
















 Hogar
Hogar
Tongyi, de Alibaba, presenta Fun-CineForge: un modelo de IA de código abierto que logra una síntesis de voz con calidad cinematográfica
El 16 de marzo, Alibaba Tongyi Lab presentó oficialmente y puso a disposición como código abierto el modelo multimodal de síntesis de voz para múltiples escenarios y con calidad cinematográfica Fun-CineForge. Este modelo aborda los principales retos del doblaje con IA, entre los que se incluyen la falta de sincronización labial, la falta de expresión emocional y las características vocales inconsistentes entre los distintos personajes. Además, introduce un método de alta calidad para la construcción de conjuntos de datos.
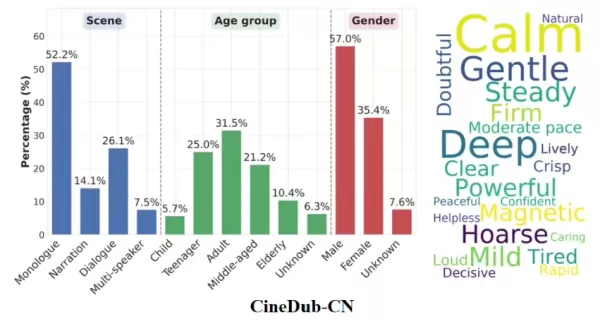
Técnicamente, Fun-CineForge es pionero en el concepto de «modalidad temporal». A diferencia de los modelos convencionales que se centran únicamente en el texto o las imágenes, garantiza que la síntesis de voz se produzca en intervalos de tiempo precisos mediante un control exacto de las marcas de tiempo. Incluso en escenas cinematográficas complejas con personajes ocultos, cortes frecuentes de cámara o rostros borrosos, el modelo mantiene un alto grado de sincronización audiovisual y de cumplimiento de las instrucciones.
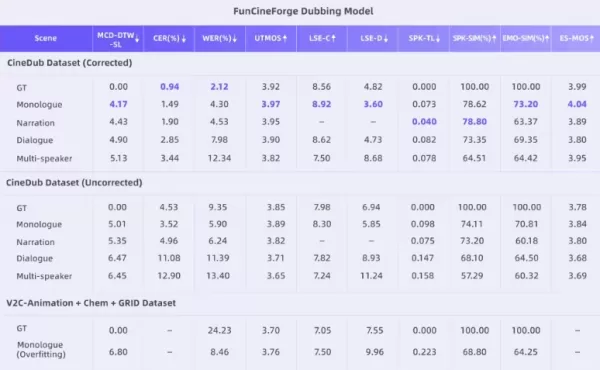
El canal de construcción del conjunto de datos de código abierto CineDub que lo acompaña es otra innovación clave. Tongyi Lab empleó el razonamiento de cadena de pensamiento de los grandes modelos de lenguaje para transformar automáticamente el metraje cinematográfico sin procesar en datos estructurados, lo que redujo significativamente la necesidad de anotación manual. Este proceso alcanza una tasa de error de palabras de aproximadamente el 1 % y una tasa de error de diarización de hablantes de solo el 1,20 %, lo que proporciona una base de entrenamiento altamente competitiva para modelos de gran tamaño.
Fun-CineForge ya está disponible en GitHub, HuggingFace y la comunidad ModelScope, y admite la inferencia de clips de vídeo de hasta 30 segundos de duración. Destaca no solo en monólogos de un solo hablante, sino que también ofrece soporte de nivel profesional para escenarios de diálogo a dúo y con varios hablantes. Este avance marca la evolución de la tecnología de voz de IA, pasando de funciones básicas de atención al cliente y asistencia a la postproducción de animación y cine de alto nivel.
GitHub: https://github.com/FunAudioLLM/FunCineForge
HuggingFace: https://huggingface.co/FunAudioLLM/Fun-CineForge
ModelScope: https://www.modelscope.cn/models/FunAudioLLM/Fun-CineForge/
Artículo relacionado
 Aspectos destacados del documento de oferta pública inicial de SpaceX: las ambiciones de expansión en internet por satélite y inteligencia artificial
En su declaración de registro S-1 presentada antes de lo que se espera sea su oferta pública inicial, SpaceX reveló recientemente una serie de impresionantes indicadores comerciales que destacan su sólida posición en las comunicaciones aeroespaciales
Alibaba Tuhao M890 debuta con un triple rendimiento, marcando el inicio de una nueva era de agentes full-stack para modelos de inferencia basados en chips y nube.
El 20 de mayo de 2026, en la Cumbre de Alibaba Cloud, esta compañía anunció la finalización de una actualización del sistema tecnológico completo diseñado para la era de los agentes inteligentes. Esta transformación reconfiguró todo el proceso, desde
Pentium 4 Revival: Una CPU de 20 años de antigüedad ejecuta el modelo grande Meta Llama 3
Recientemente, el canal técnico de YouTube Fully Buffered llevó a cabo un experimento impresionante y riguroso: lograron ejecutar con éxito el último modelo grande de Meta, Llama 3.2 3B, en un procesador Pentium 4 641, un chip lanzado en 2006.Esta p
Recomendaciones de temas especiales relacionados
Creación de vídeos
Aspectos destacados del documento de oferta pública inicial de SpaceX: las ambiciones de expansión en internet por satélite y inteligencia artificial
En su declaración de registro S-1 presentada antes de lo que se espera sea su oferta pública inicial, SpaceX reveló recientemente una serie de impresionantes indicadores comerciales que destacan su sólida posición en las comunicaciones aeroespaciales
Alibaba Tuhao M890 debuta con un triple rendimiento, marcando el inicio de una nueva era de agentes full-stack para modelos de inferencia basados en chips y nube.
El 20 de mayo de 2026, en la Cumbre de Alibaba Cloud, esta compañía anunció la finalización de una actualización del sistema tecnológico completo diseñado para la era de los agentes inteligentes. Esta transformación reconfiguró todo el proceso, desde
Pentium 4 Revival: Una CPU de 20 años de antigüedad ejecuta el modelo grande Meta Llama 3
Recientemente, el canal técnico de YouTube Fully Buffered llevó a cabo un experimento impresionante y riguroso: lograron ejecutar con éxito el último modelo grande de Meta, Llama 3.2 3B, en un procesador Pentium 4 641, un chip lanzado en 2006.Esta p
Recomendaciones de temas especiales relacionados
Creación de vídeos
 Los mejores creadores de vídeos con IA para podcasters: convierte ondas de audio en atractivos vídeos con rostros en primer plano
Los mejores creadores de vídeos con IA para podcasters: convierte ondas de audio en atractivos vídeos con rostros en primer plano
Descubre los mejores creadores de vídeos con IA para podcasters de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que convierten tu audio en atractivos vídeos de «talking head» sin esfuerzo. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. Aprovecha ahora tu ventaja en la narración visual.
 10 herramientas
10 herramientas
 xix.ai
chatbot
Crea tu propia historia de amor con IA gracias a estas herramientas de juego de rol
xix.ai
chatbot
Crea tu propia historia de amor con IA gracias a estas herramientas de juego de rol
Descubre las mejores herramientas de rol basadas en IA de 2026 para crear narrativas envolventes. La selección de XIX.AI incluye potentes asistentes revolucionarios que te permitirán desarrollar una narrativa creativa y una gran profundidad emocional. Compara las opciones gratuitas con las de pago mediante pruebas reales. Empieza hoy mismo tu viaje único.
10 herramientas
xix.ai
Texto a voz
Las mejores herramientas de voz con IA para desarrolladores de videojuegos independientes: ahorra tiempo en la grabación de voces para juegos de rol y novelas visuales
¡Descubre las mejores herramientas de voz con IA de 2026 para desarrolladores de videojuegos! La lista seleccionada por XIX.AI incluye soluciones de primera categoría que marcarán un antes y un después, y que te permitirán ahorrar tiempo y dinero en la locución de juegos de rol y novelas visuales. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones que se actualizan semanalmente. ¡Encuentra hoy mismo tu herramienta de voz perfecta!
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores herramientas de repetición espaciada con IA: optimiza los horarios de estudio para estudiantes de medicina y derecho
Descubra los mejores herramientas de repetición espacial de IA para 2026, seleccionadas por XIX.AI. Nuestras opciones más recomendadas y revolucionarias ayudan a estudiantes de medicina y derecho a optimizar sus horarios de estudio para lograr un mayor retención del conocimiento. Compare las opciones gratuitas con las pagas mediante pruebas reales y clasificaciones actualizadas semanalmente. Despliegue todo su potencial de aprendizaje ahora mismo.
10 herramientas
xix.ai
Creación de vídeos
Las mejores plataformas de IA para convertir texto en vídeo, destinadas a la redacción de guiones y la narración visual
Las mejores plataformas de IA para convertir texto en vídeo de 2026: las herramientas mejor valoradas para la redacción de guiones y la narración visual. Descubre soluciones potentes y revolucionarias para transformar tu texto en vídeos atractivos. Compara las opciones gratuitas con las de pago gracias a nuestras clasificaciones, que se actualizan semanalmente, y a nuestras pruebas en condiciones reales. Encuentra la plataforma perfecta para potenciar tu creatividad y productividad. Explora la selección cuidada de XIX.AI.
10 herramientas
xix.ai
chatbot
Orquestadores de Agentes Multiservidores AI: Diseño de Flujos de Trabajo Automatizados y Complejos a través del Lenguaje Natural
2026 Últimas novedades: Descubra los mejores herramientas de inteligencia artificial para diseñar flujos de trabajo automatizados complejos a través del lenguaje natural. Nuestra lista seleccionada incluye las plataformas más reconocidas y potentes para una automatización de tareas sin problemas y una gestión inteligente de procesos. Compare opciones gratuitas y pagadas con información basada en casos reales. Despliegue todo su potencial con las clasificaciones actualizadas semanalmente por expertos de XIX.AI.
10 herramientas
xix.ai

 comentario (1)
0/500
comentario (1)
0/500
![NicholasThomas]()
Just tried the demo and honestly blown away by how natural the lip-sync feels now! 😮 Always thought AI dubbing sounded a bit robotic, but this seems like a huge leap. Wonder if this will start being used in indie films or even gaming soon? The open-source move is pretty bold too—curious to see how other companies respond.
El 16 de marzo, Alibaba Tongyi Lab presentó oficialmente y puso a disposición como código abierto el modelo multimodal de síntesis de voz para múltiples escenarios y con calidad cinematográfica Fun-CineForge. Este modelo aborda los principales retos del doblaje con IA, entre los que se incluyen la falta de sincronización labial, la falta de expresión emocional y las características vocales inconsistentes entre los distintos personajes. Además, introduce un método de alta calidad para la construcción de conjuntos de datos.
Técnicamente, Fun-CineForge es pionero en el concepto de «modalidad temporal». A diferencia de los modelos convencionales que se centran únicamente en el texto o las imágenes, garantiza que la síntesis de voz se produzca en intervalos de tiempo precisos mediante un control exacto de las marcas de tiempo. Incluso en escenas cinematográficas complejas con personajes ocultos, cortes frecuentes de cámara o rostros borrosos, el modelo mantiene un alto grado de sincronización audiovisual y de cumplimiento de las instrucciones.
El canal de construcción del conjunto de datos de código abierto CineDub que lo acompaña es otra innovación clave. Tongyi Lab empleó el razonamiento de cadena de pensamiento de los grandes modelos de lenguaje para transformar automáticamente el metraje cinematográfico sin procesar en datos estructurados, lo que redujo significativamente la necesidad de anotación manual. Este proceso alcanza una tasa de error de palabras de aproximadamente el 1 % y una tasa de error de diarización de hablantes de solo el 1,20 %, lo que proporciona una base de entrenamiento altamente competitiva para modelos de gran tamaño.
Fun-CineForge ya está disponible en GitHub, HuggingFace y la comunidad ModelScope, y admite la inferencia de clips de vídeo de hasta 30 segundos de duración. Destaca no solo en monólogos de un solo hablante, sino que también ofrece soporte de nivel profesional para escenarios de diálogo a dúo y con varios hablantes. Este avance marca la evolución de la tecnología de voz de IA, pasando de funciones básicas de atención al cliente y asistencia a la postproducción de animación y cine de alto nivel.
GitHub: https://github.com/FunAudioLLM/FunCineForge
HuggingFace: https://huggingface.co/FunAudioLLM/Fun-CineForge
ModelScope: https://www.modelscope.cn/models/FunAudioLLM/Fun-CineForge/










 Aspectos destacados del documento de oferta pública inicial de SpaceX: las ambiciones de expansión en internet por satélite y inteligencia artificial
En su declaración de registro S-1 presentada antes de lo que se espera sea su oferta pública inicial, SpaceX reveló recientemente una serie de impresionantes indicadores comerciales que destacan su sólida posición en las comunicaciones aeroespaciales
Aspectos destacados del documento de oferta pública inicial de SpaceX: las ambiciones de expansión en internet por satélite y inteligencia artificial
En su declaración de registro S-1 presentada antes de lo que se espera sea su oferta pública inicial, SpaceX reveló recientemente una serie de impresionantes indicadores comerciales que destacan su sólida posición en las comunicaciones aeroespaciales
 Alibaba Tuhao M890 debuta con un triple rendimiento, marcando el inicio de una nueva era de agentes full-stack para modelos de inferencia basados en chips y nube.
El 20 de mayo de 2026, en la Cumbre de Alibaba Cloud, esta compañía anunció la finalización de una actualización del sistema tecnológico completo diseñado para la era de los agentes inteligentes. Esta transformación reconfiguró todo el proceso, desde
Alibaba Tuhao M890 debuta con un triple rendimiento, marcando el inicio de una nueva era de agentes full-stack para modelos de inferencia basados en chips y nube.
El 20 de mayo de 2026, en la Cumbre de Alibaba Cloud, esta compañía anunció la finalización de una actualización del sistema tecnológico completo diseñado para la era de los agentes inteligentes. Esta transformación reconfiguró todo el proceso, desde
 Pentium 4 Revival: Una CPU de 20 años de antigüedad ejecuta el modelo grande Meta Llama 3
Recientemente, el canal técnico de YouTube Fully Buffered llevó a cabo un experimento impresionante y riguroso: lograron ejecutar con éxito el último modelo grande de Meta, Llama 3.2 3B, en un procesador Pentium 4 641, un chip lanzado en 2006.Esta p
Pentium 4 Revival: Una CPU de 20 años de antigüedad ejecuta el modelo grande Meta Llama 3
Recientemente, el canal técnico de YouTube Fully Buffered llevó a cabo un experimento impresionante y riguroso: lograron ejecutar con éxito el último modelo grande de Meta, Llama 3.2 3B, en un procesador Pentium 4 641, un chip lanzado en 2006.Esta p

Descubre los mejores creadores de vídeos con IA para podcasters de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que convierten tu audio en atractivos vídeos de «talking head» sin esfuerzo. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. Aprovecha ahora tu ventaja en la narración visual.
10 herramientas
xix.ai

Descubre las mejores herramientas de rol basadas en IA de 2026 para crear narrativas envolventes. La selección de XIX.AI incluye potentes asistentes revolucionarios que te permitirán desarrollar una narrativa creativa y una gran profundidad emocional. Compara las opciones gratuitas con las de pago mediante pruebas reales. Empieza hoy mismo tu viaje único.
10 herramientas
xix.ai

¡Descubre las mejores herramientas de voz con IA de 2026 para desarrolladores de videojuegos! La lista seleccionada por XIX.AI incluye soluciones de primera categoría que marcarán un antes y un después, y que te permitirán ahorrar tiempo y dinero en la locución de juegos de rol y novelas visuales. Explora comparativas entre opciones gratuitas y de pago, pruebas en condiciones reales y clasificaciones que se actualizan semanalmente. ¡Encuentra hoy mismo tu herramienta de voz perfecta!
10 herramientas
xix.ai

Descubra los mejores herramientas de repetición espacial de IA para 2026, seleccionadas por XIX.AI. Nuestras opciones más recomendadas y revolucionarias ayudan a estudiantes de medicina y derecho a optimizar sus horarios de estudio para lograr un mayor retención del conocimiento. Compare las opciones gratuitas con las pagas mediante pruebas reales y clasificaciones actualizadas semanalmente. Despliegue todo su potencial de aprendizaje ahora mismo.
10 herramientas
xix.ai

Las mejores plataformas de IA para convertir texto en vídeo de 2026: las herramientas mejor valoradas para la redacción de guiones y la narración visual. Descubre soluciones potentes y revolucionarias para transformar tu texto en vídeos atractivos. Compara las opciones gratuitas con las de pago gracias a nuestras clasificaciones, que se actualizan semanalmente, y a nuestras pruebas en condiciones reales. Encuentra la plataforma perfecta para potenciar tu creatividad y productividad. Explora la selección cuidada de XIX.AI.
10 herramientas
xix.ai

2026 Últimas novedades: Descubra los mejores herramientas de inteligencia artificial para diseñar flujos de trabajo automatizados complejos a través del lenguaje natural. Nuestra lista seleccionada incluye las plataformas más reconocidas y potentes para una automatización de tareas sin problemas y una gestión inteligente de procesos. Compare opciones gratuitas y pagadas con información basada en casos reales. Despliegue todo su potencial con las clasificaciones actualizadas semanalmente por expertos de XIX.AI.
10 herramientas
xix.ai

Just tried the demo and honestly blown away by how natural the lip-sync feels now! 😮 Always thought AI dubbing sounded a bit robotic, but this seems like a huge leap. Wonder if this will start being used in indie films or even gaming soon? The open-source move is pretty bold too—curious to see how other companies respond.













