
















 Maison
MaisonLangchain Agents : Un guide pour construire des outils LLM avancés en 2025
Dans le monde en pleine évolution de l'intelligence artificielle, Langchain s'est imposé comme un cadre puissant pour le développement d'applications sophistiquées avec de grands modèles de langage (LLM). Une caractéristique particulièrement dynamique est son système d'agents, qui permet aux LLM d'interagir avec leur environnement, d'utiliser des outils et de prendre des décisions éclairées pour atteindre des objectifs complexes. Ce guide approfondi vous permettra de comprendre les agents Langchain et de créer des outils qui étendent leurs capacités.
Points clés
Comprendre le concept fondamental des agents Langchain et leur capacité à interagir avec des outils.
Apprendre le processus de création d'outils qui étendent les capacités des LLM au-delà de la génération de texte de base.
Approfondir le cadre ReAct et sa fonction de raisonnement et de sélection d'actions pour les agents.
Apprendre à implémenter la mémoire conversationnelle pour les agents en utilisant la mémoire tampon de Langchain.
Devenir compétent dans le formatage des données et l'élaboration de messages-guides efficaces pour vos agents.
Étudier les applications potentielles des outils conçus pour améliorer les LLM.
Comprendre les agents Langchain et la construction d'outils
Que sont les agents Langchain ?
Les agents Langchain sont essentiellement de grands modèles linguistiques dotés de la capacité d'utiliser des outils et de prendre des décisions autonomes.

Contrairement aux LLM standard qui se concentrent principalement sur l'achèvement du texte, les agents peuvent utiliser stratégiquement des outils externes pour recueillir des informations, effectuer des calculs ou interagir avec des API. Leur conception leur permet de délibérer et d'utiliser les outils fournis, offrant ainsi une fonctionnalité nettement supérieure à celle de l'autocomplétion de base. Ce processus de prise de décision est souvent guidé par le cadre ReAct, qui incite les agents à alterner entre les étapes de raisonnement et d'action pour s'attaquer à des tâches complexes.
Composants clés d'un agent :
- LLM : le LLM est le cœur de l'agent et lui confère un pouvoir de raisonnement et de décision.
- Outils : Ils permettent à l'agent d'accéder à des informations et à des capacités externes, telles que des moteurs de recherche, des calculateurs et des API.
- Cadre ReAct : Cette méthodologie permet à l'agent de raisonner sur ses objectifs, de choisir les actions appropriées et d'apprendre des résultats.
- Mémoire : Les agents conversationnels ont besoin de mémoire pour conserver le contexte des interactions précédentes.
Construire des outils efficaces pour les agents Langchain
La véritable force des agents Langchain réside dans les outils auxquels ils ont accès.

Ces outils dotent les agents des fonctions nécessaires pour aller au-delà de la simple génération de texte et effectuer des tâches complexes. Lors de la conception d'outils, il est essentiel de définir précisément les fonctionnalités spécifiques que vous souhaitez pour votre agent. Voici quelques conseils pour créer des outils efficaces :
- Définir un objectif clair : chaque outil doit avoir un objectif unique et bien défini, ce qui permet à l'agent de savoir rapidement quand et comment l'utiliser.
- Fournir des descriptions détaillées : Offrez des descriptions claires de la fonction de l'outil et de son utilisation correcte. Ces informations sont essentielles pour permettre à l'agent de déterminer si un outil permet de répondre efficacement à une requête.
- Garantir la fiabilité des données d'entrée et de sortie : Les outils doivent avoir des formats d'entrée et de sortie cohérents et bien définis pour une intégration harmonieuse avec le LLM.
- Traiter les erreurs avec élégance : Mettre en œuvre une gestion robuste des erreurs pour éviter que l'agent n'échoue ou ne produise des résultats erratiques si un outil rencontre un problème.
Le cadre React : Raisonnement et action
Le cadre ReAct est un élément central des agents Langchain, leur permettant de gérer des tâches complexes en imbriquant des étapes de raisonnement et d'action. Dans ReAct, l'agent raisonne d'abord sur la tâche à accomplir, puis sélectionne une action à réaliser. Après avoir exécuté l'action, l'agent observe le résultat et utilise cette observation pour guider son raisonnement ultérieur. Ce cycle se répète jusqu'à ce que l'objectif soit atteint.
Le processus ReAct aide le LLM à sélectionner l'outil le plus approprié en analysant d'abord le contexte. Ce cadre permet aux agents de prendre des décisions mieux informées, de s'adapter à des situations dynamiques et de résoudre des problèmes complexes que la simple génération de texte ne peut résoudre.
LangChain utilise deux types d'outils principaux pour traiter les documents :
- La méthode Stuff : Les documents multiples sont renvoyés dans leur forme originale, non résumée.
- La méthode Map Reduce : Les éléments sont traités et résumés.
Configuration de votre environnement de développement pour la création d'agents
Installation des paquets nécessaires
Pour commencer à construire des outils pour les Agents Langchain, vous devez d'abord installer les paquets pré-requis nécessaires. Vous pouvez le faire en utilisant pip :

pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- datasets : Cette bibliothèque permet d'accéder à divers ensembles de données, y compris les transcriptions de podcasts.
- pod-gpt : Une bibliothèque conçue pour faciliter l'accès aux données des podcasts de Lex Fridman.
- pinecone-client[grpc] : Le client Pinecone pour interagir avec la base de données vectorielle Pinecone.
- langchain : La bibliothèque Langchain que nous utiliserons.
- openai : Permet d'accéder aux modèles d'OpenAI.
- tqdm : Une bibliothèque utilisée pour afficher des barres de progression.
Définition des clés API
Certains de ces outils nécessitent des clés API pour fonctionner, comme la clé OPENAI_API_KEY et une clé API Pinecone. Après avoir installé les prérequis, la prochaine étape critique est de configurer vos clés API pour OpenAI et Pinecone :
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY "PINECONE_API_KEY = "YOUR_PINECONE_API_KEY "PINECONE_ENV = "YOUR_PINECONE_ENV"
Obtenez une clé API OpenAI à partir de platform.openai.com. Vous aurez besoin d'un compte actif pour accéder à cette page.
Vous aurez également besoin de votre clé API Pinecone et de votre environnement Pinecone ; ceux-ci peuvent être trouvés sur app.pinecone.io.
Téléchargement d'un jeu de données préconstruit
Nous pouvons utiliser un ensemble de données pour démontrer la construction d'un chatbot. Pour cet exemple, le chatbot utilisera les transcriptions du podcast de Lex Fridman :
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
Visualisation du flux de l'agent conversationnel
Le flux typique d'un agent conversationnel suit les étapes suivantes :
- Entrée : L'utilisateur fournit une requête ou une instruction.
- Le LLM traite la question et détermine si un outil peut l'aider. Les outils fournissent des capacités étendues.
- Un outil de base de données est interrogé. Le résultat est transmis au LLM pour une prise de décision ultérieure.
- Une réflexion ou une réponse finale est formulée et fournie.
Construction d'un agent de réponse aux questions basé sur l'extraction
Formatage des données pour l'indexeur Pod-GPT
Pour utiliser l'indexeur pod-gpt, nous devons reformater nos données dans une structure spécifique :
docs = [{'id' : x['video_id'], 'text' : x['transcript'], 'metadata' : {'title' : x['title'], 'url' : x['source']}} for x in data]
Initialisation de l'objet indexeur
Les données étant correctement formatées, l'étape suivante consiste à créer un objet indexeur à partir de pod-gpt :
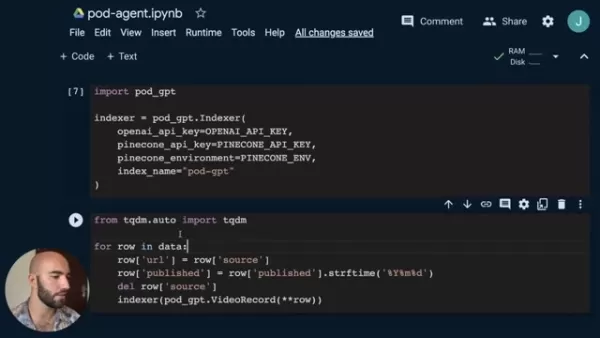
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Ajouter des transcriptions de podcasts à Pinecone
Le processus d'indexation consiste à itérer sur chaque ligne de données :
from tqdm.auto import tqdmfor row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
Les transcriptions des podcasts sont maintenant stockées et consultables dans Pinecone.
Initialiser Pinecone
Pour initialiser une connexion à Pinecone, utilisez le code suivant :
import pineconepinecone.init(api_key=PINECONE_API_KEY,# find at app.pinecone.ioenvironment=PINECONE_ENV# next to api key in console)index_name = "pod-gpt"
Accéder à Pinecone pour importer les Embeddings OpenAI
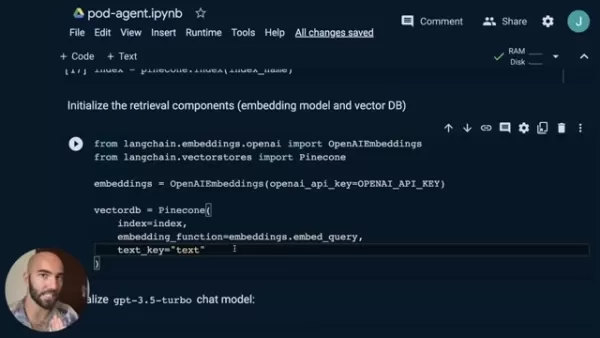
Accéder aux vecteurs dans Pinecone et initialiser le magasin de vecteurs avec OpenAI Embeddings :
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")
Article connexe
 WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
Recommandations de sujets spéciaux liés
Entreprise
WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
Recommandations de sujets spéciaux liés
Entreprise
 Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
 10 outils
10 outils
 xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

 commentaires (0)
commentaires (0)
Dans le monde en pleine évolution de l'intelligence artificielle, Langchain s'est imposé comme un cadre puissant pour le développement d'applications sophistiquées avec de grands modèles de langage (LLM). Une caractéristique particulièrement dynamique est son système d'agents, qui permet aux LLM d'interagir avec leur environnement, d'utiliser des outils et de prendre des décisions éclairées pour atteindre des objectifs complexes. Ce guide approfondi vous permettra de comprendre les agents Langchain et de créer des outils qui étendent leurs capacités.
Points clés
Comprendre le concept fondamental des agents Langchain et leur capacité à interagir avec des outils.
Apprendre le processus de création d'outils qui étendent les capacités des LLM au-delà de la génération de texte de base.
Approfondir le cadre ReAct et sa fonction de raisonnement et de sélection d'actions pour les agents.
Apprendre à implémenter la mémoire conversationnelle pour les agents en utilisant la mémoire tampon de Langchain.
Devenir compétent dans le formatage des données et l'élaboration de messages-guides efficaces pour vos agents.
Étudier les applications potentielles des outils conçus pour améliorer les LLM.
Comprendre les agents Langchain et la construction d'outils
Que sont les agents Langchain ?
Les agents Langchain sont essentiellement de grands modèles linguistiques dotés de la capacité d'utiliser des outils et de prendre des décisions autonomes.
Contrairement aux LLM standard qui se concentrent principalement sur l'achèvement du texte, les agents peuvent utiliser stratégiquement des outils externes pour recueillir des informations, effectuer des calculs ou interagir avec des API. Leur conception leur permet de délibérer et d'utiliser les outils fournis, offrant ainsi une fonctionnalité nettement supérieure à celle de l'autocomplétion de base. Ce processus de prise de décision est souvent guidé par le cadre ReAct, qui incite les agents à alterner entre les étapes de raisonnement et d'action pour s'attaquer à des tâches complexes.
Composants clés d'un agent :
- LLM : le LLM est le cœur de l'agent et lui confère un pouvoir de raisonnement et de décision.
- Outils : Ils permettent à l'agent d'accéder à des informations et à des capacités externes, telles que des moteurs de recherche, des calculateurs et des API.
- Cadre ReAct : Cette méthodologie permet à l'agent de raisonner sur ses objectifs, de choisir les actions appropriées et d'apprendre des résultats.
- Mémoire : Les agents conversationnels ont besoin de mémoire pour conserver le contexte des interactions précédentes.
Construire des outils efficaces pour les agents Langchain
La véritable force des agents Langchain réside dans les outils auxquels ils ont accès.
Ces outils dotent les agents des fonctions nécessaires pour aller au-delà de la simple génération de texte et effectuer des tâches complexes. Lors de la conception d'outils, il est essentiel de définir précisément les fonctionnalités spécifiques que vous souhaitez pour votre agent. Voici quelques conseils pour créer des outils efficaces :
- Définir un objectif clair : chaque outil doit avoir un objectif unique et bien défini, ce qui permet à l'agent de savoir rapidement quand et comment l'utiliser.
- Fournir des descriptions détaillées : Offrez des descriptions claires de la fonction de l'outil et de son utilisation correcte. Ces informations sont essentielles pour permettre à l'agent de déterminer si un outil permet de répondre efficacement à une requête.
- Garantir la fiabilité des données d'entrée et de sortie : Les outils doivent avoir des formats d'entrée et de sortie cohérents et bien définis pour une intégration harmonieuse avec le LLM.
- Traiter les erreurs avec élégance : Mettre en œuvre une gestion robuste des erreurs pour éviter que l'agent n'échoue ou ne produise des résultats erratiques si un outil rencontre un problème.
Le cadre React : Raisonnement et action
Le cadre ReAct est un élément central des agents Langchain, leur permettant de gérer des tâches complexes en imbriquant des étapes de raisonnement et d'action. Dans ReAct, l'agent raisonne d'abord sur la tâche à accomplir, puis sélectionne une action à réaliser. Après avoir exécuté l'action, l'agent observe le résultat et utilise cette observation pour guider son raisonnement ultérieur. Ce cycle se répète jusqu'à ce que l'objectif soit atteint.
Le processus ReAct aide le LLM à sélectionner l'outil le plus approprié en analysant d'abord le contexte. Ce cadre permet aux agents de prendre des décisions mieux informées, de s'adapter à des situations dynamiques et de résoudre des problèmes complexes que la simple génération de texte ne peut résoudre.
LangChain utilise deux types d'outils principaux pour traiter les documents :
- La méthode Stuff : Les documents multiples sont renvoyés dans leur forme originale, non résumée.
- La méthode Map Reduce : Les éléments sont traités et résumés.
Configuration de votre environnement de développement pour la création d'agents
Installation des paquets nécessaires
Pour commencer à construire des outils pour les Agents Langchain, vous devez d'abord installer les paquets pré-requis nécessaires. Vous pouvez le faire en utilisant pip :
pip install -qU datasets Pod-gpt Pinecone-client[grpc] langchain OpenAI tqdm
- datasets : Cette bibliothèque permet d'accéder à divers ensembles de données, y compris les transcriptions de podcasts.
- pod-gpt : Une bibliothèque conçue pour faciliter l'accès aux données des podcasts de Lex Fridman.
- pinecone-client[grpc] : Le client Pinecone pour interagir avec la base de données vectorielle Pinecone.
- langchain : La bibliothèque Langchain que nous utiliserons.
- openai : Permet d'accéder aux modèles d'OpenAI.
- tqdm : Une bibliothèque utilisée pour afficher des barres de progression.
Définition des clés API
Certains de ces outils nécessitent des clés API pour fonctionner, comme la clé OPENAI_API_KEY et une clé API Pinecone. Après avoir installé les prérequis, la prochaine étape critique est de configurer vos clés API pour OpenAI et Pinecone :
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY "PINECONE_API_KEY = "YOUR_PINECONE_API_KEY "PINECONE_ENV = "YOUR_PINECONE_ENV"
Obtenez une clé API OpenAI à partir de platform.openai.com. Vous aurez besoin d'un compte actif pour accéder à cette page.
Vous aurez également besoin de votre clé API Pinecone et de votre environnement Pinecone ; ceux-ci peuvent être trouvés sur app.pinecone.io.
Téléchargement d'un jeu de données préconstruit
Nous pouvons utiliser un ensemble de données pour démontrer la construction d'un chatbot. Pour cet exemple, le chatbot utilisera les transcriptions du podcast de Lex Fridman :
from datasets import load_datasetdata = load_dataset('jamescalam/lex-transcripts', split='train')
Visualisation du flux de l'agent conversationnel
Le flux typique d'un agent conversationnel suit les étapes suivantes :
- Entrée : L'utilisateur fournit une requête ou une instruction.
- Le LLM traite la question et détermine si un outil peut l'aider. Les outils fournissent des capacités étendues.
- Un outil de base de données est interrogé. Le résultat est transmis au LLM pour une prise de décision ultérieure.
- Une réflexion ou une réponse finale est formulée et fournie.
Construction d'un agent de réponse aux questions basé sur l'extraction
Formatage des données pour l'indexeur Pod-GPT
Pour utiliser l'indexeur pod-gpt, nous devons reformater nos données dans une structure spécifique :
docs = [{'id' : x['video_id'], 'text' : x['transcript'], 'metadata' : {'title' : x['title'], 'url' : x['source']}} for x in data]
Initialisation de l'objet indexeur
Les données étant correctement formatées, l'étape suivante consiste à créer un objet indexeur à partir de pod-gpt :
indexer = pod_gpt.Indexer(openai_api_key=OPENAI_API_KEY,pinecone_api_key=PINECONE_API_KEY,pinecone_environment=PINECONE_ENV,index_name="pod-gpt")
Ajouter des transcriptions de podcasts à Pinecone
Le processus d'indexation consiste à itérer sur chaque ligne de données :
from tqdm.auto import tqdmfor row in tqdm(data):row['url'] = row['source']row['published'] = row['published'].strftime("%Y%m%d")del row['source']indexer.index([row])
Les transcriptions des podcasts sont maintenant stockées et consultables dans Pinecone.
Initialiser Pinecone
Pour initialiser une connexion à Pinecone, utilisez le code suivant :
import pineconepinecone.init(api_key=PINECONE_API_KEY,# find at app.pinecone.ioenvironment=PINECONE_ENV# next to api key in console)index_name = "pod-gpt"
Accéder à Pinecone pour importer les Embeddings OpenAI
Accéder aux vecteurs dans Pinecone et initialiser le magasin de vecteurs avec OpenAI Embeddings :
from langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pineconeembeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)index = pinecone.Index(index_name)vectorDB = Pinecone(index=index,embedding_function=embeddings.embed_query,text_key="text")










 WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
WordPress.com permet désormais à des agents IA de rédiger et de publier des articles, et bien plus encore
WordPress.com, la célèbre plateforme d'hébergement et de publication Web, se tourne désormais vers les agents IA, une initiative qui pourrait bien redéfinir l'apparence et l'ergonomie du Web. La socié
 Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
Claude, l'IA expérimentale d'Anthropic, mène à bien des négociations et des transactions dans le cadre d'un test de commerce électronique
Alors que l'intelligence artificielle progresse à grands pas, Anthropic a discrètement lancé vendredi dernier une expérience interne baptisée « Project Deal », visant à mettre en avant le potentiel de
 DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.
DeepSeek Code s'apprête à être lancé
Alors que les technologies d'IA progressent à grands pas, DeepSeek se trouve à un tournant passionnant. L'entreprise spécialisée dans l'IA a récemment annoncé avoir levé plus de 70 milliards de yuans.

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai













