不同的測試案例中表現優異,從而編制出一份領先的候選名單。透過從各種成功的策略中抽樣,GEPA 可以探索更廣闊的解決方案空間,並且更有可能發現在各種輸入中表現優異的提示。
整個過程的成功取決於研究人員所謂的「反饋工程」。Agrawal 強調,關鍵在於捕捉系統已經產生但經常忽略的豐富文字細節。"傳統的管道通常會將這些資訊濃縮為單一的數字獎勵,隱藏了特定結果背後的原因,」他解釋道。"GEPA 的核心方法是結構化回饋,不僅揭示最終結果,還揭示中間步驟和純文本中的錯誤 - 與人類專家分析系統行為所使用的證據相同。
例如,對於文件擷取系統而言,這將包括列出哪些文件被正確擷取,哪些被遺漏,而非僅報告最終的準確度分數。
實踐中的 GEPA
研究團隊在四個不同的任務中評估了 GEPA,從多跳問題回答到隱私保護查詢。他們測試了開放源碼和專有模型,並將 GEPA 與基於 RL 的 GRPO 和先進的提示最佳化器 MIPROv2 進行了比較。
在所有的評估中,GEPA 的表現明顯優於 GRPO,最多可提升 19% 的分數,同時使用的試運行次數減少了 35 倍。Agrawal 用一個具體的例子說明了這種效率:"他說:「我們使用 GEPA 優化一個答題系統只花了約 3 小時,而 GRPO 則花了 24 小時,開發時間縮短了 8 倍,同時性能提升了 20%。「針對相同的測試情境,基於 RL 的最佳化花費了約 300 美元的 GPU 計算費用,而 GEPA 只花費不到 20 美元就獲得了更好的結果--在我們的實驗中,成本降低了 15 倍」。
除了原始指標之外,研究人員觀察到 GEPA 優化過的系統在處理新的、未見過的資料時更可靠,「泛化差距」更小就表示了這一點。Agrawal 認為,這種穩健性的提升源自於 GEPA 從更豐富的回饋中學習。「GEPA 較小的泛化差距可能來自於它對每個結果使用詳細的自然語言回饋,說明哪些成功、哪些失敗以及原因,而不是依賴於單一的數字分數,」他說。"他說:「這能鼓勵系統根據對成功的全面理解來制定指令和策略,而不是簡單地記憶訓練資料中的模式。對於企業來說,這種增強的可靠性可以轉化為在面向客戶的場景中更加強大且適應性更強的人工智能應用。
一個關鍵的實際優勢是,GEPA 的最終指令比 MIPROv2 等優化器產生的提示短達 9.2 倍,而 MIPROv2 通常包含大量示例。對於以 API 為基礎的模型而言,較短的提示可減少延遲並降低成本,使最終應用程式在生產中運行的速度更快、更經濟。
論文也探討了 GEPA 作為「推理時間」搜尋策略的前景應用,將人工智能從單步答案產生器轉換為迭代問題解決器。Agrawal 描述了與公司開發管道整合的可能性,在此過程中,GEPA 可以自動建立並精細化系統的多個最佳化版本,測試其效能,並將最佳變體提交工程審查。"Agrawal 補充:「這將優化轉化為一個持續、自動化的過程,快速產生的解決方案往往能達到或超越專家人工調整的品質。在 CUDA 代碼產生的測試中,此方法將 20% 的任務效能提升至專家級,而使用 GPT-4o 等模型的單次嘗試只有 0%。
作者將 GEPA 視為邁向 AI 開發新範式的奠基性一步。然而,除了培育更類似人類的 AI 之外,其最直接的影響可能在於創造高效能系統的民主化。
"Agrawal 總結道:「我們預期 GEPA 將促進 AI 系統建構的正面轉變,讓那些擁有深厚領域專業知識,但可能缺乏時間或意願去掌握複雜 RL 技術的終端使用者,也能進行最佳化。"Agrawal 總結道:「它賦予了擁有精確、特定任務知識的利害關係人權力。










 耀科傳媒首部AIGC劇集《秦嶺青銅之謎》今日上線,主演均由AI選角
今日,耀科傳媒的AIGC奇幻懸疑短劇《秦嶺青銅秘事》正式上線。本劇由該公司首批簽約的兩位AI演員秦凌月與林西妍主演,故事背景設定在神秘莫測的秦嶺礦區。 劇情追隨退休情報官秦月帶領團隊深入該區域,揭開一樁塵封已久的礦難,以及跨越兩代人的血祭真相——這份真相就隱藏在受限的地下區域,正是科學探索與古代巫術交匯之處。作為中國最早完全由AI數位人支持的電影之一,該劇在籌備階段便引發了業界熱烈討論,而關於其A
耀科傳媒首部AIGC劇集《秦嶺青銅之謎》今日上線,主演均由AI選角
今日,耀科傳媒的AIGC奇幻懸疑短劇《秦嶺青銅秘事》正式上線。本劇由該公司首批簽約的兩位AI演員秦凌月與林西妍主演,故事背景設定在神秘莫測的秦嶺礦區。 劇情追隨退休情報官秦月帶領團隊深入該區域,揭開一樁塵封已久的礦難,以及跨越兩代人的血祭真相——這份真相就隱藏在受限的地下區域,正是科學探索與古代巫術交匯之處。作為中國最早完全由AI數位人支持的電影之一,該劇在籌備階段便引發了業界熱烈討論,而關於其A
 薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
 WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai













