
















 Lar
LarAgentes de Langchain: Um guia para a criação de ferramentas avançadas de LLM em 2025
No mundo acelerado da inteligência artificial, a Langchain se estabeleceu como uma estrutura poderosa para o desenvolvimento de aplicativos sofisticados com grandes modelos de linguagem (LLMs). Um recurso particularmente dinâmico é seu sistema de agentes, que permite que os LLMs interajam com o ambiente, utilizem ferramentas e tomem decisões informadas para atingir objetivos complexos. Este guia detalhado lhe dará uma compreensão completa dos agentes da Langchain e de como criar ferramentas que expandam seus recursos.
Pontos principais
Compreender o conceito fundamental dos Langchain Agents e sua capacidade de interagir com ferramentas.
Aprenda o processo de criação de ferramentas que ampliam os recursos dos LLMs além da geração básica de texto.
Aprofunde-se na estrutura do ReAct e em sua função de permitir o raciocínio e a seleção de ações para os agentes.
Saiba como implementar a memória de conversação para agentes usando a memória de janela de buffer da Langchain.
Torne-se proficiente na formatação de dados e na elaboração de prompts eficazes para seus agentes.
Investigue os possíveis aplicativos para ferramentas criadas para aprimorar os LLMs.
Entendendo os agentes da Langchain e a criação de ferramentas
O que são agentes Langchain?
Os Langchain Agents são essencialmente Large Language Models aprimorados com a capacidade de utilizar ferramentas e tomar decisões autônomas.

Ao contrário dos LLMs padrão que se concentram principalmente no preenchimento de texto, os agentes podem empregar estrategicamente ferramentas externas para coletar informações, realizar cálculos ou interagir com APIs. Seu design permite que eles deliberem e usem as ferramentas fornecidas, oferecendo muito mais funcionalidade do que o autocompletar básico. Esse processo de tomada de decisão é frequentemente orientado pela estrutura ReAct, que solicita que os agentes alternem entre as etapas de Raciocínio e Ação para lidar com tarefas complexas.
Principais componentes de um agente:
- LLM: o LLM funciona como o núcleo do agente, fornecendo raciocínio e poder de decisão.
- Ferramentas: Concedem ao agente acesso a informações e recursos externos, como mecanismos de pesquisa, calculadoras e APIs.
- Estrutura ReAct: Essa metodologia permite que o agente raciocine sobre seus objetivos, escolha ações apropriadas e aprenda com os resultados.
- Memória: Os agentes de conversação precisam de memória para reter o contexto de interações anteriores.
Criação de ferramentas eficazes para agentes Langchain
A verdadeira força dos agentes Langchain está nas ferramentas que eles podem acessar.

Essas ferramentas equipam os agentes com as funções necessárias para ir além da simples geração de texto e realizar tarefas complexas. Ao projetar ferramentas, é fundamental definir com precisão as funcionalidades específicas que você deseja que seu agente tenha. Aqui estão algumas dicas para criar ferramentas eficazes:
- Defina uma finalidade clara: toda ferramenta deve ter uma finalidade única e bem definida, permitindo que o agente identifique rapidamente quando e como usá-la.
- Forneça descrições detalhadas: Ofereça descrições claras da função e do uso adequado da ferramenta. Essas informações são essenciais para que o agente avalie se uma ferramenta é adequada para responder a uma consulta de forma eficaz.
- Garantir entrada e saída confiáveis: As ferramentas devem ter formatos de entrada e saída consistentes e bem definidos para facilitar a integração com o LLM.
- Tratar os erros de forma graciosa: Implemente um tratamento robusto de erros para evitar que o agente falhe ou produza resultados erráticos se uma ferramenta encontrar um problema.
A estrutura React: Raciocínio e ação
A estrutura ReAct é um elemento fundamental dos agentes Langchain, permitindo que eles lidem com tarefas complexas ao entrelaçar etapas de raciocínio e ação. No ReAct, o agente primeiro raciocina sobre a tarefa em questão e, em seguida, seleciona uma ação a ser executada. Depois de executar a ação, o agente observa o resultado e usa essa observação para orientar seu raciocínio subsequente. Esse ciclo se repete até que a meta seja atingida.
O processo ReAct ajuda o LLM a selecionar a ferramenta mais adequada, analisando primeiro o contexto. Essa estrutura permite que os agentes tomem decisões mais bem informadas, adaptem-se a situações dinâmicas e resolvam problemas complexos que a simples geração de texto não consegue resolver.
O LangChain utiliza dois tipos principais de ferramentas ao processar documentos:
- O método Stuff: Vários documentos são retornados em sua forma original, não resumida.
- O método Map Reduce: Os itens são processados e resumidos.
Configuração do ambiente de desenvolvimento para a criação de agentes
Instalação dos pacotes necessários
Para começar a criar ferramentas para os agentes da Langchain, você deve primeiro instalar os pacotes de pré-requisitos necessários. Você pode fazer isso usando o pip:

pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- conjuntos de dados: Essa biblioteca fornece acesso a vários conjuntos de dados, incluindo transcrições de podcast.
- pod-gpt: Uma biblioteca projetada para facilitar o acesso aos dados de podcast de Lex Fridman.
- pinecone-client[grpc]: O cliente Pinecone para interagir com o banco de dados de vetores Pinecone.
- langchain: A biblioteca Langchain principal que usaremos.
- openai: Fornece acesso aos modelos da OpenAI.
- tqdm: Uma biblioteca usada para exibir barras de progresso.
Definição de chaves de API
Algumas dessas ferramentas exigem chaves de API para funcionar, como a OPENAI_API_KEY e uma chave de API do Pinecone. Depois de instalar os pré-requisitos, a próxima etapa crítica é configurar suas chaves de API para o OpenAI e o Pinecone:
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY "PINECONE_API_KEY = "YOUR_PINECONE_API_KEY "PINECONE_ENV = "YOUR_PINECONE_ENV"
Obtenha uma chave de API da OpenAI em platform.openai.com. Você precisará de uma conta ativa para acessar essa página.
Você também precisará de sua chave de API do Pinecone e do Pinecone Environment, que podem ser encontrados em app.pinecone.io.
Download de um conjunto de dados pré-construído
Podemos utilizar um conjunto de dados para demonstrar a construção do chatbot. Para este exemplo, o chatbot usará transcrições do podcast de Lex Fridman:
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
Visualização do fluxo do agente de conversação
O fluxo típico do agente de conversação segue estas etapas:
- Entrada: O usuário fornece uma consulta ou instrução.
- O LLM processa a pergunta, determinando se uma ferramenta pode ajudar. As ferramentas fornecem recursos expandidos.
- Uma ferramenta de banco de dados é consultada. O resultado é enviado ao LLM para tomada de decisões adicionais.
- Um pensamento ou resposta final é formulado e entregue.
Criação de um agente de resposta a perguntas baseado em recuperação
Formatação de dados para o indexador Pod-GPT
Para usar o indexador pod-gpt, precisamos reformatar nossos dados em uma estrutura específica:
docs = [{'id': x['video_id'],'text': x['transcript'],'metadata': {'title': x['title'],'url': x['source']}} for x in data]
Inicialização do objeto indexador
Com os dados formatados corretamente, a próxima etapa é criar um objeto indexador do pod-gpt:
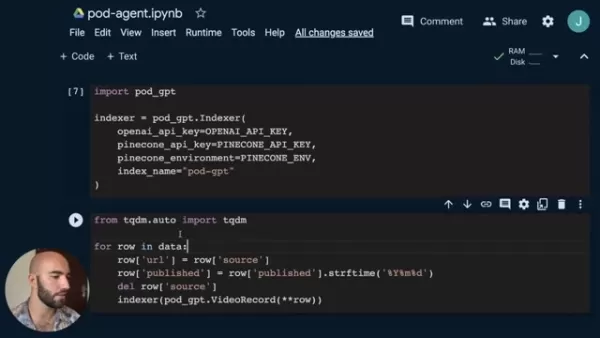
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Adição de transcrições de podcast ao Pinecone
O processo de indexação envolve a iteração de cada linha de dados:
from tqdm.auto import tqdmfor row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
As transcrições de podcast agora estão armazenadas e podem ser pesquisadas no Pinecone.
Inicializar o Pinecone
Para inicializar uma conexão com o Pinecone, use o seguinte código:
import pineconepinecone.init(api_key=PINECONE_API_KEY,# localize em app.pinecone.ioenvironment=PINECONE_ENV# ao lado da chave da API no console)index_name = "pod-gpt"
Acessar o Pinecone para importar o OpenAI Embeddings
Acesse os vetores no Pinecone e inicialize o armazenamento de vetores com o OpenAI Embeddings:
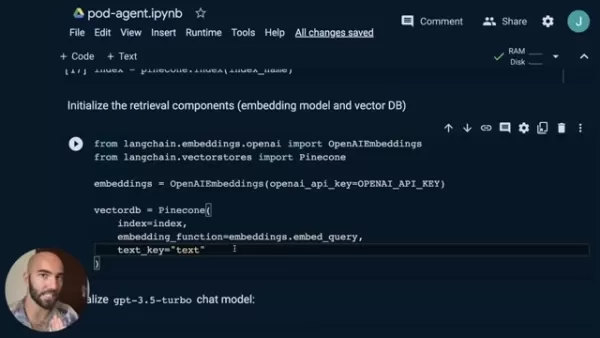
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")
Artigo relacionado
 A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
Recomendações de tópicos especiais relacionados
Negócios
A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
Recomendações de tópicos especiais relacionados
Negócios
 As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
 10 ferramentas
10 ferramentas
 xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

 Comentários (0)
Comentários (0)
No mundo acelerado da inteligência artificial, a Langchain se estabeleceu como uma estrutura poderosa para o desenvolvimento de aplicativos sofisticados com grandes modelos de linguagem (LLMs). Um recurso particularmente dinâmico é seu sistema de agentes, que permite que os LLMs interajam com o ambiente, utilizem ferramentas e tomem decisões informadas para atingir objetivos complexos. Este guia detalhado lhe dará uma compreensão completa dos agentes da Langchain e de como criar ferramentas que expandam seus recursos.
Pontos principais
Compreender o conceito fundamental dos Langchain Agents e sua capacidade de interagir com ferramentas.
Aprenda o processo de criação de ferramentas que ampliam os recursos dos LLMs além da geração básica de texto.
Aprofunde-se na estrutura do ReAct e em sua função de permitir o raciocínio e a seleção de ações para os agentes.
Saiba como implementar a memória de conversação para agentes usando a memória de janela de buffer da Langchain.
Torne-se proficiente na formatação de dados e na elaboração de prompts eficazes para seus agentes.
Investigue os possíveis aplicativos para ferramentas criadas para aprimorar os LLMs.
Entendendo os agentes da Langchain e a criação de ferramentas
O que são agentes Langchain?
Os Langchain Agents são essencialmente Large Language Models aprimorados com a capacidade de utilizar ferramentas e tomar decisões autônomas.
Ao contrário dos LLMs padrão que se concentram principalmente no preenchimento de texto, os agentes podem empregar estrategicamente ferramentas externas para coletar informações, realizar cálculos ou interagir com APIs. Seu design permite que eles deliberem e usem as ferramentas fornecidas, oferecendo muito mais funcionalidade do que o autocompletar básico. Esse processo de tomada de decisão é frequentemente orientado pela estrutura ReAct, que solicita que os agentes alternem entre as etapas de Raciocínio e Ação para lidar com tarefas complexas.
Principais componentes de um agente:
- LLM: o LLM funciona como o núcleo do agente, fornecendo raciocínio e poder de decisão.
- Ferramentas: Concedem ao agente acesso a informações e recursos externos, como mecanismos de pesquisa, calculadoras e APIs.
- Estrutura ReAct: Essa metodologia permite que o agente raciocine sobre seus objetivos, escolha ações apropriadas e aprenda com os resultados.
- Memória: Os agentes de conversação precisam de memória para reter o contexto de interações anteriores.
Criação de ferramentas eficazes para agentes Langchain
A verdadeira força dos agentes Langchain está nas ferramentas que eles podem acessar.
Essas ferramentas equipam os agentes com as funções necessárias para ir além da simples geração de texto e realizar tarefas complexas. Ao projetar ferramentas, é fundamental definir com precisão as funcionalidades específicas que você deseja que seu agente tenha. Aqui estão algumas dicas para criar ferramentas eficazes:
- Defina uma finalidade clara: toda ferramenta deve ter uma finalidade única e bem definida, permitindo que o agente identifique rapidamente quando e como usá-la.
- Forneça descrições detalhadas: Ofereça descrições claras da função e do uso adequado da ferramenta. Essas informações são essenciais para que o agente avalie se uma ferramenta é adequada para responder a uma consulta de forma eficaz.
- Garantir entrada e saída confiáveis: As ferramentas devem ter formatos de entrada e saída consistentes e bem definidos para facilitar a integração com o LLM.
- Tratar os erros de forma graciosa: Implemente um tratamento robusto de erros para evitar que o agente falhe ou produza resultados erráticos se uma ferramenta encontrar um problema.
A estrutura React: Raciocínio e ação
A estrutura ReAct é um elemento fundamental dos agentes Langchain, permitindo que eles lidem com tarefas complexas ao entrelaçar etapas de raciocínio e ação. No ReAct, o agente primeiro raciocina sobre a tarefa em questão e, em seguida, seleciona uma ação a ser executada. Depois de executar a ação, o agente observa o resultado e usa essa observação para orientar seu raciocínio subsequente. Esse ciclo se repete até que a meta seja atingida.
O processo ReAct ajuda o LLM a selecionar a ferramenta mais adequada, analisando primeiro o contexto. Essa estrutura permite que os agentes tomem decisões mais bem informadas, adaptem-se a situações dinâmicas e resolvam problemas complexos que a simples geração de texto não consegue resolver.
O LangChain utiliza dois tipos principais de ferramentas ao processar documentos:
- O método Stuff: Vários documentos são retornados em sua forma original, não resumida.
- O método Map Reduce: Os itens são processados e resumidos.
Configuração do ambiente de desenvolvimento para a criação de agentes
Instalação dos pacotes necessários
Para começar a criar ferramentas para os agentes da Langchain, você deve primeiro instalar os pacotes de pré-requisitos necessários. Você pode fazer isso usando o pip:
pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- conjuntos de dados: Essa biblioteca fornece acesso a vários conjuntos de dados, incluindo transcrições de podcast.
- pod-gpt: Uma biblioteca projetada para facilitar o acesso aos dados de podcast de Lex Fridman.
- pinecone-client[grpc]: O cliente Pinecone para interagir com o banco de dados de vetores Pinecone.
- langchain: A biblioteca Langchain principal que usaremos.
- openai: Fornece acesso aos modelos da OpenAI.
- tqdm: Uma biblioteca usada para exibir barras de progresso.
Definição de chaves de API
Algumas dessas ferramentas exigem chaves de API para funcionar, como a OPENAI_API_KEY e uma chave de API do Pinecone. Depois de instalar os pré-requisitos, a próxima etapa crítica é configurar suas chaves de API para o OpenAI e o Pinecone:
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY "PINECONE_API_KEY = "YOUR_PINECONE_API_KEY "PINECONE_ENV = "YOUR_PINECONE_ENV"
Obtenha uma chave de API da OpenAI em platform.openai.com. Você precisará de uma conta ativa para acessar essa página.
Você também precisará de sua chave de API do Pinecone e do Pinecone Environment, que podem ser encontrados em app.pinecone.io.
Download de um conjunto de dados pré-construído
Podemos utilizar um conjunto de dados para demonstrar a construção do chatbot. Para este exemplo, o chatbot usará transcrições do podcast de Lex Fridman:
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
Visualização do fluxo do agente de conversação
O fluxo típico do agente de conversação segue estas etapas:
- Entrada: O usuário fornece uma consulta ou instrução.
- O LLM processa a pergunta, determinando se uma ferramenta pode ajudar. As ferramentas fornecem recursos expandidos.
- Uma ferramenta de banco de dados é consultada. O resultado é enviado ao LLM para tomada de decisões adicionais.
- Um pensamento ou resposta final é formulado e entregue.
Criação de um agente de resposta a perguntas baseado em recuperação
Formatação de dados para o indexador Pod-GPT
Para usar o indexador pod-gpt, precisamos reformatar nossos dados em uma estrutura específica:
docs = [{'id': x['video_id'],'text': x['transcript'],'metadata': {'title': x['title'],'url': x['source']}} for x in data]
Inicialização do objeto indexador
Com os dados formatados corretamente, a próxima etapa é criar um objeto indexador do pod-gpt:
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Adição de transcrições de podcast ao Pinecone
O processo de indexação envolve a iteração de cada linha de dados:
from tqdm.auto import tqdmfor row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
As transcrições de podcast agora estão armazenadas e podem ser pesquisadas no Pinecone.
Inicializar o Pinecone
Para inicializar uma conexão com o Pinecone, use o seguinte código:
import pineconepinecone.init(api_key=PINECONE_API_KEY,# localize em app.pinecone.ioenvironment=PINECONE_ENV# ao lado da chave da API no console)index_name = "pod-gpt"
Acessar o Pinecone para importar o OpenAI Embeddings
Acesse os vetores no Pinecone e inicialize o armazenamento de vetores com o OpenAI Embeddings:
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")










 A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
A IA experimental da Anthropic, Claude, conclui negociações e transações em um teste de comércio eletrônico
À medida que a inteligência artificial avança rapidamente, a Anthropic lançou discretamente, na última sexta-feira, um experimento interno chamado “Projeto Deal”, demonstrando o potencial da IA no com
 DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
DeepSeek Code pronto para ser lançado
À medida que a tecnologia de IA avança, a DeepSeek encontra-se em um momento emocionante. A empresa de IA revelou recentemente que garantiu mais de 70 bilhões de yuans em financiamento. A direção enfa
 O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu
O Grok de Musk: 1,5 trilhão de parâmetros e absorção de código de cursor — uma revolução ou um blefe?
Elon Musk finalmente está entrando em ação.Na corrida pela programação de IA, a OpenAI e a Anthropic estão acelerando, enquanto a xAI parece estar ficando para trás. Musk já declarou várias vezes seu

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai













