
















 Hogar
HogarAgentes Langchain: Guía para crear herramientas avanzadas de LLM en 2025
En el vertiginoso mundo de la inteligencia artificial, Langchain se ha consolidado como un potente marco para desarrollar aplicaciones sofisticadas con grandes modelos lingüísticos (LLM). Una característica particularmente dinámica es su sistema de agentes, que permite a los LLM interactuar con su entorno, aprovechar las herramientas y tomar decisiones informadas para lograr objetivos complejos. Esta guía en profundidad le proporcionará un conocimiento exhaustivo de los agentes Langchain y de cómo crear herramientas que amplíen sus capacidades.
Puntos clave
Comprender el concepto fundamental de los agentes Langchain y su capacidad para interactuar con herramientas.
Aprender el proceso de creación de herramientas que amplíen las capacidades de los LLM más allá de la generación básica de texto.
Profundizar en el marco ReAct y su función a la hora de permitir el razonamiento y la selección de acciones para los Agentes.
Aprender a implementar la memoria conversacional para agentes utilizando la memoria de ventana de búfer de Langchain.
Adquirir destreza en el formateo de datos y en la elaboración de prompts efectivos para sus agentes.
Investigar aplicaciones potenciales para herramientas diseñadas para mejorar LLMs.
Entendiendo los Agentes Langchain y la Construcción de Herramientas
¿Qué son los Agentes Langchain?
Los Agentes Langchain son esencialmente Grandes Modelos de Lenguaje mejorados con la habilidad de utilizar herramientas y tomar decisiones autónomas.

A diferencia de los LLM estándar, centrados principalmente en completar texto, los Agentes pueden emplear estratégicamente herramientas externas para recopilar información, realizar cálculos o interactuar con APIs. Su diseño les permite deliberar y utilizar las herramientas proporcionadas, ofreciendo una funcionalidad significativamente mayor que el autocompletado básico. Este proceso de toma de decisiones suele estar guiado por el marco ReAct, que lleva a los agentes a alternar entre pasos de Razonamiento y Acción para abordar tareas complejas.
Componentes clave de un agente:
- LLM: el LLM es el núcleo del agente y proporciona capacidad de razonamiento y toma de decisiones.
- Herramientas: Permiten al agente acceder a información y capacidades externas, como motores de búsqueda, calculadoras y API.
- Marco ReAct: Esta metodología permite al agente razonar sobre sus objetivos, elegir las acciones adecuadas y aprender de los resultados.
- Memoria: Los agentes conversacionales necesitan memoria para retener el contexto de interacciones anteriores.
Creación de herramientas eficaces para los agentes Langchain
La verdadera fuerza de los agentes Langchain reside en las herramientas a las que pueden acceder.

Estas herramientas dotan a los agentes de las funciones necesarias para ir más allá de la simple generación de texto y realizar tareas intrincadas. A la hora de diseñar herramientas, es crucial definir con precisión las funcionalidades específicas que desea que tenga su agente. He aquí algunos consejos para crear herramientas eficaces:
- Defina un propósito claro: Cada herramienta debe tener un propósito singular y bien definido, que permita al agente identificar rápidamente cuándo y cómo utilizarla.
- Proporcione descripciones detalladas: Ofrezca descripciones claras de la función y el uso adecuado de la herramienta. Esta información es vital para que el agente evalúe si una herramienta es adecuada para responder eficazmente a una consulta.
- Garantizar entradas y salidas fiables: Las herramientas deben tener formatos de entrada y salida coherentes y bien definidos para una integración fluida con el LLM.
- Manejar los errores con elegancia: Implementar una gestión de errores robusta para evitar que el agente falle o produzca resultados erráticos si una herramienta encuentra un problema.
El marco React: Razonamiento y acción
El marco ReAct es un elemento fundamental de los agentes Langchain, ya que les permite gestionar tareas complejas entrelazando pasos de razonamiento y acción. Dentro de ReAct, el agente primero Razona sobre la tarea que tiene entre manos, luego selecciona una Acción a realizar. Tras ejecutar la acción, el agente observa el resultado y utiliza esta observación para guiar su razonamiento posterior. Este ciclo se repite hasta que se alcanza el objetivo.
El proceso ReAct ayuda al LLM a seleccionar la herramienta más adecuada analizando primero el contexto. Este marco permite a los agentes tomar decisiones mejor informadas, adaptarse a situaciones dinámicas y resolver problemas complejos que la simple generación de texto no puede abordar.
LangChain utiliza dos tipos principales de herramientas a la hora de procesar documentos:
- El método Stuff: Se devuelven múltiples documentos en su forma original, sin resumir.
- El método Map Reduce: Los elementos son procesados y resumidos.
Configuración del entorno de desarrollo para la creación de agentes
Instalación de los paquetes necesarios
Para empezar a crear herramientas para los Agentes Langchain, primero debe instalar los paquetes necesarios. Puedes hacerlo usando pip:

pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- datasets: Esta biblioteca proporciona acceso a varios conjuntos de datos, incluidas las transcripciones de podcasts.
- pod-gpt: Una biblioteca diseñada para facilitar el acceso a los datos de podcast de Lex Fridman.
- pinecone-client[grpc]: El cliente Pinecone para interactuar con la base de datos vectorial Pinecone.
- langchain: El núcleo de la biblioteca Langchain que utilizaremos.
- openai: Proporciona acceso a los modelos de OpenAI.
- tqdm: Una librería utilizada para mostrar barras de progreso.
Establecer claves API
Algunas de estas herramientas requieren claves API para funcionar, como la OPENAI_API_KEY y una clave API de Pinecone. Después de instalar los requisitos previos, el siguiente paso crítico es configurar sus claves de API para OpenAI y Pinecone:
OPENAI_API_KEY = "TU_OPENAI_API_KEY "PINECONE_API_KEY = "TU_PINECONE_API_KEY "PINECONE_ENV = "TU_PINECONE_ENV"
Obtenga una clave de API de OpenAI en platform.openai.com. Necesitará una cuenta activa para acceder a esta página.
También necesitarás tu Clave API Pinecone y tu Entorno Pinecone; los puedes encontrar en app.pinecone.io.
Descarga de un conjunto de datos predefinido
Podemos utilizar un conjunto de datos para demostrar la construcción de un chatbot. En este ejemplo, el chatbot utilizará las transcripciones del podcast de Lex Fridman:
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
Visualización del flujo del agente conversacional
El flujo típico de un agente conversacional sigue los siguientes pasos:
- Entrada: El usuario proporciona una consulta o instrucción.
- El LLM procesa la pregunta, determinando si una herramienta puede ayudar. Las herramientas proporcionan capacidades ampliadas.
- Se consulta una herramienta de base de datos. El resultado se devuelve al LLM para la toma de decisiones.
- Se formula y entrega una idea o respuesta final.
Creación de un agente de respuesta a preguntas basado en la recuperación
Formateo de datos para el indexador Pod-GPT
Para utilizar el indexador pod-gpt, debemos reformatear nuestros datos en una estructura específica:
docs = [{'id': x['video_id'],'text': x['transcript'],'metadata': {'title': x['title'],'url': x['source']}} for x in data]
Inicialización del objeto indexador
Con los datos correctamente formateados, el siguiente paso es crear un objeto indexador desde pod-gpt:
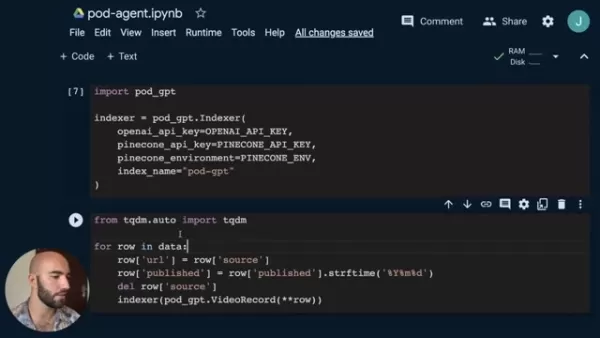
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Añadir transcripciones de podcasts a Pinecone
El proceso de indexación implica iterar a través de cada fila de datos:
from tqdm.auto import tqdmfor row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
Las transcripciones de los podcasts ya están almacenadas y pueden buscarse en Pinecone.
Inicializar Pinecone
Para inicializar una conexión con Pinecone, utilice el siguiente código:
import pineconepinecone.init(api_key=PINECONE_API_KEY,# buscar en app.pinecone.ioenvironment=PINECONE_ENV# junto a la clave api en la consola)index_name = "pod-gpt"
Acceso a Pinecone para importar OpenAI Embeddings
Acceder a los vectores en Pinecone e inicializar el almacén de vectores con OpenAI Embeddings:
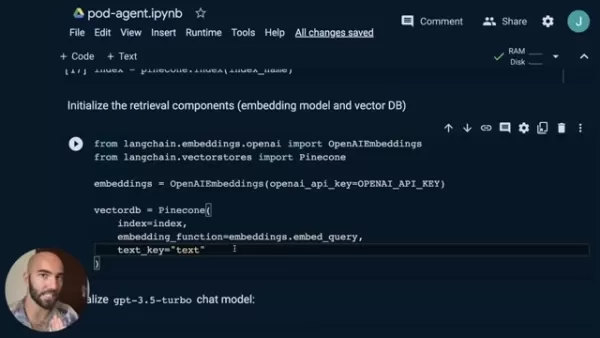
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")
Artículo relacionado
 Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
Recomendaciones de temas especiales relacionados
Negocio
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
Recomendaciones de temas especiales relacionados
Negocio
 Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

 comentario (0)
0/500
comentario (0)
0/500
En el vertiginoso mundo de la inteligencia artificial, Langchain se ha consolidado como un potente marco para desarrollar aplicaciones sofisticadas con grandes modelos lingüísticos (LLM). Una característica particularmente dinámica es su sistema de agentes, que permite a los LLM interactuar con su entorno, aprovechar las herramientas y tomar decisiones informadas para lograr objetivos complejos. Esta guía en profundidad le proporcionará un conocimiento exhaustivo de los agentes Langchain y de cómo crear herramientas que amplíen sus capacidades.
Puntos clave
Comprender el concepto fundamental de los agentes Langchain y su capacidad para interactuar con herramientas.
Aprender el proceso de creación de herramientas que amplíen las capacidades de los LLM más allá de la generación básica de texto.
Profundizar en el marco ReAct y su función a la hora de permitir el razonamiento y la selección de acciones para los Agentes.
Aprender a implementar la memoria conversacional para agentes utilizando la memoria de ventana de búfer de Langchain.
Adquirir destreza en el formateo de datos y en la elaboración de prompts efectivos para sus agentes.
Investigar aplicaciones potenciales para herramientas diseñadas para mejorar LLMs.
Entendiendo los Agentes Langchain y la Construcción de Herramientas
¿Qué son los Agentes Langchain?
Los Agentes Langchain son esencialmente Grandes Modelos de Lenguaje mejorados con la habilidad de utilizar herramientas y tomar decisiones autónomas.
A diferencia de los LLM estándar, centrados principalmente en completar texto, los Agentes pueden emplear estratégicamente herramientas externas para recopilar información, realizar cálculos o interactuar con APIs. Su diseño les permite deliberar y utilizar las herramientas proporcionadas, ofreciendo una funcionalidad significativamente mayor que el autocompletado básico. Este proceso de toma de decisiones suele estar guiado por el marco ReAct, que lleva a los agentes a alternar entre pasos de Razonamiento y Acción para abordar tareas complejas.
Componentes clave de un agente:
- LLM: el LLM es el núcleo del agente y proporciona capacidad de razonamiento y toma de decisiones.
- Herramientas: Permiten al agente acceder a información y capacidades externas, como motores de búsqueda, calculadoras y API.
- Marco ReAct: Esta metodología permite al agente razonar sobre sus objetivos, elegir las acciones adecuadas y aprender de los resultados.
- Memoria: Los agentes conversacionales necesitan memoria para retener el contexto de interacciones anteriores.
Creación de herramientas eficaces para los agentes Langchain
La verdadera fuerza de los agentes Langchain reside en las herramientas a las que pueden acceder.
Estas herramientas dotan a los agentes de las funciones necesarias para ir más allá de la simple generación de texto y realizar tareas intrincadas. A la hora de diseñar herramientas, es crucial definir con precisión las funcionalidades específicas que desea que tenga su agente. He aquí algunos consejos para crear herramientas eficaces:
- Defina un propósito claro: Cada herramienta debe tener un propósito singular y bien definido, que permita al agente identificar rápidamente cuándo y cómo utilizarla.
- Proporcione descripciones detalladas: Ofrezca descripciones claras de la función y el uso adecuado de la herramienta. Esta información es vital para que el agente evalúe si una herramienta es adecuada para responder eficazmente a una consulta.
- Garantizar entradas y salidas fiables: Las herramientas deben tener formatos de entrada y salida coherentes y bien definidos para una integración fluida con el LLM.
- Manejar los errores con elegancia: Implementar una gestión de errores robusta para evitar que el agente falle o produzca resultados erráticos si una herramienta encuentra un problema.
El marco React: Razonamiento y acción
El marco ReAct es un elemento fundamental de los agentes Langchain, ya que les permite gestionar tareas complejas entrelazando pasos de razonamiento y acción. Dentro de ReAct, el agente primero Razona sobre la tarea que tiene entre manos, luego selecciona una Acción a realizar. Tras ejecutar la acción, el agente observa el resultado y utiliza esta observación para guiar su razonamiento posterior. Este ciclo se repite hasta que se alcanza el objetivo.
El proceso ReAct ayuda al LLM a seleccionar la herramienta más adecuada analizando primero el contexto. Este marco permite a los agentes tomar decisiones mejor informadas, adaptarse a situaciones dinámicas y resolver problemas complejos que la simple generación de texto no puede abordar.
LangChain utiliza dos tipos principales de herramientas a la hora de procesar documentos:
- El método Stuff: Se devuelven múltiples documentos en su forma original, sin resumir.
- El método Map Reduce: Los elementos son procesados y resumidos.
Configuración del entorno de desarrollo para la creación de agentes
Instalación de los paquetes necesarios
Para empezar a crear herramientas para los Agentes Langchain, primero debe instalar los paquetes necesarios. Puedes hacerlo usando pip:
pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- datasets: Esta biblioteca proporciona acceso a varios conjuntos de datos, incluidas las transcripciones de podcasts.
- pod-gpt: Una biblioteca diseñada para facilitar el acceso a los datos de podcast de Lex Fridman.
- pinecone-client[grpc]: El cliente Pinecone para interactuar con la base de datos vectorial Pinecone.
- langchain: El núcleo de la biblioteca Langchain que utilizaremos.
- openai: Proporciona acceso a los modelos de OpenAI.
- tqdm: Una librería utilizada para mostrar barras de progreso.
Establecer claves API
Algunas de estas herramientas requieren claves API para funcionar, como la OPENAI_API_KEY y una clave API de Pinecone. Después de instalar los requisitos previos, el siguiente paso crítico es configurar sus claves de API para OpenAI y Pinecone:
OPENAI_API_KEY = "TU_OPENAI_API_KEY "PINECONE_API_KEY = "TU_PINECONE_API_KEY "PINECONE_ENV = "TU_PINECONE_ENV"
Obtenga una clave de API de OpenAI en platform.openai.com. Necesitará una cuenta activa para acceder a esta página.
También necesitarás tu Clave API Pinecone y tu Entorno Pinecone; los puedes encontrar en app.pinecone.io.
Descarga de un conjunto de datos predefinido
Podemos utilizar un conjunto de datos para demostrar la construcción de un chatbot. En este ejemplo, el chatbot utilizará las transcripciones del podcast de Lex Fridman:
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
Visualización del flujo del agente conversacional
El flujo típico de un agente conversacional sigue los siguientes pasos:
- Entrada: El usuario proporciona una consulta o instrucción.
- El LLM procesa la pregunta, determinando si una herramienta puede ayudar. Las herramientas proporcionan capacidades ampliadas.
- Se consulta una herramienta de base de datos. El resultado se devuelve al LLM para la toma de decisiones.
- Se formula y entrega una idea o respuesta final.
Creación de un agente de respuesta a preguntas basado en la recuperación
Formateo de datos para el indexador Pod-GPT
Para utilizar el indexador pod-gpt, debemos reformatear nuestros datos en una estructura específica:
docs = [{'id': x['video_id'],'text': x['transcript'],'metadata': {'title': x['title'],'url': x['source']}} for x in data]
Inicialización del objeto indexador
Con los datos correctamente formateados, el siguiente paso es crear un objeto indexador desde pod-gpt:
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Añadir transcripciones de podcasts a Pinecone
El proceso de indexación implica iterar a través de cada fila de datos:
from tqdm.auto import tqdmfor row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
Las transcripciones de los podcasts ya están almacenadas y pueden buscarse en Pinecone.
Inicializar Pinecone
Para inicializar una conexión con Pinecone, utilice el siguiente código:
import pineconepinecone.init(api_key=PINECONE_API_KEY,# buscar en app.pinecone.ioenvironment=PINECONE_ENV# junto a la clave api en la consola)index_name = "pod-gpt"
Acceso a Pinecone para importar OpenAI Embeddings
Acceder a los vectores en Pinecone e inicializar el almacén de vectores con OpenAI Embeddings:
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")










 Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
Claude, la IA experimental de Anthropic, lleva a cabo negociaciones y transacciones en una prueba de comercio electrónico
A medida que la inteligencia artificial avanza rápidamente, Anthropic puso en marcha discretamente el pasado viernes un experimento interno denominado «Project Deal», en el que se ponía de manifiesto
 DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
DeepSeek Code, listo para su lanzamiento
A medida que la tecnología de IA avanza a pasos agigantados, DeepSeek se encuentra en un momento decisivo. La empresa de IA ha revelado recientemente que ha conseguido más de 70 000 millones de yuanes
 Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai













