
















 Heim
Heim
Alibabas Tongyi stellt Fun-CineForge vor: Open-Source-KI-Modell ermöglicht Sprachsynthese in Kinoqualität
Das Alibaba Tongyi Lab hat am 16. März das multimodale Modell „Fun-CineForge“ für die filmspitzen, szenarioübergreifende Sprachsynthese offiziell vorgestellt und als Open-Source-Projekt veröffentlicht. Dieses Modell befasst sich mit zentralen Herausforderungen bei der KI-Synchronisation, darunter Lippensynchronisationsfehler, mangelnder emotionaler Ausdruck und uneinheitliche Stimmcharakteristika bei mehreren Charakteren. Zudem führt es eine hochwertige Methode zur Erstellung von Datensätzen ein.
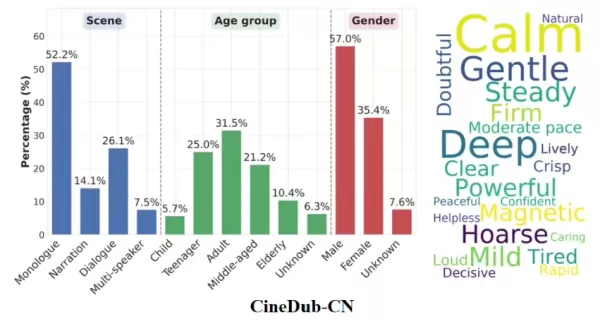
Technisch gesehen ist Fun-CineForge Vorreiter beim Konzept der „zeitlichen Modalität“. Im Gegensatz zu herkömmlichen Modellen, die sich ausschließlich auf Text oder Bildmaterial konzentrieren, stellt es durch präzise Zeitstempelsteuerung sicher, dass die Sprachsynthese innerhalb genauer Zeitintervalle erfolgt. Selbst in komplexen Filmszenen mit verdeckten Charakteren, häufigen Kameraschnitten oder unscharfen Gesichtern gewährleistet das Modell ein hohes Maß an audiovisueller Synchronisation und die Einhaltung von Anweisungen.
Die begleitende Open-Source-Pipeline zur Erstellung des CineDub-Datensatzes ist eine weitere wichtige Innovation. Tongyi Lab nutzte die Kettengedanken-Argumentation großer Sprachmodelle, um rohes Filmmaterial automatisch in strukturierte Daten umzuwandeln, wodurch der Bedarf an manueller Annotation erheblich reduziert wurde. Dieser Prozess erreicht eine Wortfehlerrate von etwa 1 % und eine Sprecher-Diarisierungsfehlerrate von nur 1,20 %, was eine äußerst wettbewerbsfähige Trainingsgrundlage für große Modelle bietet.
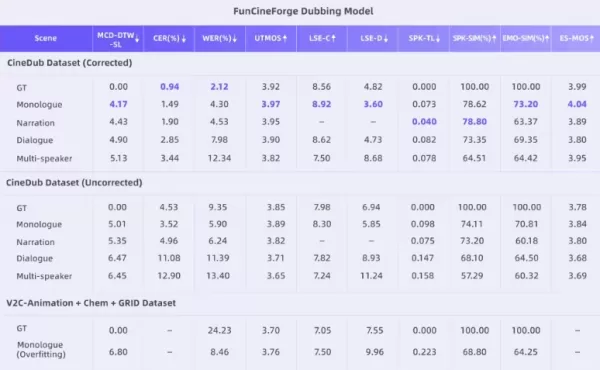
Fun-CineForge ist nun auf GitHub, HuggingFace und in der ModelScope-Community verfügbar und unterstützt die Inferenz für Videoclips mit einer Länge von bis zu 30 Sekunden. Es zeichnet sich nicht nur bei Monologen einzelner Sprecher aus, sondern bietet auch professionelle Unterstützung für Duett- und Mehrsprecher-Dialogszenarien. Dieser Fortschritt signalisiert die Entwicklung der KI-Sprachtechnologie von grundlegenden Kundendienst- und Assistenzfunktionen hin zu hochwertiger Animation und Film-Postproduktion.
GitHub: https://github.com/FunAudioLLM/FunCineForge
HuggingFace: https://huggingface.co/FunAudioLLM/Fun-CineForge
ModelScope: https://www.modelscope.cn/models/FunAudioLLM/Fun-CineForge/
Verwandter Artikel
 Der Bezirk Shangcheng in Hangzhou führt die ersten „goldenen zehn Maßnahmen“ der audiovisuellen Industrie in Zhejiang unter der Schirmherrschaft von AIGC durch und stellt dabei einen Industriefonds in Höhe von 5 Milliarden Yuan bereit.
Am 16. fand die AIGC Audio-Visual Industry Innovation Ecosystem Conference im Bezirk Shangcheng in Hangzhou statt. Während der Veranstaltung kündigte die Provinz ihre erste spezielle Politik für die AIGC-Audio-Visual-Branche an – „Die Goldenen Zehn“.
Das MIIT bittet die Öffentlichkeit um Rückmeldungen zu 121 Branchenstandards, darunter auch das Protokoll zum Kontext von KI-Modellen.
Das chinesische Ministerium für Industrie und Informationstechnologie hat offiziell eine Mitteilung veröffentlicht, in der es die Öffentlichkeit um Rückmeldungen zu 121 Standardisierungsprojekten im Industriebereich bittet, darunter auch die „Anforde
OpenAI arbeitet mit dem US-Verteidigungsministerium zusammen – Die Zahl der Deinstallierungen von ChatGPT steigt um 295 Prozent
Öffentliche Empörung: OpenAI’s Militärpartnerschaft löst eine Welle von Abmeldungen ausKürzlich kündigte der führende KI-Anbieter OpenAI eine enge Partnerschaft mit dem US-Verteidigungsministerium an, bei der seine KI-Modelle in hochgeheime militäri
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
Der Bezirk Shangcheng in Hangzhou führt die ersten „goldenen zehn Maßnahmen“ der audiovisuellen Industrie in Zhejiang unter der Schirmherrschaft von AIGC durch und stellt dabei einen Industriefonds in Höhe von 5 Milliarden Yuan bereit.
Am 16. fand die AIGC Audio-Visual Industry Innovation Ecosystem Conference im Bezirk Shangcheng in Hangzhou statt. Während der Veranstaltung kündigte die Provinz ihre erste spezielle Politik für die AIGC-Audio-Visual-Branche an – „Die Goldenen Zehn“.
Das MIIT bittet die Öffentlichkeit um Rückmeldungen zu 121 Branchenstandards, darunter auch das Protokoll zum Kontext von KI-Modellen.
Das chinesische Ministerium für Industrie und Informationstechnologie hat offiziell eine Mitteilung veröffentlicht, in der es die Öffentlichkeit um Rückmeldungen zu 121 Standardisierungsprojekten im Industriebereich bittet, darunter auch die „Anforde
OpenAI arbeitet mit dem US-Verteidigungsministerium zusammen – Die Zahl der Deinstallierungen von ChatGPT steigt um 295 Prozent
Öffentliche Empörung: OpenAI’s Militärpartnerschaft löst eine Welle von Abmeldungen ausKürzlich kündigte der führende KI-Anbieter OpenAI eine enge Partnerschaft mit dem US-Verteidigungsministerium an, bei der seine KI-Modelle in hochgeheime militäri
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
 Die besten KI-Sprachtools für Indie-Spieleentwickler: Sparen Sie Zeit bei der Sprachausgabe für RPGs und Visual Novels
Die besten KI-Sprachtools für Indie-Spieleentwickler: Sparen Sie Zeit bei der Sprachausgabe für RPGs und Visual Novels
Entdecken Sie die besten KI-Sprachtools für Spieleentwickler im Jahr 2026! Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, mit denen Sie bei der Sprachausgabe für RPGs und Visual Novels Zeit und Geld sparen. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings. Finden Sie noch heute Ihr perfektes Sprachtool!
 10 Tools
10 Tools
 xix.ai
Bildung und Lernen
Die besten AI-basierten Werkzeuge für geplantes Wiederholen: Optimieren Sie Ihr Lernplan für Medizinstudenten und Jurastudenten
xix.ai
Bildung und Lernen
Die besten AI-basierten Werkzeuge für geplantes Wiederholen: Optimieren Sie Ihr Lernplan für Medizinstudenten und Jurastudenten
Entdecken Sie die besten KI-basierten Wiederholungstools für das Jahr 2026, ausgewählt von XIX.AI. Unsere hochbewerteten, bahnbrechenden Tools helfen Medizinstudenten und Jurastudenten dabei, ihre Lernpläne so zu optimieren, dass das Gelernte optimal im Gedächtnis bleibt. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie jetzt Ihren Vorsprung beim Lernen.
10 Tools
xix.ai
Videoerstellung
Die besten KI-Plattformen für die Umwandlung von Text in Video zum Verfassen von Drehbüchern und für visuelles Storytelling
Die besten KI-Plattformen für die Umwandlung von Text in Video im Jahr 2026: Erstklassige Tools für das Verfassen von Drehbüchern und visuelles Storytelling. Entdecken Sie leistungsstarke, bahnbrechende Lösungen, mit denen Sie Ihren Text in fesselnde Videos verwandeln können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand unserer wöchentlich aktualisierten Ranglisten und Praxistests. Finden Sie die perfekte Plattform, um Ihre Kreativität und Produktivität zu steigern. Entdecken Sie die sorgfältig zusammengestellte Auswahl bei XIX.AI.
10 Tools
xix.ai
Chatbot
KI-Multi-Agent-Orchestratoren: Gestaltung komplexer automatisierter Arbeitsabläufe mithilfe natürlicher Sprache
2026 Neuestes: Entdecken Sie die besten AI-Multi-Agenten-Orchestratoren, um mithilfe natürlicher Sprache komplexe automatisierte Arbeitsabläufe zu gestalten. Unsere sorgfältig ausgewählte Liste enthält hochbewertete, leistungsstarke Plattformen für reibungslose Aufgabenerstellung und intelligente Prozessverwaltung. Vergleichen Sie kostenlose und kostenpflichtige Optionen unter Berücksichtigung praktischer Erfahrungen. Nutzen Sie die wöchentlich aktualisierten Rankings von XIX.AI, um einen Vorsprung durch künstliche Intelligenz zu erlangen.
10 Tools
xix.ai
Bildbearbeitung
Die besten AI-Softwarelösungen zur Geräuschreduzierung: Beseitigen Sie Körnchen und Artefakte in Nachtaufnahmen bei schwachem Licht.
Entdecken Sie die besten KI-basierten Softwarelösungen zur Rauschreduzierung für Nachtfotografie in schwach beleuchteten Umgebungen im Jahr 2026. Unsere hochrangig bewertete, sorgfältig ausgewählte Liste vergleicht kostenlose und kostenpflichtige Tools und enthält Ergebnisse aus realen Tests sowie wöchentlich aktualisierte Ranglisten. Entfernen Sie mühelos Unreinheiten und Artefakte aus Ihren Bildern – eröffnen Sie mit XIX.AI den Vorteil der KI-Technologie für Ihre Fotografie.
10 Tools
xix.ai
Chatbot
Die besten Generatoren für individuelle KI-Freundinnen: Entwirf einzigartige Persönlichkeiten, Hobbys und Hintergrundgeschichten
Entdecken Sie auf XIX.AI die besten Generatoren für individuelle KI-Freundinnen des Jahres 2026. Stöbern Sie in unserer sorgfältig zusammengestellten Liste der besten Angebote, um einzigartige Persönlichkeiten, Hobbys und tiefgründige Hintergrundgeschichten zu entwerfen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Holen Sie sich noch heute Ihre perfekte kreative Begleiterin.
10 Tools
xix.ai

 Kommentare (1)
Kommentare (1)
![NicholasThomas]()
Just tried the demo and honestly blown away by how natural the lip-sync feels now! 😮 Always thought AI dubbing sounded a bit robotic, but this seems like a huge leap. Wonder if this will start being used in indie films or even gaming soon? The open-source move is pretty bold too—curious to see how other companies respond.
Das Alibaba Tongyi Lab hat am 16. März das multimodale Modell „Fun-CineForge“ für die filmspitzen, szenarioübergreifende Sprachsynthese offiziell vorgestellt und als Open-Source-Projekt veröffentlicht. Dieses Modell befasst sich mit zentralen Herausforderungen bei der KI-Synchronisation, darunter Lippensynchronisationsfehler, mangelnder emotionaler Ausdruck und uneinheitliche Stimmcharakteristika bei mehreren Charakteren. Zudem führt es eine hochwertige Methode zur Erstellung von Datensätzen ein.
Technisch gesehen ist Fun-CineForge Vorreiter beim Konzept der „zeitlichen Modalität“. Im Gegensatz zu herkömmlichen Modellen, die sich ausschließlich auf Text oder Bildmaterial konzentrieren, stellt es durch präzise Zeitstempelsteuerung sicher, dass die Sprachsynthese innerhalb genauer Zeitintervalle erfolgt. Selbst in komplexen Filmszenen mit verdeckten Charakteren, häufigen Kameraschnitten oder unscharfen Gesichtern gewährleistet das Modell ein hohes Maß an audiovisueller Synchronisation und die Einhaltung von Anweisungen.
Die begleitende Open-Source-Pipeline zur Erstellung des CineDub-Datensatzes ist eine weitere wichtige Innovation. Tongyi Lab nutzte die Kettengedanken-Argumentation großer Sprachmodelle, um rohes Filmmaterial automatisch in strukturierte Daten umzuwandeln, wodurch der Bedarf an manueller Annotation erheblich reduziert wurde. Dieser Prozess erreicht eine Wortfehlerrate von etwa 1 % und eine Sprecher-Diarisierungsfehlerrate von nur 1,20 %, was eine äußerst wettbewerbsfähige Trainingsgrundlage für große Modelle bietet.
Fun-CineForge ist nun auf GitHub, HuggingFace und in der ModelScope-Community verfügbar und unterstützt die Inferenz für Videoclips mit einer Länge von bis zu 30 Sekunden. Es zeichnet sich nicht nur bei Monologen einzelner Sprecher aus, sondern bietet auch professionelle Unterstützung für Duett- und Mehrsprecher-Dialogszenarien. Dieser Fortschritt signalisiert die Entwicklung der KI-Sprachtechnologie von grundlegenden Kundendienst- und Assistenzfunktionen hin zu hochwertiger Animation und Film-Postproduktion.
GitHub: https://github.com/FunAudioLLM/FunCineForge
HuggingFace: https://huggingface.co/FunAudioLLM/Fun-CineForge
ModelScope: https://www.modelscope.cn/models/FunAudioLLM/Fun-CineForge/










 Der Bezirk Shangcheng in Hangzhou führt die ersten „goldenen zehn Maßnahmen“ der audiovisuellen Industrie in Zhejiang unter der Schirmherrschaft von AIGC durch und stellt dabei einen Industriefonds in Höhe von 5 Milliarden Yuan bereit.
Am 16. fand die AIGC Audio-Visual Industry Innovation Ecosystem Conference im Bezirk Shangcheng in Hangzhou statt. Während der Veranstaltung kündigte die Provinz ihre erste spezielle Politik für die AIGC-Audio-Visual-Branche an – „Die Goldenen Zehn“.
Der Bezirk Shangcheng in Hangzhou führt die ersten „goldenen zehn Maßnahmen“ der audiovisuellen Industrie in Zhejiang unter der Schirmherrschaft von AIGC durch und stellt dabei einen Industriefonds in Höhe von 5 Milliarden Yuan bereit.
Am 16. fand die AIGC Audio-Visual Industry Innovation Ecosystem Conference im Bezirk Shangcheng in Hangzhou statt. Während der Veranstaltung kündigte die Provinz ihre erste spezielle Politik für die AIGC-Audio-Visual-Branche an – „Die Goldenen Zehn“.
 Das MIIT bittet die Öffentlichkeit um Rückmeldungen zu 121 Branchenstandards, darunter auch das Protokoll zum Kontext von KI-Modellen.
Das chinesische Ministerium für Industrie und Informationstechnologie hat offiziell eine Mitteilung veröffentlicht, in der es die Öffentlichkeit um Rückmeldungen zu 121 Standardisierungsprojekten im Industriebereich bittet, darunter auch die „Anforde
Das MIIT bittet die Öffentlichkeit um Rückmeldungen zu 121 Branchenstandards, darunter auch das Protokoll zum Kontext von KI-Modellen.
Das chinesische Ministerium für Industrie und Informationstechnologie hat offiziell eine Mitteilung veröffentlicht, in der es die Öffentlichkeit um Rückmeldungen zu 121 Standardisierungsprojekten im Industriebereich bittet, darunter auch die „Anforde
 OpenAI arbeitet mit dem US-Verteidigungsministerium zusammen – Die Zahl der Deinstallierungen von ChatGPT steigt um 295 Prozent
Öffentliche Empörung: OpenAI’s Militärpartnerschaft löst eine Welle von Abmeldungen ausKürzlich kündigte der führende KI-Anbieter OpenAI eine enge Partnerschaft mit dem US-Verteidigungsministerium an, bei der seine KI-Modelle in hochgeheime militäri
OpenAI arbeitet mit dem US-Verteidigungsministerium zusammen – Die Zahl der Deinstallierungen von ChatGPT steigt um 295 Prozent
Öffentliche Empörung: OpenAI’s Militärpartnerschaft löst eine Welle von Abmeldungen ausKürzlich kündigte der führende KI-Anbieter OpenAI eine enge Partnerschaft mit dem US-Verteidigungsministerium an, bei der seine KI-Modelle in hochgeheime militäri

Entdecken Sie die besten KI-Sprachtools für Spieleentwickler im Jahr 2026! Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, mit denen Sie bei der Sprachausgabe für RPGs und Visual Novels Zeit und Geld sparen. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings. Finden Sie noch heute Ihr perfektes Sprachtool!
10 Tools
xix.ai

Entdecken Sie die besten KI-basierten Wiederholungstools für das Jahr 2026, ausgewählt von XIX.AI. Unsere hochbewerteten, bahnbrechenden Tools helfen Medizinstudenten und Jurastudenten dabei, ihre Lernpläne so zu optimieren, dass das Gelernte optimal im Gedächtnis bleibt. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie jetzt Ihren Vorsprung beim Lernen.
10 Tools
xix.ai

Die besten KI-Plattformen für die Umwandlung von Text in Video im Jahr 2026: Erstklassige Tools für das Verfassen von Drehbüchern und visuelles Storytelling. Entdecken Sie leistungsstarke, bahnbrechende Lösungen, mit denen Sie Ihren Text in fesselnde Videos verwandeln können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand unserer wöchentlich aktualisierten Ranglisten und Praxistests. Finden Sie die perfekte Plattform, um Ihre Kreativität und Produktivität zu steigern. Entdecken Sie die sorgfältig zusammengestellte Auswahl bei XIX.AI.
10 Tools
xix.ai

2026 Neuestes: Entdecken Sie die besten AI-Multi-Agenten-Orchestratoren, um mithilfe natürlicher Sprache komplexe automatisierte Arbeitsabläufe zu gestalten. Unsere sorgfältig ausgewählte Liste enthält hochbewertete, leistungsstarke Plattformen für reibungslose Aufgabenerstellung und intelligente Prozessverwaltung. Vergleichen Sie kostenlose und kostenpflichtige Optionen unter Berücksichtigung praktischer Erfahrungen. Nutzen Sie die wöchentlich aktualisierten Rankings von XIX.AI, um einen Vorsprung durch künstliche Intelligenz zu erlangen.
10 Tools
xix.ai

Entdecken Sie die besten KI-basierten Softwarelösungen zur Rauschreduzierung für Nachtfotografie in schwach beleuchteten Umgebungen im Jahr 2026. Unsere hochrangig bewertete, sorgfältig ausgewählte Liste vergleicht kostenlose und kostenpflichtige Tools und enthält Ergebnisse aus realen Tests sowie wöchentlich aktualisierte Ranglisten. Entfernen Sie mühelos Unreinheiten und Artefakte aus Ihren Bildern – eröffnen Sie mit XIX.AI den Vorteil der KI-Technologie für Ihre Fotografie.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten Generatoren für individuelle KI-Freundinnen des Jahres 2026. Stöbern Sie in unserer sorgfältig zusammengestellten Liste der besten Angebote, um einzigartige Persönlichkeiten, Hobbys und tiefgründige Hintergrundgeschichten zu entwerfen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Holen Sie sich noch heute Ihre perfekte kreative Begleiterin.
10 Tools
xix.ai

Just tried the demo and honestly blown away by how natural the lip-sync feels now! 😮 Always thought AI dubbing sounded a bit robotic, but this seems like a huge leap. Wonder if this will start being used in indie films or even gaming soon? The open-source move is pretty bold too—curious to see how other companies respond.













