




स्क्रैपिग्राफाई के साथ वेब स्क्रैपिंग क्रांति: एक व्यापक गाइड
आज की डेटा-संचालित दुनिया में, वेबसाइटों से जानकारी निकालना विभिन्न उद्देश्यों जैसे कि बिजनेस इंटेलिजेंस, मार्केट रिसर्च और प्रतिस्पर्धी विश्लेषण के लिए आवश्यक है। वेब स्क्रैपिंग, वेबसाइटों से डेटा खींचने की स्वचालित प्रक्रिया, एक महत्वपूर्ण उपकरण बन गई है। हालांकि, पारंपरिक वेब स्क्रैपिंग विधियों में अक्सर वेबसाइट संरचनाओं में परिवर्तन के कारण जटिल कोडिंग और नियमित अपडेट की आवश्यकता होती है। यह वह जगह है जहां स्क्रैपिफ़ैफाई खेल में आता है-एक अभिनव ओपन-सोर्स पायथन लाइब्रेरी जिसका उद्देश्य बड़े भाषा मॉडल (एलएलएम) की क्षमताओं का उपयोग करके वेब स्क्रैपिंग को बदलना है।
प्रमुख बिंदु
- Scrapegraphai एक ओपन-सोर्स पायथन लाइब्रेरी है जो वेब स्क्रैपिंग को सुव्यवस्थित करती है।
- यह अधिक प्रभावी ढंग से वेबसाइटों से डेटा निकालने के लिए बड़े भाषा मॉडल (एलएलएम) का उपयोग करता है।
- उपकरण वेबसाइटों में परिवर्तन के लिए अनुकूल होकर चल रहे डेवलपर हस्तक्षेप की आवश्यकता को कम करता है।
- यह GPT, GEMINI, GROQ, AZURE और HUGHING FACE सहित LLM की एक श्रृंखला का समर्थन करता है।
- PIP के साथ स्थापना सरल है, और एक आभासी वातावरण का उपयोग करने की सिफारिश की जाती है।
- Scrapegraphai उपयोगकर्ताओं को डेटा को परिमार्जन करने और पारंपरिक तरीकों की तुलना में कम कोड के साथ विशिष्ट जानकारी निकालने में सक्षम बनाता है।
- ओलामा के माध्यम से स्थानीय होस्टिंग एक निजी और कुशल स्क्रैपिंग वातावरण प्रदान करता है।
वेब स्क्रैपिंग और इसके विकास को समझना
पारंपरिक वेब स्क्रैपिंग युग
1990 के दशक के अंत और 2000 के दशक की शुरुआत से वेब स्क्रैपिंग आसपास रहा है, जब इंटरनेट विकसित होने लगा। इसके बाद, HTML पृष्ठों से डेटा निकालने के लिए गहन कोडिंग को शामिल किया गया। कस्टम कोडिंग ऑनलाइन पाए गए विभिन्न HTML संरचनाओं के माध्यम से नेविगेट करने के लिए महत्वपूर्ण था। नियमित अभिव्यक्तियों का उपयोग अक्सर HTML डेटा को पार्स करने के लिए किया जाता था, जो थकाऊ और जटिल दोनों था। इस विधि का उपयोग मुख्य रूप से ऑफ़लाइन एप्लिकेशन में किया गया था, जिसमें ऑनलाइन जाने के लिए मैनुअल अपडेट की आवश्यकता थी। पूरी प्रक्रिया ने काफी समय और विशेषज्ञता की मांग की, जिससे यह मुख्य रूप से उन्नत कोडिंग कौशल वाले लोगों के लिए सुलभ हो गया।
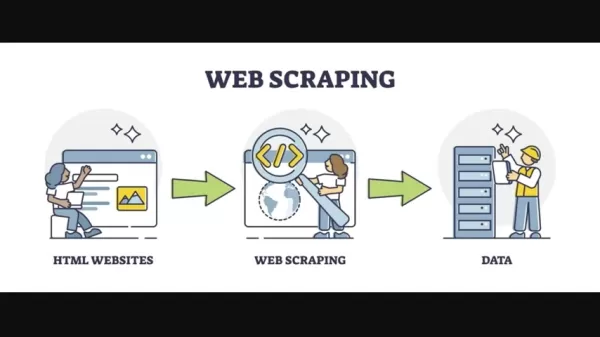
समय के साथ, कई उपकरण और तकनीकें वेब स्क्रैपिंग को सरल बनाने के लिए उभरी हैं। पायथन, पुस्तकालयों के अपने मजबूत पारिस्थितिकी तंत्र के साथ, इस कार्य के लिए एक पसंदीदा भाषा बन गई है। सुंदर सूप और स्क्रैपी जैसे पुस्तकालयों ने अधिक संरचित डेटा निष्कर्षण विधियों की पेशकश की है, फिर भी वेबसाइट संरचनाओं को बदलने के लिए अनुकूल होने की चुनौती बनी रहती है।
परिदृश्य अब बड़ी भाषा मॉडल (एलएलएम) की शुरूआत के साथ महत्वपूर्ण रूप से बदल गया है जो पारंपरिक वेब स्क्रैपिंग में बहुत अधिक जटिलता को स्वचालित करता है। आइए एक उपकरण का पता लगाएं जिसने इसे आसान बना दिया है।
परिचय Scrapegraphai: वेब स्क्रैपिंग पुन: प्राप्त किया
Scrapegraphai एक शक्तिशाली समाधान के रूप में उभरता है, AI- चालित बड़े भाषा मॉडल का उपयोग करके वेब स्क्रैपिंग प्रक्रिया को स्वचालित और सरल बनाने के लिए। यह एक ओपन-सोर्स पायथन लाइब्रेरी है जिसे हम वेब स्क्रैपिंग के लिए क्रांति करने के लिए डिज़ाइन किया गया है।
पारंपरिक वेब स्क्रैपिंग टूल्स के विपरीत, जो अक्सर निश्चित पैटर्न या मैनुअल समायोजन पर निर्भर करते हैं, स्क्रैपिग्राफाई वेबसाइट संरचनाओं में परिवर्तन के लिए अनुकूलित करता है, निरंतर डेवलपर हस्तक्षेप की आवश्यकता को कम करता है। यह विभिन्न स्रोतों से डेटा स्क्रैपिंग को स्वचालित करने के लिए बड़ी भाषा मॉडल (एलएलएम) और मॉड्यूलर ग्राफ-आधारित पाइपलाइनों को एकीकृत करके बाहर खड़ा है।
यह पुस्तकालय पारंपरिक स्क्रैपिंग टूल की तुलना में अधिक लचीला और कम रखरखाव समाधान प्रदान करता है। यह उपयोगकर्ताओं को व्यापक कोडिंग के बिना या जटिल नियमित अभिव्यक्तियों से निपटने के बिना HTML मार्कअप से विशिष्ट जानकारी को आसानी से निकालने की अनुमति देता है। आपको बस यह निर्दिष्ट करने की आवश्यकता है कि आपको किन जानकारी की आवश्यकता है, और स्क्रैपिग्राफाई बाकी का ख्याल रखता है। यह जीपीटी, मिथुन, ग्रोक और एज़्योर सहित कई एलएलएम का समर्थन करता है, साथ ही स्थानीय मॉडल भी जो ओलामा का उपयोग करके आपकी मशीन पर चल सकते हैं।
प्रमुख घटक और वास्तुकला
Scrapegraphai विभिन्न वर्गों में सभी HTML नोड्स को संभालने के लिए अलग -अलग पार्सिंग नोड्स को नियुक्त करता है। यह HTML पृष्ठ के भीतर विशिष्ट क्षेत्रों को इंगित करने के लिए खोज नोड्स का उपयोग करता है। होशियार ग्राफ बिल्डर HTML में सभी मार्कअप भाषा का प्रबंधन करता है।
यहाँ इसकी वास्तुकला का एक त्वरित अवलोकन है:
- नोड प्रकार: Scrapegraphai HTML के विभिन्न वर्गों को संसाधित करने के लिए विभिन्न पार्सिंग नोड्स का उपयोग करता है, जिसमें सशर्त नोड्स, लाने वाले नोड्स, पार्स नोड्स, रैग नोड्स और खोज नोड्स शामिल हैं। ये नोड्स सशर्त पार्सिंग, डेटा लाने, सामग्री पार्सिंग, और HTML संरचना के भीतर प्रासंगिक जानकारी की खोज करने में सक्षम बनाते हैं।
- ग्राफ बिल्डर: Scrapegraphai का स्मार्ट ग्राफ बिल्डर सभी HTML मार्कअप भाषा को संभालकर वांछित जानकारी के निष्कर्षण को सरल बनाता है।
- बड़े भाषा मॉडल (LLMS): स्क्रैपिफ़ैफाई कुशल डेटा निष्कर्षण के लिए उनकी प्राकृतिक भाषा प्रसंस्करण क्षमताओं का लाभ उठाते हुए, मिथुन और ओपनई जैसे एलएलएम का समर्थन करता है।
लाइब्रेरी की मैन्युअल रूप से रेखांकन को परिभाषित करने या एलएलएम को संकेतों के आधार पर ग्राफ़ बनाने की क्षमता लचीलेपन की एक परत जोड़ती है जो विभिन्न उपयोगकर्ता की आवश्यकताओं और परियोजना की आवश्यकताओं को पूरा करती है। यह उच्च-स्तरीय आर्किटेक्चर न्यूनतम कोडिंग के साथ जटिल स्क्रैपिंग पाइपलाइनों को आसान बनाता है।
Scrapegraphai की स्थापना: स्थापना और कॉन्फ़िगरेशन
आवश्यक शर्तें और स्थापना चरण
Scrapegraphai में गोता लगाने से पहले, सुनिश्चित करें कि आपका सिस्टम आवश्यक पूर्वापेक्षाओं को पूरा करता है।
यहाँ सब कुछ सेट करने के लिए एक विस्तृत मार्गदर्शिका है:
- पायथन संस्करण: Scrapegraphai को पायथन 3.9 या उच्चतर की आवश्यकता होती है, लेकिन 3.12 से अधिक नहीं। पायथन 3.10 आमतौर पर पर्याप्त है।
- PIP: सुनिश्चित करें कि आपके पास PIP, PYTHON पैकेज इंस्टॉलर का नवीनतम संस्करण है। आप इसे कमांड
pip install --upgrade pip का उपयोग करके अपडेट कर सकते हैं। - Ollama (वैकल्पिक): यदि आप स्थानीय बड़े भाषा मॉडल चलाने की योजना बनाते हैं, तो आपको Ollama स्थापित करने की आवश्यकता होगी। विस्तृत स्थापना और सेटअप निर्देशों के लिए प्रलेखन की जाँच करें।
एक बार जब आप इन पूर्वापेक्षाओं की पुष्टि कर लेते हैं, तो स्क्रैपिग्राफाई स्थापित करना सीधा होता है:
pip install scrapegraphai
अपने सिस्टम में अन्य पायथन पैकेजों के साथ संघर्ष से बचने के लिए वर्चुअल वातावरण (CONDA, VENV, आदि) में स्क्रैपिग्राफाई स्थापित करने की अत्यधिक अनुशंसा की जाती है।
विंडोज उपयोगकर्ताओं के लिए, आप अतिरिक्त पुस्तकालयों को स्थापित करने के लिए लिनक्स (डब्ल्यूएसएल) के लिए विंडोज सबसिस्टम का उपयोग कर सकते हैं।
सही बड़ी भाषा मॉडल चुनना
Scrapegraphai का उपयोग करते समय प्रमुख निर्णयों में से एक आपकी वेब स्क्रैपिंग आवश्यकताओं के लिए उपयुक्त बड़े भाषा मॉडल (LLM) का चयन कर रहा है। Scrapegraphai विभिन्न LLMs का समर्थन करता है, प्रत्येक अपनी ताकत और क्षमताओं के साथ:
- Openai के GPT मॉडल: GPT-3.5 टर्बो और GPT-4 सामान्य-उद्देश्य वाले वेब स्क्रैपिंग कार्यों के लिए शक्तिशाली विकल्प हैं। ये मॉडल विविध वेबसाइट संरचनाओं से जानकारी को प्रभावी ढंग से समझ और निकाल सकते हैं।
- मिथुन: उन्नत प्राकृतिक भाषा प्रसंस्करण क्षमताओं की पेशकश करता है, जिससे यह जटिल डेटा निष्कर्षण कार्यों के लिए उपयुक्त है।
- Groq: अपनी गति और दक्षता के लिए जाना जाता है, Groq एक उत्कृष्ट विकल्प है जब आपको जल्दी से वेब डेटा के बड़े संस्करणों को संसाधित करने की आवश्यकता होती है।
- Azure: उद्यम-ग्रेड सुरक्षा और स्केलेबिलिटी प्रदान करता है, जो कड़े डेटा गोपनीयता आवश्यकताओं के साथ संगठनों के लिए आदर्श बनाता है।
- हगिंग फेस: ओपन-सोर्स एलएलएम की एक विस्तृत श्रृंखला प्रदान करता है, जिससे आप विशिष्ट वेब स्क्रैपिंग कार्यों के लिए अनुकूलित और फाइन-ट्यून मॉडल की अनुमति देते हैं।
डेटा गोपनीयता या लागत के बारे में चिंतित लोगों के लिए, Scrapegraphai आपको ओलमा का उपयोग करके स्थानीय LLM चलाने की अनुमति देता है। यह सेटअप आपको बाहरी सेवाओं पर भरोसा किए बिना एलएलएम की शक्ति का लाभ उठाने में सक्षम बनाता है।
व्यावहारिक उदाहरण: स्क्रैपिंग के साथ स्क्रैपिंग
Openai मॉडल स्थापित करना
OpenAI मॉडल को जोड़ने और उपयोग करने के लिए, आपको आवश्यक पुस्तकालयों को आयात करने और अपनी API कुंजी सेट करने की आवश्यकता होगी। यहाँ एक उदाहरण है कि कैसे Openai के GPT मॉडल के साथ Scrapegraphai को कॉन्फ़िगर किया जाए:
import os from dotenv import load_dotenv from scrapegraphai.graphs import SmartScraperGraph from scrapegraphai.utils import prettify_exec_info load_dotenv ()
openai_key = os.getenv ("Openai_apikey") graph_config = {
"एलएलएम": {
"api_key": openai_key,
"मॉडल": "GPT-3.5-टर्बो",
}
}
प्रॉम्प्ट, सोर्स और कॉन्फ़िगरेशन के साथ SmartScraperGraph को इनिशियलाइज़ करें
smart_scraper_graph = smartscrapergraph (
शीघ्र = "मुझे उनके शीर्षक और विवरण के साथ सभी परियोजनाओं को सूचीबद्ध करें।",
स्रोत = " https://perinim.github.io/projects/ ",
config = graph_config
)
SmartScraperGraph चलाएं और परिणाम स्टोर करें
परिणाम = smart_scraper_graph.run ()
प्रिंट (परिणाम)
इस उदाहरण में, graph_config शब्दकोश को API कुंजी और उस मॉडल को निर्दिष्ट करने के लिए परिभाषित किया गया है जिसे आप उपयोग करना चाहते हैं (GPT-3.5-टर्बो)। फिर, SmartScraperGraph को एक संकेत, स्रोत URL और कॉन्फ़िगरेशन के साथ आरंभीकृत किया जाता है। अंत में, run() विधि को स्क्रैपिंग प्रक्रिया को निष्पादित करने और परिणामों को प्रिंट करने के लिए कहा जाता है।
स्थानीय मॉडल को कॉन्फ़िगर करना
स्थानीय मॉडलों के लिए, स्क्रैपिग्राफाई को थोड़ा और कॉन्फ़िगरेशन की आवश्यकता होती है, लेकिन यह अभी भी सीधा है:
from scrapegraphai.graphs import SmartScraperGraph from scrapegraphai.utils import prettify_exec_info graph_config = {
"एलएलएम": {
"मॉडल": "ओलामा/llama3",
"तापमान": 0.5,
"प्रारूप": "JSON",
"model_tokens": 3500,
"base_url": " http: // localhost: 11434 ",
},
"एम्बेडिंग": {
"मॉडल": "ओलामा/नॉमिक-एम्बेड-टेक्स्ट",
"base_url": " http: // localhost: 11434 ",
},
"वर्बोज़": सच,
} प्रॉम्प्ट, सोर्स और कॉन्फ़िगरेशन के साथ SmartScraperGraph को इनिशियलाइज़ करें
smart_scraper_graph = smartscrapergraph (
शीघ्र = "मुझे उनके शीर्षक और विवरण के साथ सभी परियोजनाओं को सूचीबद्ध करें।",
स्रोत = " https://perinim.github.io/projects/ ",
config = graph_config
)
SmartScraperGraph चलाएं और परिणाम स्टोर करें
परिणाम = smart_scraper_graph.run ()
प्रिंट (परिणाम)
इस कॉन्फ़िगरेशन में एलएलएम और एम्बेडिंग दोनों के लिए मॉडल (ओलामा/llama3), तापमान, प्रारूप और आधार URL निर्दिष्ट करना शामिल है। आप अपनी विशिष्ट वेब स्क्रैपिंग आवश्यकताओं को पूरा करने के लिए आवश्यक मॉडल और अन्य मापदंडों को समायोजित कर सकते हैं।
लागत और लाइसेंसिंग को समझना
ओपन सोर्स नेचर
चूंकि Scrapegraphai एक ओपन-सोर्स लाइब्रेरी है, इसलिए यह उपयोग करने के लिए स्वतंत्र है। आप लाइसेंस की शर्तों के अनुसार इसे डाउनलोड, संशोधित और वितरित कर सकते हैं। यह खुली प्रकृति सामुदायिक योगदान को प्रोत्साहित करती है और यह सुनिश्चित करती है कि पुस्तकालय व्यापक दर्शकों के लिए सुलभ रहे।
हालांकि, ध्यान रखें कि कुछ बड़े भाषा मॉडल का उपयोग करना, जैसे कि Openai के लोग, लागत को बढ़ा सकते हैं। Openai, Bardeen AI, और अन्य एक टोकन-आधारित मूल्य निर्धारण मॉडल पर काम करते हैं। जब आप एलएलएम को एक प्रॉम्प्ट भेजते हैं, तो यह अनुरोध को संसाधित करता है और एक प्रतिक्रिया उत्पन्न करता है। लागत संकेत और प्रतिक्रिया में उपयोग किए जाने वाले टोकन की संख्या पर निर्भर करती है। इसलिए, अप्रत्याशित आरोपों से बचने के लिए अपने उपयोग की निगरानी करना और अपनी एपीआई कुंजियों का प्रबंधन करना आवश्यक है। यह Openai के लिए अपनी खुद की API कुंजी रखने में मदद करता है।
लाभ और नुकसान के नुकसान
पेशेवरों
- LLMS का उपयोग करके सरलीकृत वेब स्क्रैपिंग प्रक्रिया।
- निरंतर रखरखाव और समायोजन की आवश्यकता कम।
- विभिन्न बड़े भाषा मॉडल के लिए समर्थन।
- बढ़ी हुई गोपनीयता और सुरक्षा के लिए स्थानीय एलएलएम होस्टिंग के लिए विकल्प।
- ग्राफ-आधारित पाइपलाइनों के माध्यम से लचीलापन और अनुकूलन में वृद्धि।
दोष
- बाहरी एलएलएम सेवाओं का उपयोग करने से जुड़ी संभावित लागत।
- चुने हुए एलएलएम की सटीकता और क्षमताओं पर निर्भरता।
- पायथन और आभासी वातावरण के साथ कुछ परिचित होने की आवश्यकता है।
- अपेक्षाकृत नई लाइब्रेरी, इसलिए सामुदायिक समर्थन और प्रलेखन अभी भी बढ़ सकता है।
प्रमुख विशेषताऐं
एलएलएम एकीकरण
Scrapegraphai बुद्धिमान वेब स्क्रैपिंग के लिए बड़े भाषा मॉडल (LLM) का लाभ उठाता है। यह स्वचालित रूप से वेबसाइट संरचनाओं में परिवर्तन का पता लगा सकता है और अनुकूलन कर सकता है, निरंतर मैनुअल समायोजन की आवश्यकता को कम कर सकता है। यह सुविधा अकेले महत्वपूर्ण विकास और रखरखाव समय बचाती है।
ग्राफ़-आधारित पाइपलाइन
लाइब्रेरी मॉड्यूलर ग्राफ-आधारित पाइपलाइनों को नियुक्त करती है जो कुशल और संरचित डेटा निष्कर्षण के लिए अनुमति देती है। इन पाइपलाइनों को विभिन्न वेब स्क्रैपिंग परिदृश्यों को फिट करने के लिए अनुकूलित किया जा सकता है, जो निष्कर्षण प्रक्रिया पर लचीलापन और नियंत्रण प्रदान करता है।
कई एलएलएम के लिए समर्थन
Scrapegraphai विभिन्न प्रकार के LLMs का समर्थन करता है, जिसमें GPT, GEMINI, GROQ, AZURE और HUGHING FACE शामिल हैं। यह समर्थन उपयोगकर्ताओं को उस मॉडल का चयन करने में सक्षम बनाता है जो उनकी आवश्यकताओं के अनुरूप है, चाहे वह सामान्य-उद्देश्य स्क्रैपिंग या अधिक विशेष कार्यों के लिए हो।
स्थानीय एलएलएम होस्टिंग
Ollama एकीकरण के साथ, Scrapegraphai आपको स्थानीय रूप से बड़ी भाषा मॉडल की मेजबानी करने की अनुमति देता है। यह बाहरी सेवाओं पर निर्भरता के बिना, एक सुरक्षित और निजी वेब स्क्रैपिंग वातावरण प्रदान करता है।
स्क्रैपिग्राफाई के लिए विविध उपयोग के मामले
ई-कॉमर्स बिजनेस इंटेलिजेंस
Scrapegraphai का उपयोग उत्पाद की कीमतों की निगरानी करने, प्रतियोगी प्रसाद को ट्रैक करने और ग्राहक समीक्षाओं को इकट्ठा करने के लिए किया जा सकता है, जो प्रतिस्पर्धी बढ़त के साथ ई-कॉमर्स व्यवसाय प्रदान करता है। इस डेटा के संग्रह को स्वचालित करके, व्यवसाय अपनी रणनीतियों को अनुकूलित करने के लिए डेटा-संचालित निर्णय ले सकते हैं।
निवेशक अनुसंधान
निवेशक वित्तीय डेटा निकालने, कंपनी की खबरों का विश्लेषण करने और बाजार के रुझानों की निगरानी करने के लिए स्क्रैपिग्राफाई का लाभ उठा सकते हैं। यह डेटा निवेशकों को सूचित निवेश निर्णय लेने और प्रभावी रूप से जोखिमों का प्रबंधन करने के लिए आवश्यक अंतर्दृष्टि प्रदान करता है।
विपणन और प्रतिस्पर्धी विश्लेषण
मार्केटिंग टीमें ग्राहक प्रतिक्रिया इकट्ठा करने, सोशल मीडिया ट्रेंड का विश्लेषण करने और प्रतियोगी रणनीतियों को ट्रैक करने के लिए स्क्रैपिफ़ैफाई का उपयोग कर सकती हैं। ये अंतर्दृष्टि विपणक को लक्षित अभियान बनाने, उनकी सामग्री का अनुकूलन करने और ग्राहक जुड़ाव में सुधार करने में सक्षम बनाती हैं।
अक्सर पूछे जाने वाले प्रश्नों
Scrapegraphai क्या है?
Scrapegraphai एक ओपन-सोर्स पायथन लाइब्रेरी है जिसे बड़े भाषा मॉडल (LLMS) का उपयोग करके वेब स्क्रैपिंग को सरल और स्वचालित करने के लिए डिज़ाइन किया गया है। यह उपयोगकर्ताओं को अधिक कुशलता से और कम मैनुअल कोडिंग के साथ वेबसाइटों से डेटा निकालने की अनुमति देता है।
Scrapegraphai स्थापित करने के लिए क्या आवश्यक शर्तें हैं?
पूर्वापेक्षाओं में पायथन 3.9 या उच्चतर (लेकिन 3.12 से अधिक नहीं), पीआईपी, और वैकल्पिक रूप से, स्थानीय एलएलएम चलाने के लिए ओलामा शामिल हैं।
मैं Scrapegraphai कैसे स्थापित करूं?
आप कमांड PIP के साथ PIP का उपयोग करके pip install scrapegraphai स्थापित कर सकते हैं। इसे आभासी वातावरण में स्थापित करने की सिफारिश की जाती है।
कौन से बड़े भाषा मॉडल स्क्रैपिग्राफाई का समर्थन करते हैं?
Scrapegraphai GPT, GEMINI, Groq, Azure, Hugging Face, और स्थानीय मॉडल Ollama का उपयोग करते हुए चलते हैं।
मैं Openai के GPT मॉडल का उपयोग करने के लिए Scrapegraphai को कैसे कॉन्फ़िगर करूं?
आपको graph_config Dictionary में अपनी OpenAI API कुंजी सेट करने की आवश्यकता है और उस मॉडल को निर्दिष्ट करें जिसे आप उपयोग करना चाहते हैं।
क्या मैं मुफ्त में Scrapegraphai का उपयोग कर सकता हूं?
हां, Scrapegraphai एक ओपन-सोर्स लाइब्रेरी है और उपयोग करने के लिए स्वतंत्र है। हालांकि, OpenAI के लोगों की तरह कुछ LLM का उपयोग करना टोकन उपयोग के आधार पर लागत को बढ़ा सकता है।
संबंधित प्रश्न
स्क्रैपिफ़ैफाई पारंपरिक वेब स्क्रैपिंग टूल की तुलना कैसे करता है?
Scrapegraphai वेबसाइट संरचना परिवर्तनों के कारण निरंतर मैनुअल समायोजन की आवश्यकता को कम करते हुए, AI- चालित बड़े भाषा मॉडल का लाभ उठाता है। पारंपरिक उपकरणों को अक्सर अधिक कोडिंग और रखरखाव की आवश्यकता होती है। Scrapegraphai वेबसाइट संरचनाओं को बदलने के लिए, निरंतर डेवलपर हस्तक्षेप की आवश्यकता को कम करता है। यह लचीलापन यह सुनिश्चित करता है कि वेबसाइट लेआउट बदलने पर भी स्क्रैपर कार्यात्मक बने रहते हैं। Scrapegraphai के साथ, आपको केवल यह निर्दिष्ट करने की आवश्यकता है कि आपको किस जानकारी की आवश्यकता है, और लाइब्रेरी बाकी को संभालती है। पारंपरिक वेब स्क्रैपिंग विधि 1990 के दशक के उत्तरार्ध और 2000 के दशक की शुरुआत से है, जब इंटरनेट ने आकार लेना शुरू किया था। दिन में वापस, वेब स्क्रैपिंग में HTML वेबपेजों से डेटा निकालने के लिए भारी कोडिंग शामिल थी। नियमित अभिव्यक्तियों का उपयोग आमतौर पर HTML डेटा को पार्स करने के लिए किया जाता था, जो एक थकाऊ और जटिल कार्य था। इस दृष्टिकोण का मुख्य रूप से ऑफ़लाइन अनुप्रयोगों में उपयोग किया गया था, जिससे डेवलपर्स को उन्हें मैन्युअल रूप से ऑनलाइन लाने की आवश्यकता थी।
Scrapegraphai का उपयोग करते समय किस तरह के संकेतों को परिभाषित किया जा सकता है?
इस कॉन्फ़िगरेशन में एलएलएम और एम्बेडिंग दोनों के लिए मॉडल (ओलामा/llama3), तापमान, प्रारूप और आधार URL निर्दिष्ट करना शामिल है। आप अपनी विशिष्ट वेब स्क्रैपिंग आवश्यकताओं को पूरा करने के लिए आवश्यक मॉडल और अन्य मापदंडों को समायोजित कर सकते हैं। कुछ सामान्य संकेत इस प्रकार हैं:
- मुझे उनके शीर्षक और विवरण के साथ सभी परियोजनाओं को सूचीबद्ध करें।
- मुझे सभी सामग्री सूचीबद्ध करें।
संबंधित लेख
 Agentic AI 2025 में वॉल स्ट्रीट को मात देने के लिए निवेश में क्रांति लाता है
वर्षों से, वॉल स्ट्रीट फर्मों ने स्टॉक मार्केट पर हावी रहा है, बेहतर संसाधनों का उपयोग करके मुनाफा कमाया है। अब, अत्याधुनिक तकनीक, विशेष रूप से कृत्रिम बुद्धिमत्ता, संतुलन बना रही है। Agentic AI व्यक्
Perplexity ने पिछले महीने 780 मिलियन क्वेरीज़ प्राप्त कीं, CEO ने कहा
json收起自动换行复制{"content": ",[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],,[object Object],— Aravind Srinivas (@AravSrin
MURF AI बनाम Descript: शीर्ष टेक्स्ट-टू-स्पीच टूल्स की तुलना
डिजिटल युग में, उच्च गुणवत्ता वाले टेक्स्ट-टू-स्पीच (TTS) समाधान सामग्री निर्माताओं, विपणकों और शिक्षकों के लिए महत्वपूर्ण हैं। MURF AI Voices और Descript का Overdub अग्रणी मंचों के रूप में उभरते हैं,
सूचना (5)
0/200
Agentic AI 2025 में वॉल स्ट्रीट को मात देने के लिए निवेश में क्रांति लाता है
वर्षों से, वॉल स्ट्रीट फर्मों ने स्टॉक मार्केट पर हावी रहा है, बेहतर संसाधनों का उपयोग करके मुनाफा कमाया है। अब, अत्याधुनिक तकनीक, विशेष रूप से कृत्रिम बुद्धिमत्ता, संतुलन बना रही है। Agentic AI व्यक्
Perplexity ने पिछले महीने 780 मिलियन क्वेरीज़ प्राप्त कीं, CEO ने कहा
json收起自动换行复制{"content": ",[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],,[object Object],— Aravind Srinivas (@AravSrin
MURF AI बनाम Descript: शीर्ष टेक्स्ट-टू-स्पीच टूल्स की तुलना
डिजिटल युग में, उच्च गुणवत्ता वाले टेक्स्ट-टू-स्पीच (TTS) समाधान सामग्री निर्माताओं, विपणकों और शिक्षकों के लिए महत्वपूर्ण हैं। MURF AI Voices और Descript का Overdub अग्रणी मंचों के रूप में उभरते हैं,
सूचना (5)
0/200
![SamuelAllen]() SamuelAllen
SamuelAllen
 13 मई 2025 12:00:00 पूर्वाह्न IST
13 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎


 0
0
![ThomasLewis]() ThomasLewis
14 मई 2025 12:00:00 पूर्वाह्न IST
ThomasLewis
14 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
0
![BillyWilson]() BillyWilson
14 मई 2025 12:00:00 पूर्वाह्न IST
BillyWilson
14 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
0
![RyanAdams]() RyanAdams
13 मई 2025 12:00:00 पूर्वाह्न IST
RyanAdams
13 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAI revolucionou a forma como eu coleto dados de sites! É super eficiente e economiza muito tempo. Mas às vezes ele luta com estruturas de sites complexas, o que pode ser um pouco frustrante. Ainda assim, é essencial para qualquer entusiasta de dados! 😎
0
![CharlesYoung]() CharlesYoung
12 मई 2025 12:00:00 पूर्वाह्न IST
CharlesYoung
12 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAI ha transformado completamente cómo recopilo datos de sitios web. Es súper eficiente y me ahorra muchísimo tiempo. Pero a veces tiene problemas con estructuras de sitios complejas, lo cual puede ser un poco frustrante. Aún así, es imprescindible para cualquier entusiasta de datos! 😎
0
आज की डेटा-संचालित दुनिया में, वेबसाइटों से जानकारी निकालना विभिन्न उद्देश्यों जैसे कि बिजनेस इंटेलिजेंस, मार्केट रिसर्च और प्रतिस्पर्धी विश्लेषण के लिए आवश्यक है। वेब स्क्रैपिंग, वेबसाइटों से डेटा खींचने की स्वचालित प्रक्रिया, एक महत्वपूर्ण उपकरण बन गई है। हालांकि, पारंपरिक वेब स्क्रैपिंग विधियों में अक्सर वेबसाइट संरचनाओं में परिवर्तन के कारण जटिल कोडिंग और नियमित अपडेट की आवश्यकता होती है। यह वह जगह है जहां स्क्रैपिफ़ैफाई खेल में आता है-एक अभिनव ओपन-सोर्स पायथन लाइब्रेरी जिसका उद्देश्य बड़े भाषा मॉडल (एलएलएम) की क्षमताओं का उपयोग करके वेब स्क्रैपिंग को बदलना है।
प्रमुख बिंदु
- Scrapegraphai एक ओपन-सोर्स पायथन लाइब्रेरी है जो वेब स्क्रैपिंग को सुव्यवस्थित करती है।
- यह अधिक प्रभावी ढंग से वेबसाइटों से डेटा निकालने के लिए बड़े भाषा मॉडल (एलएलएम) का उपयोग करता है।
- उपकरण वेबसाइटों में परिवर्तन के लिए अनुकूल होकर चल रहे डेवलपर हस्तक्षेप की आवश्यकता को कम करता है।
- यह GPT, GEMINI, GROQ, AZURE और HUGHING FACE सहित LLM की एक श्रृंखला का समर्थन करता है।
- PIP के साथ स्थापना सरल है, और एक आभासी वातावरण का उपयोग करने की सिफारिश की जाती है।
- Scrapegraphai उपयोगकर्ताओं को डेटा को परिमार्जन करने और पारंपरिक तरीकों की तुलना में कम कोड के साथ विशिष्ट जानकारी निकालने में सक्षम बनाता है।
- ओलामा के माध्यम से स्थानीय होस्टिंग एक निजी और कुशल स्क्रैपिंग वातावरण प्रदान करता है।
वेब स्क्रैपिंग और इसके विकास को समझना
पारंपरिक वेब स्क्रैपिंग युग
1990 के दशक के अंत और 2000 के दशक की शुरुआत से वेब स्क्रैपिंग आसपास रहा है, जब इंटरनेट विकसित होने लगा। इसके बाद, HTML पृष्ठों से डेटा निकालने के लिए गहन कोडिंग को शामिल किया गया। कस्टम कोडिंग ऑनलाइन पाए गए विभिन्न HTML संरचनाओं के माध्यम से नेविगेट करने के लिए महत्वपूर्ण था। नियमित अभिव्यक्तियों का उपयोग अक्सर HTML डेटा को पार्स करने के लिए किया जाता था, जो थकाऊ और जटिल दोनों था। इस विधि का उपयोग मुख्य रूप से ऑफ़लाइन एप्लिकेशन में किया गया था, जिसमें ऑनलाइन जाने के लिए मैनुअल अपडेट की आवश्यकता थी। पूरी प्रक्रिया ने काफी समय और विशेषज्ञता की मांग की, जिससे यह मुख्य रूप से उन्नत कोडिंग कौशल वाले लोगों के लिए सुलभ हो गया।
समय के साथ, कई उपकरण और तकनीकें वेब स्क्रैपिंग को सरल बनाने के लिए उभरी हैं। पायथन, पुस्तकालयों के अपने मजबूत पारिस्थितिकी तंत्र के साथ, इस कार्य के लिए एक पसंदीदा भाषा बन गई है। सुंदर सूप और स्क्रैपी जैसे पुस्तकालयों ने अधिक संरचित डेटा निष्कर्षण विधियों की पेशकश की है, फिर भी वेबसाइट संरचनाओं को बदलने के लिए अनुकूल होने की चुनौती बनी रहती है।
परिदृश्य अब बड़ी भाषा मॉडल (एलएलएम) की शुरूआत के साथ महत्वपूर्ण रूप से बदल गया है जो पारंपरिक वेब स्क्रैपिंग में बहुत अधिक जटिलता को स्वचालित करता है। आइए एक उपकरण का पता लगाएं जिसने इसे आसान बना दिया है।
परिचय Scrapegraphai: वेब स्क्रैपिंग पुन: प्राप्त किया
Scrapegraphai एक शक्तिशाली समाधान के रूप में उभरता है, AI- चालित बड़े भाषा मॉडल का उपयोग करके वेब स्क्रैपिंग प्रक्रिया को स्वचालित और सरल बनाने के लिए। यह एक ओपन-सोर्स पायथन लाइब्रेरी है जिसे हम वेब स्क्रैपिंग के लिए क्रांति करने के लिए डिज़ाइन किया गया है।
पारंपरिक वेब स्क्रैपिंग टूल्स के विपरीत, जो अक्सर निश्चित पैटर्न या मैनुअल समायोजन पर निर्भर करते हैं, स्क्रैपिग्राफाई वेबसाइट संरचनाओं में परिवर्तन के लिए अनुकूलित करता है, निरंतर डेवलपर हस्तक्षेप की आवश्यकता को कम करता है। यह विभिन्न स्रोतों से डेटा स्क्रैपिंग को स्वचालित करने के लिए बड़ी भाषा मॉडल (एलएलएम) और मॉड्यूलर ग्राफ-आधारित पाइपलाइनों को एकीकृत करके बाहर खड़ा है।
यह पुस्तकालय पारंपरिक स्क्रैपिंग टूल की तुलना में अधिक लचीला और कम रखरखाव समाधान प्रदान करता है। यह उपयोगकर्ताओं को व्यापक कोडिंग के बिना या जटिल नियमित अभिव्यक्तियों से निपटने के बिना HTML मार्कअप से विशिष्ट जानकारी को आसानी से निकालने की अनुमति देता है। आपको बस यह निर्दिष्ट करने की आवश्यकता है कि आपको किन जानकारी की आवश्यकता है, और स्क्रैपिग्राफाई बाकी का ख्याल रखता है। यह जीपीटी, मिथुन, ग्रोक और एज़्योर सहित कई एलएलएम का समर्थन करता है, साथ ही स्थानीय मॉडल भी जो ओलामा का उपयोग करके आपकी मशीन पर चल सकते हैं।
प्रमुख घटक और वास्तुकला
Scrapegraphai विभिन्न वर्गों में सभी HTML नोड्स को संभालने के लिए अलग -अलग पार्सिंग नोड्स को नियुक्त करता है। यह HTML पृष्ठ के भीतर विशिष्ट क्षेत्रों को इंगित करने के लिए खोज नोड्स का उपयोग करता है। होशियार ग्राफ बिल्डर HTML में सभी मार्कअप भाषा का प्रबंधन करता है।
यहाँ इसकी वास्तुकला का एक त्वरित अवलोकन है:
- नोड प्रकार: Scrapegraphai HTML के विभिन्न वर्गों को संसाधित करने के लिए विभिन्न पार्सिंग नोड्स का उपयोग करता है, जिसमें सशर्त नोड्स, लाने वाले नोड्स, पार्स नोड्स, रैग नोड्स और खोज नोड्स शामिल हैं। ये नोड्स सशर्त पार्सिंग, डेटा लाने, सामग्री पार्सिंग, और HTML संरचना के भीतर प्रासंगिक जानकारी की खोज करने में सक्षम बनाते हैं।
- ग्राफ बिल्डर: Scrapegraphai का स्मार्ट ग्राफ बिल्डर सभी HTML मार्कअप भाषा को संभालकर वांछित जानकारी के निष्कर्षण को सरल बनाता है।
- बड़े भाषा मॉडल (LLMS): स्क्रैपिफ़ैफाई कुशल डेटा निष्कर्षण के लिए उनकी प्राकृतिक भाषा प्रसंस्करण क्षमताओं का लाभ उठाते हुए, मिथुन और ओपनई जैसे एलएलएम का समर्थन करता है।
लाइब्रेरी की मैन्युअल रूप से रेखांकन को परिभाषित करने या एलएलएम को संकेतों के आधार पर ग्राफ़ बनाने की क्षमता लचीलेपन की एक परत जोड़ती है जो विभिन्न उपयोगकर्ता की आवश्यकताओं और परियोजना की आवश्यकताओं को पूरा करती है। यह उच्च-स्तरीय आर्किटेक्चर न्यूनतम कोडिंग के साथ जटिल स्क्रैपिंग पाइपलाइनों को आसान बनाता है।
Scrapegraphai की स्थापना: स्थापना और कॉन्फ़िगरेशन
आवश्यक शर्तें और स्थापना चरण
Scrapegraphai में गोता लगाने से पहले, सुनिश्चित करें कि आपका सिस्टम आवश्यक पूर्वापेक्षाओं को पूरा करता है।
यहाँ सब कुछ सेट करने के लिए एक विस्तृत मार्गदर्शिका है:
- पायथन संस्करण: Scrapegraphai को पायथन 3.9 या उच्चतर की आवश्यकता होती है, लेकिन 3.12 से अधिक नहीं। पायथन 3.10 आमतौर पर पर्याप्त है।
- PIP: सुनिश्चित करें कि आपके पास PIP, PYTHON पैकेज इंस्टॉलर का नवीनतम संस्करण है। आप इसे कमांड
pip install --upgrade pipका उपयोग करके अपडेट कर सकते हैं। - Ollama (वैकल्पिक): यदि आप स्थानीय बड़े भाषा मॉडल चलाने की योजना बनाते हैं, तो आपको Ollama स्थापित करने की आवश्यकता होगी। विस्तृत स्थापना और सेटअप निर्देशों के लिए प्रलेखन की जाँच करें।
एक बार जब आप इन पूर्वापेक्षाओं की पुष्टि कर लेते हैं, तो स्क्रैपिग्राफाई स्थापित करना सीधा होता है:
pip install scrapegraphaiअपने सिस्टम में अन्य पायथन पैकेजों के साथ संघर्ष से बचने के लिए वर्चुअल वातावरण (CONDA, VENV, आदि) में स्क्रैपिग्राफाई स्थापित करने की अत्यधिक अनुशंसा की जाती है।
विंडोज उपयोगकर्ताओं के लिए, आप अतिरिक्त पुस्तकालयों को स्थापित करने के लिए लिनक्स (डब्ल्यूएसएल) के लिए विंडोज सबसिस्टम का उपयोग कर सकते हैं।
सही बड़ी भाषा मॉडल चुनना
Scrapegraphai का उपयोग करते समय प्रमुख निर्णयों में से एक आपकी वेब स्क्रैपिंग आवश्यकताओं के लिए उपयुक्त बड़े भाषा मॉडल (LLM) का चयन कर रहा है। Scrapegraphai विभिन्न LLMs का समर्थन करता है, प्रत्येक अपनी ताकत और क्षमताओं के साथ:
- Openai के GPT मॉडल: GPT-3.5 टर्बो और GPT-4 सामान्य-उद्देश्य वाले वेब स्क्रैपिंग कार्यों के लिए शक्तिशाली विकल्प हैं। ये मॉडल विविध वेबसाइट संरचनाओं से जानकारी को प्रभावी ढंग से समझ और निकाल सकते हैं।
- मिथुन: उन्नत प्राकृतिक भाषा प्रसंस्करण क्षमताओं की पेशकश करता है, जिससे यह जटिल डेटा निष्कर्षण कार्यों के लिए उपयुक्त है।
- Groq: अपनी गति और दक्षता के लिए जाना जाता है, Groq एक उत्कृष्ट विकल्प है जब आपको जल्दी से वेब डेटा के बड़े संस्करणों को संसाधित करने की आवश्यकता होती है।
- Azure: उद्यम-ग्रेड सुरक्षा और स्केलेबिलिटी प्रदान करता है, जो कड़े डेटा गोपनीयता आवश्यकताओं के साथ संगठनों के लिए आदर्श बनाता है।
- हगिंग फेस: ओपन-सोर्स एलएलएम की एक विस्तृत श्रृंखला प्रदान करता है, जिससे आप विशिष्ट वेब स्क्रैपिंग कार्यों के लिए अनुकूलित और फाइन-ट्यून मॉडल की अनुमति देते हैं।
डेटा गोपनीयता या लागत के बारे में चिंतित लोगों के लिए, Scrapegraphai आपको ओलमा का उपयोग करके स्थानीय LLM चलाने की अनुमति देता है। यह सेटअप आपको बाहरी सेवाओं पर भरोसा किए बिना एलएलएम की शक्ति का लाभ उठाने में सक्षम बनाता है।
व्यावहारिक उदाहरण: स्क्रैपिंग के साथ स्क्रैपिंग
Openai मॉडल स्थापित करना
OpenAI मॉडल को जोड़ने और उपयोग करने के लिए, आपको आवश्यक पुस्तकालयों को आयात करने और अपनी API कुंजी सेट करने की आवश्यकता होगी। यहाँ एक उदाहरण है कि कैसे Openai के GPT मॉडल के साथ Scrapegraphai को कॉन्फ़िगर किया जाए:
import os from dotenv import load_dotenv from scrapegraphai.graphs import SmartScraperGraph from scrapegraphai.utils import prettify_exec_infoload_dotenv () openai_key = os.getenv ("Openai_apikey")graph_config = { "एलएलएम": { "api_key": openai_key, "मॉडल": "GPT-3.5-टर्बो", } }
प्रॉम्प्ट, सोर्स और कॉन्फ़िगरेशन के साथ SmartScraperGraph को इनिशियलाइज़ करें
smart_scraper_graph = smartscrapergraph ( शीघ्र = "मुझे उनके शीर्षक और विवरण के साथ सभी परियोजनाओं को सूचीबद्ध करें।", स्रोत = " https://perinim.github.io/projects/ ", config = graph_config )
SmartScraperGraph चलाएं और परिणाम स्टोर करें
परिणाम = smart_scraper_graph.run () प्रिंट (परिणाम)
इस उदाहरण में, graph_config शब्दकोश को API कुंजी और उस मॉडल को निर्दिष्ट करने के लिए परिभाषित किया गया है जिसे आप उपयोग करना चाहते हैं (GPT-3.5-टर्बो)। फिर, SmartScraperGraph को एक संकेत, स्रोत URL और कॉन्फ़िगरेशन के साथ आरंभीकृत किया जाता है। अंत में, run() विधि को स्क्रैपिंग प्रक्रिया को निष्पादित करने और परिणामों को प्रिंट करने के लिए कहा जाता है।
स्थानीय मॉडल को कॉन्फ़िगर करना
स्थानीय मॉडलों के लिए, स्क्रैपिग्राफाई को थोड़ा और कॉन्फ़िगरेशन की आवश्यकता होती है, लेकिन यह अभी भी सीधा है:
from scrapegraphai.graphs import SmartScraperGraph from scrapegraphai.utils import prettify_exec_infograph_config = { "एलएलएम": { "मॉडल": "ओलामा/llama3", "तापमान": 0.5, "प्रारूप": "JSON", "model_tokens": 3500, "base_url": " http: // localhost: 11434 ", }, "एम्बेडिंग": { "मॉडल": "ओलामा/नॉमिक-एम्बेड-टेक्स्ट", "base_url": " http: // localhost: 11434 ", }, "वर्बोज़": सच, }प्रॉम्प्ट, सोर्स और कॉन्फ़िगरेशन के साथ SmartScraperGraph को इनिशियलाइज़ करें
smart_scraper_graph = smartscrapergraph ( शीघ्र = "मुझे उनके शीर्षक और विवरण के साथ सभी परियोजनाओं को सूचीबद्ध करें।", स्रोत = " https://perinim.github.io/projects/ ", config = graph_config )
SmartScraperGraph चलाएं और परिणाम स्टोर करें
परिणाम = smart_scraper_graph.run () प्रिंट (परिणाम)
इस कॉन्फ़िगरेशन में एलएलएम और एम्बेडिंग दोनों के लिए मॉडल (ओलामा/llama3), तापमान, प्रारूप और आधार URL निर्दिष्ट करना शामिल है। आप अपनी विशिष्ट वेब स्क्रैपिंग आवश्यकताओं को पूरा करने के लिए आवश्यक मॉडल और अन्य मापदंडों को समायोजित कर सकते हैं।
लागत और लाइसेंसिंग को समझना
ओपन सोर्स नेचर
चूंकि Scrapegraphai एक ओपन-सोर्स लाइब्रेरी है, इसलिए यह उपयोग करने के लिए स्वतंत्र है। आप लाइसेंस की शर्तों के अनुसार इसे डाउनलोड, संशोधित और वितरित कर सकते हैं। यह खुली प्रकृति सामुदायिक योगदान को प्रोत्साहित करती है और यह सुनिश्चित करती है कि पुस्तकालय व्यापक दर्शकों के लिए सुलभ रहे।
हालांकि, ध्यान रखें कि कुछ बड़े भाषा मॉडल का उपयोग करना, जैसे कि Openai के लोग, लागत को बढ़ा सकते हैं। Openai, Bardeen AI, और अन्य एक टोकन-आधारित मूल्य निर्धारण मॉडल पर काम करते हैं। जब आप एलएलएम को एक प्रॉम्प्ट भेजते हैं, तो यह अनुरोध को संसाधित करता है और एक प्रतिक्रिया उत्पन्न करता है। लागत संकेत और प्रतिक्रिया में उपयोग किए जाने वाले टोकन की संख्या पर निर्भर करती है। इसलिए, अप्रत्याशित आरोपों से बचने के लिए अपने उपयोग की निगरानी करना और अपनी एपीआई कुंजियों का प्रबंधन करना आवश्यक है। यह Openai के लिए अपनी खुद की API कुंजी रखने में मदद करता है।
लाभ और नुकसान के नुकसान
पेशेवरों
- LLMS का उपयोग करके सरलीकृत वेब स्क्रैपिंग प्रक्रिया।
- निरंतर रखरखाव और समायोजन की आवश्यकता कम।
- विभिन्न बड़े भाषा मॉडल के लिए समर्थन।
- बढ़ी हुई गोपनीयता और सुरक्षा के लिए स्थानीय एलएलएम होस्टिंग के लिए विकल्प।
- ग्राफ-आधारित पाइपलाइनों के माध्यम से लचीलापन और अनुकूलन में वृद्धि।
दोष
- बाहरी एलएलएम सेवाओं का उपयोग करने से जुड़ी संभावित लागत।
- चुने हुए एलएलएम की सटीकता और क्षमताओं पर निर्भरता।
- पायथन और आभासी वातावरण के साथ कुछ परिचित होने की आवश्यकता है।
- अपेक्षाकृत नई लाइब्रेरी, इसलिए सामुदायिक समर्थन और प्रलेखन अभी भी बढ़ सकता है।
प्रमुख विशेषताऐं
एलएलएम एकीकरण
Scrapegraphai बुद्धिमान वेब स्क्रैपिंग के लिए बड़े भाषा मॉडल (LLM) का लाभ उठाता है। यह स्वचालित रूप से वेबसाइट संरचनाओं में परिवर्तन का पता लगा सकता है और अनुकूलन कर सकता है, निरंतर मैनुअल समायोजन की आवश्यकता को कम कर सकता है। यह सुविधा अकेले महत्वपूर्ण विकास और रखरखाव समय बचाती है।
ग्राफ़-आधारित पाइपलाइन
लाइब्रेरी मॉड्यूलर ग्राफ-आधारित पाइपलाइनों को नियुक्त करती है जो कुशल और संरचित डेटा निष्कर्षण के लिए अनुमति देती है। इन पाइपलाइनों को विभिन्न वेब स्क्रैपिंग परिदृश्यों को फिट करने के लिए अनुकूलित किया जा सकता है, जो निष्कर्षण प्रक्रिया पर लचीलापन और नियंत्रण प्रदान करता है।
कई एलएलएम के लिए समर्थन
Scrapegraphai विभिन्न प्रकार के LLMs का समर्थन करता है, जिसमें GPT, GEMINI, GROQ, AZURE और HUGHING FACE शामिल हैं। यह समर्थन उपयोगकर्ताओं को उस मॉडल का चयन करने में सक्षम बनाता है जो उनकी आवश्यकताओं के अनुरूप है, चाहे वह सामान्य-उद्देश्य स्क्रैपिंग या अधिक विशेष कार्यों के लिए हो।
स्थानीय एलएलएम होस्टिंग
Ollama एकीकरण के साथ, Scrapegraphai आपको स्थानीय रूप से बड़ी भाषा मॉडल की मेजबानी करने की अनुमति देता है। यह बाहरी सेवाओं पर निर्भरता के बिना, एक सुरक्षित और निजी वेब स्क्रैपिंग वातावरण प्रदान करता है।
स्क्रैपिग्राफाई के लिए विविध उपयोग के मामले
ई-कॉमर्स बिजनेस इंटेलिजेंस
Scrapegraphai का उपयोग उत्पाद की कीमतों की निगरानी करने, प्रतियोगी प्रसाद को ट्रैक करने और ग्राहक समीक्षाओं को इकट्ठा करने के लिए किया जा सकता है, जो प्रतिस्पर्धी बढ़त के साथ ई-कॉमर्स व्यवसाय प्रदान करता है। इस डेटा के संग्रह को स्वचालित करके, व्यवसाय अपनी रणनीतियों को अनुकूलित करने के लिए डेटा-संचालित निर्णय ले सकते हैं।
निवेशक अनुसंधान
निवेशक वित्तीय डेटा निकालने, कंपनी की खबरों का विश्लेषण करने और बाजार के रुझानों की निगरानी करने के लिए स्क्रैपिग्राफाई का लाभ उठा सकते हैं। यह डेटा निवेशकों को सूचित निवेश निर्णय लेने और प्रभावी रूप से जोखिमों का प्रबंधन करने के लिए आवश्यक अंतर्दृष्टि प्रदान करता है।
विपणन और प्रतिस्पर्धी विश्लेषण
मार्केटिंग टीमें ग्राहक प्रतिक्रिया इकट्ठा करने, सोशल मीडिया ट्रेंड का विश्लेषण करने और प्रतियोगी रणनीतियों को ट्रैक करने के लिए स्क्रैपिफ़ैफाई का उपयोग कर सकती हैं। ये अंतर्दृष्टि विपणक को लक्षित अभियान बनाने, उनकी सामग्री का अनुकूलन करने और ग्राहक जुड़ाव में सुधार करने में सक्षम बनाती हैं।
अक्सर पूछे जाने वाले प्रश्नों
Scrapegraphai क्या है?
Scrapegraphai एक ओपन-सोर्स पायथन लाइब्रेरी है जिसे बड़े भाषा मॉडल (LLMS) का उपयोग करके वेब स्क्रैपिंग को सरल और स्वचालित करने के लिए डिज़ाइन किया गया है। यह उपयोगकर्ताओं को अधिक कुशलता से और कम मैनुअल कोडिंग के साथ वेबसाइटों से डेटा निकालने की अनुमति देता है।
Scrapegraphai स्थापित करने के लिए क्या आवश्यक शर्तें हैं?
पूर्वापेक्षाओं में पायथन 3.9 या उच्चतर (लेकिन 3.12 से अधिक नहीं), पीआईपी, और वैकल्पिक रूप से, स्थानीय एलएलएम चलाने के लिए ओलामा शामिल हैं।
मैं Scrapegraphai कैसे स्थापित करूं?
आप कमांड PIP के साथ PIP का उपयोग करके pip install scrapegraphai स्थापित कर सकते हैं। इसे आभासी वातावरण में स्थापित करने की सिफारिश की जाती है।
कौन से बड़े भाषा मॉडल स्क्रैपिग्राफाई का समर्थन करते हैं?
Scrapegraphai GPT, GEMINI, Groq, Azure, Hugging Face, और स्थानीय मॉडल Ollama का उपयोग करते हुए चलते हैं।
मैं Openai के GPT मॉडल का उपयोग करने के लिए Scrapegraphai को कैसे कॉन्फ़िगर करूं?
आपको graph_config Dictionary में अपनी OpenAI API कुंजी सेट करने की आवश्यकता है और उस मॉडल को निर्दिष्ट करें जिसे आप उपयोग करना चाहते हैं।
क्या मैं मुफ्त में Scrapegraphai का उपयोग कर सकता हूं?
हां, Scrapegraphai एक ओपन-सोर्स लाइब्रेरी है और उपयोग करने के लिए स्वतंत्र है। हालांकि, OpenAI के लोगों की तरह कुछ LLM का उपयोग करना टोकन उपयोग के आधार पर लागत को बढ़ा सकता है।
संबंधित प्रश्न
स्क्रैपिफ़ैफाई पारंपरिक वेब स्क्रैपिंग टूल की तुलना कैसे करता है?
Scrapegraphai वेबसाइट संरचना परिवर्तनों के कारण निरंतर मैनुअल समायोजन की आवश्यकता को कम करते हुए, AI- चालित बड़े भाषा मॉडल का लाभ उठाता है। पारंपरिक उपकरणों को अक्सर अधिक कोडिंग और रखरखाव की आवश्यकता होती है। Scrapegraphai वेबसाइट संरचनाओं को बदलने के लिए, निरंतर डेवलपर हस्तक्षेप की आवश्यकता को कम करता है। यह लचीलापन यह सुनिश्चित करता है कि वेबसाइट लेआउट बदलने पर भी स्क्रैपर कार्यात्मक बने रहते हैं। Scrapegraphai के साथ, आपको केवल यह निर्दिष्ट करने की आवश्यकता है कि आपको किस जानकारी की आवश्यकता है, और लाइब्रेरी बाकी को संभालती है। पारंपरिक वेब स्क्रैपिंग विधि 1990 के दशक के उत्तरार्ध और 2000 के दशक की शुरुआत से है, जब इंटरनेट ने आकार लेना शुरू किया था। दिन में वापस, वेब स्क्रैपिंग में HTML वेबपेजों से डेटा निकालने के लिए भारी कोडिंग शामिल थी। नियमित अभिव्यक्तियों का उपयोग आमतौर पर HTML डेटा को पार्स करने के लिए किया जाता था, जो एक थकाऊ और जटिल कार्य था। इस दृष्टिकोण का मुख्य रूप से ऑफ़लाइन अनुप्रयोगों में उपयोग किया गया था, जिससे डेवलपर्स को उन्हें मैन्युअल रूप से ऑनलाइन लाने की आवश्यकता थी।
Scrapegraphai का उपयोग करते समय किस तरह के संकेतों को परिभाषित किया जा सकता है?
इस कॉन्फ़िगरेशन में एलएलएम और एम्बेडिंग दोनों के लिए मॉडल (ओलामा/llama3), तापमान, प्रारूप और आधार URL निर्दिष्ट करना शामिल है। आप अपनी विशिष्ट वेब स्क्रैपिंग आवश्यकताओं को पूरा करने के लिए आवश्यक मॉडल और अन्य मापदंडों को समायोजित कर सकते हैं। कुछ सामान्य संकेत इस प्रकार हैं:
- मुझे उनके शीर्षक और विवरण के साथ सभी परियोजनाओं को सूचीबद्ध करें।
- मुझे सभी सामग्री सूचीबद्ध करें।










 Agentic AI 2025 में वॉल स्ट्रीट को मात देने के लिए निवेश में क्रांति लाता है
वर्षों से, वॉल स्ट्रीट फर्मों ने स्टॉक मार्केट पर हावी रहा है, बेहतर संसाधनों का उपयोग करके मुनाफा कमाया है। अब, अत्याधुनिक तकनीक, विशेष रूप से कृत्रिम बुद्धिमत्ता, संतुलन बना रही है। Agentic AI व्यक्
Agentic AI 2025 में वॉल स्ट्रीट को मात देने के लिए निवेश में क्रांति लाता है
वर्षों से, वॉल स्ट्रीट फर्मों ने स्टॉक मार्केट पर हावी रहा है, बेहतर संसाधनों का उपयोग करके मुनाफा कमाया है। अब, अत्याधुनिक तकनीक, विशेष रूप से कृत्रिम बुद्धिमत्ता, संतुलन बना रही है। Agentic AI व्यक्
 Perplexity ने पिछले महीने 780 मिलियन क्वेरीज़ प्राप्त कीं, CEO ने कहा
json收起自动换行复制{"content": ",[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],,[object Object],— Aravind Srinivas (@AravSrin
Perplexity ने पिछले महीने 780 मिलियन क्वेरीज़ प्राप्त कीं, CEO ने कहा
json收起自动换行复制{"content": ",[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],[object Object],,[object Object],— Aravind Srinivas (@AravSrin
 MURF AI बनाम Descript: शीर्ष टेक्स्ट-टू-स्पीच टूल्स की तुलना
डिजिटल युग में, उच्च गुणवत्ता वाले टेक्स्ट-टू-स्पीच (TTS) समाधान सामग्री निर्माताओं, विपणकों और शिक्षकों के लिए महत्वपूर्ण हैं। MURF AI Voices और Descript का Overdub अग्रणी मंचों के रूप में उभरते हैं,
13 मई 2025 12:00:00 पूर्वाह्न IST
MURF AI बनाम Descript: शीर्ष टेक्स्ट-टू-स्पीच टूल्स की तुलना
डिजिटल युग में, उच्च गुणवत्ता वाले टेक्स्ट-टू-स्पीच (TTS) समाधान सामग्री निर्माताओं, विपणकों और शिक्षकों के लिए महत्वपूर्ण हैं। MURF AI Voices और Descript का Overdub अग्रणी मंचों के रूप में उभरते हैं,
13 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAI has totally transformed how I gather data from websites! It's super efficient and saves me tons of time. But sometimes it struggles with complex site structures, which can be a bit frustrating. Still, a must-have for any data enthusiast! 😎
0
14 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAIを使ってウェブサイトからデータを収集するのが楽になりました!効率的で時間も節約できます。ただ、複雑なサイト構造には苦労することがあり、少しイライラします。それでもデータ愛好者には必須ですね!😎
0
14 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAI 덕분에 웹사이트에서 데이터를 수집하는 게 훨씬 쉬워졌어요! 효율적이고 시간도 많이 절약됩니다. 다만 복잡한 사이트 구조에는 어려움을 겪어서 조금 짜증나요. 그래도 데이터 애호가라면 꼭 필요한 도구입니다! 😎
0
13 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAI revolucionou a forma como eu coleto dados de sites! É super eficiente e economiza muito tempo. Mas às vezes ele luta com estruturas de sites complexas, o que pode ser um pouco frustrante. Ainda assim, é essencial para qualquer entusiasta de dados! 😎
0
12 मई 2025 12:00:00 पूर्वाह्न IST
ScrapeGraphAI ha transformado completamente cómo recopilo datos de sitios web. Es súper eficiente y me ahorra muchísimo tiempo. Pero a veces tiene problemas con estructuras de sitios complejas, lo cual puede ser un poco frustrante. Aún así, es imprescindible para cualquier entusiasta de datos! 😎
0













