データエンジニアリングインタビューの準備:究極のガイドとチートシート

 2025年4月30日
2025年4月30日

 FrankJackson
FrankJackson

 0
0
データエンジニアリングインタビューの世界をナビゲートします
データエンジニアリングのインタビューの旅に着手すると、テクノロジーと概念の迷路に足を踏み入れるように感じることができます。圧倒されるのは簡単ですが、適切な焦点を合わせることで、エネルギーを効果的に導くことができます。このガイドはコンパスとして機能し、データエンジニアリングインタビューの準備に構造化されたアプローチを提供します。必須の技術的スキルからプロジェクトのライフサイクルの理解まで、成功するために必要な知識と自信を持って、ベテランのデータ専門家と新人の両方に分野に力を与えるように設計されています。
マスターへのキーポイント
- ETL、データモデリング、データウェアハウジングなどのデータエンジニアリングのコア概念を把握します。
- AWS、Azure、GCPなどのクラウドサービスを使用して、SQL、Python、習熟度などの技術的スキルを磨きます。
- データエンジニアリングプロジェクトを紹介するポートフォリオを構築して、専門知識と経験を実証します。
- 問題解決とシステムの設計に焦点を当てて、典型的なインタビューの質問に備えてください。
- 要件の収集からダッシュボードの作成まで、データエンジニアリングプロジェクトの完全なサイクルを理解してください。
データモデリングとデータ設計に焦点を当てます
ETLとデータパイプラインに熟練することが重要です。これらのスキルは、効果的なデータ管理のバックボーンを形成し、この分野で高く評価されています。
データエンジニアリングの基礎を理解する
データエンジニアリングとは何ですか?
データエンジニアリングは、データ駆動型の組織の背後にある名も込められていないヒーローです。これは、RAWデータをデータサイエンティスト、ビジネスアナリスト、および利害関係者にとって使用可能な形式に変換する芸術と科学です。データエンジニアは、組織が大量のデータを収集、処理、保存、分析できるインフラストラクチャを設計、構築、維持するアーキテクトです。

この分野には、データの摂取や抽出から変換、清掃、保管、倉庫、パイプライン開発、自動化、セキュリティガバナンスまで、さまざまな専門分野が含まれています。データエンジニアは、情報に基づいた意思決定を促進する堅牢でスケーラブルで信頼性の高いデータシステムを作成します。また、データをアクセスしやすくするだけでなく、生データ分析に飛び込んで傾向を明らかにし、短期および長期のビジネス戦略を形成する予測モデルを構築します。データエンジニアリングがなければ、データの広大な海をナビゲートすることはほぼ不可能です。
データエンジニアの役割
データエンジニアは、さまざまな環境で動作し、生データを収集、管理、変換するシステムを構築し、データサイエンティストとビジネスアナリストのための実用的な洞察に変換します。彼らの主な使命は、データをアクセスしやすく、組織がパフォーマンスを評価および強化するために有用にすることです。

彼らの主な責任は次のとおりです。
- データパイプラインの開発と維持。
- データ倉庫とデータ湖の構築と最適化。
- データの品質と完全性を確保します。
- データ処理タスクの自動化。
- データ科学者やビジネスアナリストと協力して、データのニーズを満たします。
- データセキュリティ対策の実装。
- データ関連の問題のトラブルシューティング。
データエンジニアのための主要な技術的スキル
データエンジニアリングで繁栄するために、特定の技術的スキルは交渉不可能です。
- SQL:リレーショナルデータベースのデータをクエリ、操作、および管理するための礎石。
- Python:データ処理、自動化、スクリプトに広範囲に使用される多目的言語。
- クラウドコンピューティング:データストレージ、処理、分析のためのAWS、Azure、GCPなどのプラットフォームを使用する習熟度。
- ETLツール:データパイプラインを調整するためのApache Airflowなどのツールに精通しています。
- Spark:大規模なデータセットを処理するための強力なフレームワーク。
データエンジニアリングプロジェクトのライフサイクルのナビゲート
データエンジニアリングプロジェクトの手順
データエンジニアリングプロジェクトのさまざまな段階を理解することは、成功に不可欠です。これが典型的なプロジェクトのライフサイクルです:
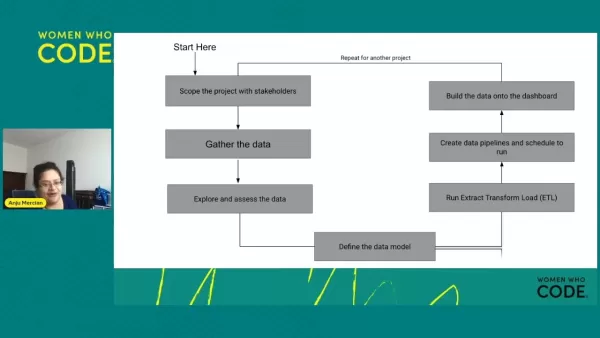
- 利害関係者とのプロジェクトの範囲:プロジェクトの目標と要件を定義することから始めます。成功した結果を達成するために、ビジネスニーズと技術的制約を理解することが重要です。
- データの収集:データベース、API、データストリームなど、内部および外部の両方のさまざまなソースからデータを収集します。
- データを調査して評価する:データを分析して、その構造、品質、および潜在的な問題を理解します。これにより、クリーニングと変換が必要なものを特定できます。
- データモデルを定義します。データモデルを設計して、データを構成して効率的に保存します。これには、データ型の選択、関係の定義、クエリパフォーマンスの最適化が含まれます。
- 実行抽出変換負荷(ETL): ETLプロセスを実装してデータを抽出し、使用可能な形式に変換し、ターゲットデータウェアハウスまたはデータレイクにロードします。
- データパイプラインと実行するスケジュールを作成します。自動データパイプラインを開発して、スケジュールタスク、データフローの監視、取り扱いエラーなどの定期的なデータ処理と更新を確保します。
- データをダッシュボードに作成します。ダッシュボードと視覚化を作成して、処理されたデータを理解できる形式で提示し、利害関係者が洞察を得て情報に基づいた決定を下すことができます。データアナリストはしばしばこの段階を処理することに注意してください。
データエンジニアリングインタビューの準備
データエンジニアリングインタビュー構造の理解
データエンジニアリングのインタビューは通常、ソフトウェアエンジニアリングのインタビューに似た構造に従います。通常、3〜4ラウンドで構成されています。
- テクニカルラウンド:これらは、SQLやPythonなどのコア技術スキルに焦点を当て、コーディングの課題、問題解決の質問、データ構造とアルゴリズムに関する議論を備えています。
- データモデリングと設計:これにより、データモデルを設計し、データウェアハウジングの概念を理解し、効率的なデータパイプラインを作成する能力が評価されます。
- データパイプライン:これにより、データパイプラインの設計と維持のスキルが評価されます。
技術的なインタビューの準備:SQLとPython
技術的なインタビューをACEするには、SQLとPythonに焦点を当てます。
SQL:
- 基本をマスターする: SQL構文、データ型、および一般的なクエリパターンを確認します。
- 複雑なクエリを練習する:クエリの最適化とパフォーマンスに注目して、複数のテーブルからのデータをフィルタリング、集約、および結合するためのクエリの作成に取り組みます。
- データウェアハウジングの概念を理解する:スタースキーマ、スノーフレークスキーマ、およびその他のデータウェアハウジングの概念に慣れる。
Python:
- データ操作ライブラリ:データの操作、クリーニング、分析のために、パンダやNumpyなどのライブラリに精通しています。
- スクリプトと自動化:データの摂取、変換、読み込みなどの一般的なデータエンジニアリングタスクを自動化するためのスクリプトを作成する練習。
- データ構造とアルゴリズム:基本的なデータ構造とアルゴリズムに関する知識を更新して、効率的なデータ処理を確保します。
マスタリングデータモデリング
データのモデリングと設計については、次を検討してください。
- 寸法モデリング:事実、寸法、測定の識別を含む、次元モデリングの原則を理解します。
- データの正規化:データの正規化手法について学び、冗長性を減らし、データの整合性を向上させます。
- データウェアハウジングの概念:スタースキーマ、スノーフレークスキーマ、データボールトモデリングなどの概念を確認します。
- 実際のシナリオ:データボリューム、クエリパターン、ビジネス要件などの要因を考慮して、実際のシナリオのデータモデルの設計を練習します。
- 一般的なデータ形式の理解: CSV、JSON、XMLなどを含む構造化、半構造化、および非構造化データ形式について学びます。
インタビューのヒント:一般的な質問タイプ
データエンジニアリングのインタビューでさまざまな種類の質問に備えてください:
- 行動の質問:あなたの経験、問題解決スキル、チームワーク能力について議論する準備をします。 STARメソッド(状況、タスク、アクション、結果)を使用して、応答を構成します。
- 技術的な質問:コーディング、SQL、およびデータパイプラインの設計に関する質問を期待してください。
- データのクリーニングと変換:欠損データ、外れ値、および矛盾を処理するための手法を議論する準備をしてください。
- データパイプライン設計:データのボリューム、レイテンシ、エラー処理などの要因を考慮して、エンドツーエンドのデータパイプラインを設計する準備をします。
実際のデータモデリングについては、クラウドインフラストラクチャやその他の独自の情報であなたの経験について話し合う準備をしてください。
データエンジニアリングの利点と課題
長所
- 高い需要と競争力のある給与:データエンジニアは需要が高く、競争力のある給与につながります。
- 知的刺激的な仕事:この役割には、複雑な技術的課題に取り組み、最先端のテクノロジーを扱うことが含まれます。
- インパクトのある貢献:データエンジニアは、企業がデータ駆動型の意思決定を行い、競争力を獲得できるようにする上で重要な役割を果たします。
- キャリア成長の機会:この分野では、データウェアハウジング、データパイプライン、データガバナンスの専門的な役割など、多くのキャリアパスを提供します。
短所
- 技術的な複雑さ:この仕事には、さまざまな技術と概念を深く理解する必要があります。
- 一定の学習:データエンジニアリングの状況は進化しており、継続的な学習とスキル開発が必要です。
- 高圧:データエンジニアは、重要なデータシステムの信頼性とパフォーマンスを担当します。
- コラボレーションの課題:この役割には、多くの場合、多様なチームとの協力が含まれ、強力なコミュニケーションとコラボレーションスキルが必要です。
よくある質問
データエンジニアリングとデータサイエンスの違いは何ですか?
データエンジニアは、データを管理するインフラストラクチャの構築と維持に焦点を当て、データサイエンティストはそのデータを分析して洞察を抽出し、予測モデルを構築します。本質的に、データエンジニアはデータを準備し、データ科学者はそれを使用します。
コンピューターサイエンスの学位は、データエンジニアになるために必要ですか?
コンピューターサイエンスの学位は役立ちますが、必ずしも必要とは限りません。不可欠なのは、プログラミング、データベース、およびデータ構造を強く把握することであり、さまざまな教育パスを通じて取得できます。
人気のあるデータエンジニアリングツールは何ですか?
データエンジニアリングで人気のあるツールには、Apache Airflow、Apache Spark、Hadoop、Kafka、AWS、Azure、GCPなどのクラウドベースのサービスが含まれます。
データエンジニアリングポートフォリオを構築するにはどうすればよいですか?
ポートフォリオの構築は、個人データプロジェクトに取り組み、オープンソースプロジェクトに貢献し、データエンジニアリング競争に参加することで達成できます。
関連する質問
2025年にデータエンジニアに必要なトップスキルは何ですか?
2025年、データエンジニアは、技術的な腕前、ビジネスの洞察力、ソフトスキルのブレンドが必要になります。これが詳細な外観です:
技術的な習熟度:
- クラウドコンピューティング: AWS、Azure、またはGCPの専門知識が重要です。データウェアハウジングのストレージや赤方偏移のためのAWS S3などのサービス、またはAzure Synapse Analytics、Data Lake Storage、およびData Factoryのようなサービスは非常に価値があります。
- SQLおよびNOSQLデータベース: SQLの習熟度は基本的ですが、MongoDBやCassandraなどのNOSQLデータベースの経験は、非構造化データの処理にますます重要になっています。
- プログラミング言語: Pythonは頼りになる言語であり、その後にデータ処理、自動化、スクリプトに不可欠なJavaとScalaが続きます。
- ビッグデータテクノロジー:大規模なデータセットを処理および分析するためのApache SparkやHadoopなどのテクノロジーの習得が不可欠です。
- データパイプラインツール:データワークフローを調整および自動化するためのApache Airflow、Jenkins、Kubeflowなどのツールの習熟度が非常に重要です。
- データモデリング:寸法モデリングやデータの正規化を含むデータモデリング手法を強く理解することは、効率的なデータウェアハウスを設計するために不可欠です。
- ETL/ELTプロセス: ETLおよびELTプロセスの知識は、データの統合と変換に不可欠です。
ビジネスの洞察力:
- データガバナンス:データの品質、セキュリティ、コンプライアンスを含むデータガバナンスの原則を理解することは、データの整合性を確保するために重要です。
- データリテラシー:データの洞察を効果的に理解、解釈、および通信する能力がますます重要になっています。
- ビジネスインテリジェンス(BI)ツール: TableauやPower BIなどのBIツールに精通することは、ダッシュボードの構築やデータの視覚化に有益です。
ソフトスキル:
- コミュニケーション:効果的なコミュニケーションは、利害関係者と協力し、技術情報を伝えるための鍵です。
- 問題解決:データ関連の問題を迅速に特定して解決する能力は、システムの信頼性を維持するために不可欠です。
- チームワーク:機能を超えたチームで働くには、強力なチームワークとコラボレーションスキルが必要です。
- 適応性:データエンジニアリングの絶えず変化する性質は、適応性と新しいテクノロジーを学ぶ意欲を必要とします。
関連記事
 Mo Dao Zu Shi:復活、栽培、漫画分析の探求
悪魔の栽培のグランドマスターとしても知られるモダズズーシーは、中国の神話、ファンタジー、歴史小説の要素を織り上げる愛されているシリーズです。この詳細な探索は、復活、栽培、およびコミックアダップで見つかった微妙なストーリーテリングのテーマに分かれています
契約のAI:法律専門家向けの包括的なガイド
人工知能(AI)はさまざまな業界で大きな影響を与えており、法的部門も例外ではありません。 AIテクノロジーが進歩し続けるにつれて、特に契約管理の領域において、法律専門家がその可能性と制限を把握することが重要です。このガイドdelv
Recram:AIビデオ分析を通じてカスタマーサポートを変換します
今日のペースの速いビジネスの世界では、一流のカスタマーサポートを提供することが重要です。 AIの力を活用してカスタマーサポートビデオを分析するゲームチェンジャーであるRecramを入力してください。問題を解決するだけではありません。それは顧客の感情を理解し、言語の壁を壊すことです
コメント (0)
0/200
Mo Dao Zu Shi:復活、栽培、漫画分析の探求
悪魔の栽培のグランドマスターとしても知られるモダズズーシーは、中国の神話、ファンタジー、歴史小説の要素を織り上げる愛されているシリーズです。この詳細な探索は、復活、栽培、およびコミックアダップで見つかった微妙なストーリーテリングのテーマに分かれています
契約のAI:法律専門家向けの包括的なガイド
人工知能(AI)はさまざまな業界で大きな影響を与えており、法的部門も例外ではありません。 AIテクノロジーが進歩し続けるにつれて、特に契約管理の領域において、法律専門家がその可能性と制限を把握することが重要です。このガイドdelv
Recram:AIビデオ分析を通じてカスタマーサポートを変換します
今日のペースの速いビジネスの世界では、一流のカスタマーサポートを提供することが重要です。 AIの力を活用してカスタマーサポートビデオを分析するゲームチェンジャーであるRecramを入力してください。問題を解決するだけではありません。それは顧客の感情を理解し、言語の壁を壊すことです
コメント (0)
0/200
2025年4月30日
FrankJackson
0
データエンジニアリングインタビューの世界をナビゲートします
データエンジニアリングのインタビューの旅に着手すると、テクノロジーと概念の迷路に足を踏み入れるように感じることができます。圧倒されるのは簡単ですが、適切な焦点を合わせることで、エネルギーを効果的に導くことができます。このガイドはコンパスとして機能し、データエンジニアリングインタビューの準備に構造化されたアプローチを提供します。必須の技術的スキルからプロジェクトのライフサイクルの理解まで、成功するために必要な知識と自信を持って、ベテランのデータ専門家と新人の両方に分野に力を与えるように設計されています。
マスターへのキーポイント
- ETL、データモデリング、データウェアハウジングなどのデータエンジニアリングのコア概念を把握します。
- AWS、Azure、GCPなどのクラウドサービスを使用して、SQL、Python、習熟度などの技術的スキルを磨きます。
- データエンジニアリングプロジェクトを紹介するポートフォリオを構築して、専門知識と経験を実証します。
- 問題解決とシステムの設計に焦点を当てて、典型的なインタビューの質問に備えてください。
- 要件の収集からダッシュボードの作成まで、データエンジニアリングプロジェクトの完全なサイクルを理解してください。
データモデリングとデータ設計に焦点を当てます
ETLとデータパイプラインに熟練することが重要です。これらのスキルは、効果的なデータ管理のバックボーンを形成し、この分野で高く評価されています。
データエンジニアリングの基礎を理解する
データエンジニアリングとは何ですか?
データエンジニアリングは、データ駆動型の組織の背後にある名も込められていないヒーローです。これは、RAWデータをデータサイエンティスト、ビジネスアナリスト、および利害関係者にとって使用可能な形式に変換する芸術と科学です。データエンジニアは、組織が大量のデータを収集、処理、保存、分析できるインフラストラクチャを設計、構築、維持するアーキテクトです。
この分野には、データの摂取や抽出から変換、清掃、保管、倉庫、パイプライン開発、自動化、セキュリティガバナンスまで、さまざまな専門分野が含まれています。データエンジニアは、情報に基づいた意思決定を促進する堅牢でスケーラブルで信頼性の高いデータシステムを作成します。また、データをアクセスしやすくするだけでなく、生データ分析に飛び込んで傾向を明らかにし、短期および長期のビジネス戦略を形成する予測モデルを構築します。データエンジニアリングがなければ、データの広大な海をナビゲートすることはほぼ不可能です。
データエンジニアの役割
データエンジニアは、さまざまな環境で動作し、生データを収集、管理、変換するシステムを構築し、データサイエンティストとビジネスアナリストのための実用的な洞察に変換します。彼らの主な使命は、データをアクセスしやすく、組織がパフォーマンスを評価および強化するために有用にすることです。
彼らの主な責任は次のとおりです。
- データパイプラインの開発と維持。
- データ倉庫とデータ湖の構築と最適化。
- データの品質と完全性を確保します。
- データ処理タスクの自動化。
- データ科学者やビジネスアナリストと協力して、データのニーズを満たします。
- データセキュリティ対策の実装。
- データ関連の問題のトラブルシューティング。
データエンジニアのための主要な技術的スキル
データエンジニアリングで繁栄するために、特定の技術的スキルは交渉不可能です。
- SQL:リレーショナルデータベースのデータをクエリ、操作、および管理するための礎石。
- Python:データ処理、自動化、スクリプトに広範囲に使用される多目的言語。
- クラウドコンピューティング:データストレージ、処理、分析のためのAWS、Azure、GCPなどのプラットフォームを使用する習熟度。
- ETLツール:データパイプラインを調整するためのApache Airflowなどのツールに精通しています。
- Spark:大規模なデータセットを処理するための強力なフレームワーク。
データエンジニアリングプロジェクトのライフサイクルのナビゲート
データエンジニアリングプロジェクトの手順
データエンジニアリングプロジェクトのさまざまな段階を理解することは、成功に不可欠です。これが典型的なプロジェクトのライフサイクルです:
- 利害関係者とのプロジェクトの範囲:プロジェクトの目標と要件を定義することから始めます。成功した結果を達成するために、ビジネスニーズと技術的制約を理解することが重要です。
- データの収集:データベース、API、データストリームなど、内部および外部の両方のさまざまなソースからデータを収集します。
- データを調査して評価する:データを分析して、その構造、品質、および潜在的な問題を理解します。これにより、クリーニングと変換が必要なものを特定できます。
- データモデルを定義します。データモデルを設計して、データを構成して効率的に保存します。これには、データ型の選択、関係の定義、クエリパフォーマンスの最適化が含まれます。
- 実行抽出変換負荷(ETL): ETLプロセスを実装してデータを抽出し、使用可能な形式に変換し、ターゲットデータウェアハウスまたはデータレイクにロードします。
- データパイプラインと実行するスケジュールを作成します。自動データパイプラインを開発して、スケジュールタスク、データフローの監視、取り扱いエラーなどの定期的なデータ処理と更新を確保します。
- データをダッシュボードに作成します。ダッシュボードと視覚化を作成して、処理されたデータを理解できる形式で提示し、利害関係者が洞察を得て情報に基づいた決定を下すことができます。データアナリストはしばしばこの段階を処理することに注意してください。
データエンジニアリングインタビューの準備
データエンジニアリングインタビュー構造の理解
データエンジニアリングのインタビューは通常、ソフトウェアエンジニアリングのインタビューに似た構造に従います。通常、3〜4ラウンドで構成されています。
- テクニカルラウンド:これらは、SQLやPythonなどのコア技術スキルに焦点を当て、コーディングの課題、問題解決の質問、データ構造とアルゴリズムに関する議論を備えています。
- データモデリングと設計:これにより、データモデルを設計し、データウェアハウジングの概念を理解し、効率的なデータパイプラインを作成する能力が評価されます。
- データパイプライン:これにより、データパイプラインの設計と維持のスキルが評価されます。
技術的なインタビューの準備:SQLとPython
技術的なインタビューをACEするには、SQLとPythonに焦点を当てます。
SQL:
- 基本をマスターする: SQL構文、データ型、および一般的なクエリパターンを確認します。
- 複雑なクエリを練習する:クエリの最適化とパフォーマンスに注目して、複数のテーブルからのデータをフィルタリング、集約、および結合するためのクエリの作成に取り組みます。
- データウェアハウジングの概念を理解する:スタースキーマ、スノーフレークスキーマ、およびその他のデータウェアハウジングの概念に慣れる。
Python:
- データ操作ライブラリ:データの操作、クリーニング、分析のために、パンダやNumpyなどのライブラリに精通しています。
- スクリプトと自動化:データの摂取、変換、読み込みなどの一般的なデータエンジニアリングタスクを自動化するためのスクリプトを作成する練習。
- データ構造とアルゴリズム:基本的なデータ構造とアルゴリズムに関する知識を更新して、効率的なデータ処理を確保します。
マスタリングデータモデリング
データのモデリングと設計については、次を検討してください。
- 寸法モデリング:事実、寸法、測定の識別を含む、次元モデリングの原則を理解します。
- データの正規化:データの正規化手法について学び、冗長性を減らし、データの整合性を向上させます。
- データウェアハウジングの概念:スタースキーマ、スノーフレークスキーマ、データボールトモデリングなどの概念を確認します。
- 実際のシナリオ:データボリューム、クエリパターン、ビジネス要件などの要因を考慮して、実際のシナリオのデータモデルの設計を練習します。
- 一般的なデータ形式の理解: CSV、JSON、XMLなどを含む構造化、半構造化、および非構造化データ形式について学びます。
インタビューのヒント:一般的な質問タイプ
データエンジニアリングのインタビューでさまざまな種類の質問に備えてください:
- 行動の質問:あなたの経験、問題解決スキル、チームワーク能力について議論する準備をします。 STARメソッド(状況、タスク、アクション、結果)を使用して、応答を構成します。
- 技術的な質問:コーディング、SQL、およびデータパイプラインの設計に関する質問を期待してください。
- データのクリーニングと変換:欠損データ、外れ値、および矛盾を処理するための手法を議論する準備をしてください。
- データパイプライン設計:データのボリューム、レイテンシ、エラー処理などの要因を考慮して、エンドツーエンドのデータパイプラインを設計する準備をします。
実際のデータモデリングについては、クラウドインフラストラクチャやその他の独自の情報であなたの経験について話し合う準備をしてください。
データエンジニアリングの利点と課題
長所
- 高い需要と競争力のある給与:データエンジニアは需要が高く、競争力のある給与につながります。
- 知的刺激的な仕事:この役割には、複雑な技術的課題に取り組み、最先端のテクノロジーを扱うことが含まれます。
- インパクトのある貢献:データエンジニアは、企業がデータ駆動型の意思決定を行い、競争力を獲得できるようにする上で重要な役割を果たします。
- キャリア成長の機会:この分野では、データウェアハウジング、データパイプライン、データガバナンスの専門的な役割など、多くのキャリアパスを提供します。
短所
- 技術的な複雑さ:この仕事には、さまざまな技術と概念を深く理解する必要があります。
- 一定の学習:データエンジニアリングの状況は進化しており、継続的な学習とスキル開発が必要です。
- 高圧:データエンジニアは、重要なデータシステムの信頼性とパフォーマンスを担当します。
- コラボレーションの課題:この役割には、多くの場合、多様なチームとの協力が含まれ、強力なコミュニケーションとコラボレーションスキルが必要です。
よくある質問
データエンジニアリングとデータサイエンスの違いは何ですか?
データエンジニアは、データを管理するインフラストラクチャの構築と維持に焦点を当て、データサイエンティストはそのデータを分析して洞察を抽出し、予測モデルを構築します。本質的に、データエンジニアはデータを準備し、データ科学者はそれを使用します。
コンピューターサイエンスの学位は、データエンジニアになるために必要ですか?
コンピューターサイエンスの学位は役立ちますが、必ずしも必要とは限りません。不可欠なのは、プログラミング、データベース、およびデータ構造を強く把握することであり、さまざまな教育パスを通じて取得できます。
人気のあるデータエンジニアリングツールは何ですか?
データエンジニアリングで人気のあるツールには、Apache Airflow、Apache Spark、Hadoop、Kafka、AWS、Azure、GCPなどのクラウドベースのサービスが含まれます。
データエンジニアリングポートフォリオを構築するにはどうすればよいですか?
ポートフォリオの構築は、個人データプロジェクトに取り組み、オープンソースプロジェクトに貢献し、データエンジニアリング競争に参加することで達成できます。
関連する質問
2025年にデータエンジニアに必要なトップスキルは何ですか?
2025年、データエンジニアは、技術的な腕前、ビジネスの洞察力、ソフトスキルのブレンドが必要になります。これが詳細な外観です:
技術的な習熟度:
- クラウドコンピューティング: AWS、Azure、またはGCPの専門知識が重要です。データウェアハウジングのストレージや赤方偏移のためのAWS S3などのサービス、またはAzure Synapse Analytics、Data Lake Storage、およびData Factoryのようなサービスは非常に価値があります。
- SQLおよびNOSQLデータベース: SQLの習熟度は基本的ですが、MongoDBやCassandraなどのNOSQLデータベースの経験は、非構造化データの処理にますます重要になっています。
- プログラミング言語: Pythonは頼りになる言語であり、その後にデータ処理、自動化、スクリプトに不可欠なJavaとScalaが続きます。
- ビッグデータテクノロジー:大規模なデータセットを処理および分析するためのApache SparkやHadoopなどのテクノロジーの習得が不可欠です。
- データパイプラインツール:データワークフローを調整および自動化するためのApache Airflow、Jenkins、Kubeflowなどのツールの習熟度が非常に重要です。
- データモデリング:寸法モデリングやデータの正規化を含むデータモデリング手法を強く理解することは、効率的なデータウェアハウスを設計するために不可欠です。
- ETL/ELTプロセス: ETLおよびELTプロセスの知識は、データの統合と変換に不可欠です。
ビジネスの洞察力:
- データガバナンス:データの品質、セキュリティ、コンプライアンスを含むデータガバナンスの原則を理解することは、データの整合性を確保するために重要です。
- データリテラシー:データの洞察を効果的に理解、解釈、および通信する能力がますます重要になっています。
- ビジネスインテリジェンス(BI)ツール: TableauやPower BIなどのBIツールに精通することは、ダッシュボードの構築やデータの視覚化に有益です。
ソフトスキル:
- コミュニケーション:効果的なコミュニケーションは、利害関係者と協力し、技術情報を伝えるための鍵です。
- 問題解決:データ関連の問題を迅速に特定して解決する能力は、システムの信頼性を維持するために不可欠です。
- チームワーク:機能を超えたチームで働くには、強力なチームワークとコラボレーションスキルが必要です。
- 適応性:データエンジニアリングの絶えず変化する性質は、適応性と新しいテクノロジーを学ぶ意欲を必要とします。










 Mo Dao Zu Shi:復活、栽培、漫画分析の探求
悪魔の栽培のグランドマスターとしても知られるモダズズーシーは、中国の神話、ファンタジー、歴史小説の要素を織り上げる愛されているシリーズです。この詳細な探索は、復活、栽培、およびコミックアダップで見つかった微妙なストーリーテリングのテーマに分かれています
Mo Dao Zu Shi:復活、栽培、漫画分析の探求
悪魔の栽培のグランドマスターとしても知られるモダズズーシーは、中国の神話、ファンタジー、歴史小説の要素を織り上げる愛されているシリーズです。この詳細な探索は、復活、栽培、およびコミックアダップで見つかった微妙なストーリーテリングのテーマに分かれています
 契約のAI:法律専門家向けの包括的なガイド
人工知能(AI)はさまざまな業界で大きな影響を与えており、法的部門も例外ではありません。 AIテクノロジーが進歩し続けるにつれて、特に契約管理の領域において、法律専門家がその可能性と制限を把握することが重要です。このガイドdelv
契約のAI:法律専門家向けの包括的なガイド
人工知能(AI)はさまざまな業界で大きな影響を与えており、法的部門も例外ではありません。 AIテクノロジーが進歩し続けるにつれて、特に契約管理の領域において、法律専門家がその可能性と制限を把握することが重要です。このガイドdelv
 Recram:AIビデオ分析を通じてカスタマーサポートを変換します
今日のペースの速いビジネスの世界では、一流のカスタマーサポートを提供することが重要です。 AIの力を活用してカスタマーサポートビデオを分析するゲームチェンジャーであるRecramを入力してください。問題を解決するだけではありません。それは顧客の感情を理解し、言語の壁を壊すことです
Recram:AIビデオ分析を通じてカスタマーサポートを変換します
今日のペースの速いビジネスの世界では、一流のカスタマーサポートを提供することが重要です。 AIの力を活用してカスタマーサポートビデオを分析するゲームチェンジャーであるRecramを入力してください。問題を解決するだけではありません。それは顧客の感情を理解し、言語の壁を壊すことです