
















 Home
Home
Alibaba's Tongyi Unveils Fun-CineForge: Open-Source AI Model Achieves Film-Grade Voice Synthesis
Alibaba Tongyi Lab officially launched and open-sourced the film-grade, multi-scenario voice synthesis multimodal model Fun-CineForge on March 16. This model addresses core challenges in AI dubbing, including lip-sync mismatch, lack of emotional expression, and inconsistent voice characteristics across multiple characters. It also introduces a high-quality method for dataset construction.
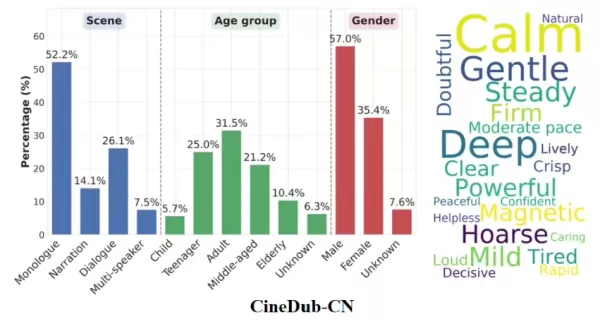
Technically, Fun-CineForge pioneers the concept of "temporal modality." Unlike conventional models that focus solely on text or visuals, it ensures voice synthesis occurs within precise time intervals through accurate timestamp control. Even in complex film scenes with occluded characters, frequent camera cuts, or blurred faces, the model maintains a high degree of audio-visual synchronization and adherence to instructions.
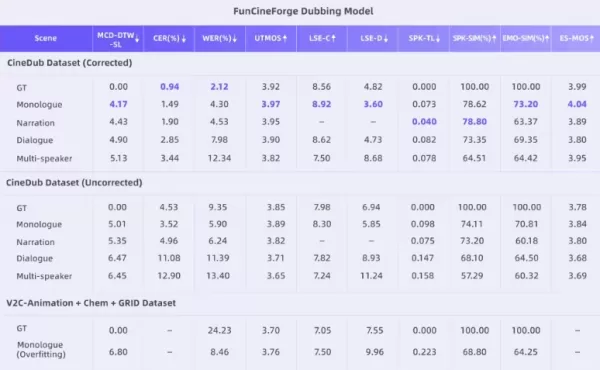
The accompanying open-source CineDub dataset construction pipeline is another key innovation. Tongyi Lab employed large language model chain-of-thought reasoning to automatically transform raw film footage into structured data, significantly reducing the need for manual annotation. This process achieves a word error rate of approximately 1% and a speaker diarization error rate of just 1.20%, providing a highly competitive training foundation for large models.
Fun-CineForge is now available on GitHub, HuggingFace, and the ModelScope community, supporting inference for video clips up to 30 seconds long. It excels not only in single-speaker monologues but also offers professional-grade support for duet and multi-speaker dialogue scenarios. This advancement signals AI voice technology's evolution from basic customer service and assistant roles into high-standard animation and film post-production.
GitHub: https://github.com/FunAudioLLM/FunCineForge
HuggingFace: https://huggingface.co/FunAudioLLM/Fun-CineForge
ModelScope: https://www.modelscope.cn/models/FunAudioLLM/Fun-CineForge/
Related article
 MIIT Seeks Public Feedback on 121 Industry Standards, Including AI Model Context Protocol
China's Ministry of Industry and Information Technology has officially released a notice seeking public feedback on 121 industry standardization projects, including the "Application Security Requirements for the Artificial Intelligence Security Gover
OpenAI Partners with U.S. Department of Defense, ChatGPT Uninstallations Surge 295%
Public Outrage: OpenAI's Military Partnership Sparks a 'Uninstall Surge'Recently, AI leader OpenAI announced a deep partnership with the U.S. Department of Defense (DoD), integrating its AI models into top-secret military networks. The news sparked w
OpenAI Launches Sites Feature, Marking the End of the No-Code Era with Word-Powered Websites
OpenAI has introduced Sites, a new feature for Codex, its AI for software engineering. Currently in preview, it's available only to paying Business and Enterprise subscribers and aims to remove traditional barriers in web and application development.
Related Special Topic Recommendations
Education and Learning
MIIT Seeks Public Feedback on 121 Industry Standards, Including AI Model Context Protocol
China's Ministry of Industry and Information Technology has officially released a notice seeking public feedback on 121 industry standardization projects, including the "Application Security Requirements for the Artificial Intelligence Security Gover
OpenAI Partners with U.S. Department of Defense, ChatGPT Uninstallations Surge 295%
Public Outrage: OpenAI's Military Partnership Sparks a 'Uninstall Surge'Recently, AI leader OpenAI announced a deep partnership with the U.S. Department of Defense (DoD), integrating its AI models into top-secret military networks. The news sparked w
OpenAI Launches Sites Feature, Marking the End of the No-Code Era with Word-Powered Websites
OpenAI has introduced Sites, a new feature for Codex, its AI for software engineering. Currently in preview, it's available only to paying Business and Enterprise subscribers and aims to remove traditional barriers in web and application development.
Related Special Topic Recommendations
Education and Learning
 Best AI Spaced Repetition Tools: Optimize Study Schedules for Medical & Law Students
Best AI Spaced Repetition Tools: Optimize Study Schedules for Medical & Law Students
Discover the 2026 best AI spaced repetition tools, curated by XIX.AI. Our top-rated, game-changing picks help medical and law students optimize study schedules for maximum retention. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your learning edge now.
 10 tools
10 tools
 xix.ai
Video creation
Best AI Text to Video Platforms for Script Writing and Visual Storytelling
xix.ai
Video creation
Best AI Text to Video Platforms for Script Writing and Visual Storytelling
2026 Latest Best AI Text to Video Platforms: Top-rated tools for script writing and visual storytelling. Discover powerful, game-changing solutions to transform your text into engaging videos. Compare free vs paid options with our weekly updated rankings and real-world tests. Find your perfect platform to boost creativity and productivity. Explore the curated selection at XIX.AI.
10 tools
xix.ai
chatbot
AI Multi-Agent Orchestrators: Design Complex Automated Workflows through Natural Language
2026 Latest: Discover the best AI multi-agent orchestrators to design complex automated workflows through natural language. Our curated list features top-rated, powerful platforms for seamless task automation and intelligent process management. Compare free vs paid options with real-world insights. Unlock your AI edge with XIX.AI's expert weekly updated rankings.
10 tools
xix.ai
Image editing
Best AI Noise Reduction Software: Remove Grain & Artifacts from Low-Light Night Photography
Discover the 2026 best AI noise reduction software for low-light night photography. Our top-rated, curated list compares free vs paid tools, featuring real-world tests and weekly updated rankings. Remove grain & artifacts effortlessly. Unlock your AI edge at XIX.AI.
10 tools
xix.ai
chatbot
Best Custom AI Girlfriend Generators: Design Unique Personalities, Hobbies, and Backstories
Discover the 2026 best custom AI girlfriend generators on XIX.AI. Explore our top-rated, curated list for designing unique personalities, hobbies, and deep backstories. Compare free vs paid options with real-world insights. Unlock your perfect creative companion today.
10 tools
xix.ai
Productivity
AI Architecture Designers: Build Scalable System Architectures Using Natural Language
Discover the 2026 best AI architecture design tools on XIX.AI. Our curated, top-rated list features powerful, game-changing solutions to build scalable system architectures using natural language. Compare free vs paid options with real-world insights. Unlock your AI edge and streamline development today.
10 tools
xix.ai

 Comments (1)
0/500
Comments (1)
0/500
![NicholasThomas]()
Just tried the demo and honestly blown away by how natural the lip-sync feels now! 😮 Always thought AI dubbing sounded a bit robotic, but this seems like a huge leap. Wonder if this will start being used in indie films or even gaming soon? The open-source move is pretty bold too—curious to see how other companies respond.
Alibaba Tongyi Lab officially launched and open-sourced the film-grade, multi-scenario voice synthesis multimodal model Fun-CineForge on March 16. This model addresses core challenges in AI dubbing, including lip-sync mismatch, lack of emotional expression, and inconsistent voice characteristics across multiple characters. It also introduces a high-quality method for dataset construction.
Technically, Fun-CineForge pioneers the concept of "temporal modality." Unlike conventional models that focus solely on text or visuals, it ensures voice synthesis occurs within precise time intervals through accurate timestamp control. Even in complex film scenes with occluded characters, frequent camera cuts, or blurred faces, the model maintains a high degree of audio-visual synchronization and adherence to instructions.
The accompanying open-source CineDub dataset construction pipeline is another key innovation. Tongyi Lab employed large language model chain-of-thought reasoning to automatically transform raw film footage into structured data, significantly reducing the need for manual annotation. This process achieves a word error rate of approximately 1% and a speaker diarization error rate of just 1.20%, providing a highly competitive training foundation for large models.
Fun-CineForge is now available on GitHub, HuggingFace, and the ModelScope community, supporting inference for video clips up to 30 seconds long. It excels not only in single-speaker monologues but also offers professional-grade support for duet and multi-speaker dialogue scenarios. This advancement signals AI voice technology's evolution from basic customer service and assistant roles into high-standard animation and film post-production.
GitHub: https://github.com/FunAudioLLM/FunCineForge
HuggingFace: https://huggingface.co/FunAudioLLM/Fun-CineForge
ModelScope: https://www.modelscope.cn/models/FunAudioLLM/Fun-CineForge/










 MIIT Seeks Public Feedback on 121 Industry Standards, Including AI Model Context Protocol
China's Ministry of Industry and Information Technology has officially released a notice seeking public feedback on 121 industry standardization projects, including the "Application Security Requirements for the Artificial Intelligence Security Gover
MIIT Seeks Public Feedback on 121 Industry Standards, Including AI Model Context Protocol
China's Ministry of Industry and Information Technology has officially released a notice seeking public feedback on 121 industry standardization projects, including the "Application Security Requirements for the Artificial Intelligence Security Gover
 OpenAI Partners with U.S. Department of Defense, ChatGPT Uninstallations Surge 295%
Public Outrage: OpenAI's Military Partnership Sparks a 'Uninstall Surge'Recently, AI leader OpenAI announced a deep partnership with the U.S. Department of Defense (DoD), integrating its AI models into top-secret military networks. The news sparked w
OpenAI Partners with U.S. Department of Defense, ChatGPT Uninstallations Surge 295%
Public Outrage: OpenAI's Military Partnership Sparks a 'Uninstall Surge'Recently, AI leader OpenAI announced a deep partnership with the U.S. Department of Defense (DoD), integrating its AI models into top-secret military networks. The news sparked w
 OpenAI Launches Sites Feature, Marking the End of the No-Code Era with Word-Powered Websites
OpenAI has introduced Sites, a new feature for Codex, its AI for software engineering. Currently in preview, it's available only to paying Business and Enterprise subscribers and aims to remove traditional barriers in web and application development.
OpenAI Launches Sites Feature, Marking the End of the No-Code Era with Word-Powered Websites
OpenAI has introduced Sites, a new feature for Codex, its AI for software engineering. Currently in preview, it's available only to paying Business and Enterprise subscribers and aims to remove traditional barriers in web and application development.

Discover the 2026 best AI spaced repetition tools, curated by XIX.AI. Our top-rated, game-changing picks help medical and law students optimize study schedules for maximum retention. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your learning edge now.
10 tools
xix.ai

2026 Latest Best AI Text to Video Platforms: Top-rated tools for script writing and visual storytelling. Discover powerful, game-changing solutions to transform your text into engaging videos. Compare free vs paid options with our weekly updated rankings and real-world tests. Find your perfect platform to boost creativity and productivity. Explore the curated selection at XIX.AI.
10 tools
xix.ai

2026 Latest: Discover the best AI multi-agent orchestrators to design complex automated workflows through natural language. Our curated list features top-rated, powerful platforms for seamless task automation and intelligent process management. Compare free vs paid options with real-world insights. Unlock your AI edge with XIX.AI's expert weekly updated rankings.
10 tools
xix.ai

Discover the 2026 best AI noise reduction software for low-light night photography. Our top-rated, curated list compares free vs paid tools, featuring real-world tests and weekly updated rankings. Remove grain & artifacts effortlessly. Unlock your AI edge at XIX.AI.
10 tools
xix.ai

Discover the 2026 best custom AI girlfriend generators on XIX.AI. Explore our top-rated, curated list for designing unique personalities, hobbies, and deep backstories. Compare free vs paid options with real-world insights. Unlock your perfect creative companion today.
10 tools
xix.ai

Discover the 2026 best AI architecture design tools on XIX.AI. Our curated, top-rated list features powerful, game-changing solutions to build scalable system architectures using natural language. Compare free vs paid options with real-world insights. Unlock your AI edge and streamline development today.
10 tools
xix.ai

Just tried the demo and honestly blown away by how natural the lip-sync feels now! 😮 Always thought AI dubbing sounded a bit robotic, but this seems like a huge leap. Wonder if this will start being used in indie films or even gaming soon? The open-source move is pretty bold too—curious to see how other companies respond.













