




微軟研究發現更多 AI 代幣會增加推理錯誤
LLM 推理效率的新觀點
微軟的最新研究顯示,大型語言模型中的先進推理技術並不能在不同的人工智能系統中產生一致的改進。他們的突破性研究分析了九個領先的基礎模型在推理過程中對各種擴充方法的反應。
評估推理時間縮放方法
研究團隊針對三種不同的縮放技術實施了嚴格的測試方法:
- 傳統的思考鏈提示
- 並行答案產生與彙總
- 透過回饋迴圈進行順序精煉
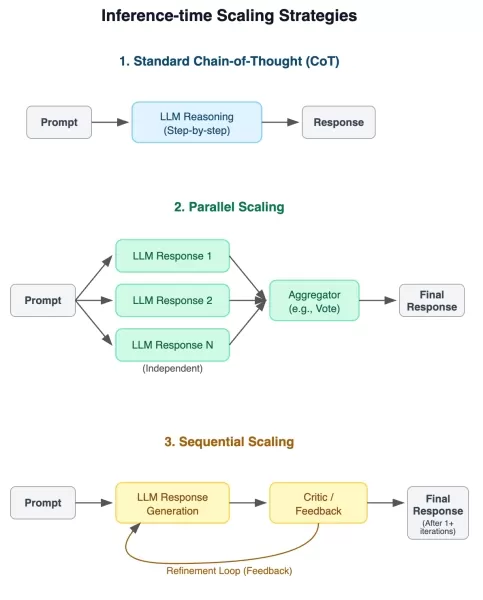
評估推理效能的實驗框架 八項綜合基準提供了跨學科的挑戰性測試情境,包括數學、科學推理、複雜問題解決和空間分析。有幾個評估的難度是分等級的,以檢視效能如何隨著問題複雜性而遞增。
推理能力的重要發現
對於人工智能實務人員而言,這項全面的評估產生了幾項重要的啟發:
- 模型架構和任務領域不同,縮放技術帶來的效能提升也有很大差異
- 較長的回應時間與較好的解決方案並不一致
- 即使是相同的查詢,計算成本也會出現不可預測的波動
- 傳統模型有時可以透過廣泛的擴充來匹配專門的推理模型
- 驗證機制有希望提高效率
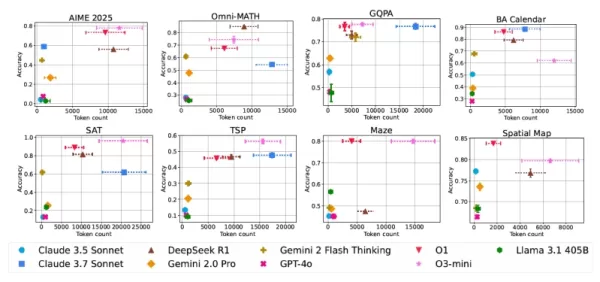
不同模型和任務的效能相對於計算成本 對人工智能發展的實際影響
這些發現對企業的 AI 實作有重大影響:
成本的可預測性是一大挑戰,即使是正確的答案,代幣的使用量也顯示出很大的差異。"微軟研究人員 Besmira Nushi 指出:「開發人員需要具有一致計算模式的模型。
這項研究也指出回應長度是模型可信度的潛在指標,過長的回應通常代表超過特定臨界值的錯誤解決方案。
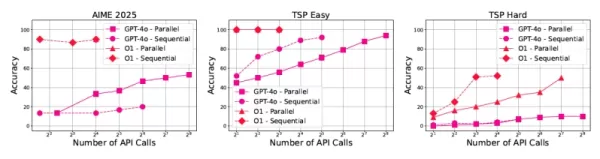
GPT-4o 性能中的推理縮放模式 高效推理系統的未來
這項研究強調了未來發展的多個前景看好的方向:
Nushi 解釋說:「驗證機制可以改變我們處理推理問題的方式,」他建議將現有的企業驗證系統適用於 AI 應用。這種整合將允許自然語言介面利用專門的驗證邏輯。
這項研究強調,隨著人工智慧系統承接越來越複雜的現實世界任務,人們越來越需要能平衡推理準確性與可預測計算成本的解決方案。
相關文章
 為何 LLM 忽視指示及如何有效解決問題
瞭解大型語言模型跳過指令的原因大型語言模型 (LLM) 已經改變了我們與人工智能互動的方式,讓從會話介面到自動內容產生與程式輔助等先進應用程式得以實現。然而,使用者經常會遇到一個令人沮喪的限制:這些模型偶爾會忽略特定的指令,尤其是在複雜或冗長的提示中。這種任務執行不完整的問題不僅會影響輸出品質,也會降低使用者對這些系統的信心。研究這種行為背後的根本原因,可以為優化 LLM 互動提供寶貴的啟示。
Google 的 Gemini 應用程式新增即時 AI 視訊、深度研究和新功能 (120 個字)
Google 在 I/O 2025 開發者大會上發表了重大的 Gemini AI 強化功能,擴展多模態功能、引進下一代 AI 模型,並加強整個產品組合的生態系統整合。關鍵的 Gemini Live 推出Google 已正式向所有 iOS 和 Android 使用者推出 Gemini Live 的視覺辨識功能。這項更新以尖端的 Project Astra 技術為基礎,結合裝置攝影機或螢幕分享的即時視
Google Cloud 為科學研究與發現的突破提供動力
數位革命正透過前所未有的計算能力改變科學方法。尖端技術現在可增強理論框架和實驗室實驗,透過精密模擬和大數據分析,推動各學科的突破。透過策略性地投資於基礎研究、可擴充的雲端架構和人工智慧開發,我們建立了一個加速科學進步的生態系統。我們的貢獻橫跨醫藥研究、氣候建模和奈米技術等領域的突破性創新,並輔以世界級的運算基礎架構、雲端原生軟體解決方案和新一代的生成式人工智慧平台。Google DeepMind
評論 (0)
0/200
為何 LLM 忽視指示及如何有效解決問題
瞭解大型語言模型跳過指令的原因大型語言模型 (LLM) 已經改變了我們與人工智能互動的方式,讓從會話介面到自動內容產生與程式輔助等先進應用程式得以實現。然而,使用者經常會遇到一個令人沮喪的限制:這些模型偶爾會忽略特定的指令,尤其是在複雜或冗長的提示中。這種任務執行不完整的問題不僅會影響輸出品質,也會降低使用者對這些系統的信心。研究這種行為背後的根本原因,可以為優化 LLM 互動提供寶貴的啟示。
Google 的 Gemini 應用程式新增即時 AI 視訊、深度研究和新功能 (120 個字)
Google 在 I/O 2025 開發者大會上發表了重大的 Gemini AI 強化功能,擴展多模態功能、引進下一代 AI 模型,並加強整個產品組合的生態系統整合。關鍵的 Gemini Live 推出Google 已正式向所有 iOS 和 Android 使用者推出 Gemini Live 的視覺辨識功能。這項更新以尖端的 Project Astra 技術為基礎,結合裝置攝影機或螢幕分享的即時視
Google Cloud 為科學研究與發現的突破提供動力
數位革命正透過前所未有的計算能力改變科學方法。尖端技術現在可增強理論框架和實驗室實驗,透過精密模擬和大數據分析,推動各學科的突破。透過策略性地投資於基礎研究、可擴充的雲端架構和人工智慧開發,我們建立了一個加速科學進步的生態系統。我們的貢獻橫跨醫藥研究、氣候建模和奈米技術等領域的突破性創新,並輔以世界級的運算基礎架構、雲端原生軟體解決方案和新一代的生成式人工智慧平台。Google DeepMind
評論 (0)
0/200
LLM 推理效率的新觀點
微軟的最新研究顯示,大型語言模型中的先進推理技術並不能在不同的人工智能系統中產生一致的改進。他們的突破性研究分析了九個領先的基礎模型在推理過程中對各種擴充方法的反應。
評估推理時間縮放方法
研究團隊針對三種不同的縮放技術實施了嚴格的測試方法:
- 傳統的思考鏈提示
- 並行答案產生與彙總
- 透過回饋迴圈進行順序精煉
八項綜合基準提供了跨學科的挑戰性測試情境,包括數學、科學推理、複雜問題解決和空間分析。有幾個評估的難度是分等級的,以檢視效能如何隨著問題複雜性而遞增。
推理能力的重要發現
對於人工智能實務人員而言,這項全面的評估產生了幾項重要的啟發:
- 模型架構和任務領域不同,縮放技術帶來的效能提升也有很大差異
- 較長的回應時間與較好的解決方案並不一致
- 即使是相同的查詢,計算成本也會出現不可預測的波動
- 傳統模型有時可以透過廣泛的擴充來匹配專門的推理模型
- 驗證機制有希望提高效率
對人工智能發展的實際影響
這些發現對企業的 AI 實作有重大影響:
成本的可預測性是一大挑戰,即使是正確的答案,代幣的使用量也顯示出很大的差異。"微軟研究人員 Besmira Nushi 指出:「開發人員需要具有一致計算模式的模型。
這項研究也指出回應長度是模型可信度的潛在指標,過長的回應通常代表超過特定臨界值的錯誤解決方案。
高效推理系統的未來
這項研究強調了未來發展的多個前景看好的方向:
Nushi 解釋說:「驗證機制可以改變我們處理推理問題的方式,」他建議將現有的企業驗證系統適用於 AI 應用。這種整合將允許自然語言介面利用專門的驗證邏輯。
這項研究強調,隨著人工智慧系統承接越來越複雜的現實世界任務,人們越來越需要能平衡推理準確性與可預測計算成本的解決方案。










 為何 LLM 忽視指示及如何有效解決問題
瞭解大型語言模型跳過指令的原因大型語言模型 (LLM) 已經改變了我們與人工智能互動的方式,讓從會話介面到自動內容產生與程式輔助等先進應用程式得以實現。然而,使用者經常會遇到一個令人沮喪的限制:這些模型偶爾會忽略特定的指令,尤其是在複雜或冗長的提示中。這種任務執行不完整的問題不僅會影響輸出品質,也會降低使用者對這些系統的信心。研究這種行為背後的根本原因,可以為優化 LLM 互動提供寶貴的啟示。
Google 的 Gemini 應用程式新增即時 AI 視訊、深度研究和新功能 (120 個字)
Google 在 I/O 2025 開發者大會上發表了重大的 Gemini AI 強化功能,擴展多模態功能、引進下一代 AI 模型,並加強整個產品組合的生態系統整合。關鍵的 Gemini Live 推出Google 已正式向所有 iOS 和 Android 使用者推出 Gemini Live 的視覺辨識功能。這項更新以尖端的 Project Astra 技術為基礎,結合裝置攝影機或螢幕分享的即時視
為何 LLM 忽視指示及如何有效解決問題
瞭解大型語言模型跳過指令的原因大型語言模型 (LLM) 已經改變了我們與人工智能互動的方式,讓從會話介面到自動內容產生與程式輔助等先進應用程式得以實現。然而,使用者經常會遇到一個令人沮喪的限制:這些模型偶爾會忽略特定的指令,尤其是在複雜或冗長的提示中。這種任務執行不完整的問題不僅會影響輸出品質,也會降低使用者對這些系統的信心。研究這種行為背後的根本原因,可以為優化 LLM 互動提供寶貴的啟示。
Google 的 Gemini 應用程式新增即時 AI 視訊、深度研究和新功能 (120 個字)
Google 在 I/O 2025 開發者大會上發表了重大的 Gemini AI 強化功能,擴展多模態功能、引進下一代 AI 模型,並加強整個產品組合的生態系統整合。關鍵的 Gemini Live 推出Google 已正式向所有 iOS 和 Android 使用者推出 Gemini Live 的視覺辨識功能。這項更新以尖端的 Project Astra 技術為基礎,結合裝置攝影機或螢幕分享的即時視
 Google Cloud 為科學研究與發現的突破提供動力
數位革命正透過前所未有的計算能力改變科學方法。尖端技術現在可增強理論框架和實驗室實驗,透過精密模擬和大數據分析,推動各學科的突破。透過策略性地投資於基礎研究、可擴充的雲端架構和人工智慧開發,我們建立了一個加速科學進步的生態系統。我們的貢獻橫跨醫藥研究、氣候建模和奈米技術等領域的突破性創新,並輔以世界級的運算基礎架構、雲端原生軟體解決方案和新一代的生成式人工智慧平台。Google DeepMind
Google Cloud 為科學研究與發現的突破提供動力
數位革命正透過前所未有的計算能力改變科學方法。尖端技術現在可增強理論框架和實驗室實驗,透過精密模擬和大數據分析,推動各學科的突破。透過策略性地投資於基礎研究、可擴充的雲端架構和人工智慧開發,我們建立了一個加速科學進步的生態系統。我們的貢獻橫跨醫藥研究、氣候建模和奈米技術等領域的突破性創新,並輔以世界級的運算基礎架構、雲端原生軟體解決方案和新一代的生成式人工智慧平台。Google DeepMind
0/200
頭號新聞
Gemini 2.5 Pro現在比Claude,GPT-4O更便宜,更便宜
2025頂級AI影片生成器:Pika Labs與其他對比
AI配音:真實聲音創作終極指南
Cambium的AI將垃圾木頭變成木材
Openai增強了AI語音助手以進行更好的聊天
如何確保您的數據值得信賴AI集成
NotebookLM在全球範圍內擴展,添加幻燈片並增強了事實檢查
對美國數據中心的調整可以解鎖76 GW的新電源容量
Google利用AI暫停了超過3900萬的廣告帳戶,以涉嫌欺詐
AI語音克隆:掌握語音轉換的終極指南
更多
精選
更多

Claude
認識Claude:您的AI助手智能工作是否希望您有一個知識淵博的同事,他隨時準備

Cici AI
你是否曾經好奇過Cici AI到底是什麼?讓我告訴你,它不僅僅是一個普通的AI聊

Gemini
有沒有想過關於雙子座的嗡嗡聲是什麼?讓我為您分解。雙子座是由Google Dee

DeepSeek
曾經想過什麼是全部意見?讓我為您分解。 DeepSeek不僅是另一個AI平台;無

Grok
聽說過Grok嗎?這是Xai的Nifty AI助手,這一切都是為了給您直接的勺子

ChatGPT
有沒有想過什麼是什麼?好吧,讓我為您分解它 - 聊天不僅僅是您在技術領域的普通喬

OpenAI
有沒有想過Openai周圍的嗡嗡聲是什麼?好吧,讓我為您分解。 Openai不僅

Tencent Hunyuan
騰訊hunyuan-large,是嗎?就像騰訊技術巨頭開發的AI模型的瑞士軍刀一

Qwen AI
有沒有想過Qwen AI是什麼?好吧,讓我向您介紹阿里巴巴雲的這顆寶石。 Qwe

Runway
有沒有想過如何將您的常規視頻剪輯變成非凡的東西?好吧,讓我向您介紹跑道,這是一個



