
















 Дом
ДомLangchain Agents: Руководство по созданию продвинутых инструментов LLM в 2025 году
В стремительно развивающемся мире искусственного интеллекта Langchain зарекомендовал себя как мощный фреймворк для разработки сложных приложений с большими языковыми моделями (LLM). Особенно динамичной является система агентов, которая позволяет LLM взаимодействовать с окружением, использовать инструменты и принимать взвешенные решения для достижения сложных целей. Это подробное руководство даст вам полное представление об агентах Langchain и о том, как создавать инструменты, расширяющие их возможности.
Ключевые моменты
Познакомьтесь с фундаментальной концепцией агентов Langchain и их способностью взаимодействовать с инструментами.
Узнайте о процессе создания инструментов, расширяющих возможности LLM за пределы базовой генерации текста.
Познакомьтесь с фреймворком ReAct и его функцией, позволяющей Агентам рассуждать и выбирать действия.
Узнайте, как реализовать разговорную память для агентов с помощью буферной оконной памяти Langchain.
Овладейте навыками форматирования данных и создания эффективных подсказок для ваших агентов.
Изучите потенциальные возможности применения инструментов, разработанных для улучшения LLM.
Понимание агентов Langchain и создание инструментов
Что такое агенты Langchain?
Агенты Langchain - это, по сути, большие языковые модели, наделенные способностью использовать инструменты и принимать самостоятельные решения.

В отличие от стандартных LLM, ориентированных в основном на заполнение текста, агенты могут стратегически использовать внешние инструменты для сбора информации, выполнения вычислений или взаимодействия с API. Их дизайн позволяет им обдумывать и использовать предоставленные инструменты, предлагая значительно большую функциональность, чем базовое автозаполнение. Этот процесс принятия решений часто направляется фреймворком ReAct, который побуждает агентов чередовать шаги рассуждения и действия для решения сложных задач.
Основные компоненты агента:
- LLM: LLM служит ядром агента, обеспечивая способность рассуждать и принимать решения.
- Инструменты: Они предоставляют агенту доступ к внешней информации и возможностям, таким как поисковые системы, калькуляторы и API.
- ReAct Framework: Эта методология позволяет агенту рассуждать о своих целях, выбирать соответствующие действия и учиться на их результатах.
- Память: Разговорные агенты нуждаются в памяти, чтобы сохранять контекст предыдущих взаимодействий.
Создание эффективных инструментов для агентов Langchain
Настоящая сила агентов Langchain заключается в доступных им инструментах.

Эти инструменты наделяют агентов необходимыми функциями для того, чтобы выйти за рамки простой генерации текста и выполнять сложные задачи. При разработке инструментов очень важно точно определить конкретные функции, которыми должен обладать ваш агент. Вот несколько советов по созданию эффективных инструментов:
- Определите четкое назначение: каждый инструмент должен иметь единственное, четко определенное назначение, позволяющее агенту быстро понять, когда и как его использовать.
- Дайте подробное описание: Предложите четкие описания функций и правильного использования инструмента. Эта информация необходима агенту для того, чтобы оценить, подходит ли инструмент для эффективного ответа на запрос.
- Обеспечьте надежный ввод и вывод данных: Инструменты должны иметь последовательные и четко определенные форматы ввода и вывода для плавной интеграции с LLM.
- Грациозно обрабатывать ошибки: Реализуйте надежную обработку ошибок, чтобы предотвратить сбои в работе агента или выдачу нестабильных результатов, если инструмент столкнулся с проблемой.
React Framework: Рассуждения и действия
Фреймворк ReAct является ключевым элементом агентов Langchain, позволяя им решать сложные задачи путем переплетения рассуждений и действий. В рамках ReAct агент сначала рассуждает о поставленной задаче, а затем выбирает действие для выполнения. После выполнения действия агент наблюдает за результатом и использует это наблюдение для последующих рассуждений. Этот цикл повторяется до тех пор, пока цель не будет достигнута.
Процесс ReAct помогает LLM выбрать наиболее подходящий инструмент, предварительно проанализировав контекст. Эта система позволяет агентам принимать более обоснованные решения, адаптироваться к динамичным ситуациям и решать сложные задачи, которые не под силу простой генерации текста.
LangChain использует два основных типа инструментов при обработке документов:
- Метод Stuff: Несколько документов возвращаются в исходном, не обобщенном виде.
- Метод Map Reduce: Элементы обрабатываются и обобщаются.
Настройка среды разработки для создания агента
Установка необходимых пакетов
Чтобы приступить к созданию инструментов для агентов Langchain, сначала нужно установить необходимые пакеты. Это можно сделать с помощью pip:

pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- datasets: Эта библиотека предоставляет доступ к различным наборам данных, включая транскрипции подкастов.
- pod-gpt: Библиотека, предназначенная для облегчения доступа к данным подкастов Лекса Фридмана.
- pinecone-client[grpc]: Клиент Pinecone для взаимодействия с векторной базой данных Pinecone.
- langchain: Основная библиотека Langchain, которую мы будем использовать.
- openai: Предоставляет доступ к моделям OpenAI.
- tqdm: Библиотека, используемая для отображения прогресс-баров.
Установка API-ключей
Для работы некоторых из этих инструментов требуются API-ключи, например OPENAI_API_KEY и API-ключ Pinecone. После установки предварительных условий следующим важным шагом будет настройка API-ключей для OpenAI и Pinecone:
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY "PINECONE_API_KEY = "YOUR_PINECONE_API_KEY "PINECONE_ENV = "YOUR_PINECONE_ENV"
Получите API-ключ OpenAI на сайте platform.openai.com. Для доступа к этой странице вам понадобится активная учетная запись.
Также вам понадобится API-ключ Pinecone и среда Pinecone Environment; их можно найти на сайте app.pinecone.io.
Загрузка готового набора данных
Мы можем использовать набор данных, чтобы продемонстрировать создание чатбота. В этом примере чатбот будет использовать транскрипции из подкаста Лекса Фридмана:
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
Визуализация потока разговорного агента
Типичный поток разговорного агента состоит из следующих шагов:
- Вход: Пользователь предоставляет запрос или инструкцию.
- LLM обрабатывает вопрос, определяя, может ли помочь инструмент. Инструменты предоставляют расширенные возможности.
- Запрашивается инструмент базы данных. Результат возвращается в LLM для дальнейшего принятия решения.
- Формулируется и выдается окончательное решение или ответ.
Создание агента для ответа на вопросы на основе поиска
Форматирование данных для индексатора Pod-GPT
Чтобы использовать индексатор pod-gpt, мы должны переформатировать наши данные в определенную структуру:
docs = [{ 'id': x['video_id'], 'text': x['transcript'], 'metadata': {'title': x['title'], 'url': x['source']}} for x in data]
Инициализация объекта индексатора
Когда данные правильно отформатированы, следующим шагом будет создание объекта индексатора из pod-gpt:
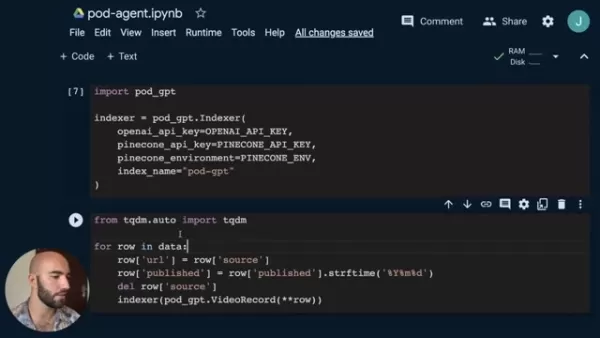
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Добавление транскрипций подкастов в Pinecone
Процесс индексирования включает в себя итерацию по каждой строке данных:
from tqdm.auto import tqdmfor row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
Теперь транскрипты подкастов хранятся и доступны для поиска в Pinecone.
Инициализация Pinecone
Чтобы инициализировать соединение с Pinecone, используйте следующий код:
import pineconepinecone.init(api_key=PINECONE_API_KEY,# находим в app.pinecone.ioenvironment=PINECONE_ENV# рядом с api ключом в консоли)index_name = "pod-gpt"
Доступ к Pinecone для импорта вкраплений OpenAI
Получите доступ к векторам в Pinecone и инициализируйте векторное хранилище с помощью OpenAI Embeddings:
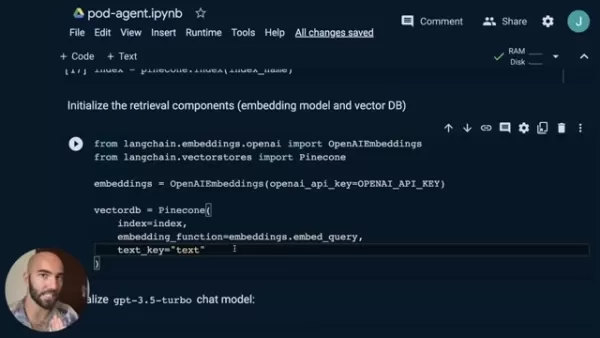
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")
Связанная статья
 Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
Рекомендации по связанным специальным темам
Бизнес
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
Рекомендации по связанным специальным темам
Бизнес
 Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
 10 инструментов
10 инструментов
 xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие тренажеры по флирту и общению на базе ИИ: повышайте свою харизму и уверенность в себе в режиме реального времени
Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

 Комментарии (0)
Комментарии (0)
В стремительно развивающемся мире искусственного интеллекта Langchain зарекомендовал себя как мощный фреймворк для разработки сложных приложений с большими языковыми моделями (LLM). Особенно динамичной является система агентов, которая позволяет LLM взаимодействовать с окружением, использовать инструменты и принимать взвешенные решения для достижения сложных целей. Это подробное руководство даст вам полное представление об агентах Langchain и о том, как создавать инструменты, расширяющие их возможности.
Ключевые моменты
Познакомьтесь с фундаментальной концепцией агентов Langchain и их способностью взаимодействовать с инструментами.
Узнайте о процессе создания инструментов, расширяющих возможности LLM за пределы базовой генерации текста.
Познакомьтесь с фреймворком ReAct и его функцией, позволяющей Агентам рассуждать и выбирать действия.
Узнайте, как реализовать разговорную память для агентов с помощью буферной оконной памяти Langchain.
Овладейте навыками форматирования данных и создания эффективных подсказок для ваших агентов.
Изучите потенциальные возможности применения инструментов, разработанных для улучшения LLM.
Понимание агентов Langchain и создание инструментов
Что такое агенты Langchain?
Агенты Langchain - это, по сути, большие языковые модели, наделенные способностью использовать инструменты и принимать самостоятельные решения.
В отличие от стандартных LLM, ориентированных в основном на заполнение текста, агенты могут стратегически использовать внешние инструменты для сбора информации, выполнения вычислений или взаимодействия с API. Их дизайн позволяет им обдумывать и использовать предоставленные инструменты, предлагая значительно большую функциональность, чем базовое автозаполнение. Этот процесс принятия решений часто направляется фреймворком ReAct, который побуждает агентов чередовать шаги рассуждения и действия для решения сложных задач.
Основные компоненты агента:
- LLM: LLM служит ядром агента, обеспечивая способность рассуждать и принимать решения.
- Инструменты: Они предоставляют агенту доступ к внешней информации и возможностям, таким как поисковые системы, калькуляторы и API.
- ReAct Framework: Эта методология позволяет агенту рассуждать о своих целях, выбирать соответствующие действия и учиться на их результатах.
- Память: Разговорные агенты нуждаются в памяти, чтобы сохранять контекст предыдущих взаимодействий.
Создание эффективных инструментов для агентов Langchain
Настоящая сила агентов Langchain заключается в доступных им инструментах.
Эти инструменты наделяют агентов необходимыми функциями для того, чтобы выйти за рамки простой генерации текста и выполнять сложные задачи. При разработке инструментов очень важно точно определить конкретные функции, которыми должен обладать ваш агент. Вот несколько советов по созданию эффективных инструментов:
- Определите четкое назначение: каждый инструмент должен иметь единственное, четко определенное назначение, позволяющее агенту быстро понять, когда и как его использовать.
- Дайте подробное описание: Предложите четкие описания функций и правильного использования инструмента. Эта информация необходима агенту для того, чтобы оценить, подходит ли инструмент для эффективного ответа на запрос.
- Обеспечьте надежный ввод и вывод данных: Инструменты должны иметь последовательные и четко определенные форматы ввода и вывода для плавной интеграции с LLM.
- Грациозно обрабатывать ошибки: Реализуйте надежную обработку ошибок, чтобы предотвратить сбои в работе агента или выдачу нестабильных результатов, если инструмент столкнулся с проблемой.
React Framework: Рассуждения и действия
Фреймворк ReAct является ключевым элементом агентов Langchain, позволяя им решать сложные задачи путем переплетения рассуждений и действий. В рамках ReAct агент сначала рассуждает о поставленной задаче, а затем выбирает действие для выполнения. После выполнения действия агент наблюдает за результатом и использует это наблюдение для последующих рассуждений. Этот цикл повторяется до тех пор, пока цель не будет достигнута.
Процесс ReAct помогает LLM выбрать наиболее подходящий инструмент, предварительно проанализировав контекст. Эта система позволяет агентам принимать более обоснованные решения, адаптироваться к динамичным ситуациям и решать сложные задачи, которые не под силу простой генерации текста.
LangChain использует два основных типа инструментов при обработке документов:
- Метод Stuff: Несколько документов возвращаются в исходном, не обобщенном виде.
- Метод Map Reduce: Элементы обрабатываются и обобщаются.
Настройка среды разработки для создания агента
Установка необходимых пакетов
Чтобы приступить к созданию инструментов для агентов Langchain, сначала нужно установить необходимые пакеты. Это можно сделать с помощью pip:
pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- datasets: Эта библиотека предоставляет доступ к различным наборам данных, включая транскрипции подкастов.
- pod-gpt: Библиотека, предназначенная для облегчения доступа к данным подкастов Лекса Фридмана.
- pinecone-client[grpc]: Клиент Pinecone для взаимодействия с векторной базой данных Pinecone.
- langchain: Основная библиотека Langchain, которую мы будем использовать.
- openai: Предоставляет доступ к моделям OpenAI.
- tqdm: Библиотека, используемая для отображения прогресс-баров.
Установка API-ключей
Для работы некоторых из этих инструментов требуются API-ключи, например OPENAI_API_KEY и API-ключ Pinecone. После установки предварительных условий следующим важным шагом будет настройка API-ключей для OpenAI и Pinecone:
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY "PINECONE_API_KEY = "YOUR_PINECONE_API_KEY "PINECONE_ENV = "YOUR_PINECONE_ENV"
Получите API-ключ OpenAI на сайте platform.openai.com. Для доступа к этой странице вам понадобится активная учетная запись.
Также вам понадобится API-ключ Pinecone и среда Pinecone Environment; их можно найти на сайте app.pinecone.io.
Загрузка готового набора данных
Мы можем использовать набор данных, чтобы продемонстрировать создание чатбота. В этом примере чатбот будет использовать транскрипции из подкаста Лекса Фридмана:
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
Визуализация потока разговорного агента
Типичный поток разговорного агента состоит из следующих шагов:
- Вход: Пользователь предоставляет запрос или инструкцию.
- LLM обрабатывает вопрос, определяя, может ли помочь инструмент. Инструменты предоставляют расширенные возможности.
- Запрашивается инструмент базы данных. Результат возвращается в LLM для дальнейшего принятия решения.
- Формулируется и выдается окончательное решение или ответ.
Создание агента для ответа на вопросы на основе поиска
Форматирование данных для индексатора Pod-GPT
Чтобы использовать индексатор pod-gpt, мы должны переформатировать наши данные в определенную структуру:
docs = [{ 'id': x['video_id'], 'text': x['transcript'], 'metadata': {'title': x['title'], 'url': x['source']}} for x in data]
Инициализация объекта индексатора
Когда данные правильно отформатированы, следующим шагом будет создание объекта индексатора из pod-gpt:
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Добавление транскрипций подкастов в Pinecone
Процесс индексирования включает в себя итерацию по каждой строке данных:
from tqdm.auto import tqdmfor row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
Теперь транскрипты подкастов хранятся и доступны для поиска в Pinecone.
Инициализация Pinecone
Чтобы инициализировать соединение с Pinecone, используйте следующий код:
import pineconepinecone.init(api_key=PINECONE_API_KEY,# находим в app.pinecone.ioenvironment=PINECONE_ENV# рядом с api ключом в консоли)index_name = "pod-gpt"
Доступ к Pinecone для импорта вкраплений OpenAI
Получите доступ к векторам в Pinecone и инициализируйте векторное хранилище с помощью OpenAI Embeddings:
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")










 Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
 WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
 Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai













