
















 首頁
首頁新基準測試質疑人工智慧代理程式的工作就緒性
近兩年前,微軟執行長薩蒂亞·納德拉曾預言人工智慧將重塑知識型工作——涵蓋律師、投資銀行家、圖書館員、會計師、資訊科技專業人員等白領職域。
然而,儘管基礎模型取得重大進展,知識型工作的轉型卻遲遲未能實現。儘管模型在深度研究與代理規劃方面表現出色,但多數白領職業所受的衝擊相對有限,箇中原因仍不明朗。
這已成為人工智慧領域的重大謎題。訓練數據領導者Mercor的最新研究現正提供關鍵洞見。
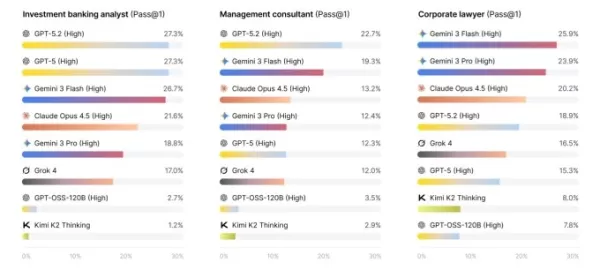
該研究評估頂尖AI模型處理諮詢、投資銀行與法律等真實白領任務的能力,進而創建了APEX-Agents基準測試——目前所有AI實驗室皆未能通過。當面對真實專業人士的提問時,即使最優秀的模型正確回答率也不足四分之一,多數情況下會返回錯誤答案或完全無回應。
參與研究的Mercor執行長布倫丹·富迪指出,模型主要弱點在於跨領域資訊整合能力——這正是人類知識工作的核心要素。
「此基準測試的關鍵創新在於,我們建構了模擬真實專業服務的完整環境,」富迪向TechCrunch解釋道:「現實工作中不會有人將所有背景資訊集中提供給我們,實際操作需橫跨Slack、Google雲端硬碟等多元工具。」對多數智能體型AI模型而言,這類跨領域推理仍存在不一致性。
截圖 測試情境源自Mercor專家市場的真實從業者,由他們設計查詢內容並定義成功答題標準。檢視Hugging Face平台公開的試題即可窺見任務複雜性。
Techcrunch活動 Disrupt 2026 門票:限時優惠
門票現已開售!限時優惠最高可省680美元,前500名註冊者更享+1通行證五折優惠。TechCrunch Disrupt匯聚Google Cloud、Netflix、Microsoft、Box、a16z、Hugging Face等頂尖企業領袖,透過250多場專題議程助您加速成長、強化競爭優勢。 與數百家創新新創企業建立連結,參與精心策劃的交流活動,促成合作契機、獲取產業洞見並激發創新靈感。
Disrupt 2026 門票:限時優惠
門票現已開售!限時優惠最高可省680美元,前500名註冊者更可享+1通行證半價優惠。TechCrunch Disrupt匯聚Google Cloud、Netflix、Microsoft、Box、a16z、Hugging Face等頂尖企業領袖,透過250多場專題議程助您加速成長並強化競爭優勢。 與數百家創新新創企業建立連結,參與精心策劃的交流活動,促成合作契機、獲取產業洞見並激發創新靈感。
舊金山 | 2026年10月13-15日 立即註冊 「法規」單元舉例說明:
在歐盟生產系統停機的前48分鐘內,北極星工程團隊將一至兩組包含個人資料的歐盟生產事件日誌打包匯出至美國分析供應商...根據北極星自身政策,能否合理認定此一至兩次日誌匯出符合第49條規範?
正確答案為是,但得出結論需詳細分析該公司內部政策與相關歐盟隱私法規。
此類問題即使對專業人士亦具挑戰性,但研究人員旨在模擬真實工作情境。能可靠解答此類查詢的大型語言模型,未來或可取代眾多執業律師。Foody向TechCrunch表示:「這無疑是當今最重要的經濟議題,該基準測試精準反映了專業人士的實際工作內容。」
OpenAI先前曾以GDPval基準測試專業技能,但APEX-Agents測試存在顯著差異:GDPval評估多領域的廣博知識,而APEX-Agents則衡量系統在特定高價值職業中執行持續性任務的能力。這不僅提升模型挑戰難度,更直接關聯職能自動化的潛在影響。
儘管目前尚無模型能取代投資銀行家的工作,但部分模型表現明顯優於其他系統。Gemini 3 Flash以24%的單次準確率領先群雄,緊隨其後的是23%的GPT-5.2。Opus 4.5、Gemini 3 Pro及GPT-5的得分均約為18%。
儘管初期成果未達預期,但人工智慧領域素以快速突破艱難基準著稱。隨著APEX-Agents測試公開,這對自信能改進的AI實驗室構成公開挑戰——Foody完全預期未來數月將見證此結果。
他向TechCrunch表示:「技術進步速度驚人。現階段將此技術比作每四次任務僅成功一次的實習生尚屬合理,但去年此時成功率僅5%至10%。這種逐年躍進的進步幅度,將迅速產生深遠影響。」
相關文章
 騰訊旗下《小龍夏》表現超乎預期,團隊將伺服器容量擴增10倍,並公開致歉及提供補償
騰訊正式推出全場景AI智能助手「WorkBuddy」,憑藉高度整合與低部署門檻,標誌著大型模型應用層競賽進入新階段。該產品在發布當天便立即引起業界關注。 用戶流量遠超預期,導致相關的騰雲代碼助手(CodeBuddy)出現登入問題及服務不穩定。騰雲團隊隨後發布致歉聲明,表示技術團隊已緊急將容量擴展十倍,目前服務已全面恢復。受影響用戶獲得 5,000 點代碼點數作為補償。業界觀察家將 WorkBudd
Suno 領投方:刪除貼文無法彌補版權訴訟的漏洞
備受矚目的 AI 音樂生成平台 Suno 正面臨一場艱難的版權之爭,而其主要投資人的坦率言論,可能正好提供了對方所期盼的證據。 Menlo Ventures(Suno的核心投資者)合夥人C.C. Gong最近刪除了一則推文,該推文與該公司當前的法律辯護策略直接相悖。在之前的版權訴訟中,Suno 的辯護主要依賴「合理使用」的論點,聲稱 AI 生成的音樂僅僅是一種「工具」,不會直接與受版權保護的原創作
Claude Opus 4.7 正式推出,重視可靠性勝於智能
Anthropic 今年持續保持強勁的開發步調,幾乎每隔一天就會推出新功能。備受期待的 Claude Opus 4.7 剛正式發布,有趣的是,Anthropic 在公告中直言不諱地表示:「這並非我們最強大的模型。」 傳聞中更強大的 Claude Mythos Preview 仍處於待命狀態。儘管如此,Opus 4.7 仍引起了相當大的關注,因為它著重解決的是「更可靠」而非「更聰明」的問題。基準測試
相關專題推薦
漫畫創作
騰訊旗下《小龍夏》表現超乎預期,團隊將伺服器容量擴增10倍,並公開致歉及提供補償
騰訊正式推出全場景AI智能助手「WorkBuddy」,憑藉高度整合與低部署門檻,標誌著大型模型應用層競賽進入新階段。該產品在發布當天便立即引起業界關注。 用戶流量遠超預期,導致相關的騰雲代碼助手(CodeBuddy)出現登入問題及服務不穩定。騰雲團隊隨後發布致歉聲明,表示技術團隊已緊急將容量擴展十倍,目前服務已全面恢復。受影響用戶獲得 5,000 點代碼點數作為補償。業界觀察家將 WorkBudd
Suno 領投方:刪除貼文無法彌補版權訴訟的漏洞
備受矚目的 AI 音樂生成平台 Suno 正面臨一場艱難的版權之爭,而其主要投資人的坦率言論,可能正好提供了對方所期盼的證據。 Menlo Ventures(Suno的核心投資者)合夥人C.C. Gong最近刪除了一則推文,該推文與該公司當前的法律辯護策略直接相悖。在之前的版權訴訟中,Suno 的辯護主要依賴「合理使用」的論點,聲稱 AI 生成的音樂僅僅是一種「工具」,不會直接與受版權保護的原創作
Claude Opus 4.7 正式推出,重視可靠性勝於智能
Anthropic 今年持續保持強勁的開發步調,幾乎每隔一天就會推出新功能。備受期待的 Claude Opus 4.7 剛正式發布,有趣的是,Anthropic 在公告中直言不諱地表示:「這並非我們最強大的模型。」 傳聞中更強大的 Claude Mythos Preview 仍處於待命狀態。儘管如此,Opus 4.7 仍引起了相當大的關注,因為它著重解決的是「更可靠」而非「更聰明」的問題。基準測試
相關專題推薦
漫畫創作
 少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
 15 個工具
15 個工具
 xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

 評論 (0)
0/500
評論 (0)
0/500
近兩年前,微軟執行長薩蒂亞·納德拉曾預言人工智慧將重塑知識型工作——涵蓋律師、投資銀行家、圖書館員、會計師、資訊科技專業人員等白領職域。
然而,儘管基礎模型取得重大進展,知識型工作的轉型卻遲遲未能實現。儘管模型在深度研究與代理規劃方面表現出色,但多數白領職業所受的衝擊相對有限,箇中原因仍不明朗。
這已成為人工智慧領域的重大謎題。訓練數據領導者Mercor的最新研究現正提供關鍵洞見。
該研究評估頂尖AI模型處理諮詢、投資銀行與法律等真實白領任務的能力,進而創建了APEX-Agents基準測試——目前所有AI實驗室皆未能通過。當面對真實專業人士的提問時,即使最優秀的模型正確回答率也不足四分之一,多數情況下會返回錯誤答案或完全無回應。
參與研究的Mercor執行長布倫丹·富迪指出,模型主要弱點在於跨領域資訊整合能力——這正是人類知識工作的核心要素。
「此基準測試的關鍵創新在於,我們建構了模擬真實專業服務的完整環境,」富迪向TechCrunch解釋道:「現實工作中不會有人將所有背景資訊集中提供給我們,實際操作需橫跨Slack、Google雲端硬碟等多元工具。」對多數智能體型AI模型而言,這類跨領域推理仍存在不一致性。
測試情境源自Mercor專家市場的真實從業者,由他們設計查詢內容並定義成功答題標準。檢視Hugging Face平台公開的試題即可窺見任務複雜性。
Techcrunch活動Disrupt 2026 門票:限時優惠
門票現已開售!限時優惠最高可省680美元,前500名註冊者更享+1通行證五折優惠。TechCrunch Disrupt匯聚Google Cloud、Netflix、Microsoft、Box、a16z、Hugging Face等頂尖企業領袖,透過250多場專題議程助您加速成長、強化競爭優勢。 與數百家創新新創企業建立連結,參與精心策劃的交流活動,促成合作契機、獲取產業洞見並激發創新靈感。
Disrupt 2026 門票:限時優惠
門票現已開售!限時優惠最高可省680美元,前500名註冊者更可享+1通行證半價優惠。TechCrunch Disrupt匯聚Google Cloud、Netflix、Microsoft、Box、a16z、Hugging Face等頂尖企業領袖,透過250多場專題議程助您加速成長並強化競爭優勢。 與數百家創新新創企業建立連結,參與精心策劃的交流活動,促成合作契機、獲取產業洞見並激發創新靈感。
舊金山 | 2026年10月13-15日 立即註冊「法規」單元舉例說明:
在歐盟生產系統停機的前48分鐘內,北極星工程團隊將一至兩組包含個人資料的歐盟生產事件日誌打包匯出至美國分析供應商...根據北極星自身政策,能否合理認定此一至兩次日誌匯出符合第49條規範?
正確答案為是,但得出結論需詳細分析該公司內部政策與相關歐盟隱私法規。
此類問題即使對專業人士亦具挑戰性,但研究人員旨在模擬真實工作情境。能可靠解答此類查詢的大型語言模型,未來或可取代眾多執業律師。Foody向TechCrunch表示:「這無疑是當今最重要的經濟議題,該基準測試精準反映了專業人士的實際工作內容。」
OpenAI先前曾以GDPval基準測試專業技能,但APEX-Agents測試存在顯著差異:GDPval評估多領域的廣博知識,而APEX-Agents則衡量系統在特定高價值職業中執行持續性任務的能力。這不僅提升模型挑戰難度,更直接關聯職能自動化的潛在影響。
儘管目前尚無模型能取代投資銀行家的工作,但部分模型表現明顯優於其他系統。Gemini 3 Flash以24%的單次準確率領先群雄,緊隨其後的是23%的GPT-5.2。Opus 4.5、Gemini 3 Pro及GPT-5的得分均約為18%。
儘管初期成果未達預期,但人工智慧領域素以快速突破艱難基準著稱。隨著APEX-Agents測試公開,這對自信能改進的AI實驗室構成公開挑戰——Foody完全預期未來數月將見證此結果。
他向TechCrunch表示:「技術進步速度驚人。現階段將此技術比作每四次任務僅成功一次的實習生尚屬合理,但去年此時成功率僅5%至10%。這種逐年躍進的進步幅度,將迅速產生深遠影響。」










 騰訊旗下《小龍夏》表現超乎預期,團隊將伺服器容量擴增10倍,並公開致歉及提供補償
騰訊正式推出全場景AI智能助手「WorkBuddy」,憑藉高度整合與低部署門檻,標誌著大型模型應用層競賽進入新階段。該產品在發布當天便立即引起業界關注。 用戶流量遠超預期,導致相關的騰雲代碼助手(CodeBuddy)出現登入問題及服務不穩定。騰雲團隊隨後發布致歉聲明,表示技術團隊已緊急將容量擴展十倍,目前服務已全面恢復。受影響用戶獲得 5,000 點代碼點數作為補償。業界觀察家將 WorkBudd
騰訊旗下《小龍夏》表現超乎預期,團隊將伺服器容量擴增10倍,並公開致歉及提供補償
騰訊正式推出全場景AI智能助手「WorkBuddy」,憑藉高度整合與低部署門檻,標誌著大型模型應用層競賽進入新階段。該產品在發布當天便立即引起業界關注。 用戶流量遠超預期,導致相關的騰雲代碼助手(CodeBuddy)出現登入問題及服務不穩定。騰雲團隊隨後發布致歉聲明,表示技術團隊已緊急將容量擴展十倍,目前服務已全面恢復。受影響用戶獲得 5,000 點代碼點數作為補償。業界觀察家將 WorkBudd
 Suno 領投方:刪除貼文無法彌補版權訴訟的漏洞
備受矚目的 AI 音樂生成平台 Suno 正面臨一場艱難的版權之爭,而其主要投資人的坦率言論,可能正好提供了對方所期盼的證據。 Menlo Ventures(Suno的核心投資者)合夥人C.C. Gong最近刪除了一則推文,該推文與該公司當前的法律辯護策略直接相悖。在之前的版權訴訟中,Suno 的辯護主要依賴「合理使用」的論點,聲稱 AI 生成的音樂僅僅是一種「工具」,不會直接與受版權保護的原創作
Suno 領投方:刪除貼文無法彌補版權訴訟的漏洞
備受矚目的 AI 音樂生成平台 Suno 正面臨一場艱難的版權之爭,而其主要投資人的坦率言論,可能正好提供了對方所期盼的證據。 Menlo Ventures(Suno的核心投資者)合夥人C.C. Gong最近刪除了一則推文,該推文與該公司當前的法律辯護策略直接相悖。在之前的版權訴訟中,Suno 的辯護主要依賴「合理使用」的論點,聲稱 AI 生成的音樂僅僅是一種「工具」,不會直接與受版權保護的原創作
 Claude Opus 4.7 正式推出,重視可靠性勝於智能
Anthropic 今年持續保持強勁的開發步調,幾乎每隔一天就會推出新功能。備受期待的 Claude Opus 4.7 剛正式發布,有趣的是,Anthropic 在公告中直言不諱地表示:「這並非我們最強大的模型。」 傳聞中更強大的 Claude Mythos Preview 仍處於待命狀態。儘管如此,Opus 4.7 仍引起了相當大的關注,因為它著重解決的是「更可靠」而非「更聰明」的問題。基準測試
Claude Opus 4.7 正式推出,重視可靠性勝於智能
Anthropic 今年持續保持強勁的開發步調,幾乎每隔一天就會推出新功能。備受期待的 Claude Opus 4.7 剛正式發布,有趣的是,Anthropic 在公告中直言不諱地表示:「這並非我們最強大的模型。」 傳聞中更強大的 Claude Mythos Preview 仍處於待命狀態。儘管如此,Opus 4.7 仍引起了相當大的關注,因為它著重解決的是「更可靠」而非「更聰明」的問題。基準測試

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai













