
















 家
家ラングチェーン・エージェント2025年における高度なLLMツール構築の手引き
速いペースの人工知能の世界において、Langchainは大規模言語モデル(LLM)を使った洗練されたアプリケーションを開発するための強力なフレームワークとしての地位を確立している。特にダイナミックな特徴はエージェントシステムで、LLMが周囲と相互作用し、ツールを活用し、複雑な目的を達成するために情報に基づいた意思決定を行うことができます。この詳細なガイドでは、Langchainエージェントの完全な理解と、その機能を拡張するツールの作成方法について説明します。
キーポイント
Langchainエージェントの基本概念とツールとの相互作用を理解する。
基本的なテキスト生成にとどまらず、LLMの機能を拡張するツールの作成プロセスを学ぶ。
ReActフレームワークと、エージェントのための推論とアクション選択を可能にするその機能を理解する。
Langchainのバッファウィンドウメモリを使用して、エージェントに会話メモリを実装する方法を学びます。
データをフォーマットし、エージェントに効果的なプロンプトを作成することに習熟します。
LLMを強化するために設計されたツールの潜在的なアプリケーションを調査します。
Langchainエージェントとツール構築について
Langchainエージェントとは?
Langchainエージェントは基本的に大規模言語モデルであり、ツールの利用や自律的な意思決定ができるように強化されています。

テキスト補完に重点を置いた標準的なLLMとは異なり、エージェントは外部ツールを戦略的に利用し、情報を収集したり、計算を実行したり、APIと対話したりすることができます。その設計により、基本的なオートコンプリートよりもはるかに多くの機能を提供し、提供されたツールを熟慮して使用することができます。この意思決定プロセスは、エージェントが複雑なタスクに取り組むために推論とアクションのステップを交互に繰り返すように促すReActフレームワークによって頻繁に導かれます。
エージェントの主な構成要素
- LLM: LLMはエージェントのコアとして推論と意思決定を行います。
- ツール:検索エンジン、計算機、APIなど、エージェントが外部の情報や機能にアクセスするためのものです。
- ReActフレームワーク:この方法論は、エージェントが目的について推論し、適切な行動を選択し、結果から学習することを可能にする。
- 記憶:会話型エージェントは、以前のインタラクションのコンテキストを保持するためにメモリを必要とする。
ラングチェーンエージェントのための効果的なツールの構築
Langchainエージェントの真の強みは、エージェントがアクセスできるツールにあります。

これらのツールはエージェントが単純なテキスト生成にとどまらず、複雑なタスクを実行するために必要な機能を備えています。ツールを設計する際には、エージェントに持たせたい特定の機能を正確に定義することが重要です。効果的なツールを作成するためのヒントをいくつか紹介します:
- 明確な目的を定義する: すべてのツールは、エージェントがいつ、どのように使用するかをすぐに特定できるように、明確な目的を持つべきです。
- 詳細な説明を提供する:ツールの機能と適切な使用方法について明確な説明を提供する。この情報は、エージェントがそのツールがクエリに効果的に回答するのに適しているかどうかを評価するのに不可欠です。
- 信頼できる入出力を保証する:ツールは、LLMとのスムーズな統合のために、一貫性があり、明確に定義された入出力フォーマットを持つべきである。
- エラーの優雅な処理:ツールに問題が発生した場合、エージェントが失敗したり、誤った結果を出したりしないように、堅牢なエラー処理を実装する。
リアクトフレームワーク推論とアクション
ReActフレームワークはラングチェーンエージェントの重要な要素で、推論とアクションステップを織り交ぜることで複雑なタスクを処理できるようにします。ReActの中で、エージェントはまず手元のタスクについて推論し、次に実行するアクションを選択します。アクションを実行した後、エージェントは結果を観察し、その後の推論を導くためにこの観察を使用します。このサイクルは目標が達成されるまで繰り返される。
ReActプロセスは、まずコンテキストを分析することで、LLMが最も適切なツールを選択するのを支援する。このフレームワークにより、エージェントはより良い情報に基づいた意思決定を行い、ダイナミックな状況に適応し、単純なテキスト生成では対応できない複雑な問題を解決することができる。
LangChainはドキュメントを処理する際、主に2種類のツールを利用します:
- スタッフメソッド:Stuffメソッド:複数のドキュメントを、要約されていないオリジナルの形で返す。
- Map Reduceメソッド:アイテムは処理され、要約されます。
エージェント構築のための開発環境のセットアップ
必要なパッケージのインストール
Langchainエージェント用のツールのビルドを始めるには、まず必要な前提パッケージをインストールする必要があります。これは pip を使って行います:

pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- データセット:このライブラリは、ポッドキャストのトランスクリプションを含む様々なデータセットへのアクセスを提供します。
- pod-gpt:Lex Fridmanのポッドキャストデータへのアクセスを容易にするために設計されたライブラリ。
- pinecone-client[grpc]:PineconeベクターデータベースにアクセスするためのPineconeクライアント。
- langchain:これから使うLangchainライブラリのコア。
- openai:OpenAIのモデルへのアクセスを提供します。
- tqdm:プログレスバーを表示するためのライブラリ。
APIキーの設定
これらのツールの中には、OPENAI_API_KEYやPinecone APIキーなど、機能するためにAPIキーが必要なものがあります。前提条件をインストールしたら、次に重要なのはOpenAIとPineconeのAPIキーを設定することです:
openai_api_key = "your_openai_api_key "pinecone_api_key = "your_pinecone_api_key "pinecone_env = "your_pinecone_env"
platform.openai.comからOpenAI API Keyを取得します。このページにアクセスするには、アクティブなアカウントが必要です。
また、Pinecone API Key と Pinecone Environment も必要です。これらは app.pinecone.io にあります。
構築済みデータセットのダウンロード
チャットボット構築のデモにデータセットを利用することができます。この例では、チャットボットは Lex Fridman のポッドキャストからのトランスクリプションを使用します:
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
会話エージェントフローの可視化
典型的な会話エージェントの流れは、以下のステップに従います:
- 入力:入力:ユーザが問い合わせや指示を与える。
- LLMは質問を処理し、ツールが支援できるかどうかを判断します。ツールは拡張機能を提供する。
- データベースツールが照会される。その結果は、さらなる意思決定のためにLLMにフィードバックされる。
- 最終的な考えや答えが策定され、配信される。
検索ベースの質問応答エージェントの構築
Pod-GPTインデクサのためにデータをフォーマットする
Pod-GPTインデクサを使用するには、データを特定の構造にフォーマットし直す必要があります:
docs = [{ 'id': x['video_id'],'text': x['transcript'],'metadata': {'title': x['title'],'url': x['source']}} for x in data].
Indexerオブジェクトの初期化
データが正しくフォーマットされたので、次はpod-gptからインデクサオブジェクトを作成します:
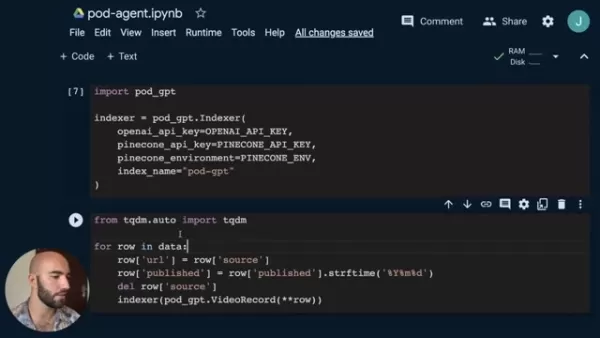
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Pineconeにポッドキャストのトランスクリプションを追加する
インデックス作成プロセスでは、各データ行を繰り返し処理します:
from tqdm.auto import tqdm for row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
これでPodcastのトランスクリプトが保存され、Pinecone内で検索できるようになりました。
Pineconeの初期化
Pineconeへの接続を初期化するには、以下のコードを使用します:
import pineconepinecone.init(api_key=PINECONE_API_KEY,# app.pinecone.ioenvironment=PINECONE_ENV#コンソールでapiキーの隣を見つける)index_name = "pod-gpt"
PineconeにアクセスしてOpenAI Embeddingsをインポートする
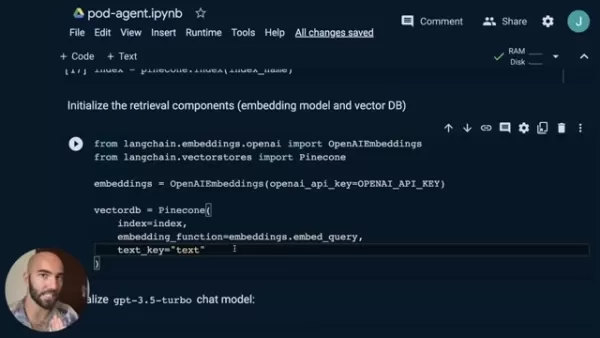
Pineconeのベクトルにアクセスし、OpenAI Embeddingsでベクトルストアを初期化します:
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")
関連記事
 Anthropic社の実験用AI「Claude」が、Eコマースのテストにおいて交渉と取引を完了した
人工知能(AI)が急速に進化する中、Anthropicは先週金曜日、「Project Deal」と呼ばれる社内実験をひっそりと開始し、EコマースにおけるAIの可能性を披露した。この実験では、同社のAIモデル「Claude」が、実際の金銭取引を伴うクローズドな市場環境において、購入、販売、価格交渉を自律的に行うよう設計された。実験の中核となったのは、Slack上に構築された社内マーケットプレイスであ
DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
関連特集おすすめ
仕事
Anthropic社の実験用AI「Claude」が、Eコマースのテストにおいて交渉と取引を完了した
人工知能(AI)が急速に進化する中、Anthropicは先週金曜日、「Project Deal」と呼ばれる社内実験をひっそりと開始し、EコマースにおけるAIの可能性を披露した。この実験では、同社のAIモデル「Claude」が、実際の金銭取引を伴うクローズドな市場環境において、購入、販売、価格交渉を自律的に行うよう設計された。実験の中核となったのは、Slack上に構築された社内マーケットプレイスであ
DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
関連特集おすすめ
仕事
 おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
 10 ツール
10 ツール
 xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

 コメント (0)
0/500
コメント (0)
0/500
速いペースの人工知能の世界において、Langchainは大規模言語モデル(LLM)を使った洗練されたアプリケーションを開発するための強力なフレームワークとしての地位を確立している。特にダイナミックな特徴はエージェントシステムで、LLMが周囲と相互作用し、ツールを活用し、複雑な目的を達成するために情報に基づいた意思決定を行うことができます。この詳細なガイドでは、Langchainエージェントの完全な理解と、その機能を拡張するツールの作成方法について説明します。
キーポイント
Langchainエージェントの基本概念とツールとの相互作用を理解する。
基本的なテキスト生成にとどまらず、LLMの機能を拡張するツールの作成プロセスを学ぶ。
ReActフレームワークと、エージェントのための推論とアクション選択を可能にするその機能を理解する。
Langchainのバッファウィンドウメモリを使用して、エージェントに会話メモリを実装する方法を学びます。
データをフォーマットし、エージェントに効果的なプロンプトを作成することに習熟します。
LLMを強化するために設計されたツールの潜在的なアプリケーションを調査します。
Langchainエージェントとツール構築について
Langchainエージェントとは?
Langchainエージェントは基本的に大規模言語モデルであり、ツールの利用や自律的な意思決定ができるように強化されています。
テキスト補完に重点を置いた標準的なLLMとは異なり、エージェントは外部ツールを戦略的に利用し、情報を収集したり、計算を実行したり、APIと対話したりすることができます。その設計により、基本的なオートコンプリートよりもはるかに多くの機能を提供し、提供されたツールを熟慮して使用することができます。この意思決定プロセスは、エージェントが複雑なタスクに取り組むために推論とアクションのステップを交互に繰り返すように促すReActフレームワークによって頻繁に導かれます。
エージェントの主な構成要素
- LLM: LLMはエージェントのコアとして推論と意思決定を行います。
- ツール:検索エンジン、計算機、APIなど、エージェントが外部の情報や機能にアクセスするためのものです。
- ReActフレームワーク:この方法論は、エージェントが目的について推論し、適切な行動を選択し、結果から学習することを可能にする。
- 記憶:会話型エージェントは、以前のインタラクションのコンテキストを保持するためにメモリを必要とする。
ラングチェーンエージェントのための効果的なツールの構築
Langchainエージェントの真の強みは、エージェントがアクセスできるツールにあります。
これらのツールはエージェントが単純なテキスト生成にとどまらず、複雑なタスクを実行するために必要な機能を備えています。ツールを設計する際には、エージェントに持たせたい特定の機能を正確に定義することが重要です。効果的なツールを作成するためのヒントをいくつか紹介します:
- 明確な目的を定義する: すべてのツールは、エージェントがいつ、どのように使用するかをすぐに特定できるように、明確な目的を持つべきです。
- 詳細な説明を提供する:ツールの機能と適切な使用方法について明確な説明を提供する。この情報は、エージェントがそのツールがクエリに効果的に回答するのに適しているかどうかを評価するのに不可欠です。
- 信頼できる入出力を保証する:ツールは、LLMとのスムーズな統合のために、一貫性があり、明確に定義された入出力フォーマットを持つべきである。
- エラーの優雅な処理:ツールに問題が発生した場合、エージェントが失敗したり、誤った結果を出したりしないように、堅牢なエラー処理を実装する。
リアクトフレームワーク推論とアクション
ReActフレームワークはラングチェーンエージェントの重要な要素で、推論とアクションステップを織り交ぜることで複雑なタスクを処理できるようにします。ReActの中で、エージェントはまず手元のタスクについて推論し、次に実行するアクションを選択します。アクションを実行した後、エージェントは結果を観察し、その後の推論を導くためにこの観察を使用します。このサイクルは目標が達成されるまで繰り返される。
ReActプロセスは、まずコンテキストを分析することで、LLMが最も適切なツールを選択するのを支援する。このフレームワークにより、エージェントはより良い情報に基づいた意思決定を行い、ダイナミックな状況に適応し、単純なテキスト生成では対応できない複雑な問題を解決することができる。
LangChainはドキュメントを処理する際、主に2種類のツールを利用します:
- スタッフメソッド:Stuffメソッド:複数のドキュメントを、要約されていないオリジナルの形で返す。
- Map Reduceメソッド:アイテムは処理され、要約されます。
エージェント構築のための開発環境のセットアップ
必要なパッケージのインストール
Langchainエージェント用のツールのビルドを始めるには、まず必要な前提パッケージをインストールする必要があります。これは pip を使って行います:
pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- データセット:このライブラリは、ポッドキャストのトランスクリプションを含む様々なデータセットへのアクセスを提供します。
- pod-gpt:Lex Fridmanのポッドキャストデータへのアクセスを容易にするために設計されたライブラリ。
- pinecone-client[grpc]:PineconeベクターデータベースにアクセスするためのPineconeクライアント。
- langchain:これから使うLangchainライブラリのコア。
- openai:OpenAIのモデルへのアクセスを提供します。
- tqdm:プログレスバーを表示するためのライブラリ。
APIキーの設定
これらのツールの中には、OPENAI_API_KEYやPinecone APIキーなど、機能するためにAPIキーが必要なものがあります。前提条件をインストールしたら、次に重要なのはOpenAIとPineconeのAPIキーを設定することです:
openai_api_key = "your_openai_api_key "pinecone_api_key = "your_pinecone_api_key "pinecone_env = "your_pinecone_env"
platform.openai.comからOpenAI API Keyを取得します。このページにアクセスするには、アクティブなアカウントが必要です。
また、Pinecone API Key と Pinecone Environment も必要です。これらは app.pinecone.io にあります。
構築済みデータセットのダウンロード
チャットボット構築のデモにデータセットを利用することができます。この例では、チャットボットは Lex Fridman のポッドキャストからのトランスクリプションを使用します:
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
会話エージェントフローの可視化
典型的な会話エージェントの流れは、以下のステップに従います:
- 入力:入力:ユーザが問い合わせや指示を与える。
- LLMは質問を処理し、ツールが支援できるかどうかを判断します。ツールは拡張機能を提供する。
- データベースツールが照会される。その結果は、さらなる意思決定のためにLLMにフィードバックされる。
- 最終的な考えや答えが策定され、配信される。
検索ベースの質問応答エージェントの構築
Pod-GPTインデクサのためにデータをフォーマットする
Pod-GPTインデクサを使用するには、データを特定の構造にフォーマットし直す必要があります:
docs = [{ 'id': x['video_id'],'text': x['transcript'],'metadata': {'title': x['title'],'url': x['source']}} for x in data].
Indexerオブジェクトの初期化
データが正しくフォーマットされたので、次はpod-gptからインデクサオブジェクトを作成します:
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Pineconeにポッドキャストのトランスクリプションを追加する
インデックス作成プロセスでは、各データ行を繰り返し処理します:
from tqdm.auto import tqdm for row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
これでPodcastのトランスクリプトが保存され、Pinecone内で検索できるようになりました。
Pineconeの初期化
Pineconeへの接続を初期化するには、以下のコードを使用します:
import pineconepinecone.init(api_key=PINECONE_API_KEY,# app.pinecone.ioenvironment=PINECONE_ENV#コンソールでapiキーの隣を見つける)index_name = "pod-gpt"
PineconeにアクセスしてOpenAI Embeddingsをインポートする
Pineconeのベクトルにアクセスし、OpenAI Embeddingsでベクトルストアを初期化します:
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")










 Anthropic社の実験用AI「Claude」が、Eコマースのテストにおいて交渉と取引を完了した
人工知能(AI)が急速に進化する中、Anthropicは先週金曜日、「Project Deal」と呼ばれる社内実験をひっそりと開始し、EコマースにおけるAIの可能性を披露した。この実験では、同社のAIモデル「Claude」が、実際の金銭取引を伴うクローズドな市場環境において、購入、販売、価格交渉を自律的に行うよう設計された。実験の中核となったのは、Slack上に構築された社内マーケットプレイスであ
Anthropic社の実験用AI「Claude」が、Eコマースのテストにおいて交渉と取引を完了した
人工知能(AI)が急速に進化する中、Anthropicは先週金曜日、「Project Deal」と呼ばれる社内実験をひっそりと開始し、EコマースにおけるAIの可能性を披露した。この実験では、同社のAIモデル「Claude」が、実際の金銭取引を伴うクローズドな市場環境において、購入、販売、価格交渉を自律的に行うよう設計された。実験の中核となったのは、Slack上に構築された社内マーケットプレイスであ
 DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
DeepSeek Code、まもなくリリースへ
AI技術の進展が加速する中、DeepSeekは今、まさに刺激的な転換点を迎えています。同社は最近、700億元を超える資金調達に成功したことを明らかにしました。経営陣は、目先の商業的利益よりも、画期的なAI研究への取り組みを重視する姿勢を強調しています。この戦略的転換は、新製品、とりわけ待望の「DeepSeek Code」の開発に全力を注ぐというDeepSeekの決意を示しています。DeepSeek
 マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(
マスク氏の「Grok」:1.5兆のパラメータとカーソルコードの統合――ゲームチェンジャーか、それともブラフか?
イーロン・マスクがついに動き出した。AI開発競争において、OpenAIとAnthropicは加速している一方、xAIは出遅れているようだ。マスクはたびたび「Claude」に対抗する意向を表明してきたが、Grok4.Xシリーズへの度重なるアップデートにもかかわらず、結果は理論上は良好に見えても実用面では不十分であり、その差はほとんど縮まっていない。しかし、今回、彼には新たな切り札がある。マスクはX(

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai













